第四阶段
时 间:2023年8月14日
参加人:全班人员
内 容:
Kubernetes 企业级高可用部
目录
一、Kubernetes高可用项目介绍
二、项目架构设计
(一)项目主机信息
(二)项目架构图
(三)项目实施思路
三、项目实施过程
(一)系统初始化(所有主机)
(二)配置部署keepalived服务
(三)配置部署haproxy服务
(四)配置部署Docker服务
(五)部署kubelet kubeadm kubectl工具
(六)部署Kubernetes Master
(七)安装集群网络
(八)添加master节点
(九)加入Kubernetes Node
(十)测试Kubernetes集群
【实验验证】
四、项目总结
一、Kubernetes高可用项目介绍
单master节点的可靠性不高,并不适合实际的生产环境。
Kubernetes 高可用集群是保证 Master 节点中 API Server 服务的高可用。
API Server 提供了 Kubernetes 各类资源对象增删改查的唯一访问入口,是整个 Kubernetes 系统的数据总线和数据中心。采用负载均衡(Load Balance)连接多个 Master 节点可以提供稳定容器云业务。
二、项目架构设计
(一)项目主机信息
准备6台虚拟机,3台master节点,3台node节点,保证master节点数为>=3的奇数。
硬件:2核CPU+、2G内存+、硬盘20G+
网络:所有机器网络互通、可以访问外网
| IP地址 | 角色 | 主机名 |
| 192.168.100.131 | master | k8s-master1 |
| 192.168.100.132 | master | k8s-master2 |
| 192.168.100.133 | master | k8s-master3 |
| 192.168.100.134 | node | k8s-node1 |
| 192.168.100.135 | node | k8s-node2 |
| 192.168.100.136 | node | k8s-node3 |
| 192.168.100.154 | VIP | master.k8s.io |
(二)项目架构图
多master节点负载均衡的kubernetes集群。官网给出了两种拓扑结构:堆叠control plane node和external etcd node,本文基于第一种拓扑结构进行搭建。

(堆叠control plane node)

(external etcd node)
(三)项目实施思路
master节点需要部署etcd、apiserver、controller-manager、scheduler这4种服务,其中etcd、controller-manager、scheduler这三种服务kubernetes自身已经实现了高可用,在多master节点的情况下,每个master节点都会启动这三种服务,同一时间只有一个生效。因此要实现kubernetes的高可用,只需要apiserver服务高可用。
keepalived是一种高性能的服务器高可用或热备解决方案,可以用来防止服务器单点故障导致服务中断的问题。keepalived使用主备模式,至少需要两台服务器才能正常工作。比如keepalived将三台服务器搭建成一个集群,对外提供一个唯一IP,正常情况下只有一台服务器上可以看到这个IP的虚拟网卡。如果这台服务异常,那么keepalived会立即将IP移动到剩下的两台服务器中的一台上,使得IP可以正常使用。
haproxy是一款提供高可用性、负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。使用haproxy负载均衡后端的apiserver服务,达到apiserver服务高可用的目的。
本文使用的keepalived+haproxy方案,使用keepalived对外提供稳定的入口,使用haproxy对内均衡负载。因为haproxy运行在master节点上,当master节点异常后,haproxy服务也会停止,为了避免这种情况,我们在每一台master节点都部署haproxy服务,达到haproxy服务高可用的目的。由于多master节点会出现投票竞选的问题,因此master节点的数据最好是单数,避免票数相同的情况。
三、项目实施过程
(一)系统初始化(所有主机)
1、关闭防火墙
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
2、关闭selinux
[root@localhost ~]# sed -i 's/enforcing/disabled/' /etc/selinux/config
[root@localhost ~]# setenforce 0
3、关闭swap
[root@localhost ~]# swapoff -a
[root@localhost ~]# sed -ri 's/.*swap.*/#&/' /etc/fstab

4、修改主机名(根据主机角色不同,做相应修改)
hostname k8s-node1
bash
5、主机名映射
[root@k8s-master1 ~]# cat >> /etc/hosts << EOF
192.168.100.131 master1.k8s.io k8s-master1
192.168.100.132 master2.k8s.io k8s-master2
192.168.100.133 master3.k8s.io k8s-master3
192.168.100.134 node1.k8s.io k8s-node1
192.168.100.135 node2.k8s.io k8s-node2
192.168.100.136 node3.k8s.io k8s-node3
192.168.100.154 master.k8s.io k8s-vip
EOF
6、将桥接的IPv4流量传递到iptables的链
[root@k8s-master1 ~]# cat << EOF >> /etc/sysctl.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@k8s-master1 ~]# modprobe br_netfilter
[root@k8s-master1 ~]# sysctl -p
7、时间同步
[root@k8s-master1 ~]# yum install ntpdate -y
[root@k8s-master1 ~]# ntpdate time.windows.com

(二)配置部署keepalived服务
1、安装Keepalived(所有master主机)
[root@k8s-master1 ~]# yum install -y keepalived

2、k8s-master1节点配置
[root@k8s-master1 ~]#
cat /etc/keepalived/keepalived.conf

k8s-master2节点配置
[root@k8s-master2 ~]#
cat /etc/keepalived/keepalived.conf
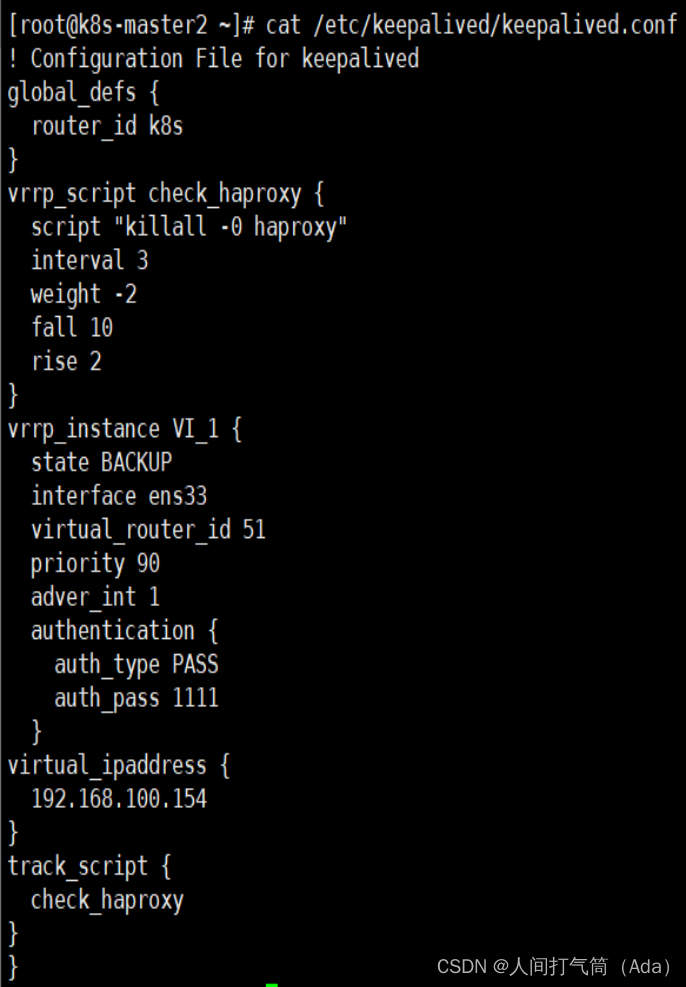
k8s-master3节点配置
[root@k8s-master3 ~]#
cat /etc/keepalived/keepalived.conf

3、启动和检查
所有master节点都要执行
[root@k8s-master1 ~]# systemctl start keepalived
[root@k8s-master1 ~]# systemctl enable keepalived
4、查看启动状态
[root@k8s-master1 ~]# systemctl status keepalived

5、启动完成后在master1查看网络信息
[root@k8s-master1 ~]# ip a s ens33

(三)配置部署haproxy服务
1、所有master主机安装haproxy
[root@k8s-master1 ~]# yum install -y haproxy

每台master节点中的配置均相同,配置中声明了后端代理的每个master节点服务器,指定了haproxy的端口为16443,因此16443端口为集群的入口。
2、修改配置文件
[root@k8s-master1 ~]# cat /etc/haproxy/haproxy.cfg

3、启动和检查
所有master节点都要执行
[root@k8s-master1 ~]# systemctl start haproxy
[root@k8s-master1 ~]# systemctl enable haproxy
4、查看启动状态
[root@k8s-master1 ~]# systemctl status haproxy

5、检查端口
[root@k8s-master1 ~]# netstat -lntup|grep haproxy

(四)配置部署Docker服务
所有主机上分别部署 Docker 环境,因为 Kubernetes 对容器的编排需要 Docker 的支持。
[root@k8s-master ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@k8s-master ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
使用 YUM 方式安装 Docker 时,推荐使用阿里的 YUM 源。
[root@k8s-master ~]# yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@k8s-master ~]# yum clean all && yum makecache fast
[root@k8s-master ~]# yum -y install docker-ce
[root@k8s-master ~]# systemctl start docker
[root@k8s-master ~]# systemctl enable docker
镜像加速器(所有主机配置)
[root@k8s-master ~]# cat /etc/docker/daemon.json
[root@k8s-master ~]# systemctl daemon-reload
[root@k8s-master ~]# systemctl restart docker


(五)部署kubelet kubeadm kubectl工具
使用 YUM 方式安装Kubernetes时,推荐使用阿里的yum。
所有主机配置
[root@k8s-master ~]#
cat /etc/yum.repos.d/kubernetes.repo
[root@k8s-master ~]# ls /etc/yum.repos.d/
backup Centos-7.repo CentOS-Media.repo CentOS-x86_64-kernel.repo docker-ce.repo kubernetes.repo

2、安装kubelet kubeadm kubectl
所有主机配置
[root@k8s-master ~]# yum install -y kubelet kubeadm kubectl
[root@k8s-master ~]# systemctl enable kubelet

(六)部署Kubernetes Master
在具有vip的master上操作。此处的vip节点为k8s-master1。
1、创建kubeadm-config.yaml文件
[root@k8s-master1 ~]# cat kubeadm-config.yaml

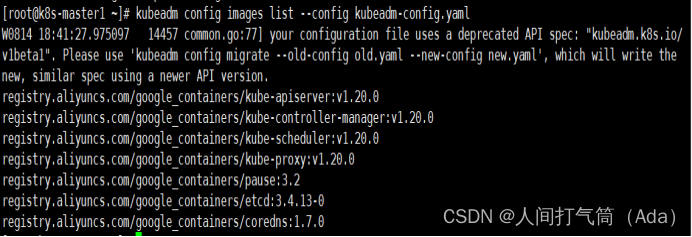
2、查看所需镜像信息
[root@k8s-master1 ~]# kubeadm config images list --config kubeadm-config.yaml
3、下载k8s所需的镜像(所有master主机)
[root@k8s-master1 ~]# kubeadm config images pull --config kubeadm-config.yaml

4、使用kubeadm命令初始化k8s
[root@k8s-master1 ~]# kubeadm init --config kubeadm-config.yaml

初始化中的错误:

执行以下命令后重新执行初始化命令
[root@k8s-master1 ~]# echo "1" > /proc/sys/net/ipv4/ip_forward
[root@k8s-master1 ~]# kubeadm init --config kubeadm-config.yaml

5、根据初始化的结果操作
[root@k8s-master1 ~]# mkdir -p $HOME/.kube
[root@k8s-master1 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master1 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config

6、查看集群状态
[root@k8s-master1 manifests]# kubectl get cs

注意:出现以上错误情况,是因为/etc/kubernetes/manifests/下的kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口为0导致的,解决方式是注释掉对应的port即可
1)修改kube-controller-manager.yaml文件

2)修改kube-scheduler.yaml文件

3)查看集群状态
[root@k8s-master1 ~]# kubectl get cs

4)查看pod信息
[root@k8s-master1 ~]# kubectl get pods -n kube-system

5)查看节点信息
[root@k8s-master1 ~]# kubectl get nodes

(七)安装集群网络
在k8s-master1节点执行
[root@k8s-master1 ~]# docker load < flannel_v0.12.0-amd64.tar

没有变成ready:(原因是网络插件缺失)

上传插件:
[root@k8s-master1 ~]# tar xf cni-plugins-linux-amd64-v0.8.6.tgz
[root@k8s-master1 ~]# cp flannel /opt/cni/bin/
[root@k8s-master1 ~]# kubectl delete -f kube-flannel.yml 删除之前的apply操作

再次查看节点信息:
[root@k8s-master1 ~]# kubectl apply -f kube-flannel.yml
[root@k8s-master1 ~]# kubectl get nodes
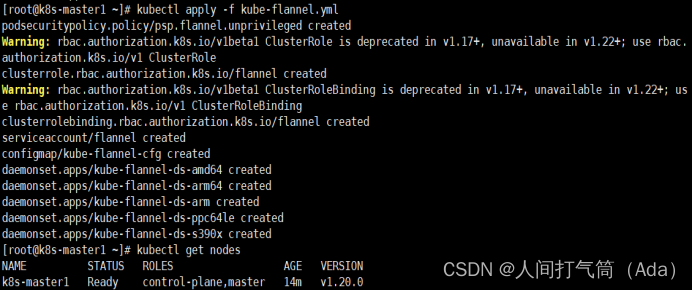
(八)添加master节点
1、在k8s-master2和k8s-master3节点创建文件夹
[root@k8s-master2 ~]# mkdir -p /etc/kubernetes/pki/etcd
[root@k8s-master3 ~]# mkdir -p /etc/kubernetes/pki/etcd
2、在k8s-master1节点执行
从k8s-master1复制秘钥和相关文件到k8s-master2和k8s-master3
[root@k8s-master1 ~]# scp /etc/kubernetes/admin.conf root@192.168.100.132:/etc/kubernetes
[root@k8s-master1 ~]# scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@192.168.100.132:/etc/kubernetes/pki
[root@k8s-master1 ~]# scp /etc/kubernetes/pki/etcd/ca.* root@192.168.100.132:/etc/kubernetes/pki/etcd
[root@k8s-master1 ~]# scp /etc/kubernetes/admin.conf root@192.168.100.133:/etc/kubernetes
[root@k8s-master1 ~]# scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@192.168.100.133:/etc/kubernetes/pki
[root@k8s-master1 ~]# scp /etc/kubernetes/pki/etcd/ca.* root@192.168.100.133:/etc/kubernetes/pki/etcd

3、将其他master节点加入集群
注意:kubeadm init生成的token有效期只有1天,生成不过期token
[root@k8s-master1 manifests]# kubeadm token create --ttl 0 --print-join-command
[root@k8s-master1 manifests]# kubeadm token list
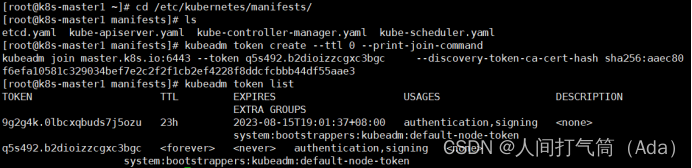
k8s-master2和k8s-master3都需要加入
[root@k8s-master2 ~]# kubeadm join master.k8s.io:6443 --token pj2haa.zf72tyum7uiyeamx --discovery-token-ca-cert-hash sha256:aaec80f6efa10581c329034bef7e2c2f2f1cb2ef4228f8ddcfcbbb44df55aae3 --control-plane
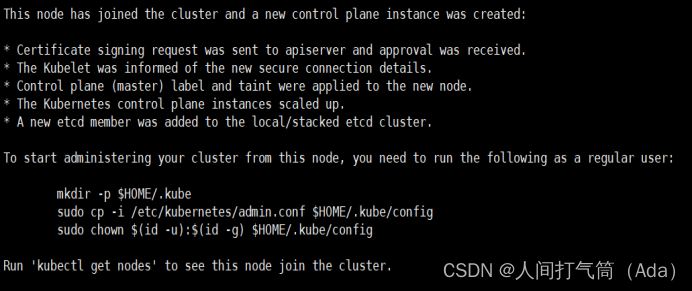
[root@k8s-master2 ~]# mkdir -p $HOME/.kube
[root@k8s-master2 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master2 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config

[root@k8s-master2 ~]# docker load < flannel_v0.12.0-amd64.tar
[root@k8s-master2 ~]# tar xf cni-plugins-linux-amd64-v0.8.6.tgz
[root@k8s-master2 ~]# cp flannel /opt/cni/bin/

[root@k8s-master1 ~]# kubectl get nodes

[root@k8s-master1 manifests]# kubectl get pods --all-namespaces

(九)加入Kubernetes Node
直接在node节点服务器上执行k8s-master1初始化成功后的消息即可:
[root@k8s-node1 ~]# kubeadm join master.k8s.io:6443 --token o3j9wj.58io4u28r6q8o9lj --discovery-token-ca-cert-hash sha256:6ad29ff932b12680844e140938eaeaaca120d6020c273b6b56d69d256fbc44b0

[root@k8s-node1 ~]# docker load < flannel_v0.12.0-amd64.tar

查看节点信息
[root@k8s-master1 ~]# kubectl get nodes

查看pod信息
[root@k8s-master1 ~]# kubectl get pods -n kube-system

(十)测试Kubernetes集群
1、所有node主机下载测试镜像
[root@k8s-node1 ~]# docker pull nginx:1.19.0

2、在Kubernetes集群中创建一个pod,验证是否正常运行。
[root@k8s-master1 ~]# mkdir demo
[root@k8s-master1 ~]# cd demo
[root@k8s-master1 demo]# vim nginx-deployment.yaml

3、创建完 Deployment 的资源清单之后,使用 create 执行资源清单来创建容器。
通过 get pods 可以查看到 Pod 容器资源已经自动创建完成。
[root@k8s-master1 demo]# kubectl create -f nginx-deployment.yaml
[root@k8s-master1 demo]# kubectl get pods
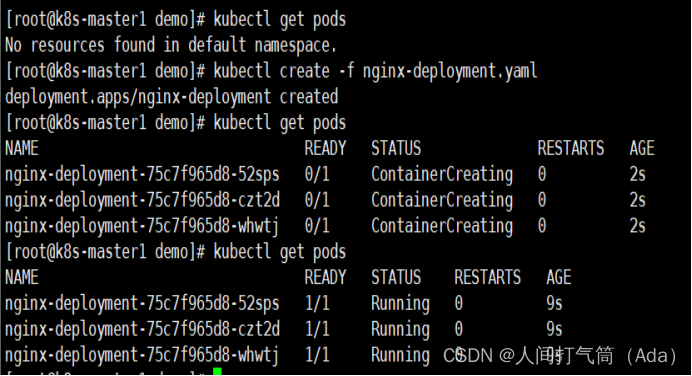
[root@k8s-master1 ~]# kubectl get pods -o wide

4、创建Service资源清单
在创建的 nginx-service 资源清单中,定义名称为 nginx-service 的 Service、标签选择器为 app: nginx、type 为 NodePort 指明外部流量可以访问内部容器。在 ports 中定义暴露的端口库号列表,对外暴露访问的端口是 80,容器内部的端口也是 80。
[root@k8s-master1 demo]# vim nginx-service.yaml

[root@k8s-master1 demo]# kubectl create -f nginx-service.yaml
[root@k8s-master1 demo]# kubectl get svc
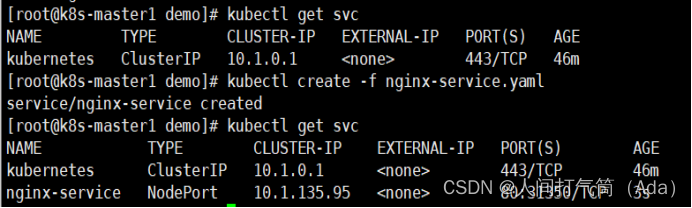
5、访问测试
通过浏览器访问nginx:http://master.k8s.io:31350 域名或者VIP地址
[root@k8s-master1 demo]# elinks --dump http://master.k8s.io:31350

浏览器测试:192.168.100.154:31350

【实验验证】
挂起k8s-master1节点,刷新页面还是能访问nginx,说明高可用集群部署成功。


检查会发现VIP已经转移到k8s-master2节点上
[root@k8s-master2 ~]# ip a s ens33

验证操作master
[root@k8s-master2 ]#kubectl get nodes

至此Kubernetes企业级高可用环境完美实现。
【拓展试验】
以此类推,停掉master2的服务,vip跳转至master3,服务仍保持

检查会发现VIP已经转移到k8s-master3节点上
[root@k8s-master3 ~]# ip a s ens33

验证操作master
[root@k8s-master3 ]#kubectl get nodes

两台宕机主机恢复,验证服务
Master1:

Master2:
Master3:

访问服务:
四、项目总结
1、集群中只要有一个master节点正常运行就可以正常对外提供业务服务。
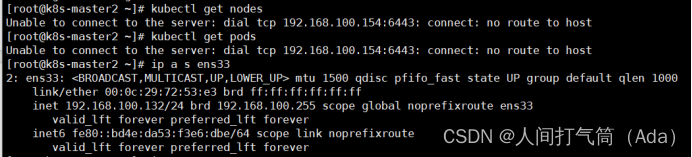
2、如果需要在master节点使用kubectl相关的命令,必须保证至少有2个master节点正常运行才可以使用,不然会有 Unable to connect to the server: net/http: TLS handshake timeout 这样的错误。
3、当一台可以查看nodes节点的master宕机之后,其余两台随机一台获取vip,然后可以观察nodes节点,但是当超过两台master宕机之后,集群需重建才可以观察nodes节点,但服务未停止;当两台宕机主机回复之后,服务停止,node节点不可观察,集群停止,需重建!
4、Node节点故障时pod自动转移:当pod所在的Node节点宕机后,根据 controller-manager的–pod-eviction-timeout 配置,默认是5分钟,5分钟后k8s会把pod状态设置为unkown, 然后在其它节点启动pod。当故障节点恢复后,k8s会删除故障节点上面的unkown pod。如果你想立即强制迁移,可以用 kubectl drain nodename
5、为了保证集群的高可用性,建议master节点和node节点至少分别部署3台及以上,且master节点应该部署基数个实例(3、5、7、9)。