目录
1. 聚簇索引是如何产生的
2. 聚簇索引和非聚簇索引有什么区别
1. 聚簇索引是如何产生的
首先聚簇索引和非聚簇索引是 InnoDB 里面的叫法,其次呢,一张表它一定有聚簇索引。
它产生的过程如下:
- 表中有无有主键索引,如果有,则使用主键索引作为聚簇索引;
- 如果没有主键索引,则看表中有无唯一索引,那么使用第一个唯一索引;
- 如果以上两个条件都不满足,InnoDB 则会生成隐藏聚簇索引。
2. 聚簇索引和非聚簇索引有什么区别
① 聚簇索引
聚簇索引一般是主键索引,
例如主键索引 id 对应的聚簇索引结构图(叶子节点存储整表数据):

② 非聚簇索引
非聚簇索引在 InnoDB 也叫做二级索引,非聚簇索引是普通列的索引(非主键索引)
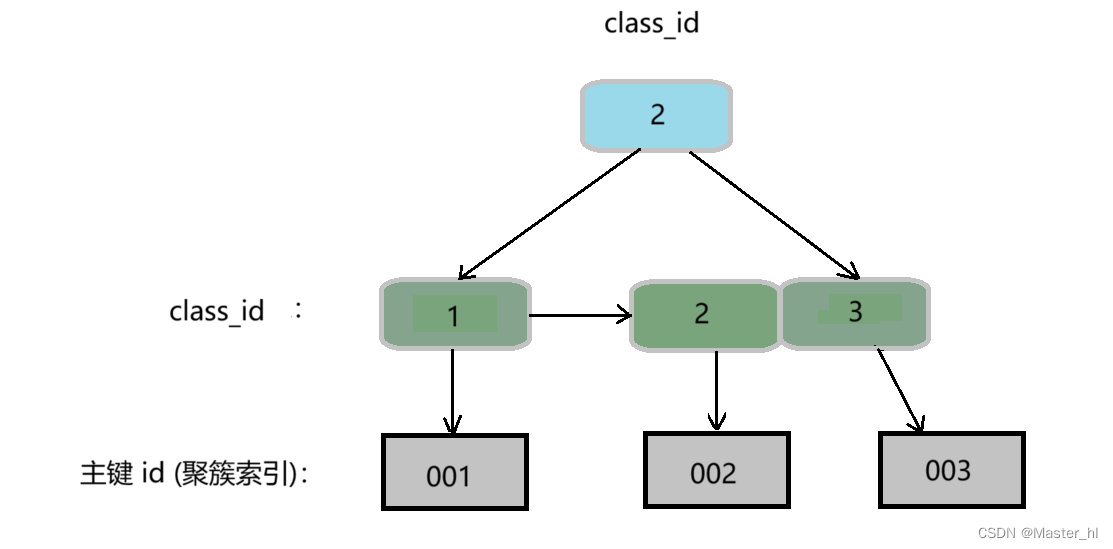
例如普通 class_id 对应的非聚簇索引结构图(叶子节点存储的是聚簇索引):
【区别】
- 聚簇索引叶子结点存储的是行数据,而非聚簇索引叶子节点存储的是聚簇索引,因此通过聚簇索引可以找到真正的行数据;
- 由于非聚簇索引的叶子结点存储的是聚簇索引,因此使用非聚簇索引还需要进行回表查询,所以在查询效率方面,聚簇索引要高于非聚簇索引;
- 聚簇索引一般为主键索引,而一个表中只能有一个主键,因此一个表中也只能有一个聚簇索引,而非聚簇索引则没有数量上的限制。
什么叫回表查询 ?
由于非聚簇索引的叶子节点存储的不是真正的数据,而是聚簇索引,所以在使用普通索引进行查询操作时,会先查询到聚簇索引,然后再去聚簇索引对应的 B+ 数去查询真正的数据,这个过程就叫做回表查询。



![[oneAPI] 手写数字识别-BiLSTM](https://img-blog.csdnimg.cn/2c9eb12082384d289927663a38f942d0.png)
![[obs] 编译记录](https://img-blog.csdnimg.cn/691b43a100994e829318a2a5dd99ad0e.png)