案例背景
每月都要写各种月报,经营管理月报,资产月报.....这些报告文字目标都是高度相似的,只是需要替换为每个月的实际数据就行,如下:

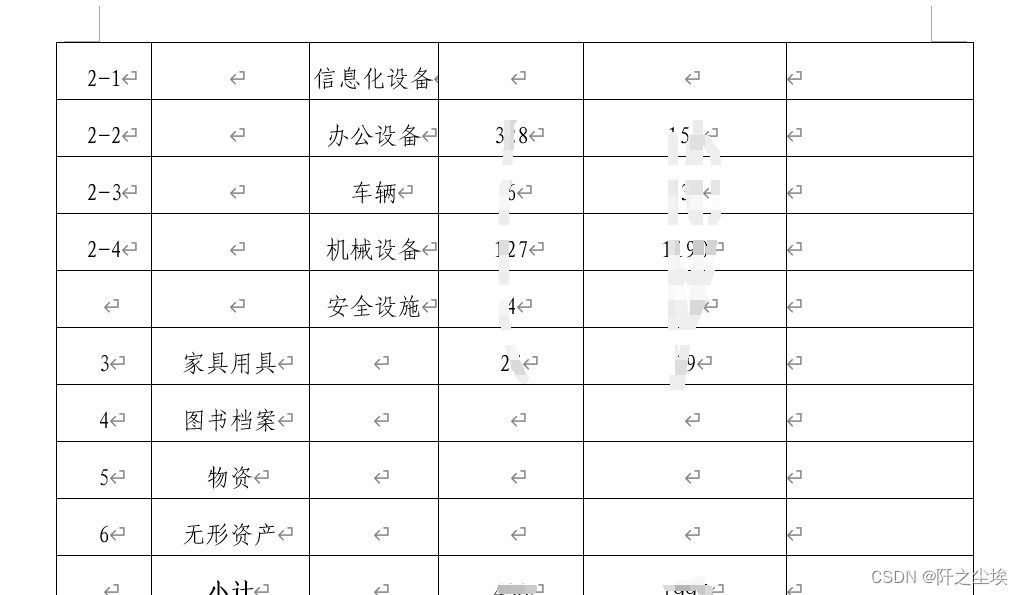
(打码是怕信息泄露.....)
可以看到,这个报告的都是高度模板化,我们只需要对里面的某些文字进行替换,例如2023年7月换成2023年8月,资产数量490替换为最新的值,表格里面的数值也是一样的情况。
这篇文章的目的:我们并不是从头到尾,去从0开始生产月报,而是在往期的月报上进行修改。
这些东西都是复制粘贴,数据准备好了,按照定点的位置填就行了。所以代码来自动化这个流程就很变得很便捷。
代码实现
导入包:
import xlrd
import pandas as pd
import docx
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
from docx import Document
from docx.oxml.ns import qn
import calendar
from docx.shared import Cm, Pt #设置像素、缩进等
from docx.enum.table import WD_TABLE_ALIGNMENT, WD_ALIGN_VERTICAL
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
year = 2023
month = 7
num_days = calendar.monthrange(year, month)[1]
print(f"{year}年{month}月有{num_days}天")
这里我们要先填入年份和信息,因为月报是月底写,最后的日期可能是31号可能是30号,所以需要用代码自动化计算一下日期.....
锚点查找
进行我们的第一步,我们需要数据来写报告,数据肯定都在excel里面算好了,没算好也肯定需要一定的流程加工算好了再说.....(参考我自动化小技巧16的文章)
例如上面我展示的目标,我需要填资产和负债的信息,这些数据都在财务那边给我的资产负债表里面,我肯定不会自己去打开excel表查找我要的值然后再写入代码里面.....这太低效了,而且这就不是自动化了。我们要用代码来找。
但是怎么找自己特定需要的数据呢?例如我要找流动资产合计这一项,我可以用固定的位置来找,比如财务那边总把流动资产合计的值写在C26这个格子里面。

但这种固定位置的查找可能有时候会有问题,比如财务那边突然需要加个标题,把资产负债表整体向下挪动了一行....那么C26这个位置就不对了。
所以绝对位置不准确,那我们就应该用相对位置,例如我发现我需要的这个值总是在‘流动资产合计’这个格子的右边两列的位置。那我先查找‘流动资产合计’这一项,然后右移动两格就是我需要的值了。
我称这种查找为锚定查找,找一个锚点,然后偏移找到自己需要的附近的值。这种相对查找的方法比绝对查找的方法出问题的可能性会小一点。
读取资产负债表,定义一个函数来进行锚点查找:
#资产负债表
wb = xlrd.open_workbook('*************业有限公司2023年7月报表20230731.xls')
sheet = wb.sheet_by_index(0) #wb.sheet_by_name('资产负债表')
def find_and_offset_xlrd(sheet, target_value, offset_row, offset_column):
for row in range(sheet.nrows):
for col in range(sheet.ncols):
if str(sheet.cell(row, col).value).replace(' ','') == target_value:
target_cell_value = sheet.cell(row + offset_row, col + offset_column).value
return target_cell_value然后进行查找各种我们需要的值:(注意这个函数是针对xls文件的,xlsx文件读取不了。。后面还会有针对xlsx的锚点查找函数,放在文章最后)
资产总计 = find_and_offset_xlrd(sheet, '资产总计', 0, 2)/10000
流动资产合计=find_and_offset_xlrd(sheet, '流动资产合计', 0, 2)/10000
非流动资产合计=find_and_offset_xlrd(sheet, '非流动资产合计', 0, 2)/10000
负债合计=find_and_offset_xlrd(sheet, '负债合计', 0, 2)/10000
固定资产净值=find_and_offset_xlrd(sheet, '固定资产净值', 0, 2)/10000
[资产总计,流动资产合计,非流动资产合计,负债合计,固定资产净值]![]()
这就是我们需要的值,然后进行一些必要的运算
流动资产占比=100*流动资产合计/资产总计
非流动资产占比=100*非流动资产合计/资产总计
净资产=资产总计-负债合计
固定资产占比=100*固定资产净值/资产总计
其他非流动资产=非流动资产合计-固定资产净值
其他非流动资产占比=100*其他非流动资产/资产总计段落替换
由于我们是资产月报,还得往表格里面填入各种资产的信息,我们需要读取我之前文章做好的资产分类汇总表:
df=pd.read_excel('../../资产管理/资产类别变动后汇总/分类汇总金额.xlsx',sheet_name='汇总').set_index('资产类别名称')
df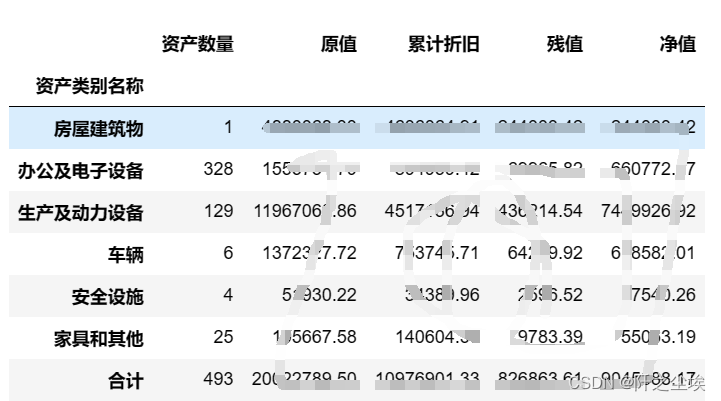
进行一些必要的计算...:
实物资产数量=df.loc['合计','资产数量']
资产原值=df.loc['合计','原值']/10000
生产及动力设备=df.loc['生产及动力设备','原值']/10000写好我们 需要的文字目标:
txt=f'''截至{year}年{month}月,**公司资产总计约{资产总计:.0f}万元。其中,流动资产{流动资产合计:.0f}万元,占比{流动资产占比:.1f}%;非流动资产{非流动资产合计:.0f}万元,占比{非流动资产占比:.1f}%。负债合计{负债合计:.0f}万元,净资产{净资产:.0f}万元。
公司非流动资产中,固定资产{固定资产净值:.0f}万元(固定资产净值),占资产总额{固定资产占比:.0f}%;其他类非流动资产{其他非流动资产:.0f}万元,占资产总额{其他非流动资产占比:.2f}%(长期待摊费用、递延所得税资产、无形资产)。
截至{year}年{month}月,**公司管理实物资产数量{实物资产数量:.0f}项,金额{资产原值:.0f}万元(资产原值)。其中,自有实物资产数量{实物资产数量:.0f}项,主要为机械设备,账面价值{生产及动力设备:.0f}万元;受托管理实物资产数量0项,账面价值(或资产原值)0万元。公司管理实物资产情况如下表:
'''
txt=txt.split('\n')这几句话我们就需要进行替换了,替换掉原来的段落。这种很多需要修改的我们就进行段落替换,如果只是像2023年7月换成8月的这种小修改就简单替换(后面会有这种函数)
核心函数!!修改样式:
def set_style(paragraphs,style=u'仿宋_GB2312',size=16):
for run in paragraphs.runs:
run.font.name = style
run.font.size = Pt(size)
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"),style)这个函数的功能是修改这个段落的字体和大小。因为我发现每次代码修改了word里面的东西后,它就会默认使用微软体文字.....使用我们需要把内容变成我们要的模板格式。我们需要这个函数,无论替换了什么内容,都需要它来变一下格式 擦屁股。
读取文档,替换文字:
doc = docx.Document(f'./资产附件/附件1:资产管理月度情况简报{month-1}月.docx')
for i,paragraph in enumerate(doc.paragraphs):
#if '2023年' in run.text:
if '月,远大公司资产总计约'in paragraph.text:
paragraph.text =txt[0]
print('0') ; set_style(paragraph)
if '公司非流动资产中,固定资产' in paragraph.text:
paragraph.text = txt[1]
print('1') ;set_style(paragraph)
if '月,远大公司管理实物资产数量' in paragraph.text:
paragraph.text=txt[2]
print('2') ;set_style(paragraph)
if f'{year}年' in paragraph.text and (i>len(doc.paragraphs)-3):
paragraph.text=f'{year}年{month}月{num_days}日' ;set_style(paragraph)
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHTif判断是尽可能找到你需要替换的段落,然后换为上面我们设定的文字,然后设置一下样式。
最后这个条件判断意思是:如果段落行数为最后3行里面的出现了年月日,那么久换为最新的年月日。因为我需要改落款日期,但是对全文全部修改会可能出问题,所以限定了最后3行。
文字替换
这个函数类似于word里面的替换功能,把你要查找的文字,换为其他文字
#查找替换
def docx_replace(old_text, new_text, doc):
for paragraph in doc.paragraphs:
if old_text in paragraph.text:
paragraph.text = paragraph.text.replace(old_text, new_text)
set_style(paragraph)
docx_replace(f"截至{year}年{month-1}月", f"截至{year}年{month}月", doc)这是替换了月份,每次都把月报里面的日期肯定要更新为最新的。
docx_replace(f"{year}年1-{month-1}月,经省", f"{year}年1-{month}月,经省", doc)
docx_replace(f"现将**公司{month-1}月资产管理情况报告如下", f"现将**公司{month}月资产管理情况报告如下", doc)表格替换
文字我们都改了之后,我们对word表里面的数据也要进行修改:
我们可以获取word里面的表对象:
table = doc.tables[0]直接替换里面的文字是不行的,还是因为样式会变成默认样式,和领导要求的模板不一样...
所以也需要设置一下。
定义一个表格替换函数,传入你要替换的格子,替换的文本,以及字体样式,大小,居中什么的
def set_cell_text(cell, text, font_name='仿宋_GB2312', font_size=12, alignment=WD_PARAGRAPH_ALIGNMENT.CENTER):
cell.text = text
for paragraph in cell.paragraphs:
paragraph.alignment = alignment
set_style(paragraph,font_name,font_size)因为目标表格填的位置是固定的,所以我可以使用绝对位置来查找我需要换的数值:
set_cell_text(table.cell(2, 3), str(df.loc['房屋建筑物','资产数量']), '仿宋_GB2312', 12)
set_cell_text(table.cell(2, 4), f'''{df.loc['房屋建筑物','原值']/10000:.0f}''')
set_cell_text(table.cell(7, 3), str(df.loc['办公及电子设备','资产数量']))
set_cell_text(table.cell(7, 4), f'''{df.loc['办公及电子设备','原值']/10000:.0f}''')
set_cell_text(table.cell(8, 3), str(df.loc['车辆','资产数量']))
set_cell_text(table.cell(8, 4), f'''{df.loc['车辆','原值']/10000:.0f}''')
set_cell_text(table.cell(9, 3), str(df.loc['生产及动力设备','资产数量']))
set_cell_text(table.cell(9, 4), f'''{df.loc['生产及动力设备','原值']/10000:.0f}''')
set_cell_text(table.cell(10, 3), str(df.loc['安全设施','资产数量']))
set_cell_text(table.cell(10, 4), f'''{df.loc['安全设施','原值']/10000:.0f}''')
set_cell_text(table.cell(11, 3), str(df.loc['家具和其他','资产数量']))
set_cell_text(table.cell(11, 4), f'''{df.loc['家具和其他','原值']/10000:.0f}''')
set_cell_text(table.cell(15, 3), str(df.loc['合计','资产数量']))
set_cell_text(table.cell(15, 4), f'''{df.loc['合计','原值']/10000:.0f}''')最后保存,一个自动化月报的工程就完成啦。
doc.save(f'附件1:资产管理月度情况简报{month}月.docx')






![linux学习(自写shell)[11]](https://img-blog.csdnimg.cn/b3b1e0e5472a42cb96ae1ac63d4d3d2a.png)