Rust 的设计灵感来源于很多现存的语言和技术。其中一个显著的影响就是 函数式编程(functional programming)。函数式编程风格通常包含将函数作为参数值或其他函数的返回值、将函数赋值给变量以供之后执行等等。
更具体的,我们将要涉及:
- 闭包(Closures),一个可以储存在变量里的类似函数的结构
- 迭代器(Iterators),一种处理元素序列的方式
- 如何使用这些功能来改进第十二章的 I/O 项目。
- 这两个功能的性能。(剧透警告: 他们的速度超乎你的想象!)
13.1 闭包:可以捕获环境的匿名函数
Rust 的 闭包(closures)是可以保存进变量或作为参数传递给其他函数的匿名函数。可以在一个地方创建闭包,然后在不同的上下文中执行闭包运算。不同于函数,闭包允许捕获调用者作用域中的值。我们将展示闭包的这些功能如何复用代码和自定义行为。
使用闭包创建行为的抽象
看一个存储稍后要执行的闭包的示例。
考虑一下这个假想的情况:我们在一个通过 app 生成自定义健身计划的初创企业工作。其后端使用 Rust 编写,而生成健身计划的算法需要考虑很多不同的因素,比如用户的年龄、身体质量指数(Body Mass Index)、用户喜好、最近的健身活动和用户指定的强度系数。本例中实际的算法并不重要,重要的是这个计算只花费几秒钟。我们只希望在需要时调用算法,并且只希望调用一次,这样就不会让用户等得太久。
这里将通过调用 simulated_expensive_calculation 函数来模拟调用假象的算法,它会打印出 calculating slowly...,等待两秒,并接着返回传递给它的数字:
use std::thread;
use std::time::Duration;
fn main() {
}
fn simulate_expensive_calculation(intensity: u32) -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2)); // 休眠2s
intensity
}
接下来,main 函数中将会包含本例的健身 app 中的重要部分。这代表当用户请求健身计划时 app 会调用的代码。因为与 app 前端的交互与闭包的使用并不相关,所以我们将硬编码代表程序输入的值并打印输出。
所需的输入有这些:
- 一个来自用户的 intensity 数字,请求健身计划时指定,它代表用户喜好低强度还是高强度健身。
- 一个随机数,其会在健身计划中生成变化。
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}出于简单考虑这里硬编码了 simulated_user_specified_value 变量的值为 10 和 simulated_random_number 变量的值为 7;一个实际的程序会从 app 前端获取强度系数并使用 rand crate 来生成随机数,正如第二章的猜猜看游戏所做的那样。main 函数使用模拟的输入值调用 generate_workout 函数:
fn generate_workout(intensity: u32, random_number: u32) {
if intensity < 25 {
println!("Today, do {}, pushups", simulate_expensive_calculation(intensity));
println!("Next do {}, situps", simulate_expensive_calculation(intensity));
} else {
if random_number == 3 {
println!("Take a break today, remember to stay hydrated");
} else {
println!("today, run for {} minutes", simulate_expensive_calculation(intensity));
}
}
}上述代码有多处调用了慢计算函数 simulated_expensive_calculation 。第一个 if 块调用了 simulated_expensive_calculation 两次, else 中的 if 没有调用它,而第二个 else 中的代码调用了它一次。
generate_workout 函数的期望行为是首先检查用户需要低强度(由小于 25 的系数表示)锻炼还是高强度(25 或以上)锻炼。
低强度锻炼计划会根据由 simulated_expensive_calculation 函数所模拟的复杂算法建议一定数量的俯卧撑和仰卧起坐。
如果用户需要高强度锻炼,这里有一些额外的逻辑:如果 app 生成的随机数刚好是 3,app 相反会建议用户稍做休息并补充水分。如果不是,则用户会从复杂算法中得到数分钟跑步的高强度锻炼计划。
现在这份代码能够应对我们的需求了,但数据科学部门的同学告知我们将来会对调用 simulated_expensive_calculation 的方式做出一些改变。为了在要做这些改动的时候简化更新步骤,我们将重构代码来让它只调用 simulated_expensive_calculation 一次。同时还希望去掉目前多余的连续两次函数调用,并不希望在计算过程中增加任何其他此函数的调用。也就是说,我们不希望在完全无需其结果的情况调用函数,不过仍然希望只调用函数一次。
使用函数重构
首先尝试的是将重复的 simulated_expensive_calculation 函数调用提取到一个变量中
fn generate_workout(intensity: u32, random_number: u32) {
// 先提取出来
let expensive_result =
simulate_expensive_calculation(intensity);
if intensity < 25 {
println!("Today, do {}, pushups", expensive_result);
println!("Next do {}, situps", expensive_result);
} else {
if random_number == 3 {
println!("Take a break today, remember to stay hydrated");
} else {
println!("today, run for {} minutes", expensive_result);
}
}
}
不幸的是,现在所有的情况下都需要调用函数并等待结果,包括那个完全不需要这一结果的内部 if 块。
我们希望能够在程序的一个位置指定某些代码,并只在程序的某处实际需要结果的时候 执行 这些代码。这正是闭包的用武之地!
重构使用闭包储存代码
不同于总是在 if 块之前调用 simulated_expensive_calculation 函数并储存其结果,我们可以定义一个闭包并将其储存在变量中,实际上可以选择将整个 simulated_expensive_calculation 函数体移动到这里引入的闭包中:
// 定义闭包
let expensive_closure = |num| {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};类似lambda表达式?
闭包定义是 expensive_closure 赋值的 = 之后的部分。闭包的定义以一对竖线(|)开始,在竖线中指定闭包的参数;之所以选择这个语法是因为它与 Smalltalk 和 Ruby 的闭包定义类似。这个闭包有一个参数 num;如果有多于一个参数,可以使用逗号分隔,比如 |param1, param2|。
参数之后是存放闭包体的大括号 —— 如果闭包体只有一行则大括号是可以省略的。大括号之后闭包的结尾,需要用于 let 语句的分号。因为闭包体的最后一行没有分号(正如函数体一样),所以闭包体(num)最后一行的返回值作为调用闭包时的返回值 。
注意这个 let 语句意味着 expensive_closure 包含一个匿名函数的 定义,不是调用匿名函数的 返回值。回忆一下使用闭包的原因是我们需要在一个位置定义代码,储存代码,并在之后的位置实际调用它;期望调用的代码现在储存在 expensive_closure 中。
fn generate_workout(intensity: u32, random_number: u32) {
// 定义闭包
let expensive_closure = |num| {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!("Today, do {}, pushups", expensive_closure(intensity));
println!("Next do {}, situps", expensive_closure(intensity));
} else {
if random_number == 3 {
println!("Take a break today, remember to stay hydrated");
} else {
println!("today, run for {} minutes", expensive_closure(intensity));
}
}
}
现在耗时的计算只在一个地方被调用,并只会在需要结果的时候执行改代码。
闭包类型推断和注解
闭包不要求像fn函数那样在参数和返回值上注明类型。函数中需要类型注解是因为他们是暴露给用户的显式接口的一部分。严格的定义这些接口对于保证所有人都认同函数使用和返回值的类型来说是很重要的。但是闭包并不用于这样暴露在外的接口:他们储存在变量中并被使用,不用命名他们或暴露给库的用户调用。
闭包通常很短并只与对应相对任意的场景较小的上下文中。在这些有限制的上下文中,编译器能可靠的推断参数和返回值的类型,类似于它是如何能够推断大部分变量的类型—样。
强制在这些小的匿名函数中注明类型是很恼人的,并且与编译器已知的信息存在大量的重复。
类似于变量,如果相比严格的必要性你更希望增加明确性并变得更啰嗦,可以选择增加类型注解;
// 定义闭包
let expensive_closure = |num: u32| -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};有了类型注解闭包的语法就更类似函数了。如下是一个对其参数加一的函数的定义与拥有相同行为闭包语法的纵向对比。这里增加了一些空格来对齐相应部分。这展示了闭包语法如何类似于函数语法,除了使用竖线而不是括号以及几个可选的语法之外:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;
第一行展示了一个函数定义,而第二行展示了一个完整标注的闭包定义。第三行闭包定义中省略了类型注解,而第四行去掉了可选的大括号,因为闭包体只有一行。这些都是有效的闭包定义,并在调用时产生相同的行为。
闭包定义会为每个参数和返回值推断一个具体类型。除了作为示例的目的这个闭包并不是很实用。注意其定义并没有增加任何类型注解:如果尝试调用闭包两次,第一次使用 String 类型作为参数而第二次使用 u32,则会得到一个错误:
fn test() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}
结果

第一次使用 String 值调用 example_closure 时,编译器推断 x 和此闭包返回值的类型为 String。接着这些类型被锁定进闭包 example_closure 中,如果尝试对同一闭包使用不同类型则会得到类型错误。
使用带有泛型和Fn trait的闭包
回到我们的健身计划生成 app ,在示例中的代码仍然调用了多于需要的慢计算闭包。解决这个问题的一个方法是在全部代码中的每一个需要多个慢计算闭包结果的地方,可以将结果保存进变量以供复用,这样就可以使用变量而不是再次调用闭包。但是这样就会有很多重复的保存结果变量的地方。
幸运的是,还有另一个可用的方案。可以创建一个存放闭包和调用闭包结果的结构体。该结构体只会在需要结果时执行闭包,并会缓存结果值,这样余下的代码就不必再负责保存结果并可以复用该值。你可能见过这种模式被称 memoization 或 lazy evaluation。
为了让结构体存放闭包,我们需要指定闭包的类型,因为结构体定义需要知道其每一个字段的类型。每一个闭包实例有其自己独有的匿名类型:也就是说,即便两个闭包有着相同的签名,他们的类型仍然可以被认为是不同。
Fn 系列 trait 由标准库提供。所有的闭包都实现了 trait Fn、FnMut 或 FnOnce 中的一个。
为了满足 Fn trait bound 我们增加了代表闭包所必须的参数和返回值类型的类型。在这个例子中,闭包有一个 u32 的参数并返回一个 u32,这样所指定的 trait bound 就是 Fn(u32) -> u32。
struct Cacher<T>
where T: Fn(u32) -> u32
{
calculation: T,
value: Option<u32>,
}结构体 Cacher 有一个泛型 T 的字段 calculation。T 的 trait bound 指定了 T 是一个使用 Fn 的闭包。任何我们希望储存到 Cacher 实例的 calculation 字段的闭包必须有一个 u32 参数(由 Fn 之后的括号的内容指定)并必须返回一个 u32(由 -> 之后的内容)。
注意:函数也都实现了这三个
Fntrait。如果不需要捕获环境中的值,则可以使用实现了Fntrait 的函数而不是闭包。
字段 value 是 Option<u32> 类型的。在执行闭包之前,value 将是 None。如果使用 Cacher 的代码请求闭包的结果,这时会执行闭包并将结果储存在 value 字段的 Some 成员中。接着如果代码再次请求闭包的结果,这时不再执行闭包,而是会返回存放在 Some 成员中的结果。
impl<T> Cacher<T>
where T: Fn(u32) -> u32
{
fn new(calculation: T) -> Cacher<T> {
Cacher {
calculation,
value: None,
}
}
fn value(&mut self, arg: u32) -> u32 {
match self.value {
Some(v) => v,
None => {
let v = (self.calculation)(arg);
self.value = Some(v);
v
},
}
}
}
Cacher 结构体的字段是私有的,因为我们希望 Cacher 管理这些值而不是任由调用代码潜在的直接改变他们。
Cacher::new 函数获取一个泛型参数 T,它定义于 impl 块上下文中并与 Cacher 结构体有着相同的 trait bound。Cacher::new 返回一个在 calculation 字段中存放了指定闭包和在 value 字段中存放了 None 值的 Cacher 实例,因为我们还未执行闭包。
当调用代码需要闭包的执行结果时,不同于直接调用闭包,它会调用 value 方法。这个方法会检查 self.value 是否已经有了一个 Some 的结果值;如果有,它返回 Some 中的值并不会再次执行闭包。
如果 self.value 是 None,则会调用 self.calculation 中储存的闭包,将结果保存到 self.value 以便将来使用,并同时返回结果值。
fn generate_workout(intensity: u32, random_number: u32) {
let mut expensive_result = Cacher::new(|num| {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
});
if intensity < 25 {
println!("Today, do {}, pushups", expensive_result.value(intensity));
println!("Next do {}, situps", expensive_result.value(intensity));
} else {
if random_number == 3 {
println!("Take a break today, remember to stay hydrated");
} else {
println!("today, run for {} minutes", expensive_result.value(intensity));
}
}
}不同于直接将闭包保存进一个变量,我们保存一个新的 Cacher 实例来存放闭包。接着,在每一个需要结果的地方,调用 Cacher 实例的 value 方法。可以调用 value 方法任意多次,或者一次也不调用,而慢计算最多只会运行一次。
Cacher实现的限制
值缓存是一种更加广泛的实用行为,我们可能希望在代码中的其他闭包中也使用他们。然而,目前 Cacher 的实现存在两个小问题,这使得在不同上下文中复用变得很困难。
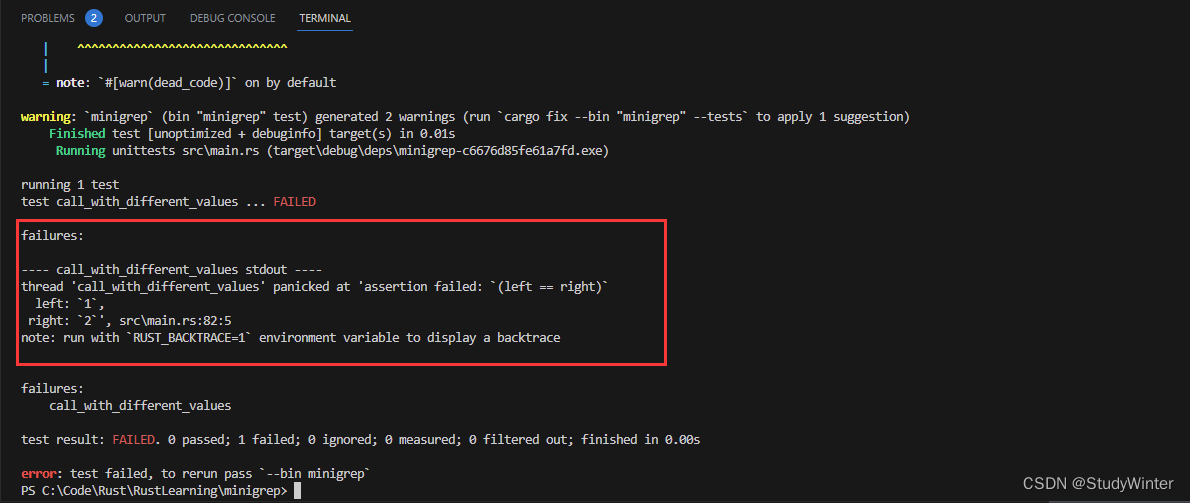
第一个问题是 Cacher 实例假设对于 value 方法的任何 arg 参数值总是会返回相同的值。也就是说,这个 Cacher 的测试会失败:
#[test]
fn call_with_different_values() {
let mut c = Cacher::new(|a| a);
let v1 = c.value(1);
let v2 = c.value(2);
assert_eq!(v2, 2);
}
这个测试使用返回传递给它的值的闭包创建了一个新的 Cacher 实例。使用为 1 的 arg 和为 2 的 arg 调用 Cacher 实例的 value 方法,同时我们期望使用为 2 的 arg 调用 value 会返回 2。
这里的问题是第一次使用 1 调用 c.value,Cacher 实例将 Some(1) 保存进 self.value。在这之后,无论传递什么值调用 value,它总是会返回 1。
尝试修改 Cacher 存放一个哈希 map 而不是单独一个值。哈希 map 的 key 将是传递进来的 arg 值,而 value 则是对应 key 调用闭包的结果值。相比之前检查 self.value 直接是 Some 还是 None 值,现在 value 函数会在哈希 map 中寻找 arg,如果找到的话就返回其对应的值。如果不存在,Cacher 会调用闭包并将结果值保存在哈希 map 对应 arg 值的位置。
当前 Cacher 实现的第二个问题是它的应用被限制为只接受获取一个 u32 值并返回一个 u32 值的闭包。比如说,我们可能需要能够缓存一个获取字符串 slice 并返回 usize 值的闭包的结果。请尝试引入更多泛型参数来增加 Cacher 功能的灵活性。
闭包会捕获其环境
在健身计划生成器的例子中,我们只将闭包作为内联匿名函数来使用。不过闭包还有另一个函数所没有的功能:他们可以捕获其环境并访问其被定义的作用域的变量。
fn main() {
let x = 4;
let equal_to_x = |z| z == x;
let y = 4;
assert!(equal_to_x(y));
}
这里,即便 x 并不是 equal_to_x 的一个参数,equal_to_x 闭包也被允许使用变量 x,因为它与 equal_to_x 定义于相同的作用域。
函数则不能做到同样的事,如果尝试如下例子,它并不能编译:
fn main() {
let x = 4;
fn equal_to_x(z: i32) -> bool { z == x }
let y = 4;
assert!(equal_to_x(y));
}
结果

编译器甚至会提示我们这只能用于闭包!
当闭包从环境中捕获一个值,闭包会在闭包体中储存这个值以供使用。这会使用内存并产生额外的开销,在更一般的场景中,当我们不需要闭包来捕获环境时,我们不希望产生这些开销。因为函数从未允许捕获环境,定义和使用函数也就从不会有这些额外开销。
闭包可以通过三种方式捕获其环境,他们直接对应函数的三种获取参数的方式:获取所有权,可变借用和不可变借用。这三种捕获值的方式被编码为如下三个 Fn trait:
FnOnce消费从周围作用域捕获的变量,闭包周围的作用域被称为其 环境,environment。为了消费捕获到的变量,闭包必须获取其所有权并在定义闭包时将其移动进闭包。其名称的Once部分代表了闭包不能多次获取相同变量的所有权的事实,所以它只能被调用一次。FnMut获取可变的借用值所以可以改变其环境Fn从其环境获取不可变的借用值
当创建一个闭包时,Rust 根据其如何使用环境中变量来推断我们希望如何引用环境。由于所有闭包都可以被调用至少一次,所以所有闭包都实现了 FnOnce 。那些并没有移动被捕获变量的所有权到闭包内的闭包也实现了 FnMut ,而不需要对被捕获的变量进行可变访问的闭包则也实现了 Fn 。
如果你希望强制闭包获取其使用的环境值的所有权,可以在参数列表前使用 move 关键字。
fn main() {
let x = vec![1, 2, 3];
let equal_to_x = move |z| z == x;
println!("can not use x here: {:?}", x);
let y = vec![1, 2, 3];
assert!(equal_to_x(y));
}
这个例子并不能编译,会产生以下错误:
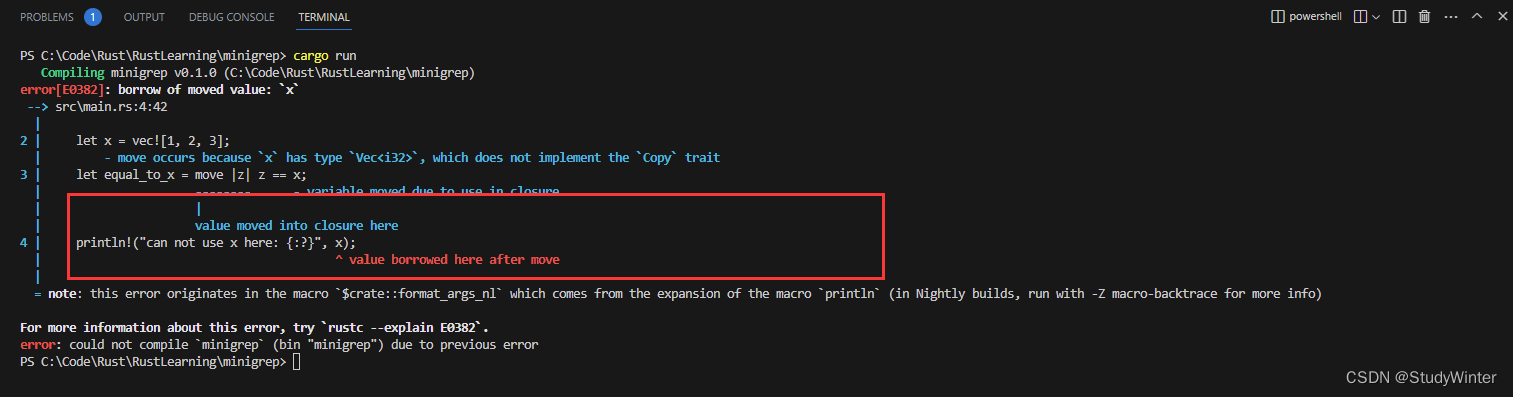
x 被移动进了闭包,因为闭包使用 move 关键字定义。接着闭包获取了 x 的所有权,同时 main 就不再允许在 println! 语句中使用 x 了。去掉 println! 即可修复问题。
大部分需要指定一个 Fn 系列 trait bound 的时候,可以从 Fn 开始,而编译器会根据闭包体中的情况告诉你是否需要 FnMut 或 FnOnce。
13.2 使用迭代器处理元素序列
迭代器模式允许你对一个项的序列进行某些处理。迭代器(iterator)负责遍历序列中的每一项和决定序列何时结束的逻辑。当使用迭代器时,我们无需重新实现这些逻辑。
在 Rust 中,迭代器是 惰性的(lazy),这意味着在调用方法使用迭代器之前它都不会有效果。
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
}
一旦创建迭代器之后,可以选择用多种方式利用它。
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for val in v1_iter {
println!("got: {}", val);
}
}
在标准库中没有提供迭代器的语言中,我们可能会使用一个从 0 开始的索引变量,使用这个变量索引 vector 中的值,并循环增加其值直到达到 vector 的元素数量。
迭代器为我们处理了所有这些逻辑,这减少了重复代码并消除了潜在的混乱。另外,迭代器的实现方式提供了对多种不同的序列使用相同逻辑的灵活性,而不仅仅是像 vector 这样可索引的数据结构.让我们看看迭代器是如何做到这些的。
Iterator trait和next方法
迭代器都实现了一个叫做 Iterator 的定义于标准库的 trait。这个 trait 的定义看起来像这样:
pub trait Iterator {
type Item;
fn next(&mut self)-> Option<Self::Item>;
// 此处省略了方法的默认实现
}
注意这里有一下我们还未讲到的新语法:type Item 和 Self::Item,他们定义了 trait 的 关联类型(associated type)。不过现在只需知道这段代码表明实现 Iterator trait 要求同时定义一个 Item 类型,这个 Item 类型被用作 next 方法的返回值类型。换句话说,Item 类型将是迭代器返回元素的类型。
next 是 Iterator 实现者被要求定义的唯一方法。next 一次返回迭代器中的一个项,封装在 Some 中,当迭代器结束时,它返回 None。可以直接调用迭代器的 next 方法。
fn main() {
iterator_demonstration();
}
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
// 迭代器移动
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}注意 v1_iter 需要是可变的:在迭代器上调用 next 方法改变了迭代器中用来记录序列位置的状态。换句话说,代码 消费(consume)了,或使用了迭代器。每一个 next 调用都会从迭代器中消费一个项。使用 for 循环时无需使 v1_iter 可变因为 for 循环会获取 v1_iter 的所有权并在后台使 v1_iter 可变。
另外需要注意到从 next 调用中得到的值是 vector 的不可变引用。iter 方法生成一个不可变引用的迭代器。如果我们需要一个获取 v1 所有权并返回拥有所有权的迭代器,则可以调用 into_iter 而不是 iter。类似的,如果我们希望迭代可变引用,则可以调用 iter_mut 而不是 iter。
消费迭代器的方法
Iterator trait 有一系列不同的由标准库提供默认实现的方法;你可以在 Iterator trait 的标准库 API 文档中找到所有这些方法。一些方法在其定义中调用了 next 方法,这也就是为什么在实现 Iterator trait 时要求实现 next 方法的原因。
这些调用 next 方法的方法被称为 消费适配器(consuming adaptors),因为调用他们会消耗迭代器。一个消费适配器的例子是 sum 方法。这个方法获取迭代器的所有权并反复调用 next 来遍历迭代器,因而会消费迭代器。
当其遍历每一个项时,它将每一个项加总到一个总和并在迭代完成时返回总和。
fn main() {
iterator_demonstration();
}
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum(); // 求和
assert_eq!(total, 6);
}
调用 sum 之后不再允许使用 v1_iter, 因为调用 sum 时它会获取迭代器的所有权。
产生其他迭代器的方法
Iterator trait 中定义了另一类方法,被称为 迭代器适配器(iterator adaptors),他们允许我们将当前迭代器变为不同类型的迭代器。可以链式调用多个迭代器适配器。不过因为所有的迭代器都是惰性的,必须调用一个消费适配器方法以便获取迭代器适配器调用的结果。
下面展示了一个调用迭代器适配器方法 map 的例子,该 map 方法使用闭包来调用每个元素以生成新的迭代器。 这里的闭包创建了一个新的迭代器,对其中 vector 中的每个元素都被加 1。不过这些代码会产生一个警告:
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1);
}
得到的警告是:
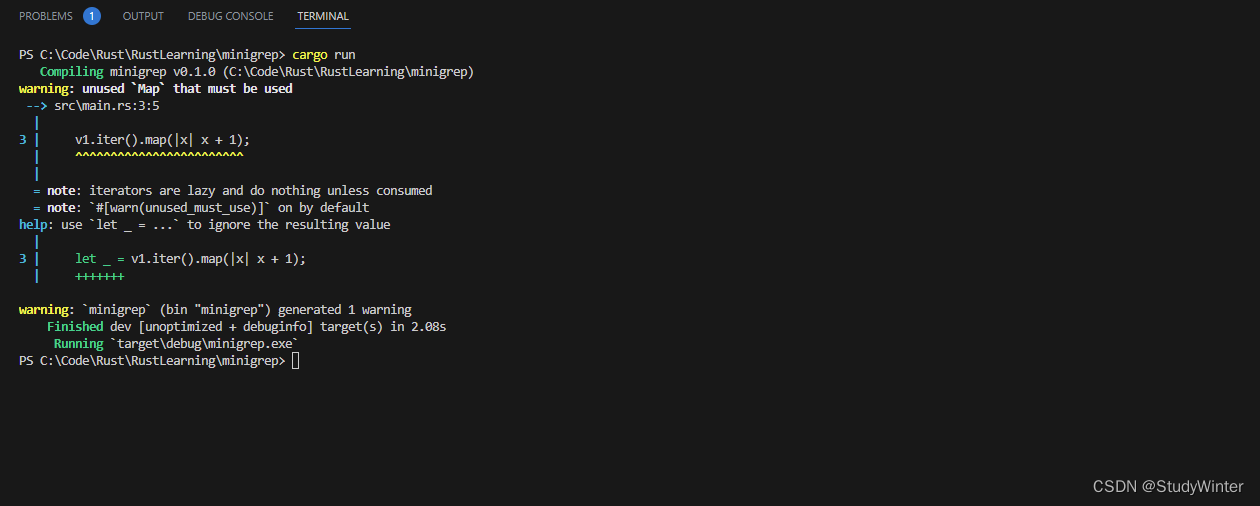
代码实际上并没有做任何事;所指定的闭包从未被调用过。警告提醒了我们为什么:迭代器适配器是惰性的,而这里我们需要消费迭代器。
为了修复这个警告并消费迭代器获取有用的结果,我们将使用第十二章结合 env::args 使用的 collect 方法。这个方法消费迭代器并将结果收集到一个数据结构中。
在示例,我们将遍历由 map 调用生成的迭代器的结果收集到一个 vector 中,它将会含有原始 vector 中每个元素加 1 的结果:
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
assert_eq!(v2, vec![2, 3, 4]);
}
调用 map 方法创建一个新迭代器,接着调用 collect 方法消费新迭代器并创建一个 vector
因为 map 获取一个闭包,可以指定任何希望在遍历的每个元素上执行的操作。这是一个展示如何使用闭包来自定义行为同时又复用 Iterator trait 提供的迭代行为的绝佳例子。
实现Iterator trait 来创建自定义迭代器
之前已经展示了可以通过在 vector 上调用 iter、into_iter 或 iter_mut 来创建一个迭代器。也可以用标准库中其他的集合类型创建迭代器,比如哈希 map。另外,可以实现 Iterator trait 来创建任何我们希望的迭代器。正如之前提到的,定义中唯一要求提供的方法就是 next 方法。一旦定义了它,就可以使用所有其他由 Iterator trait 提供的拥有默认实现的方法来创建自定义迭代器了!
作为展示,让我们创建一个只会从 1 数到 5 的迭代器。首先,创建一个结构体来存放一些值,接着实现 Iterator trait 将这个结构体放入迭代器中并在此实现中使用其值。
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
Counter 结构体有一个字段 count。这个字段存放一个 u32 值,它会记录处理 1 到 5 的迭代过程中的位置。count 是私有的因为我们希望 Counter 的实现来管理这个值。new 函数通过总是从为 0 的 count 字段开始新实例来确保我们需要的行为。
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
self.count += 1;
if self.count < 6 {
Some(self.count)
} else {
None
}
}
}
这里将迭代器的关联类型 Item 设置为 u32,意味着迭代器会返回 u32 值集合。
我们希望迭代器对其内部状态加一,这也就是为何将 count 初始化为 0:我们希望迭代器首先返回 1。如果 count 值小于 6,next 会返回封装在 Some 中的当前值,不过如果 count 大于或等于 6,迭代器会返回 None。
使用Counter送代器的next方法
一旦实现了 Iterator trait,我们就有了一个迭代器!
#[test]
fn calling_next_directly() {
let mut counter = Counter::new();
assert_eq!(counter.next(), Some(1));
assert_eq!(counter.next(), Some(2));
assert_eq!(counter.next(), Some(3));
assert_eq!(counter.next(), Some(4));
assert_eq!(counter.next(), Some(5));
assert_eq!(counter.next(), None);
}
这个测试在 counter 变量中新建了一个 Counter 实例并接着反复调用 next 方法,来验证我们实现的行为符合这个迭代器返回从 1 到 5 的值的预期。
使用自定义送代器中其他工terator trait方法
通过定义 next 方法实现 Iterator trait,我们现在就可以使用任何标准库定义的拥有默认实现的 Iterator trait 方法了,因为他们都使用了 next 方法的功能。
例如,出于某种原因我们希望获取 Counter 实例产生的值,将这些值与另一个 Counter 实例在省略了第一个值之后产生的值配对,将每一对值相乘,只保留那些可以被三整除的结果,然后将所有保留的结果相加。
#[test]
fn using_other_iterator_trait_methods() {
let sum: u32 = Counter::new().zip(Counter::new().skip(1))
.map(|(a, b)|a * b)
.filter(|x| x % 3 == 0)
.sum();
assert_eq!(18, sum);
}
注意 zip 只产生四对值;理论上第五对值 (5, None) 从未被产生,因为 zip 在任一输入迭代器返回 None 时也返回 None。
所有这些方法调用都是可能的,因为我们指定了 next 方法如何工作,而标准库则提供了其它调用 next 的方法的默认实现。
13.3 改进I/O项目
有了这些关于迭代器的新知识,我们可以使用迭代器来改进第十二章中 I/O 项目的实现来使得代码更简洁明了。
使用迭代器并去掉clone
impl Config {
pub fn new(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let filename = args[2].clone();
let case_sensitive = env::var("CASE_INSENSITIVE").is_err();
Ok(Config { query, filename, case_sensitive })
}
}
那时我们说过不必担心低效的 clone 调用了,因为将来可以对他们进行改进。好吧,就是现在!
起初这里需要 clone 的原因是参数 args 中有一个 String 元素的 slice,而 new 函数并不拥有 args。为了能够返回 Config 实例的所有权,我们需要克隆 Config 中字段 query 和 filename 的值,这样 Config 实例就能拥有这些值。
在学习了迭代器之后,我们可以将 new 函数改为获取一个有所有权的迭代器作为参数而不是借用 slice。我们将使用迭代器功能之前检查 slice 长度和索引特定位置的代码。这会明确 Config::new 的工作因为迭代器会负责访问这些值。
一旦 Config::new 获取了迭代器的所有权并不再使用借用的索引操作,就可以将迭代器中的 String 值移动到 Config 中,而不是调用 clone 分配新的空间。
直接使用env : : args返回的迭代器
打开 I/O 项目的 src/main.rs 文件,它看起来应该像这样:
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {}", err);
process::exit(1);
});
// --snip--
}
在更新 Config::new 之前这些代码还不能编译:
fn main() {
let config = Config::new(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {}", err);
process::exit(1);
});
// --snip--
}
env::args 函数返回一个迭代器!不同于将迭代器的值收集到一个 vector 中接着传递一个 slice 给 Config::new,现在我们直接将 env::args 返回的迭代器的所有权传递给 Config::new。
impl Config {
pub fn new(mut args: std::env::Args) -> Result<Config, &'static str> {
// --snip--
env::args 函数的标准库文档显示,它返回的迭代器的类型为 std::env::Args。我们已经更新了 Config :: new 函数的签名,因此参数 args 的类型为 std::env::Args 而不是 &[String]。因为我们拥有 args 的所有权,并且将通过对其进行迭代来改变 args ,所以我们可以将 mut 关键字添加到 args 参数的规范中以使其可变。
使用Iterator trait 代替索引
接下来,我们将修改 Config::new 的内容。标准库文档还提到 std::env::Args 实现了 Iterator trait,因此我们知道可以对其调用 next 方法!
fn main() {}
use std::env;
struct Config {
query: String,
filename: String,
case_sensitive: bool,
}
impl Config {
pub fn new(mut args: std::env::Args) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let filename = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file name"),
};
let case_sensitive = env::var("CASE_INSENSITIVE").is_err();
Ok(Config { query, filename, case_sensitive })
}
}
请记住 env::args 返回值的第一个值是程序的名称。我们希望忽略它并获取下一个值,所以首先调用 next 并不对返回值做任何操作。之后对希望放入 Config 中字段 query 调用 next。如果 next 返回 Some,使用 match 来提取其值。如果它返回 None,则意味着没有提供足够的参数并通过 Err 值提早返回。对 filename 值进行同样的操作。
使用迭代器适配器来使代码更简明
I/O 项目中其他可以利用迭代器的地方是 search 函数
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
可以通过使用迭代器适配器方法来编写更简明的代码。这也避免了一个可变的中间 results vector 的使用。函数式编程风格倾向于最小化可变状态的数量来使代码更简洁。去掉可变状态可能会使得将来进行并行搜索的增强变得更容易,因为我们不必管理 results vector 的并发访问。
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents.lines()
.filter(|line| line.contains(query))
.collect()
}
回忆 search 函数的目的是返回所有 contents 中包含 query 的行。可以使用 filter 适配器只保留 line.contains(query) 返回 true 的那些行。接着使用 collect 将匹配行收集到另一个 vector 中。这样就容易多了!尝试对 search_case_insensitive 函数做出同样的使用迭代器方法的修改吧。
13.4 性能对比:循环VS迭代器
结果迭代器版本还要稍微快一点!这里我们将不会查看性能测试的代码,我们的目的并不是为了证明他们是完全等同的,而是得出一个怎样比较这两种实现方式性能的基本思路。
对于一个更全面的性能测试,将会检查不同长度的文本、不同的搜索单词、不同长度的单词和所有其他的可变情况。这里所要表达的是:迭代器,作为一个高级的抽象,被编译成了与手写的底层代码大体一致性能代码。迭代器是 Rust 的 零成本抽象(zero-cost abstractions)之一,它意味着抽象并不会引入运行时开销,它与本贾尼·斯特劳斯特卢普(C++ 的设计和实现者)在 “Foundations of C++”(2012) 中所定义的 零开销(zero-overhead)如出一辙:
像音频解码器这样的程序通常最看重计算的性能。这里,我们创建了一个迭代器,使用了两个适配器,接着消费了其值。Rust 代码将会被编译为什么样的汇编代码呢?好吧,在编写本书的这个时候,它被编译成与手写的相同的汇编代码。遍历 coefficients 的值完全用不到循环:Rust 知道这里会迭代 12 次,所以它“展开”(unroll)了循环。展开是一种移除循环控制代码的开销并替换为每个迭代中的重复代码的优化。
所有的系数都被储存在了寄存器中,这意味着访问他们非常快。这里也没有运行时数组访问边界检查。所有这些 Rust 能够提供的优化使得结果代码极为高效。现在知道这些了,请放心大胆的使用迭代器和闭包吧!他们使得代码看起来更高级,但并不为此引入运行时性能损失。
总结
闭包和迭代器是 Rust 受函数式编程语言观念所启发的功能。他们对 Rust 以底层的性能来明确的表达高级概念的能力有很大贡献。闭包和迭代器的实现达到了不影响运行时性能的程度。这正是 Rust 竭力提供零成本抽象的目标的一部分。
参考:Rust 中的函数式语言功能:迭代器与闭包 - Rust 程序设计语言 简体中文版 (bootcss.com)