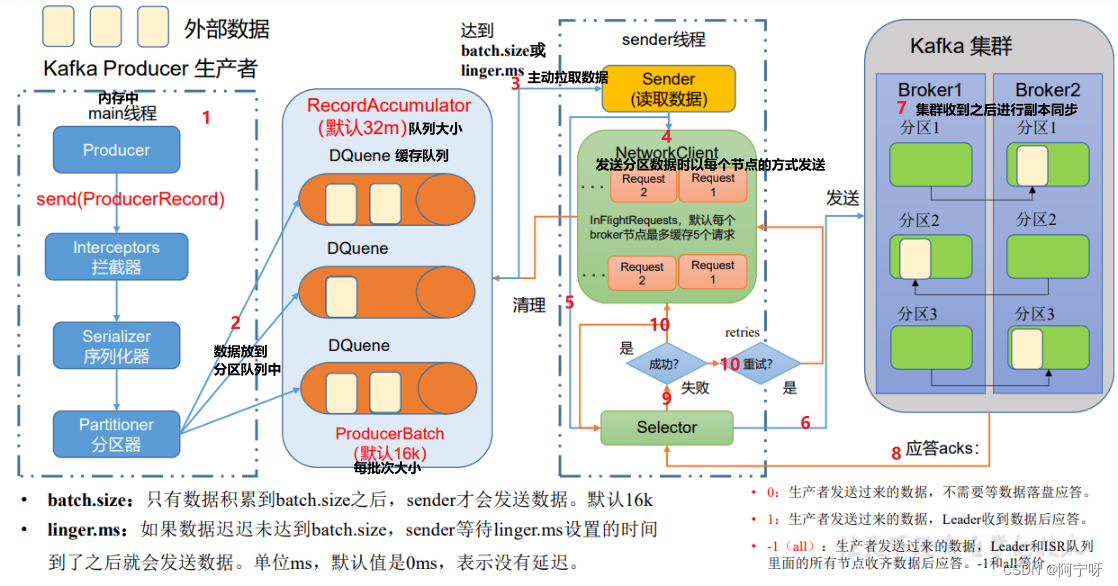
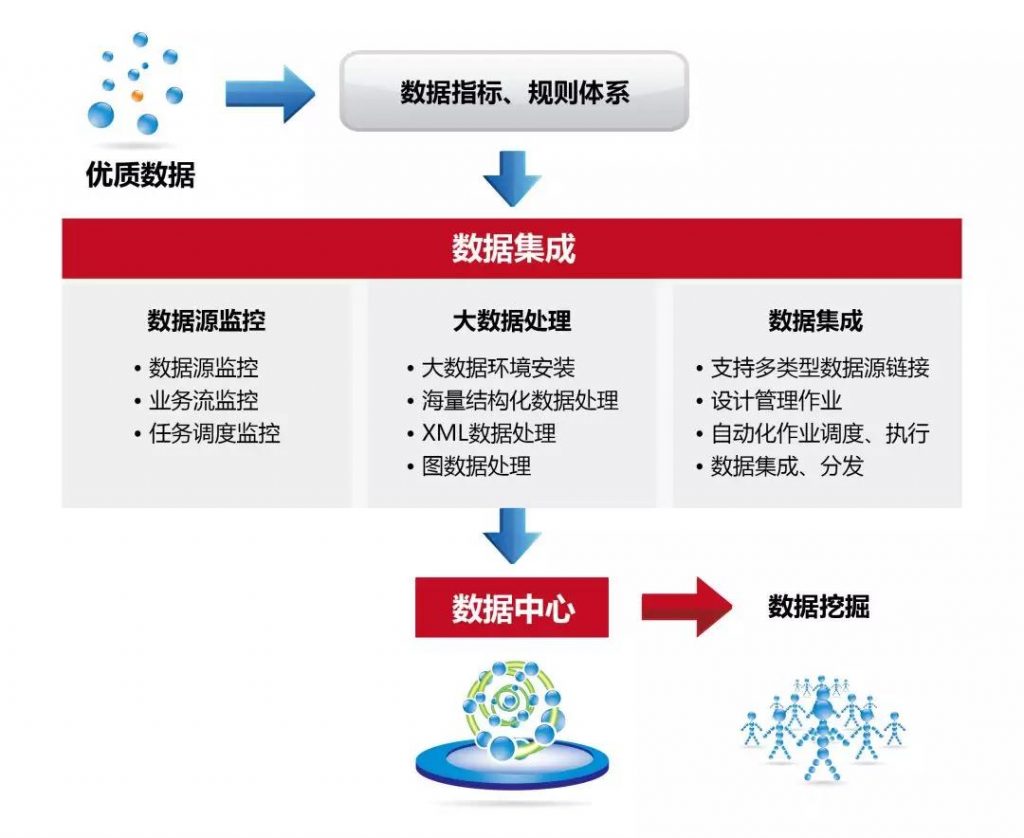
将外部传送给过来的数据发送到kafka集群。
1 发送原理
(1)创建main()线程,创建producer对象,调用send方法,经过拦截器(可选)、序列化器、分区器。
(2)分区器将数据发送到分区中,每个分区创建一个队列(分区是在内存中完成的),内存总大小为32M,每个批次的大小为16K。
(3)sender线程将缓冲队列中的数据读取出来发往Kafka集群,根据batch.size和linger.ms拉取数据(即每批次的数据满了之后或者设置的时间到了之后拉取数据)。
(4)sender线程拉取数据,以每个节点为一组,当第一个请求数据发送到broker1中,broker没有及时应答,还是能发送第二个请求,最多有5个请求都没有收到应答就不会再继续发送请求。
(5)selector打通输入流和输出流。
(6)链路接通后发送数据。
(7)Kafka集群收到数据后根据副本机制进行副本同步。
(8)Kafka集群收到数据后根据应答机制进行应答。
(9)selector根据Kafka集群反馈的消息进行判断。
(10)如果成功则删掉该请求同时在缓冲队列里清理掉对应的每一个分区的数据;如果失败则进行重试,重新发送请求,知道成功为止。
2 生产者重要参数列表

3 异步发送API
3.1 普通异步发送
(1)需求:创建Kafka 生产者,采用异步的方式发送到 Kafka Broker
(2)分析:异步发送即将外部的数据发送到缓冲队列里(不管缓冲队列中的数据有没有发送到Kafka集群)。
步骤:
(1)创建kafka工程,在pom.xml中导入依赖:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
(2)创建类:com.astudy.kafka.producer.CustomProducer
package com.study.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducer {
public static void main(String[] args) {
//0.创建 kafka 生产者的配置对象
Properties properties = new Properties();
//给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//1.创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
//2.调用 send 方法,发送消息
for (int i = 0; i < 3; i++) {
kafkaProducer.send(new ProducerRecord<>("first","test"+i));
}
//3.关闭资源
kafkaProducer.close();
}
}
(3)测试:
在hadoop102上开启Kafka消费者:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topic first
在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息:

3.2 带回调函数的异步发送
分析:
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发送成功,如果Exception 不为 null,说明消息发送失败。
package com.study.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducerCallback {
public static void main(String[] args) throws InterruptedException {
//0.创建 kafka 生产者的配置对象
Properties properties = new Properties();
//给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//1.创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
//2.调用 send 方法,发送消息
for (int i = 0; i < 3; i++) {
kafkaProducer.send(new ProducerRecord<>("first", "test" + i), new Callback() {
// 该方法在 Producer 收到 ack 时调用,为异步调用
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
// 没有异常,输出信息到控制台
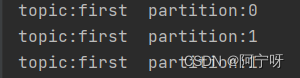
System.out.println("topic:" + recordMetadata.topic() + " partition:" + recordMetadata.partition());
}else {
// 出现异常打印
e.printStackTrace();
}
}
});
// 延迟一会会看到数据发往不同分区
Thread.sleep(2);
}
//3.关闭资源
kafkaProducer.close();
}
}
测试:
在hadoop102上开启Kafka消费者:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topic first
在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息:

4 同步发送API
分析:只需在异步发送的基础上,再调用一下 get()方法即可。
package com.study.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducerSync {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//0.创建 kafka 生产者的配置对象
Properties properties = new Properties();
//给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//1.创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
//2.调用 send 方法,发送消息
for (int i = 0; i < 3; i++) {
kafkaProducer.send(new ProducerRecord<>("first","test"+i)).get();
}
//3.关闭资源
kafkaProducer.close();
}
}
测试:
在hadoop102上开启Kafka消费者:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topic first
在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息:











![linux学习(自写shell)[11]](https://img-blog.csdnimg.cn/b3b1e0e5472a42cb96ae1ac63d4d3d2a.png)