初识数据
注册账号后下载数据集

文件目录如下:
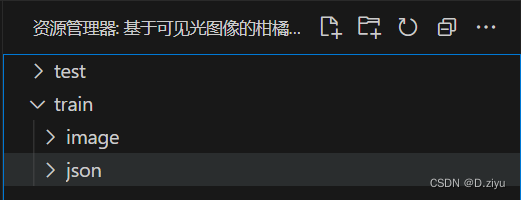
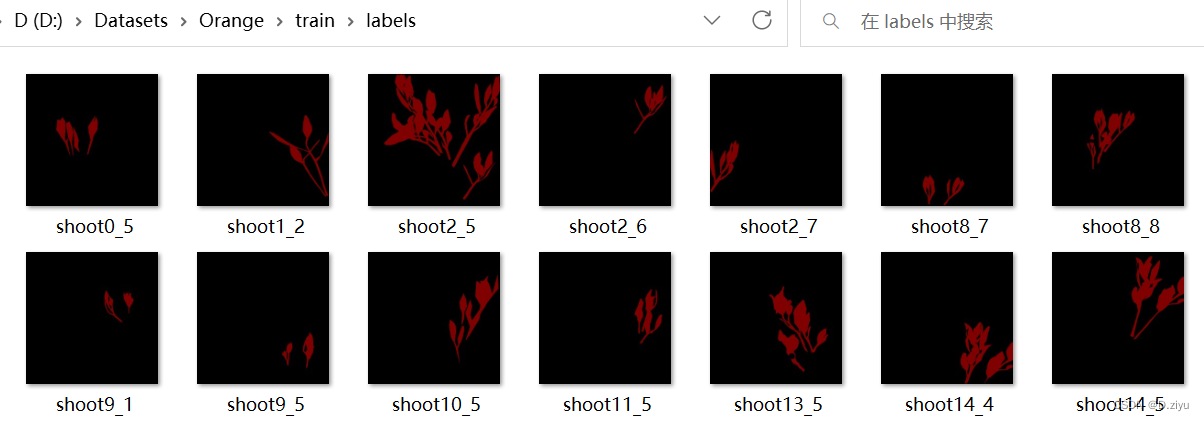
test中image有75张图片,train中image有225张图,对应json中的225个标注文件,是labelme导出的。训练:测试 遵循3:1原则。

图片分辨率为608*608; 观察文件名,均以shoot数字_数字命名,可推测原始拍摄为高清大图,第一个数字代表第几张大图,第二个数字代表从该大图中截取的第几张小图
标注导出
json格式的标注需要导出为像素图,导出方法很多,由于已知是labelme格式的文件,所以用该工具转化最方便。步骤如下
1.新建环境
之前其实已经在base安装过labelme库了,但就是找不到那个exe(转化要用),所以直接新建(推荐)一个虚拟环境,重新pip install
2.批量转化
找到该exe文件,路径大致如图
C:\ProgramData\miniconda3\envs\pyqt\Scripts\labelme_json_to_dataset.exe
接着运行如下代码,路径记得修改
import os
path = 'D:\Datasets\Orange\\train\json' # path为labelme标注后的.json文件存放的路径
json_file = os.listdir(path)
for file in json_file:
os.system("C:\ProgramData\miniconda3\envs\pyqt\Scripts\labelme_json_to_dataset.exe %s"% (path + '/' + file))
生成一个文件夹,for循环运行完是多个
其中四个文件
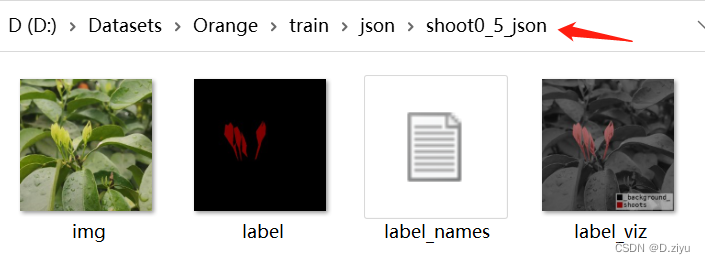
用代码将每个文件夹下的label以及label_viz按相应名字移走,结果如下
主要是要labels去训练,label_vizs就是看看
预实验
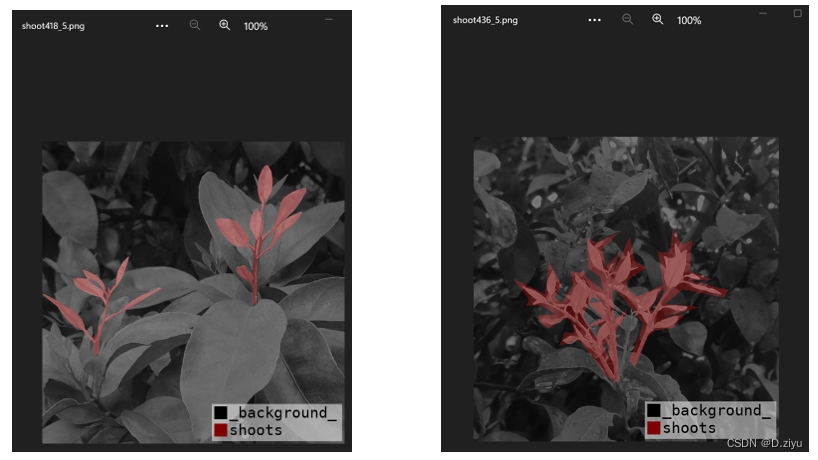
数据集标注质量不好,从436_5到526_3有53个样本标注较粗糙,疑似多人标注
左图右图差别较大
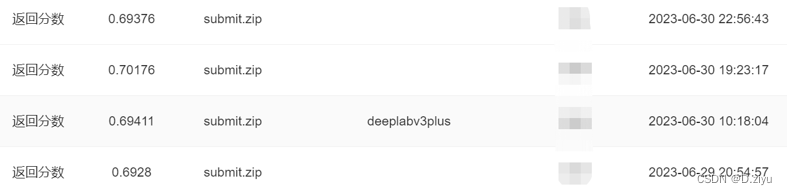
使用提供的base代码结果为0.67
提供的base代码

提交过程
预处理
一些基础的数据增强,减少颜色、位置、大小等影响。
模型改进
由于要经常换backbone,有个像工具包的环境会好很多,如paddle,mmseg等都可以。
陆陆续续用deeplabv3,deeplabv3+,fcn,pspnet等跑过,追求速度backbone都用的r50,效果一般,比base好个0.2-0.3,其中最好的是psp,精度70%,故后续选psp作为待改进网络
对数据做了少量增强augdata,精度涨了1%
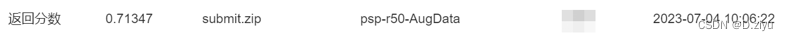
不相信deeplabv3系列干不过psp,还是在augdata上跑了这两个网络,对deeplabv3系列死心

Psp中加入eca,发现精度下降了

把损失函数换了一下,发现r50的基础上涨了点;一星期后把r50换r101,又稍微增强了数据集augdata2,精度涨至72.4%

后试图用transformer,训练了80K,训练精度是最高的98%,测试结果很惨,感觉它太准确了,训练数据较少,以至于过拟合了

试图用crf做后处理,跑通了,但结果最差,可能是要调参的问题,没时间调了放弃该做法

试图加入cbam机制,结果一般

做最后一次数据增强,一张图变13张图。加入se,精度涨了一点点,精度72.9%


用ocrnet,表现还可以

后处理
对已有的五种网络的结果进行投票融合,分别为psp,ocr,uper,deepv3系列
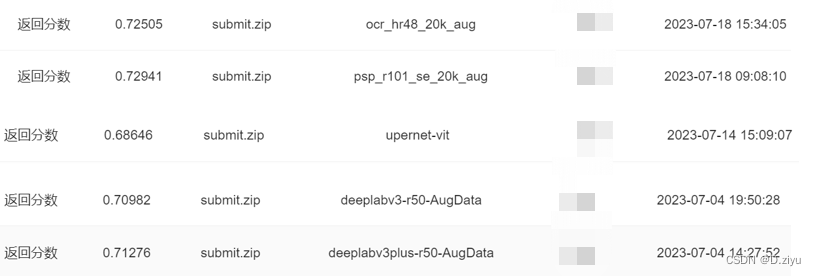
精度涨了1%,此时排名12

对之前标注不清楚的部分结果做平滑处理,即腐蚀膨胀操作,k_size=5。结果涨了2%,此时排名3
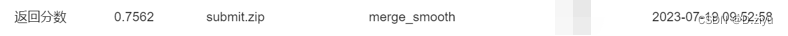
参数k_size=8,对这20张图平滑

结果涨了一点,实时排名1。初赛最终排名2

复赛提交了几次,卷不动+其他原因,弃了弃了。
总结
见识了更多的预处理方法,建模过程简单接触了transformer,简单了解后处理操作。更合理的调参有待学习。