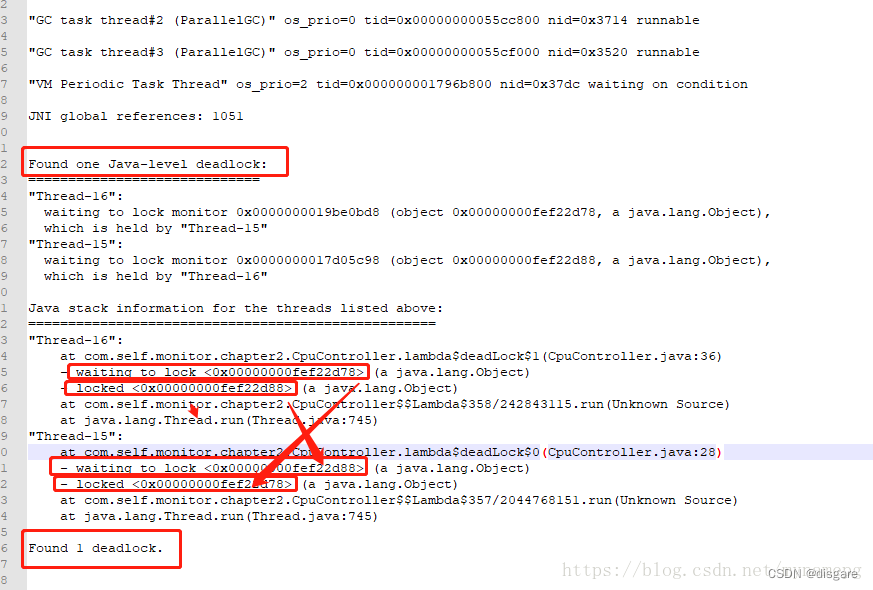
来源书籍:
TENSORFLOW REINFORCEMENT LEARNING QUICK START GUIDE
《TensorFlow强化学习快速入门指南-使用Python动手搭建自学习的智能体》
著者:[美]考希克·巴拉克里希南(Kaushik Balakrishnan)
译者:赵卫东
出版社:Packt 机械工业出版社
1.深度确定性策略梯度
前面的章节介绍了如何使用强化学习来解决离散行为问,例如在Atari游戏中出现的问题。在此基础上,可以解决持续的、有真正价值的行为问题。连续控制的问题有很多,例如机械臂的电动机转矩;自动汽车的转向、加速和制动;地上的轮式机器人运动;无人机的滚动、俯仰和偏航控制等。对于这些问题,可以在强化学习背景下训练神经网络以输出真正价值的行为。
许多连续控制算法涉及两个网络:一个为actor(基于策略),另一个为critic(基于价值)。因此,这一系列算法称为Actor-Critic算法。actor的角色是学习一个好的策略,以预测给定状态下的好行为。critic的作用是确定actor是否采取了好的行为,并提供反馈作为actor的学习信号。这类似于学生-老师或员工-老板之间的关系,其中学生或员工承担一项任务或工作,老师或老板提供对其行为质量的反馈。
连续控制强化学习的基础是策略梯度,它是对神经网络权重变化的合理估计,以便最大化长期累积折扣奖励。具体地说,其使用链式规则,是对需要反向传播到actor网络中以改进策略的梯度估计,被评估为一小批样品的平均值。本章将讨论以上内容。特别地,将介绍深度确定性策略梯度(DDPG)算法,这是一种最先进的用于连续控制的强化学习算法。
连续控制有许多实际应用。例如,连续控制可以评估自动驾驶汽车的转向/加速和制动,可以用于确定机器人行动所需的转矩,还可以用于生物医学,比如确定人类运动的肌肉控制。
1.1Actor-Critic算法和策略梯度
举一个学生在学校如何学习的例子。学生在学习时通常会犯很多错误。当他们学得很好时,它们的老师会提供积极的反馈;而如果学生在一项任务上做得不好,老师会提供负面反馈。这个反馈可以作为学生更好地完成任务地学习信号。这就是Actor-Critic算法。
Actor-Critic算法包括的步骤如下:
①两个神经网络:一个为actor,另一个为critic
②actor就像学生,在给定的状态下采取行动
③critic就像老师,为actor提供学习地反馈
④与老师不同,critic网络也应该从头开始训练,这使得问题具有挑战性
⑤策略梯度用于训练actor
⑥Bellman更新的L2范数用于训练critic
策略梯度
策略梯度定义如下:

是需要最大化的长期奖励函数,
是策略神经网络参数,
是小批量大小,
是状态动作值函数,
是策略。换言之,此式计算了动作-价值函数相对于行为的梯度,以及策略相对于网络参数的梯度,并将它们相乘,然后从一个小批量中取
个数据样本的平均值。然后,可以在梯度上升设置中使用此策略梯度来更新策略参数。请注意,它本质上是计算策略梯度的微积分的链式规则(chain rule of calculus)。
1.2深度确定性策略梯度
本节将研究DDPG算法,这是一种目前最先进的用于连续控制的强化学习算法之一。它最初由Goole DeepMind于2016年发布,并在社区中引起了大家广泛的兴趣,此后又提出了几种新的变体。与DQN的情况一样,DDPG也使用目标网络来保持稳定性。它还使用重放缓冲区来重新使用过去的数据。因此,DDPG是一种异步策略的强化学习算法。
ddpg.py文件是开始训练和测试的主文件。它将调用TrainOrTest.py中训练或测试函数。AandC.py文件包含actor和critic网络的TensorFlow代码。reply_buffer.py使用双向队列数据结构将样本存储在重放缓冲区中。
代码:
https://github.com/x45w/TensorFlow-Reinforcement-Learning-Quick-Start-Guide-master-DDPG![]() https://github.com/x45w/TensorFlow-Reinforcement-Learning-Quick-Start-Guide-master-DDPG
https://github.com/x45w/TensorFlow-Reinforcement-Learning-Quick-Start-Guide-master-DDPG
2.思考题
(1)DDPG是同步策略算法还是异步策略算法?
答:DDPG是一种异步策略算法,因为它使用重放缓冲区。
(2)是否必须对actor和critic使用相同的神经网络结构,还是可以选择不同的神经网络结构?
答:一般来说,actor和critic隐藏层和每个隐藏层的神经元数量相同,但这不是必须的。注意,对于actor和critic,输出层是不同的。其中actor的输出数量等于动作的数量,而critic只有一个输出。
(3)能用DDPG玩Atari Breakout吗?
答:DDPG用于连续控制,即动作是连续且实时的。Atari Breakout有离散动作,因此DDPG不适合Atari Breakout。
(4)为什么神经网络的偏置被初始化为小的正值?
答:使用Relu激活函数,因此偏差被初始化为小的正值,以便它们在训练开始时触发并允许梯度反向传播。
(5)试修改本章中的代码来训练一个agent来学习InvertedDoublePendulum-v2问题。是否Pendulum-v0更具挑战性?
答:https://mgoulao.github.io/gym-docs/environments/mujoco/inverted_double_pendulum/
(6)改变神经网络结构,检查agent是否可以学习Pendulum-v0。例如,使用值400、100、25、10、5和1不断减少第一个隐藏层中的神经元数量,并检查agent对第一个隐藏层中的不同数量神经元的表现。如果神经元数量太少,可能会导致信息瓶颈,网络的输入无法充分表示。也就是说,当深入探讨神经网络时,发现信息会丢失。你观察到这种效果了吗?
答:注意当第一层中的神经元数量依次减少时学习会发生什么。一般来说,不仅在强化学习设置中会遇到信息瓶颈,在任何深度学习问题中都会遇到信息瓶颈。