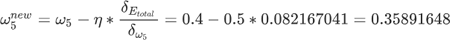常见的网络IO模型
网络 IO 模型分为四种:同步阻塞 IO、同步非阻塞IO、IO 多路复用、异步非阻塞 IO(Async IO, AIO),其中AIO为异步IO,其他都是同步IO
同步阻塞IO
同步阻塞IO:在线程处理过程中,如果涉及到IO操作,那么当前线程会被阻塞,直到IO处理完成,线程才接着处理后续流程。如下图,服务器针对客户端的每个socket都会分配一个新的线程处理,每个线程的业务处理分2步,当步骤1处理完成后遇到IO操作(比如:加载文件),这时候,当前线程会被阻塞,直到IO操作完成,线程才接着处理步骤2。

同步阻塞IO 演示图
实际使用场景
在Java中使用线程池的方式去连接数据库,使用的就是同步阻塞IO模型。
模型的缺点
因为每个客户端存都需要一个新的线程,势必导致线程被频繁阻塞和切换带来开销。
同步非阻塞 IO-NIO(New IO)
同步非阻塞IO:在线程处理过程中,如果涉及到IO操作,那么当前的线程不会被阻塞,而是会去处理其他业务代码,然后等过段时间再来查询 IO 交互是否完成。如下图:Buffer 是一个缓冲区,用来缓存读取和写入的数据;Channel 是一个通道,负责后台对接 IO 数据;而 Selector 实现的主要功能,是主动查询哪些通道是处于就绪状态。Selector复用一个线程,来查询已就绪的通道,这样大大减少 IO 交互引起的频繁切换线程的开销。

实际使用场景
Java NIO 正是基于这个 IO 交互模型,来支撑业务代码实现针对 IO 进行同步非阻塞的设计,从而降低了原来传统的同步阻塞 IO 交互过程中,线程被频繁阻塞和切换带的开销。
NIO使用的经典案例是Netty框架,Elasticsearch底层实际上就是采用的这种机制。
IO多路复用
- IO多路复用是一种同步IO模型,实现一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出cpu。多路是指网络连接,复用指的是同一个线程

所以,每个客户端和服务器的socket 连接就可以看做”一路“,多个客户端和该服务器的socket连接就是”多路“,从而,IO多路就是多个socket连接上的输入输出流,复用就是多个socket连接上的输入输出流由一个线程处理。 因此 IO多路复用可以定义如下:
Linux中的 IO多路复用是指:一个线程处理多个IO流
IO多路复用3种实现方式
select/pool/epool
基本socket模型
先看下socket模型,以便与下面几种实现方式对比:
listenSocket = socket() // 系统调用socket(),创建一个主动socket
bind(listenSocket) // 给主动socket绑定地址和端口
listen(listenSocket) // 将默认的主动socket转换为服务器的被动socket(也叫监听socket)
while(true) {
connSocket = accept(listenSocket) // 接受客户端连接,获取已链接socket
recv(connSocket) // 从客户端读取数据,只能同时处理一个客户端
send(connSocket) // 往客户端发送数据,只能同时处理一个客户端
}实现网络通信流程如下图

基础的socket模型,能够实现服务器端和客户端的通信,但程序每调用一次accept函数,只能处理一个客户端请求,当有大量客户端连接时,这种模型处理性能较差,因此linux提供了高性能的IO多路复用机制来解决这种困境。
select机制
select是最古老的I/O多路复用机制,可以同时监听多个文件描述符的读写事件。它使用的fd_set数据结构来存储待监听的文件描述符集合,并通过select()函数将fd_set集合传递给内核,等待内核返回文件描述符的状态变化。
fd_set数据结构 (bitmap)
typedef struct {
unsigned long fds_bits[__FDSET_LONGS];
} fd_set;/**
* 参数说明
* 监听的文件描述符数量__nfds、
* 被监听描述符的三个集合*__readfds,*__writefds和*__exceptfds
* 监听时阻塞等待的超时时长*__timeout
* 返回值:返回一个socket对应的文件描述符
*/
int select(int __nfds, fd_set * __readfds, fd_set * __writefds, fd_set * __exceptfds, struct timeval * __timeout)select实现网络通信流程如下图:
缺点
1、select使用的fd_set数据结构对单个进程能监听的文件描述符是有限制的,默认是1024
2、select()函数返回后,需要遍历文件描述符集合,才能找到就绪的描述符,遍历过程会产生一定开销,降低性能。
poll机制
poll与select类似,也可以同时监听多个文件描述符的读写事件。它使用的pollfd数据结构来存储待监听的文件描述符集合,并通过pool()函数将pollfd集合传递给内核,等待内核返回文件描述符的状态变化。相对于select,poll没有fd_set集合大小的限制,但并没有解决轮询获取就绪fd的问题,效率也不高。
pollfd结构体的定义
struct pollfd {
int fd; //进行监听的文件描述符
short int events; //要监听的事件类型
short int revents; //实际发生的事件类型
};poll实现网络通信流程如下图:

epoll机制
epoll 是对 select 和 poll 的改进,解决了“性能开销大”和“文件描述符数量少”这两个缺点,是性能最高的多路复用实现方式,能支持的并发量也是最大。
总结下,epoll 相关的函数里内核运行环境分两部分:
-
用户进程内核态。进行调用 epoll_wait 等函数时会将进程陷入内核态来执行。这部分代码负责查看接收队列,以及负责把当前进程阻塞掉,让出 CPU。
-
硬软中断上下文。在这些组件中,将包从网卡接收过来进行处理,然后放到 socket 的接收队列。对于 epoll 来说,再找到 socket 关联的 epitem,并把它添加到 epoll 对象的就绪链表中。这个时候再捎带检查一下 epoll 上是否有被阻塞的进程,如果有唤醒之。
epoll 的特点是:
1)使用红黑树存储一份文件
2)通过异步 IO 事件找到就绪的文件描述符,而不是通过轮询的方式;
3)使用队列存储就绪的文件描述符,且会按需返回就绪的文件描述符,无须再次遍历;
epoll接口
1、epoll_create 用于创建一个 eventpoll 对象
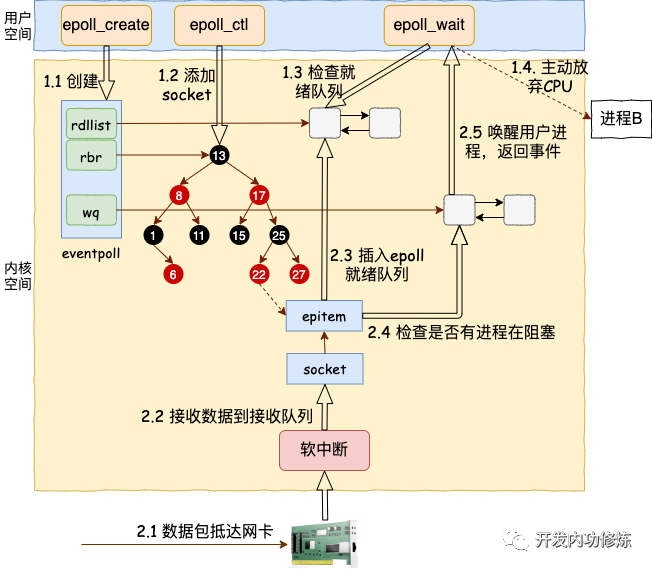
epoll 实例内部维护了3个结构,
具体如代码所示:
// 数据结构
// 每一个epoll对象都有一个独立的eventpoll结构体
// 用于存放通过epoll_ctl方法向epoll对象中添加进来的事件
// epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可
struct eventpoll {
/* 就绪的描述符的双链表.
当有的连接数据就绪的时候,内核会把就绪的连接放到 rdllist 链表里。
这样应用进程只需要判断链表就能找出就绪进程,而不用去遍历整棵树。
*/
struct list_head rdlist;
/* 一颗红黑树,通过这棵树来管理用户进程下添加进来的所有socket连接。*/
struct rb_root rbr;
/* wq: 等待队列链表。软中断数据就绪的时候会通过 wq 来找到阻塞在 epoll 对象上的用户进程。存放阻塞的进程*/
wait_queue_head_t wq;
......
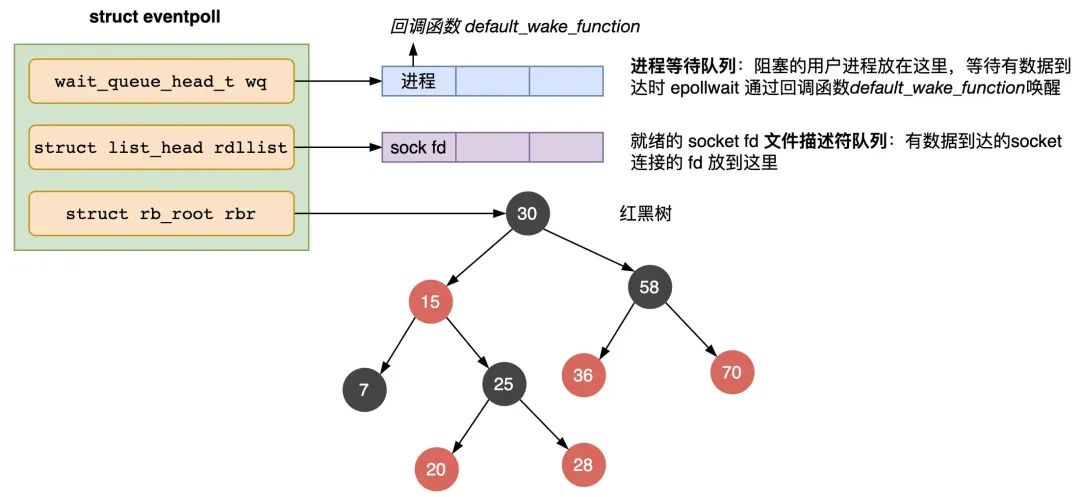
};2、epoll_ctl 负责把服务端和客户端建立的 socket 连接注册到 eventpoll 对象里,会做三件事:
1)创建一个红黑树节点对象 epitem ,主要包含两个字段,分别存放 socket fd 即连接的文件描述符,和所属的 eventpoll 对象的指针;
struct epitem {
//红黑树节点
struct rb_node rbn;
//socket文件描述符信息
struct epoll_filefd ffd;
//所归属的 eventpoll 对象
struct eventpoll *ep;
//等待队列
struct list_head pwqlist;
}2)添加等待事件到socket的等待队列中,其回调函数是将回调函数ep_poll_callback,ep_poll_callback通过回调default_wake_up_function唤醒用户进程
3)将 epitem 对象插入红黑树
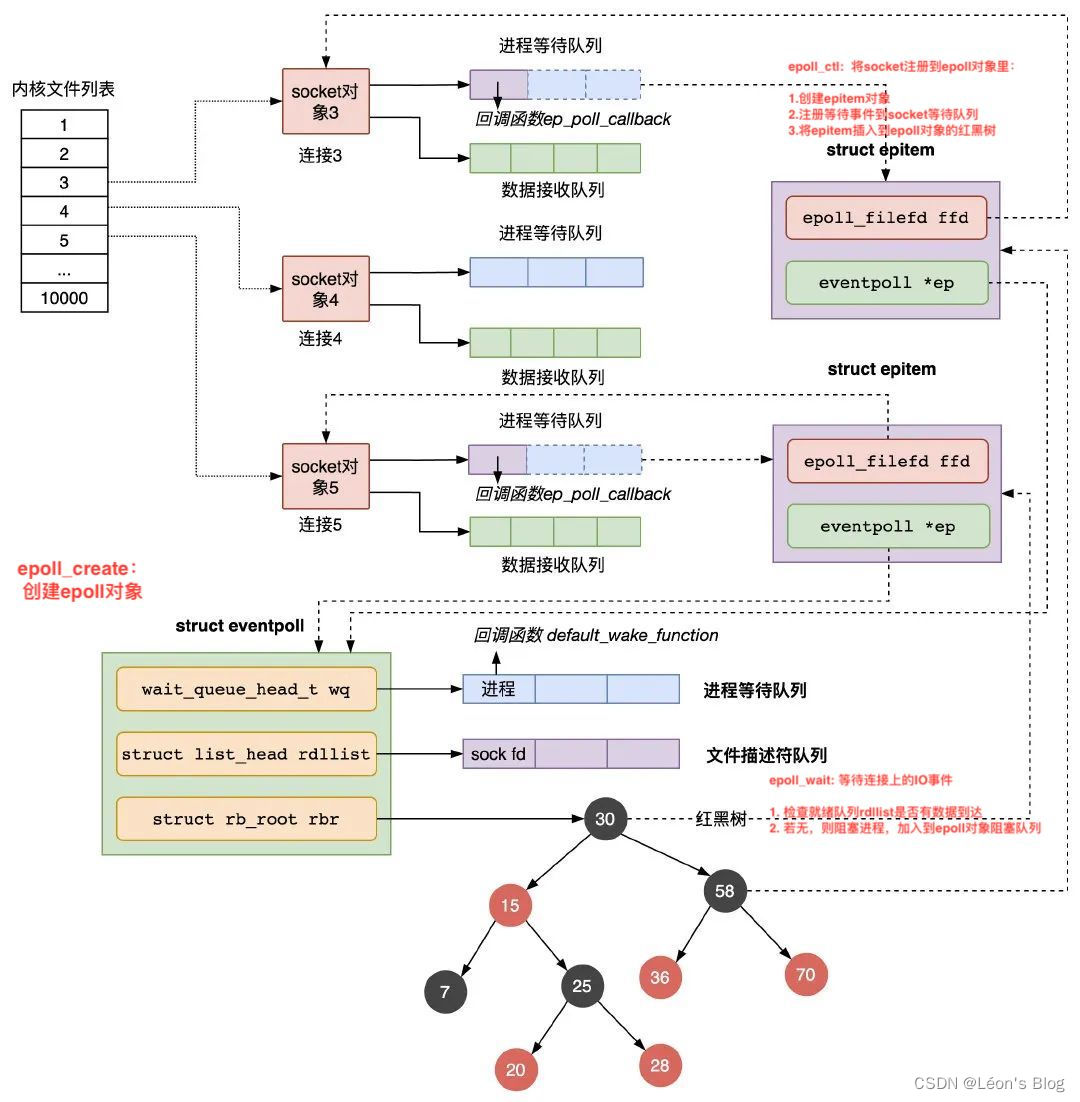
3、epoll_wait 用于等待其管理的连接上的 IO 事件
1) 检查 eventpoll 对象的就绪的连接 rdllist 上是否有数据到达;
2) 如果没有就把当前的进程描述符加入到 eventpoll 的进程等待队列里,然后阻塞当前进程,等待数据到达时通过回调函数被唤醒

3) 当 eventpoll 监控的连接上有数据到达时,通过下面几个步骤唤醒对应的进程处理数据:
1)socket 的数据接收队列有数据到达,会通过进程等待队列的回调函数 ep_poll_callback 唤醒红黑树中的节点 epitem;
2)ep_poll_callback 函数将有数据到达的 epitem 添加到 eventpoll 对象的就绪队列 rdllist 中;
3)ep_poll_callback 函数检查 eventpoll 对象的进程等待队列上是否有等待项,通过回调函数 default_wake_func 唤醒这个进程,进行数据的处理;
4)当进程醒来后,继续从 epoll_wait 时暂停的代码继续执行,把 rdlist 中就绪的事件返回给用户进程,让用户进程调用 recv 把已经到达内核 socket 等待队列的数据拷贝到用户空间使用。
软中断回调的时候回调函数也整理一下:
sock_def_readable:sock 对象初始化时设置的
=>
ep_poll_callback : epoll_ctl 时添加到 socket 上的
=>
default_wake_function: epoll_wait 是设置到 epoll上的

- 在socket等待队列中,其回调函数是ep_poll_callback,另外其 private 没有用了,指向的是空指针 null。
- 在 eventpoll 的等待队列项中,回调函数是 default_wake_function。其 private 指向的是等待该事件的用户进程。
ET模式与LT模式的区别
- epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。
- ET模式(边缘触发): epoll_wait 遍历 ready_list 的时候,会把 socket 从 ready_list 里面移除,然后读取这个 scoket 的事件。
- LT模式(水平触发)下,会把 socket 从 ready_list 里面移除,然后读取这个 scoket 的事件,如果这个 socket 返回了感兴趣的事件,那么当前这个 socket 会再被加入到 ready_list 中,这样下次调用 epoll_wait 的时候,还能拿到这个 socket。
举个栗子:
如果此时一个客户端同时发来了 5 个数据包,按正常的逻辑,只需要唤醒一次 epoll ,把当前 socket 加一次到 ready_list 就行了,不需要加 5 次。然后用户程序可以把 socket 接收队列的所有数据包都读完。
但假设用户程序就读了一个包,然后处理报错了,后面不读了,那后面的 4 个包咋办?
如果是 ET 模式,就读不了了,因为没有把 socket 加入到 ready_list 的触发条件了。除非这个客户端发了新的数据包过来,这样才会再把当前 socket 加入到 ready_list,在新包过来之前,这 4 个数据包都不会被读到。
而 LT 模式不一样,因为每次读完有感兴趣的事件发生之后,会把当前 socket 再加入到 ready_list,所以下次肯定能读到这个 socket,所以后面的 4 个数据包会被访问到,不论客户端是否发送新包。
因此,在 LT模式下开发基于 epoll的应用要简单一些,不太容易出错,而在 ET模式下事件发生时,如果没有彻底地将缓冲区数据处理完,则会导致缓冲区中的用户请求得不到响应。
3种机制底层实现的区别
select和poll都是通过轮询的方式,即内核每次要遍历监听的文件描述符集合,判断每个文件描述符是否有I/O事件发生;
而epoll底层实现是基于事件通知的方式,即当文件描述符状态发生变化时,内核会向应用程序发起事件通知,这种方式避免了无效的遍历,从而提高了效率。
在epoll中,使用epoll_wait函数进行事件监听时,内核将发生的事件文件描述符加入到一个就绪队列中,等待应用程序处理。如果就绪队列中没有任何文件描述符,则epoll_wait函数会阻塞,直到有文件描述符加入就绪队列,这种方式实现了I/O事件的高效处理和调度。
| select | poll | epoll | |
|---|---|---|---|
| 数据结构 | bitmap | 数组 | 红黑树 |
| 最大连接数 | 1024 | 无上限 | 无上限 |
| fd拷贝 | 每次调用select拷贝 | 每次调用poll拷贝 | fd首次调用epoll_ctl拷贝,每次调用epoll_wait不拷贝 |
| 工作效率 | 轮询:O(n) | 轮询:O(n) | 回调:O(1) |
参考资料:
https://juejin.cn/post/6844904200141438984
IO多路复用机制详解 - 知乎
select poll epoll 区别 和 底层实现-掘金
https://www.cnblogs.com/88223100/p/Deeply-learn-the-implementation-principle-of-IO-multiplexing-select_poll_epoll.html