一、说明
朋友们,大家好!现在我们学习了如何在Twitter数据上进行主题建模和情感分析,但我们还没有将这两种技术联系在一起。我们如何获得与每个主题相对应的情绪?在这篇文章中,我将向您展示进行基于主题的情绪分析的方法。让我们潜入!
二、准备数据
我们仍将使用我们通过废弃与卡塔尔世界杯相关的推文来准备的数据。如果您忘记了该怎么做,请查看此处。同样,我们将抽取 300 条推文用于演示目的。
import pandas as pd
import pickle
import requests
import random
with open('world_cup_tweets.pkl', 'rb') as f:
data = pickle.load(f)
tweets = data.Tweet_processed.to_list()
tweets = random.sample(tweets, 300)然后我们将模型和拥抱脸令牌存储在相应的变量中。我们将定义我们的功能:分析。如果您不知道如何创建自己的拥抱面孔令牌,请查看我在下一页中的上一篇文章。
model = "cardiffnlp/twitter-roberta-base-sentiment-latest"
hf_token = "YOUR OWN TOKEN"
API_URL = "https://api-inference.huggingface.co/models/" + model
headers = {"Authorization": "Bearer %s" % (hf_token)}
def analysis(data):
payload = dict(inputs=data, options=dict(wait_for_model=True))
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()三、情绪分析与扭曲
在此阶段之前,我们在进行情绪分析时遵循相同的步骤。从这里开始,我们的代码中将发生一些小的变化,因为我们将专注于获取每条推文的每个情绪概率分数。
# Following is the code for doing Topic Based Sentiment Analysis.
# Not only we need to get the higher score,
# we need to store the sentiment probability score for every tweet for further calculation.
import pandas as pd
tweets_analysis = []
for tweet in tweets:
try:
sentiment_result = analysis(tweet)[0]
sentiment_probabilities = {label['label']: label['score'] for label in sentiment_result}
tweets_analysis.append({'tweet': tweet, **sentiment_probabilities})
except Exception as e:
print(e) Python 中的语法用于解压缩字典。在这里,它用于使用字典解包将字典作为键值对添加到字典中。这将创建一个新字典,其中包含 中的键和键值对。**sentiment_probabilities{'tweet': tweet}tweetsentiment_probabilities
df = pd.DataFrame.from_records(tweets_analysis, columns=['tweet'] + list(sentiment_probabilities.keys()))
df = df.reset_index(drop=True)
df.head()
df.to_pickle('world_cup_tweets_sentiment_score.pkl') 我们可以用上面的代码创建一个新的数据框。在此代码中,从字典列表创建熊猫数据帧。该方法用于从字典列表创建数据帧,其中每个字典对应于数据帧中的一行。tweets_analysisfrom_records()
该参数指定数据帧的列名。第一列设置为 ,其余列使用该函数设置为字典的键。columns'tweet'sentiment_probabilitieslist()
然后,该方法用于重置数据帧的索引,从 0 开始并删除上一个索引。生成的数据帧将为每个推文提供一行,其中包含推文文本列和每个情绪标签的概率。reset_index()
让我们检查数据集的前几行。如果它看起来正确,不要忘记腌制以备后用。

四、使用 BERTopic 进行主题建模
现在我们将使用 BERTopic 进行主题建模。如果您需要更新该方法,请查看下面列出的我之前的帖子。
texts=df['tweet']
from bertopic import BERTopic
topic_model = BERTopic(language="english", calculate_probabilities=True, verbose=True)
topics, probs = topic_model.fit_transform(texts)在这里,我们将获得每条推文及其相应的主题。然后我们将结果存储在数据框中。
df2 = pd.DataFrame(topic_model.get_document_info(texts))
df2.head()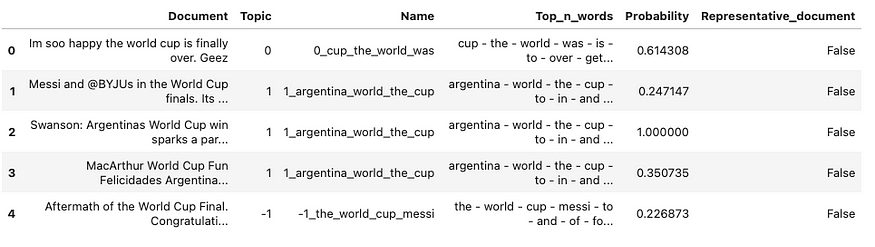
五、将情绪与主题合并
正如我们所看到的,相同的推文存储在 df2 中的列名“文档”和 df 中的列名“tweet”下。我们可以先合并两个数据框,然后从两个数据框中删除一列。
df_merge = pd.merge(df,df2, how='inner', left_on = 'tweet', right_on = 'Document')
df_merge = df_merge.drop('Document', axis=1)
df_merge.head()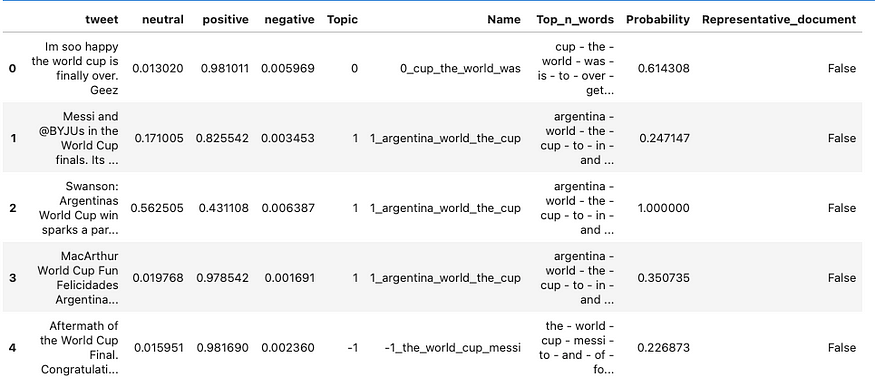
我们可能不会得到相同的结果,因为采样过程是随机完成的,但数据结构应该是相同的。请仔细检查您的结果。然后,我们将创建一个新的数据框,用于存储每个主题及其相应的情绪概率分数。
df_topic_sentiment = df_merge.groupby('Topic').agg({'neutral': 'mean', 'positive': 'mean', 'negative': 'mean'})
df_topic_sentiment = df_topic_sentiment.reset_index()
df_topic_sentiment 在此代码中,通过使用该方法按现有数据帧的值对行进行分组来创建新的数据帧。df_topic_sentimentdf_mergeTopicgroupby()
然后,该方法用于将聚合函数应用于每组行。在这种情况下,使用字典语法计算 、 和列的平均值。这将创建一个新的数据帧,每个唯一 ,其中每行显示相应主题中所有推文中每个情绪标签的平均值。agg()neutralpositivenegative{'neutral': 'mean', 'positive': 'mean', 'negative': 'mean'}Topic
最后,该方法用于重置数据帧的索引,这会将值从索引移动到常规列。生成的数据帧将具有每个唯一 的一行,其中 、 、 和 的列显示每个主题中每个标签的平均情绪值。reset_index()TopicTopicTopicneutralpositivenegative

为了更好地了解每个主题代表什么,我们可以获取每个主题的频率并将其存储在数据框中。然后使用公共列“主题”将df_topic_sentiment合并到它上面。
freq = topic_model.get_topic_info()
df_freq = pd.DataFrame(freq)
df_new = pd.merge (df_freq, df_topic_sentiment, how = 'inner', on = 'Topic' )
df_new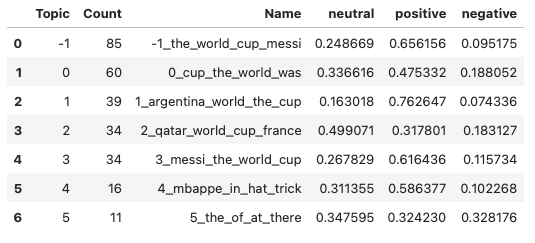
我们可以添加一个得分最高的新列,然后定义一个函数来显示情绪标签,这是最高分对应的标签。
# add new column with the highest score
score_cols = ['neutral', 'positive', 'negative']
df_new['highest_score'] = df_new[score_cols].max(axis=1)
# define function to calculate sentiment label
def get_sentiment(row):
if row['positive'] == row['highest_score']:
return 'positive'
elif row['negative'] == row['highest_score']:
return 'negative'
else:
return 'neutral'
# apply function to each row and create new column
df_new['sentiment'] = df_new.apply(get_sentiment, axis=1)
df_new
在我们抽样的 300 条推文中,我们可以得出结论,大多数主题都传达了积极的情绪。
六、总结
在这篇文章中,我向您展示了如何进行基于主题的情绪分析。此功能尚未包含在BERTopic库或Hugging Face的情感分析模型中。通过一些数据操作,我们使之成为可能。