数据库相关链接:
数据库基础操作--增删改查:http://t.csdn.cn/189CF
数据库--数据类型:http://t.csdn.cn/NnBsY
数据库--SQL关键字的执行顺序: http://t.csdn.cn/MoJ4i
一、什么是范式?
范式是数据库设计时遵循的一种规范,不同的规范要求遵循不同的范式。
最常用的三大范式
第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列)
第二范式(2NF):满足第一范式;且不存在部分依赖,即非主属性必须完全依赖于主属性。(主属性即主键;完全依赖是针对于联合主键的情况,非主键列不能只依赖于主键的一部分)
第三范式(3NF):满足第二范式;且不存在传递依赖,即非主属性不能与非主属性之间有依赖关系,非主属性必须直接依赖于主属性,不能间接依赖主属性。(A -> B, B ->C, A -> C)
举例说明3NF:
1NF
属性不可再分,即表中的每个列都不可以再进行拆分。
如下学生信息表(student):
id、name(姓名)、sex_code(性别代号)、sex_desc(性别描述)、contact(联系方式)
primary key(id)
| id | name | sex_code | sex_desc | contact |
|---|---|---|---|---|
| 001 | 张三 | 0 | 男 | 17835201234_山西省运城市xx村 |
| 002 | 李四 | 0 | 男 | 17735204567_山西省吕梁市yy村 |
| 003 | 王五 | 1 | 女 | 18835207890_山西省太原市zz村 |
如果在查询学生表时经常用到学生的电话号,则应该将联系方式(contact)这一列分为电话号(phone)和地址(address)两列,这样才符合第一范式。
修改使表满足1NF后:
| id | name | sex_code | sex_desc | phone | address |
|---|---|---|---|---|---|
| 001 | 张三 | 0 | 男 | 17835201234 | 山西省运城市xx村 |
| 002 | 李四 | 0 | 男 | 17735204567 | 山西省吕梁市yy村 |
| 003 | 王五 | 1 | 女 | 18835207890 | 山西省太原市zz村 |
判断表是否符合第一范式,列是否可以再分,得看需求,如果将电话号和地址分开才能满足查询等需求时,那之前的表设计就是不满足1NF的,如果电话号和地址拼接作为一个字段也可以满足查询、存储等需求时,那它就满足1NF。
2NF
在满足1NF的前提下,表中不存在部分依赖,非主键列要完全依赖于主键。(主要是说在联合主键的情况下,非主键列不能只依赖于主键的一部分)
如下学生成绩表(score):
stu_id(学生id)、kc_id(课程id)、score(分数)、kc_name(课程名)
primary key(stu_id, kc_id)
| stu_id | kc_id | score | kc_name |
|---|---|---|---|
| 001 | 1011 | 85 | 高数3-1 |
| 001 | 1022 | 79 | 计算机组成原理 |
| 002 | 1011 | 59.9 | 高数3-1 |
表中主键为stu_id和kc_id组成的联合主键。满足1NF;非主键列score完全依赖于主键,stu_id和kc_id两个值才能决定score的值;而kc_name只依赖于kc_id,与stu_id没有依赖关系,它不完全依赖于主键,只依赖于主键的一部分,不符合2NF。
修改使表满足2NF后:
成绩表(score) primary key(stu_id)
| stu_id | kc_id | score |
|---|---|---|
| 001 | 1011 | 85 |
| 001 | 1022 | 79 |
| 002 | 1011 | 59.9 |
课程表(kc) primary key(kc_id)
| kc_id | kc_name |
|---|---|
| 1011 | 高数3-1 |
| 1022 | 计算机组成原理 |
将原来的成绩表(score)拆分为成绩表(score)和课程表(kc),而且两个表都符合2NF。
3NF:
在满足2NF的前提下,不存在传递依赖。(A -> B, B -> C, A->C)
如下学生信息表(student):
primary key(id)
| id | name | sex_code | sex_desc | phone | address |
|---|---|---|---|---|---|
| 001 | 张三 | 0 | 男 | 17835201234 | 山西省运城市xx村 |
| 002 | 李四 | 0 | 男 | 17735204567 | 山西省吕梁市yy村 |
| 003 | 王五 | 1 | 女 | 18835207890 | 山西省太原市zz村 |
表中sex_desc依赖于sex_code,而sex_code依赖于id(主键),从而推出sex_desc依赖于id(主键);sex_desc不直接依赖于主键,而是通过依赖于非主键列而依赖于主键,属于传递依赖,不符合3NF。
修改表使满足3NF后:
学生表(student) primary key(id)
| id | name | sex_code | phone | address |
|---|---|---|---|---|
| 001 | 张三 | 0 | 17835201234 | 山西省运城市xx村 |
| 002 | 李四 | 0 | 17735204567 | 山西省吕梁市yy村 |
| 003 | 王五 | 1 | 18835207890 | 山西省太原市zz村 |
性别代码表(sexcode) primary key(sex_code)
| sex_code | sex_desc |
|---|---|
| 0 | 男 |
| 1 | 女 |
将原来的student表进行拆分后,两个表都满足3NF。
什么样的表越容易符合3NF?
非主键列越少的表。(1NF强调列不可再分;2NF和3NF强调非主属性列和主属性列之间的关系)
如代码表(sexcode),非主键列只有一个sex_desc;
或者将学生表的主键设计为primary key(id,name,sex_code,phone),这样非主键列只有address,更容易符合3NF。
二、多表关系
在进行数据库表结构的设计时,会根据业务的需求和业务模块之间的关系,分析设计表结构,由于业务之间相互关联,所以各个表结构之间也存在各种联系
表与表之间的联系:
1.一对多(多对一)
2.多对多
3.一对一
一对多(多对一)
例如,一个员工对应一个部门,一个部门可以对应多个员工
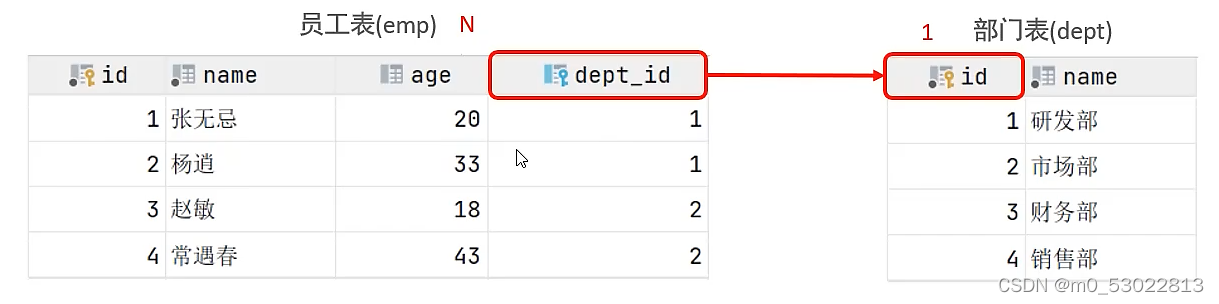
一般在多的一方创建外键,指向一的那一方
员工与部门,在员工表上设置外键,指向部门表
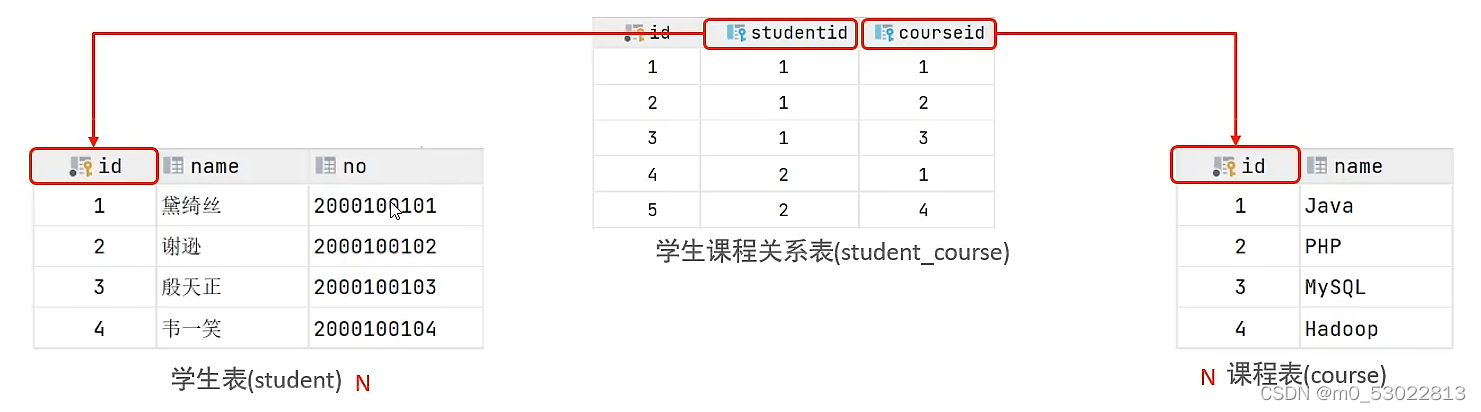
多对多
例如,一个学生可以选修多门课程,一个课程可以被多名学生选修
一般会建立第三张表,至少包含两个外键,分别指向两张表的主键
一对一
例如,用户和自己的学历信息的关系,一个人只对应一条学历信息
可以在任意一方加入外键,关联另一方的主键,并且设置外键为唯一(unique)
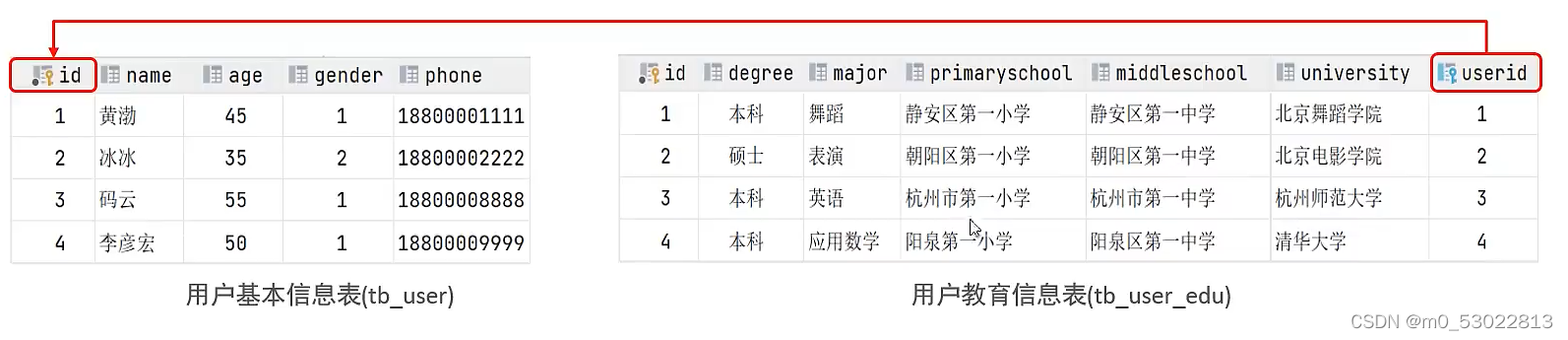
注:可以放在一张表中,但是对其进行拆分,一张表放基础信息,另一张表放详情,可以提升操作效率
三、多表查询
概述:
从多张表中查询数据
笛卡尔积:
笛卡尔积为两个集合(两张表)中的每条数据进行两两组合的结果
在多表查询时会产生笛卡尔积,要通过添加条件消除笛卡尔积
dept表:
emp表:

查询产生笛卡尔积的结果:
select * from emp, dept ;
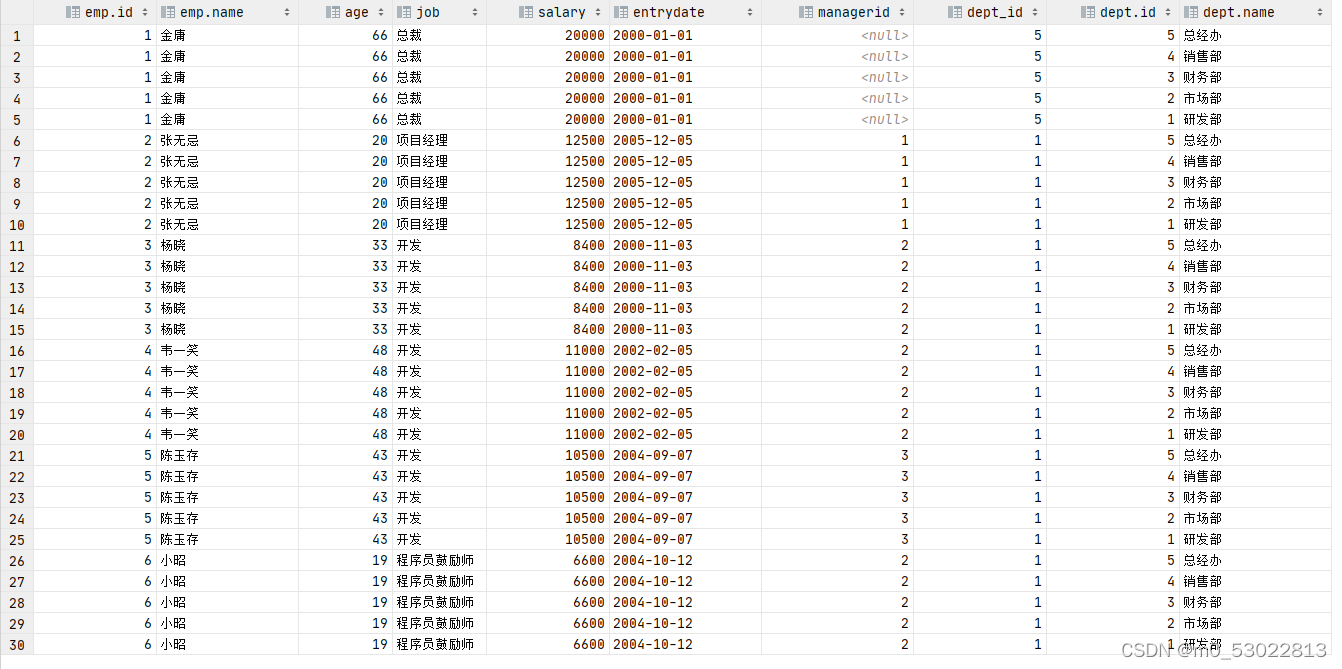
消除笛卡尔积(添加条件):
select * from emp, dept where emp.dept_id=dept.id;

多表查询的分类
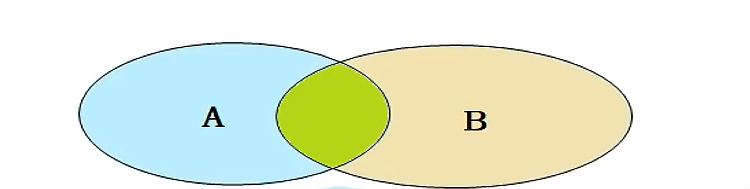
1.连接查询:
内连接:
相当于查询AB的交集部分
外连接:
左外连接:
查询A的所有数据,同时拼接上B对应的数据
右外连接:
查询B的所有数据,同时拼接上A中对应的数据
自连接:
表与自身连接查询
自连接必须给表取别名
2.子查询
数据准备
部门表:
create table dept (
id int auto_increment primary key comment 'id',
name varchar(50) not null comment '部门名称'
) comment '部门表';
insert into dept (id, name)
values (1, '研发部'),
(2, '市场部'),
(3, '财务部'),
(4, '销售部'),
(5, '总经办'),
(6, '人事部');
员工表:
create table emp(
id int auto_increment primary key ,
name varchar(50) not null ,
age int,
job varchar(20) comment '职位',
salary int ,
entrydate date comment '入职时间',
managerid int comment '直属领导id',
dept_id int comment '所在部门id'
) comment '员工表';
insert into emp
values ( 1, '金庸', 66, '总裁', 20000, '2000-01-01', null, 5 ),
( 2, '张无忌', 20, '项目经理', 12500, '2005-12-05', 1, 1 ),
( 3, '杨晓', 33, '开发', 8400, '2000-11-03', 2, 1 ),
( 4, '韦一笑', 48, '开发', 11000, '2002-02-05', 2, 1 ),
( 5, '陈玉存', 43, '开发', 10500, '2004-09-07', 3, 1 ),
( 6, '小昭', 19, '程序员鼓励师', 6600, '2004-10-12', 2, 1 ),
( 7, '灭绝', 60, '财务总监', 8500, '2002-09-12', 1, 3 ),
( 8, '周芷若', 19, '会计', 48000, '2006-06-02', 7, 3 ),
( 9, '丁敏君', 23, '出纳', 5250, '2009-05-13', 7, 3 ),
( 10, '赵敏', 20, '市场部总监', 12500, '2004-10-12', 1, 2 ),
( 11, '鹿杖客', 56, '职员', 3750, '2006-10-03', 10, 2 ),
( 12, '何碧文', 19, '职员', 3750, '2007-05-09', 10, 2 ),
( 13, '东方白', 19, '职员', 5500, '2009-02-12', 10, 2 ),
( 14, '张三丰', 88, '销售总监', 14000, '2004-10-12', 1, 4 ),
( 15, '鱼梁洲', 38, '销售', 4600, '2004-10-12', 14, 4 ),
( 16, '宋远桥', 40, '销售', 4600, '2004-10-12', 14, 4 ),
( 17, '陈友谅', 42, null, 2000, '2011-10-12', 1, null );
内连接
语法:
# 隐式内连接
select 字段列表 from 表1,表2 where 条件;
# 显示内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件;
内连接查询的是两张表交集的部分
# 查询每一个员工的姓名及关联的部门的名称
select emp.name, dept.name from emp, dept where emp.dept_id=dept.id;
select emp.name, dept.name from emp inner join dept on emp.dept_id = dept.id;外连接
语法:
# 左外连接
select 字段列表 from 表1 left [outer] join 表2 on 条件;
# 右外连接
select 字段列表 from 表1 right [outer] join 表2 on 条件;
左外连接相当于查询表1的所有数据包含表1和表2交集的部分数据
右外连接相当于查询表2的所有数据包含表1和表2交集部分的数据
# 查询emp表的所有数据,和应于的部门信息(左)
select emp.*, dept.* from emp left outer join dept on emp.dept_id = dept.id;
# 查询dept表的所有数据,和对于的员工信息(右)
select dept.*, emp.* from emp right outer join dept on emp.dept_id = dept.id;
左外连接和右外连接可以进行相互转化
自连接
语法:
select 字段列表 from 表a 别名a join 表a 别名b on 条件;
自链接查询可以是内连接查询也可以是外连接查询
# 查询员工及其所属领导的名字
# 自连接可以看成两张一样的表进行连接查询
select a.name, b.name from emp a join emp b on a.managerid=b.id;
联合查询
union、union all
对于联合查询就是把多次查询的结果合并起来,形成一个新的查询结果集
语法:
select 字段列表 from 表a
union [all]
select 字段列表 from 表b
# 将薪资低于5000的员工和年龄大于50的员工查询出来
select * from emp where salary>5000
union all
select * from emp where age>50;
# 没有all重复满足条件的只出现一次
# 将薪资低于5000的员工和年龄大于50的员工查询出来
select * from emp where salary>5000
union
select * from emp where age>50;
对于联合查询的多张表的列数必须保持一致,字段类型也要保持一致
union all会将全部的数据直接合并在一起,union会对合并之后的数据去重
子查询
概念:SQL语句中嵌套select语句为嵌套查询,又称子查询select * from 表1 where 字段=(select 字段 from 表2);
子查询外的语句可以是insert、update、delete、select中的一个
根据子查询的结构不同,分为:
标量子查询:子查询的结果为单个值
列子查询:子查询的结果为一列
行子查询:子查询的结果为一行
表子查询:子查询的结果为多行多列
根据子查询的位置,分为:
where之后
from之后
select之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询
常用符号:=、<>、>、>=、<、<=
# 根据销售部门的id查询员工信息
# 先分开查询
# 查询销售部门的id
select id from dept where name='销售部'; #id为4
# 查询销售部门中员工的信息
select * from emp where dept_id=4;
# 合并为一个查询
select * from emp where dept_id=(select dept.id from dept where dept.name='销售部' );
列子查询 in any some all
子查询的结果为一列(可以是多行)的,这种子查询为列子查询
常用操作符:

# 列子查询
# 查询销售部和市场部的所有员工信息
# 查询销售部和市场部的id
select id from dept where name='销售部' or name='市场部'; #id为2 4
# 查询两个部门的所有员工
select * from emp where dept_id in (2,4);
# 合并
select * from emp where dept_id in (select id from dept where name='销售部' or name='市场部');
any(英语:任意的)的使用:
1.查询id>1的所有记录
# 查询id>1的所有记录
SELECT bookID FROM books WHERE bookID>1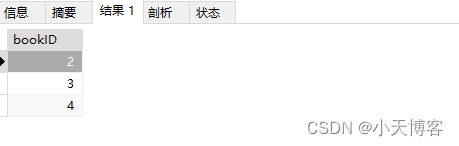
2. 查询id 大于(查询id>1的所有记录) 中的任意一个数据
SELECT * FROM `books` where bookID > ANY(SELECT bookID FROM books WHERE bookID>1) 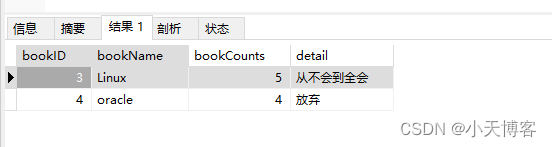
解释:
1步骤子查询中查到结果是id = 2,3,4;
2步骤查询id,只要大于2,3,4中任意一个即可;
总结:可以理解为“>”大于号时子查询结果中取最小值,“<”小于号时子查询结果中取最大值
行子查询
子查询返回的结果是一行(可以是多列),这种子查询为行子查询
常用操作符:=、<>、in、not in
# 查询与张无忌的薪资及直属领导相同的员工信息
# 查询张无忌的薪资和直属领导
select salary, managerid from emp where name='张无忌';
# 查询与张无忌的薪资及直属领导相同的员工信息
select * from emp where (salary,managerid)=(select salary, managerid from emp where name='张无忌');
表子查询
子查询的结果是多行多列这种查询为表子查询
常用操作符:in
# 查询与鹿杖客和宋远桥的职位和薪资相同的员工信息
select * from emp where (job, salary) in ( select job, salary from emp where name in ('鹿杖客', '宋远桥'));
表子查询的子表作为临时表
# 查询入职日期是’2006-01-01‘之后的员工信息和部门信息
# 先查询出入职在’2006-01-01‘之后员工的所有信息
# 与部门表左连接
select e.*, dept.* from (select * from emp where entrydate>'2006-01-01') e left outer join dept on e.dept_id=dept.id;
四、函数sql语法
1. 常见聚合函数
count(列名) max(列名)//求列中的最大值; min (列名)//求列中的最小值; avg(列名) //平均分 sum(列名) //总分
使用格式:
select count(列名),不统计为null的值; select count ( id ) 总人数 from stu1
2. 其他函数
字符串函数、数学函数、日期函数
字符串函数
1,字符串函数length select length(‘字符串’)[ from dual ] //虚表,为让语法更加清晰;
2,字符个数char_length select length(‘字符串’),char_length(‘哈哈’)
3,大小写转换upper&lower select upper(‘HelloMysql’),lower (‘HelloMysql’)
4,截取字符串subString //没有第0位; select subString(‘你看看从哪里截取,从后面截取’,8)
5,部分截取字符串subString subString (字符串,开始位置,结束位置)
6,替换replace select replace(‘我看看傻帽’,‘傻帽’,‘**’)
数学函数
1,四舍五入round select round( 888.25 ), round( 888.78 )
2,保留小数位round select round(888.235 ,2) //参数2是小数位个数;
3,天花板函数ceil ceil( 88.52 ) //比数字大的 最小整数;
4,地板函数floor floor(88.53) //比数字小的最大整数;
5,取余 select mod( 10,3 )
日期函数
1,将字符串转日期格式 select STR_TO_DATE( ‘2023-02-02’,‘%Y-%m-%d’ )
2,将日期格式转换成字符串 select now( ) //获取当前时间; select date_format( now(),‘%Y-%m-%d’) //获取当前日期;
字符串的拼接concat
eg: select concat( name,address ) from stu3 //合并字符串;
select math+English 总分 from stu3 //做相加运算;
select 100+‘100’ //数字+内容是数字的字符串;
select ‘abc’+ 'aa' //字符串使用+,得到0; select ‘abc’+null //字符串+null ,得到null;
相加运算
//数字的话,是数字的和; //数字+内容是数字的字符串=数字;反过来也可以相加; //字符串+字符串=0; //字符串+null =null; select math+english 总分 from stu3
分组查询group by
对一列数据进行分组,相同的内容分为一组,通常与聚合函数一起使用,完成统计工作;
1,语法格式
select 字段1,字段2 from 表名 [条件] group by 分组字段 [having 条件(对于分组结果的筛选) ] [ order by ];
2,案例
查询男女各多少人 select count(*/id) from stu3 group by sex;
查询年龄大于25岁的人,按照性别分组,统计每组的人数 有条件限制时,where在group by前面; select sex 性别,count(*) from stu3 where age>25 group by sex;
查询年龄大于25岁的人,按照性别分组,统计每组的人数,并只显示性别大于2的数据; select sex 性别,count() from stu3 where age>25 group by sex having count()>2;
分组原理: 对原始表进行抽取,抽取到新的表(临时表),created_tem_tables;
分页查询limit
limit 起始行数从0开始,显示的条数; 显示前三条数据:select * from stu3 limit 0,3; 显示第二页的三条数据:select from stu3 limit 3,3;
总结规律: 第pageSize页数,显示的条数num; limit (pageSize-1)num+num;
博主总结不易,点个赞不过分吧,好耶!






![linux学习(进程替换)[10]](https://img-blog.csdnimg.cn/d5d05c655ebe461180dd6dd394fc0b98.png)