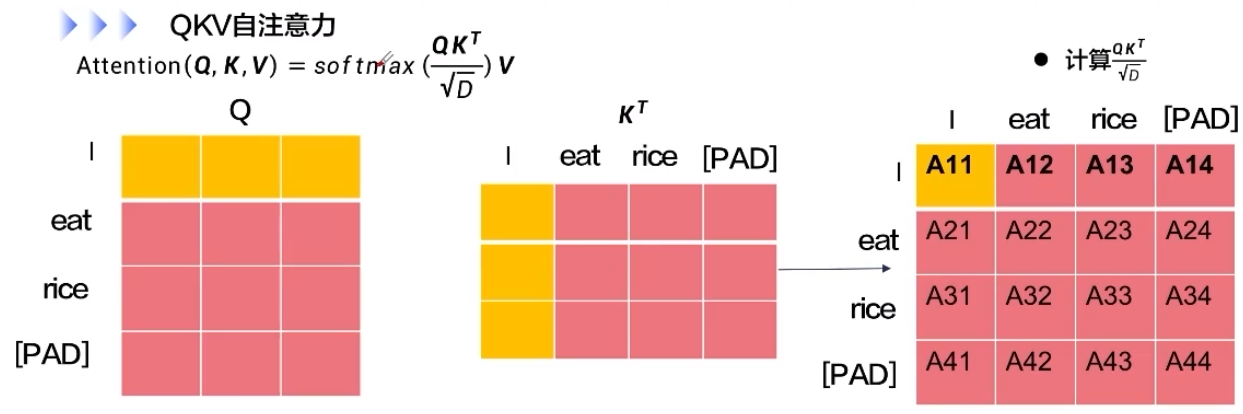
SGD 梯度下降

记住这里是减去
,因为梯度的方向指出了函数再给定上升最快的方向,或者说指引函数值增大的方向,所以我们需要沿着梯度的反方向走,才能尽快达到极小值(使其损失函数最小)。
SGD+Momentum

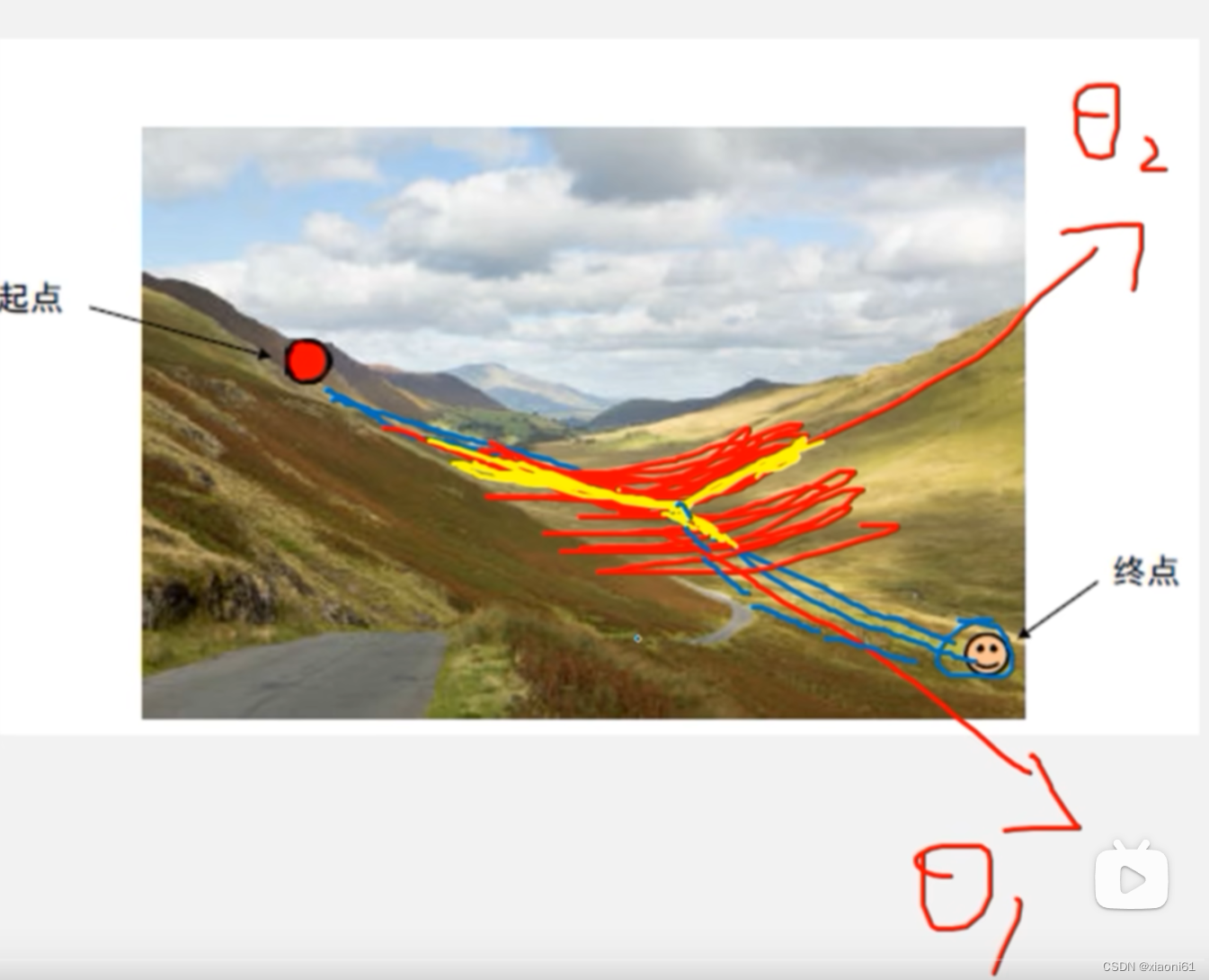
加上动量是为了解决在一个方向时,以梯度进行累加以更快的方法达到极值点;而在左右震荡区间内,却一正一负进行抵消,不会出现大幅震荡的情况。
需要注意的时:累加的是梯度,震荡的方向的梯度互相抵消,梯度小的方向逐渐累加
一般取0.9
Adagrad(自适应)

累加梯度平方,此时若的绝对值大,那么导致r变大,因为
在分母,则对于
的更新速率变低。Adagrad考虑的是全局信息,因为在累计平方梯度时只会越来越大,导致在最后步长越来越小,最终可能停下来。
RMSProp

针对于Adagrad的缺点,RMSProp提出了一个衰减系数,一般设置为0.999。由此可以渐渐忘掉之前的信息
Adam

结合了RMSProp和SGD+Momentum的优点,又进行了小量的修正,作用:避免冷启动,开始时用大步长,迅速找到一个逼近全局最优解的地方。