Pandas:表格处理
- 🌟🌟Pandas三种数据类型
- ✨✨Series数据结构
- ✨✨ DataFrame数据结构
- 🌙🌙DataFrame数据的选取
- 🌕🌕DataFrame的构建
- 🌕🌕选取多行
- 🌕🌕选取某一列
- 🌕🌕选取多列
- 🌕🌕单条件过滤
- 🌕🌕多条件过滤
- 🌙🌙获取列名和行名
- 🌙🌙观察DataFrame的内容
- ✨✨变量的变换
- ✨✨表格的拼接
- ✨✨ 表格的分组操作
- 🌙🌙按照分组求均值、求和
- ✨✨表格的拼接
🌟🌟Pandas三种数据类型
Pandas提供了三种数据类型,分别是
Series、DataFrame和Panel。Series用于保存一维数据,DataFrame用于保存二维数据,Panel用于保存三维数据或者可变维数据。平时的表格处理数据分析最常用的数据类型是Series和DataFrame,Panel较少用到。
✨✨Series数据结构
Series本质上是一个含有索引的
一维数组,其包含一个左侧自动生成的index和右侧的values值,分别使用s.index和s.values进行查看。
下面举个例子:
下面我们导入数据:
import pandas as pd
s=pd.read_excel("D:\A_data\Data_Series.xlsx")
s
运行结果如下:

其中,左侧这一列就是索引列,下面我们分别打印s.index和s.values

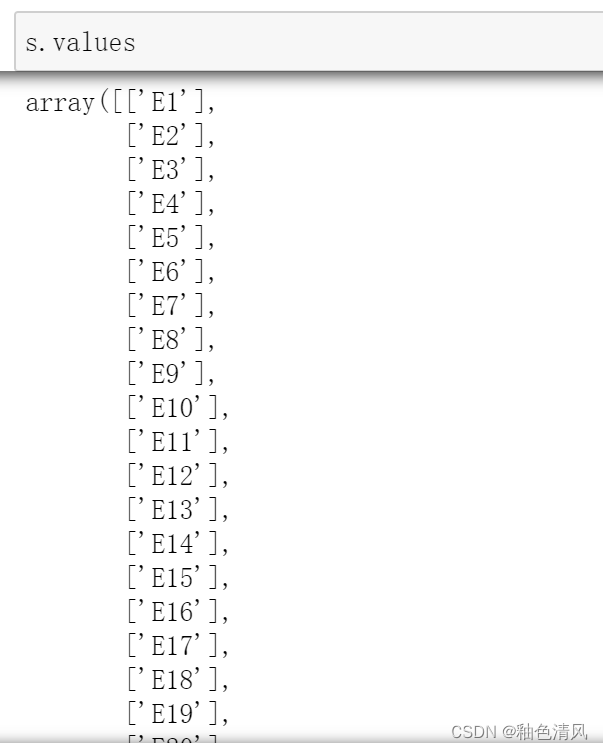
index返回一个index对象,而values返回一个array。
✨✨ DataFrame数据结构
DataFrame(数据框)类似于Excel电子表格,也与R语言中DataFrame的数据结构类似。
🌙🌙DataFrame数据的选取
🌕🌕DataFrame的构建
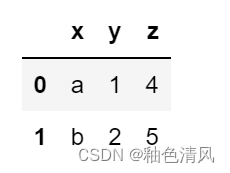
import pandas as pd
df=pd.DataFrame({'x':['a','b','c'],'y':[1,2,3],'z':[4,5,6]})
df

🌕🌕选取多行
方法一:
df.iloc[[0,1],:]
df.iloc[[0,2],:]
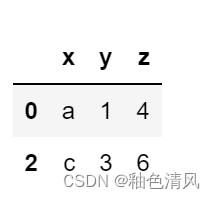
方法二:
df.loc[['0','2'],:]
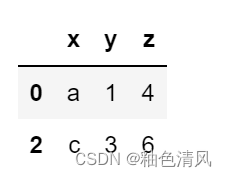
🌕🌕选取某一列
df.y
df['y']
df.loc[:,['y']]
df.iloc[:,[1]]
🌕🌕选取多列
方法一:
df.iloc[:,[1,2]]
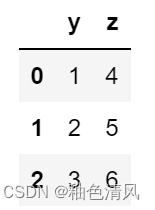
方法二:
df.loc[:,['x','y']]
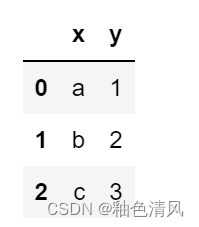
方法三:
df[['x','y']]
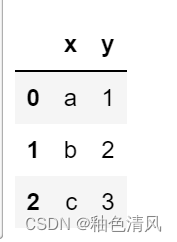
🌕🌕单条件过滤
df[df.z>=5]
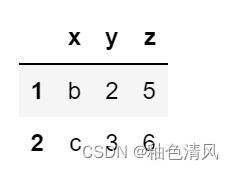
🌕🌕多条件过滤
df[(df.z>=4)&(df.z<=5)]
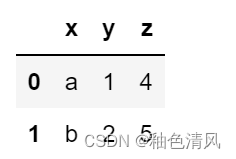
🌙🌙获取列名和行名
df.columns #获取列名
df.index #获取行名
🌙🌙观察DataFrame的内容
df.info() #打印属性信息
df.head()# 查看前五行的数据
df.tail()#查看后五行的数据
✨✨变量的变换
有时候,我们需要对DataFrame某列的每个元素都进行运算处理,从而产生并
添加新的列。
我么可以直接对DataFrame的列进行加减乘除某个数,产生新的列:
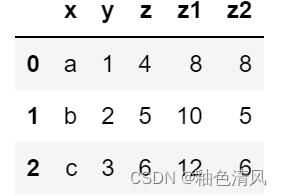
df['z1']=df['z']*2
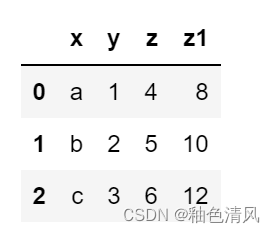
apply、applymap和map方法都可以向对象中的数据传递函数,主要区别如下:
🌙apply的操作对象是DataFrame的某一列(axis=1)或者某一行(axis=0)
🌙applymap的操作对象是元素极,作用于每个DataFrame的每个数据
🌙map的操作对象也是元素极,但其是对Series的每个数据调用一次函数
使用apply方法,结合lambda表达式,可以为原数据框添加新的列:
df['z2']=df.apply(lambda x:x['z']*2 if x['z']==4 else x['z'],axis=1)
✨✨表格的拼接
有时候,我们需要在已有数据框的基础上添加新的行或者列,或者横向或纵向的表格。此时我们需要使用pd.concat函数或者append函数实现该功能。
✨✨ 表格的分组操作
DataFrame往往存在某列包含
多个类别的数据,例如上次博客中的经典的葡萄酒数据集。我们以此为例。
import pandas as pd
file_path="D:\A_data\Data_wine数据\wine.xlsx"
df=pd.read_excel(file_path)
df
使用 groupby()函数进行分组操作:
df1=df.groupby('label')
df
分组之后的结果与原来数据一样,这是因为在类别标签‘label’这一列,原来的数据就是按照0、1、2三种类别的顺序排下来的。
🌙🌙按照分组求均值、求和
求均值:
df2=df.groupby('label').mean()
df2

当然了,也可以只打出我们想要的某一列的均值:
df2=df.groupby('label').ash.mean()
df2

求和:
对于这个葡萄酒数据集可能求和操作并没有意义,但在此只是练习:
df2=df.groupby('label').sum()
df2

求方差:
df2=df.groupby('label').std()
df2

✨✨表格的拼接
有时候,我们需要在已有数据框的基础上添加新的行或者列,或者横向或纵向的表格。此时我们需要使用pd.concat函数或者append函数实现该功能。
其中,axis=0表示沿纵轴连接。axis=1表示沿横轴连接。
下面我们再举一个例子:
(我觉得2020年国赛数学建模国赛C题很不错)
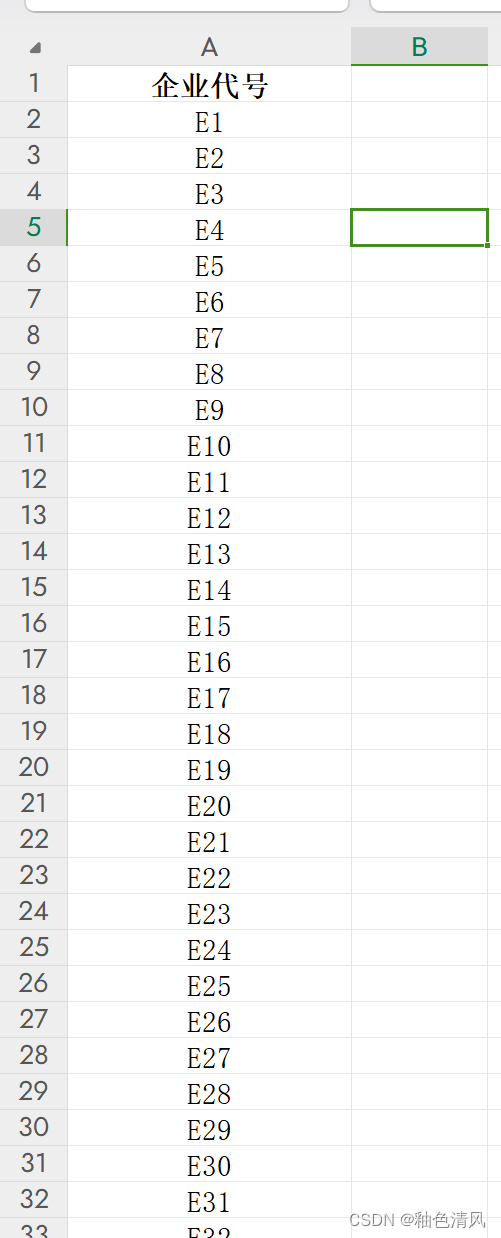
首先,我们可以看一下,这是一个多sheet Excel:
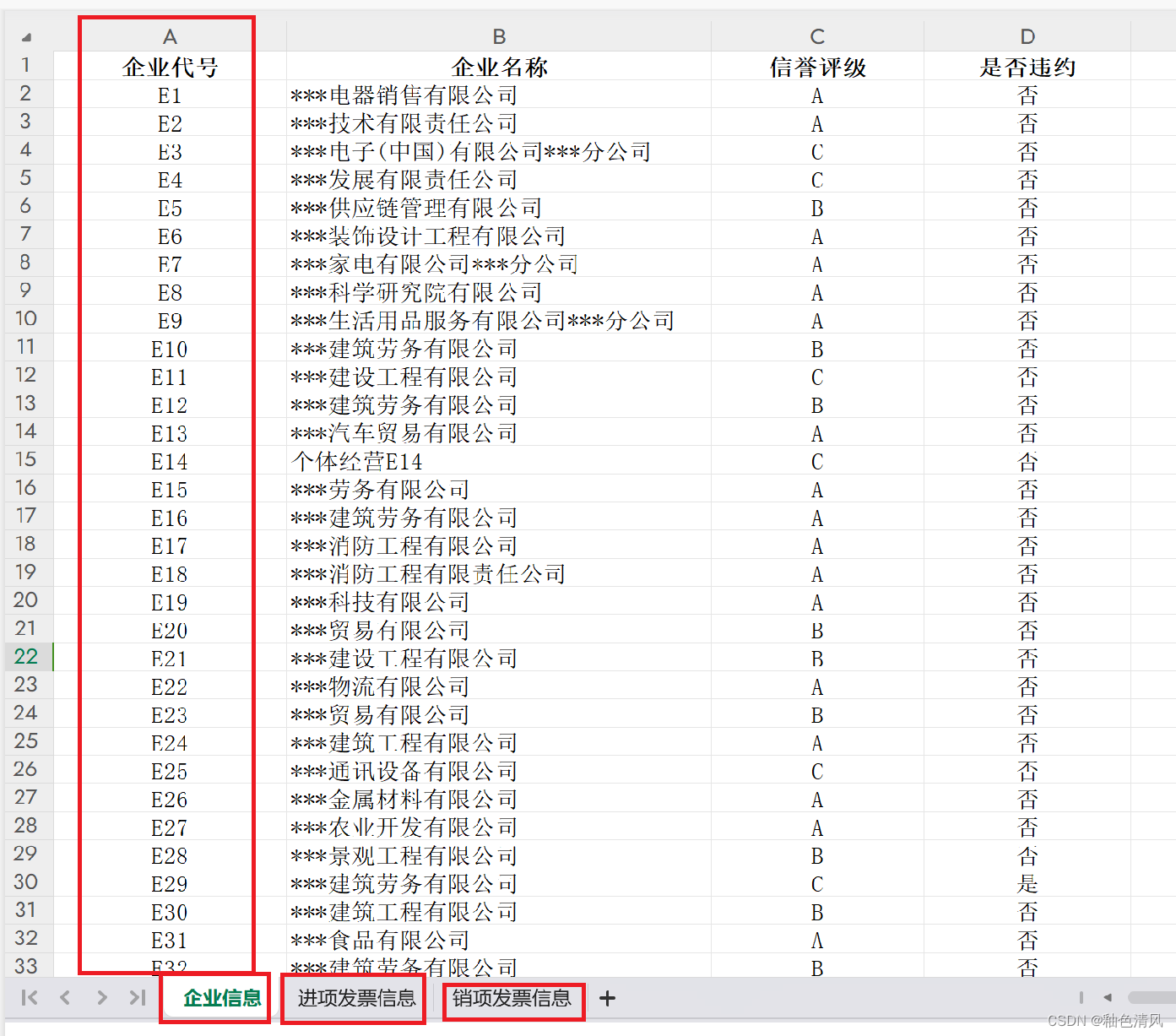
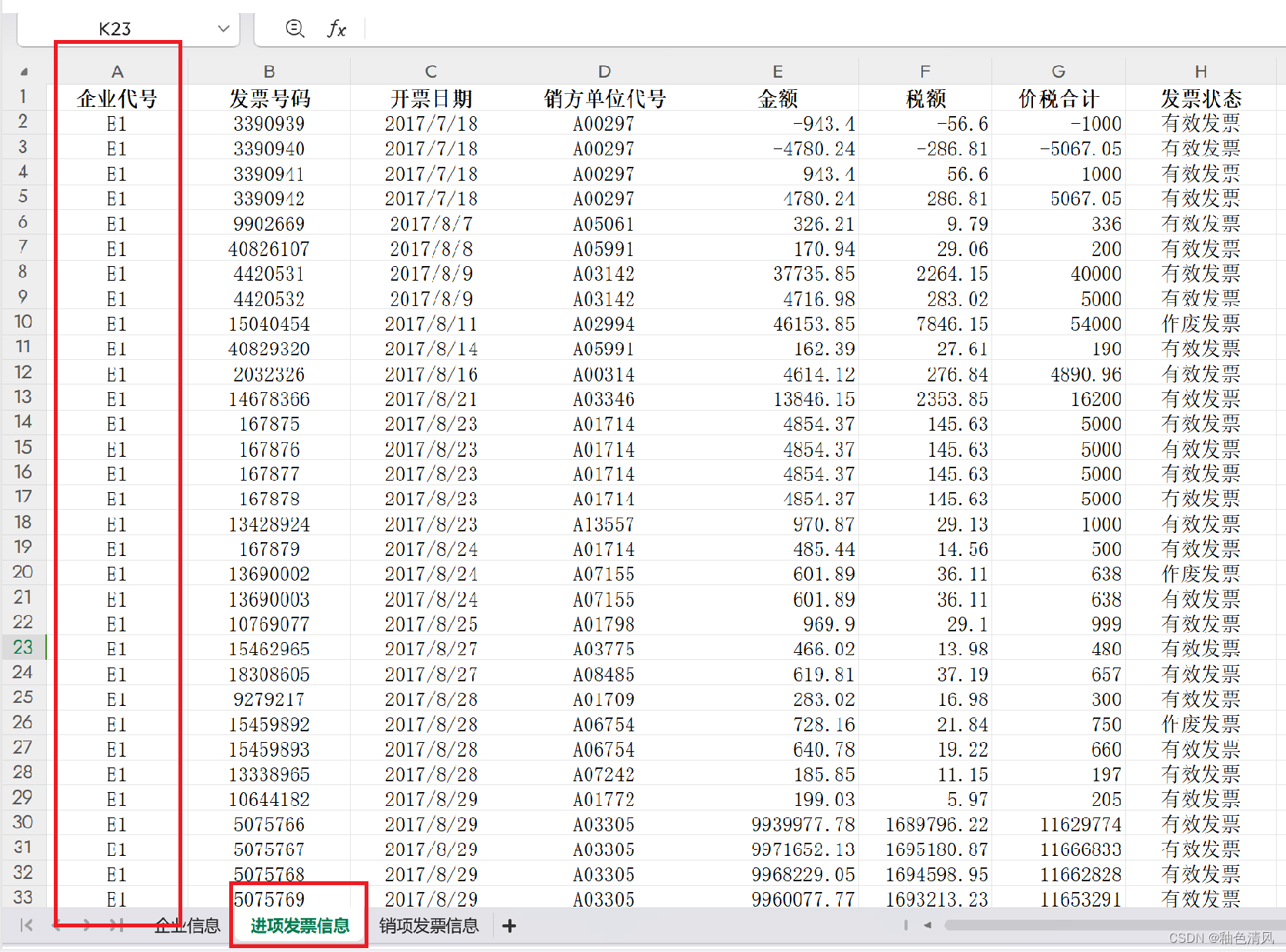
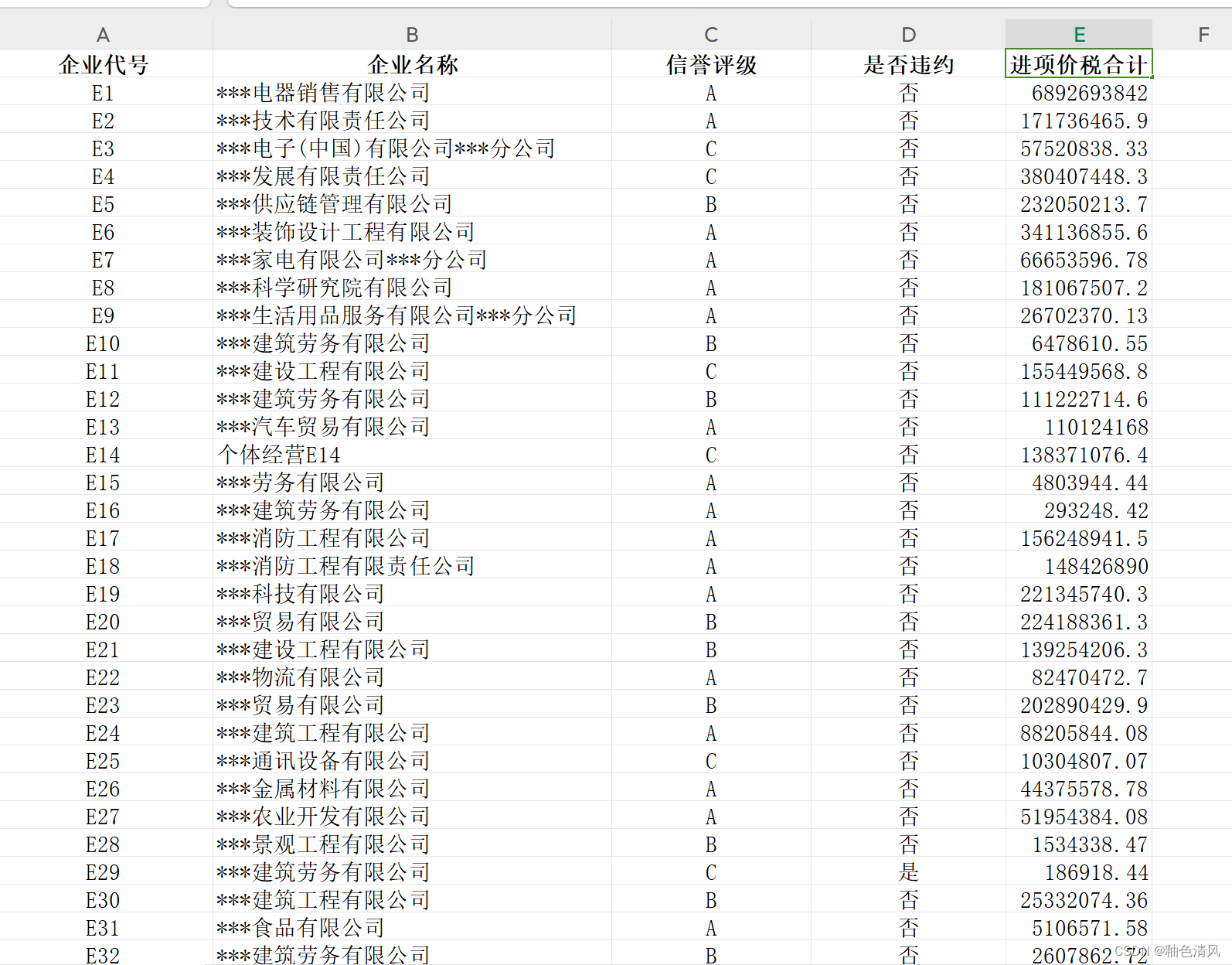
而且,sheet2 、sheet3企业代号就是sheet1中企业的所有发票信息,也就是说一个企业就有很多发票号码。
我们需要整合sheet2,以及sheet3中的信息,将一个企业的某一个指标进行计算,然后希望补到heet1中,形成一个更宏观的表格。
分析指标:总进项价税额:是指企业在一段时间内购进产品的价值总和,该值越高说明企业的生产和经营规模就越大,可以作为衡量企业生产规模大小的有效指标。
我希望根据sheet2算出这个指标,然后添加到sheet1中。
首先导入数据。
import pandas as pd
file_path="D:\A_data\Data.2020.C\附件1:123家有信贷记录企业的相关数据.xlsx"
df=pd.read_excel(file_path,sheet_name=None)
df
这里设置sheet_name=None,会将所有的sheet都整合在df中。
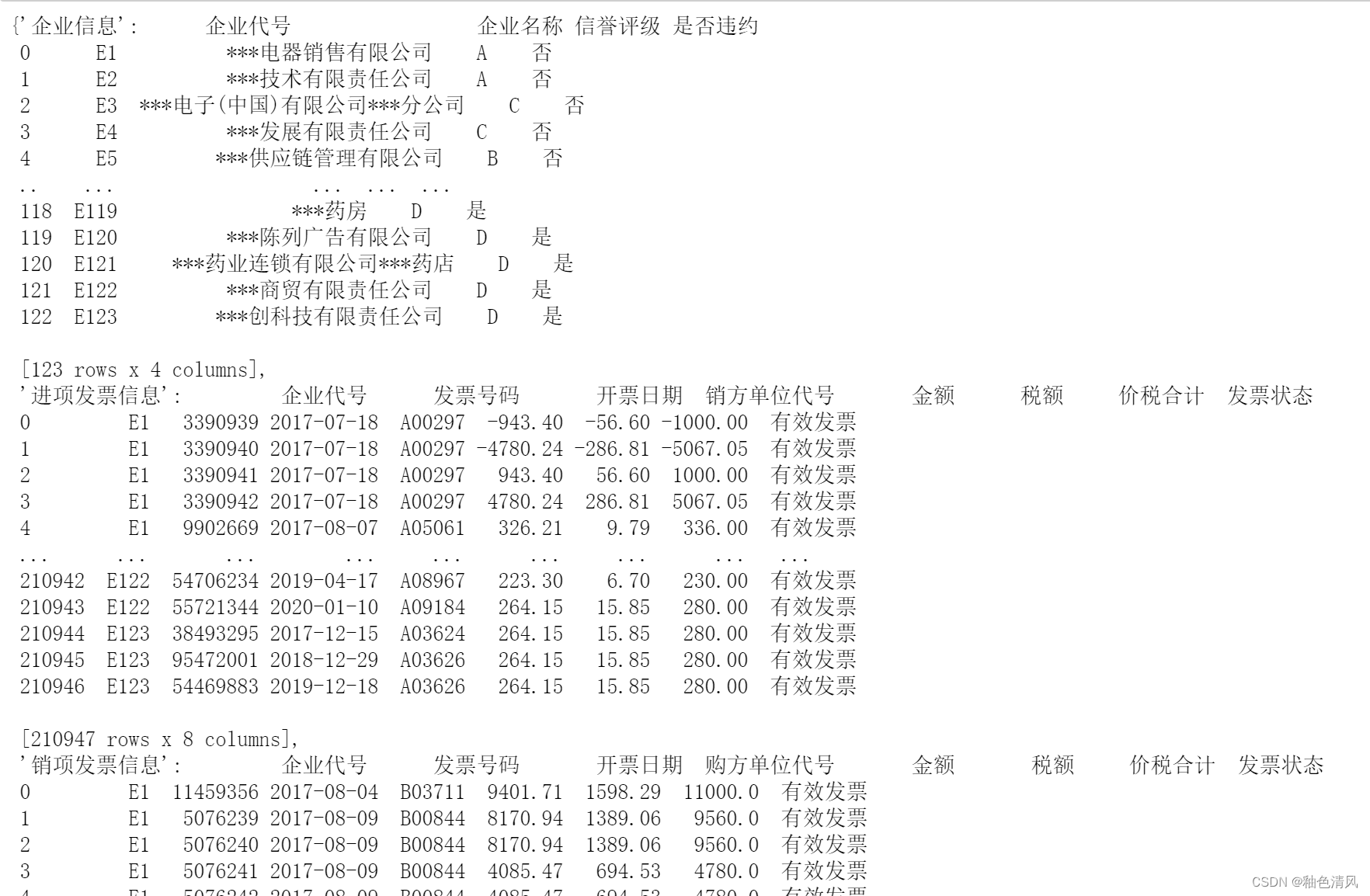
将sheet1保存至df1
df1=pd.read_excel(file_path,sheet_name='企业信息')
df1
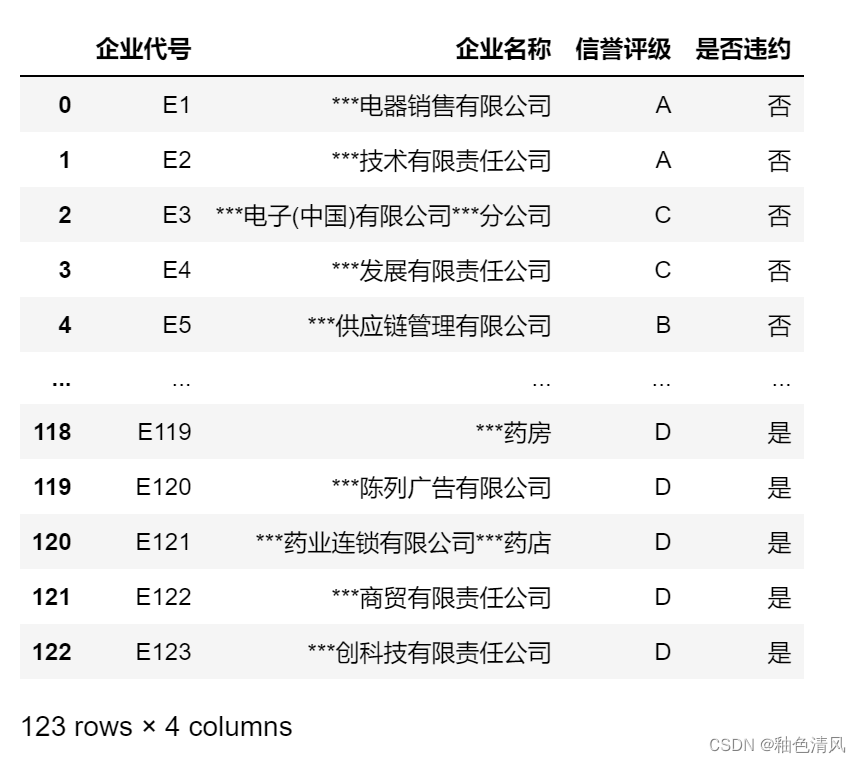
将我们所要研究的sheet2即“进项发票信息”保存给df2
df2=pd.read_excel(file_path,sheet_name='进项发票信息')
df2
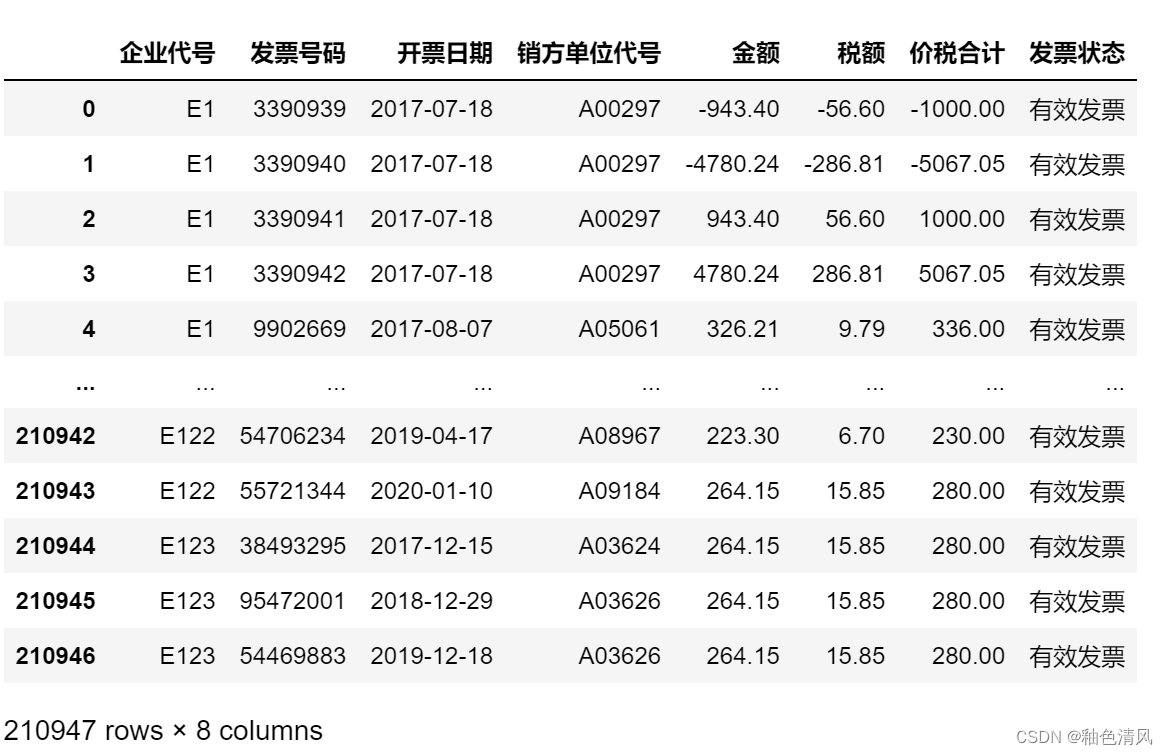
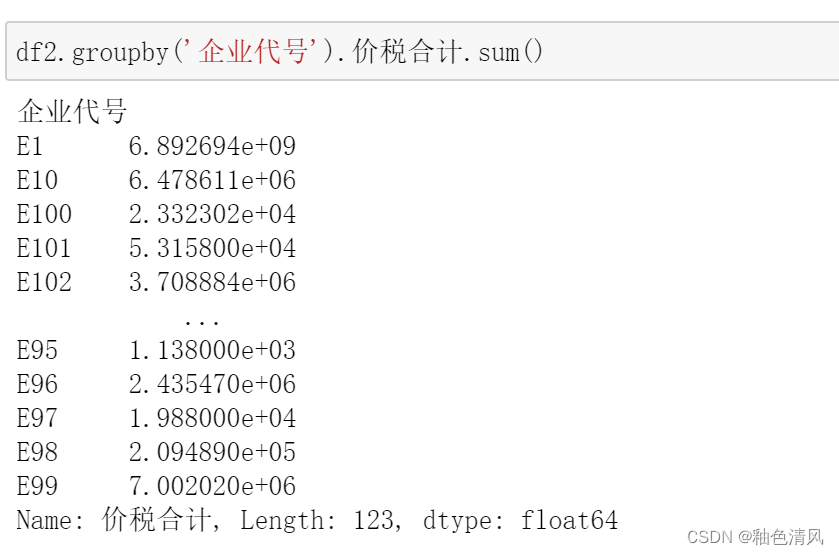
根据sheet2计算总进项价税额:
df2_=df2.groupby(['企业代号'],as_index=False,sort=False)['价税合计'].sum()
df2_
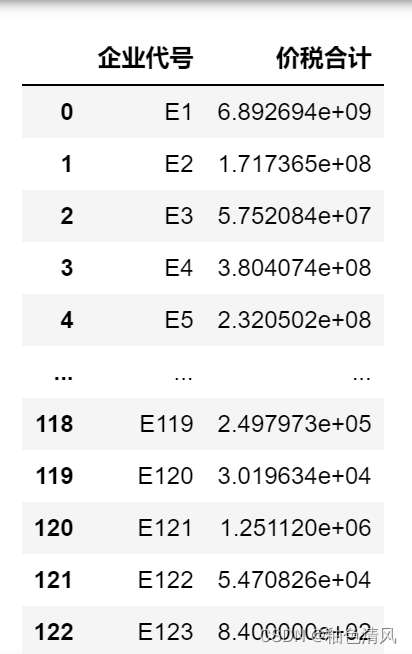
这里注意,设置参数sort=False,不然会改变企业代号的排序。
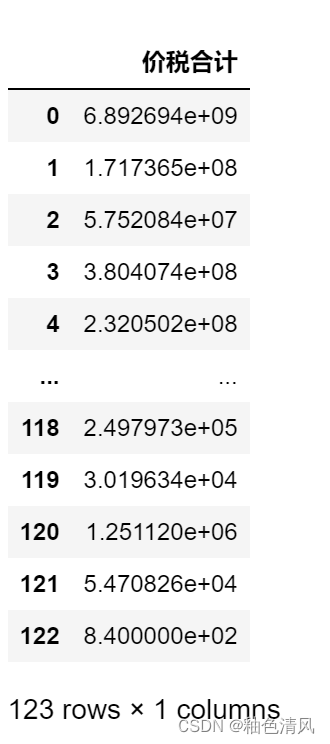
删除企业代号这一列:
df2_.drop(labels='企业代号',axis=1,inplace=False)
参数说明:axis默认为0,指删除行,axis=1,指删除列。
inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新DataFrame。inplace=True,则会直接在原数据上进行删除操作,且删除后无法返回。
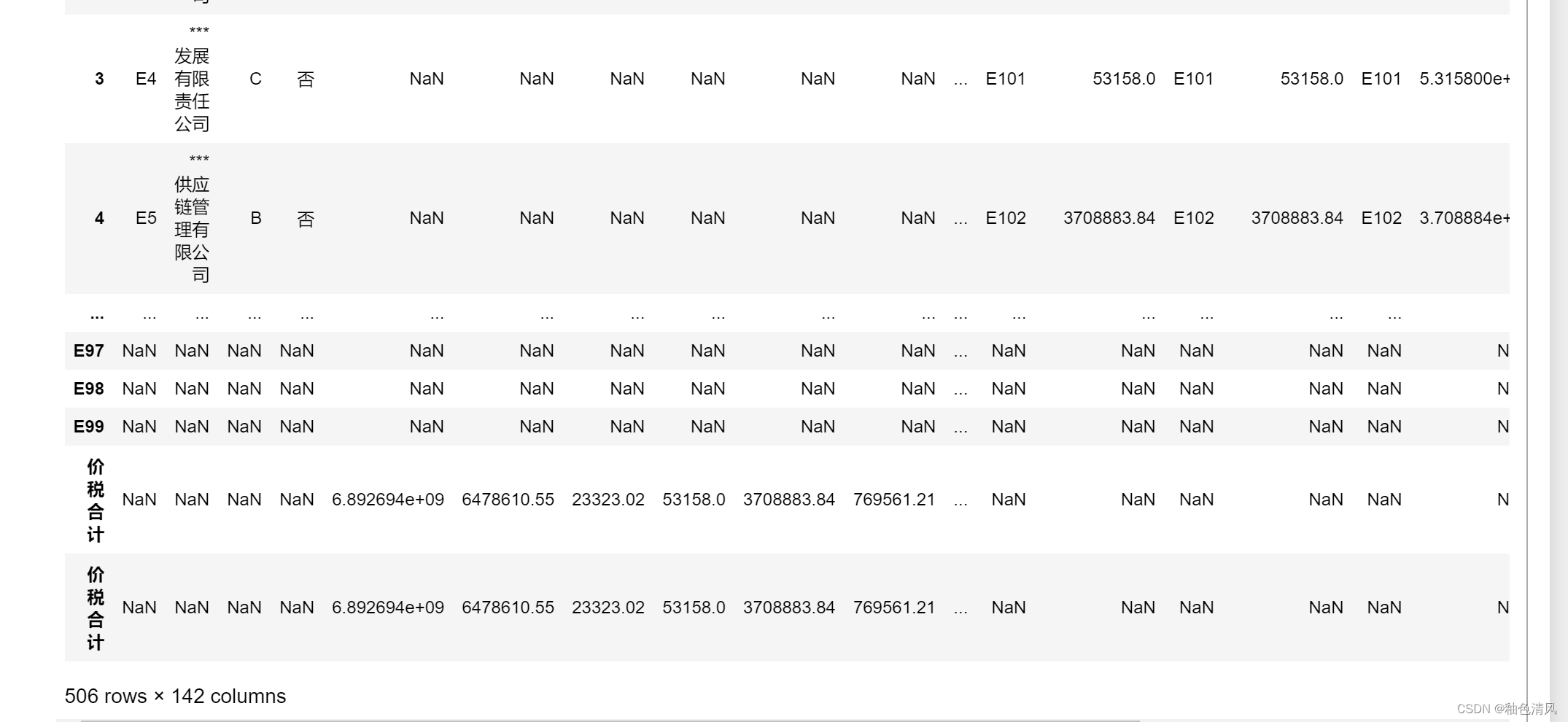
😭😭😭😭**由于我拼接表格,添加新的一列,没有成功。弄出来是这个样子的:**😱😱😱
所以下面我是导出数据,形成一个新的excel,然后利用excel复制粘贴到sheet1中。
df2__.to_excel("D:\A_data\Data.2020.C\进项价税合计.xlsx")
还要继续努力呀😭😭😭😭加油加油!






![[MAUI]在.NET MAUI中实现可拖拽排序列表](https://img-blog.csdnimg.cn/01e40435cec24ba2b8a910a4783f8139.gif)


![【Linux】Shell脚本之流程控制语句 if判断、for循环、while循环、case循环判断 + 实战详解[⭐建议收藏!!⭐]](https://img-blog.csdnimg.cn/9573137493ad4504a3f463e81691b3fb.png)