提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 主从复制原理
- 主从复制原理图
- 一、概述
- 二、为什么要读写分离?
- 三、mysql支持的复制类型
- 1、基于语句的复制statement:
- 2、基于行的复制row:
- 3、混合类型的复制mixed:
- 四、MYSQL主从复制集群解决的问题
- (1) 数据分布 (Data distribution )
- (2) 负载平衡(load balancing)
- (3) 备份(Backups)
- (4) 高可用性和容错行 ( High availability and failove )
- 五、MYSQL主从复制集群种类
- 一主一从/一主多从
- 多主一从
- 双主复制:
- 级联复制:
- 六、Replication(复制
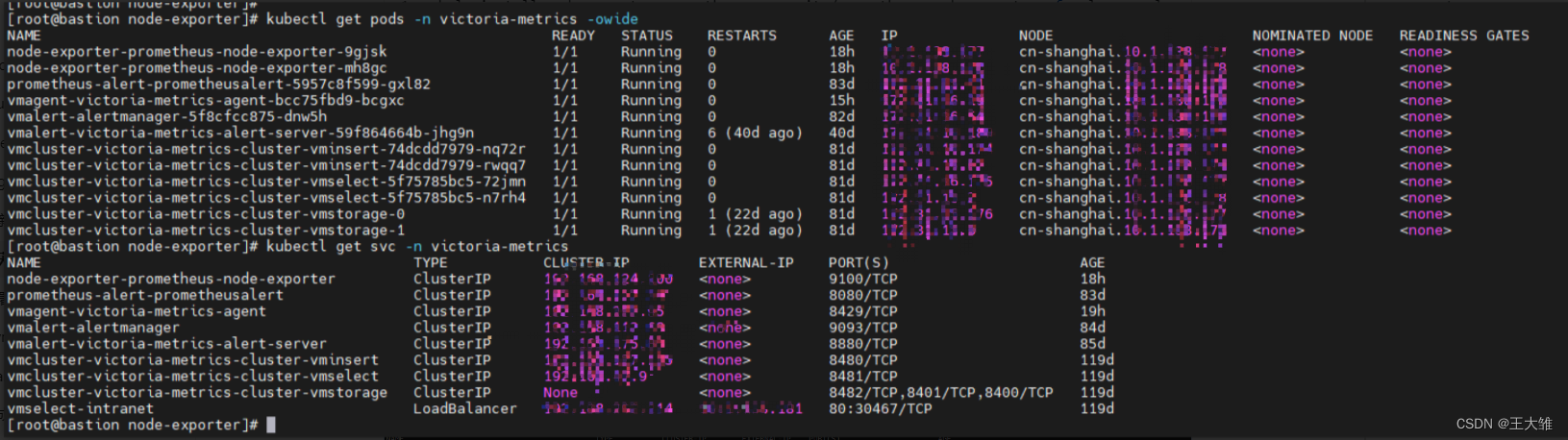
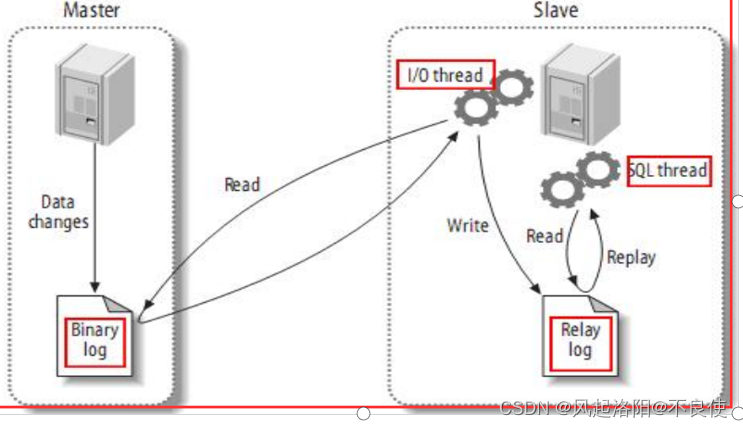
主从复制原理
1) Slave 上面的IO 线程连接上 Master,并请求从指定日志文件(二进制日志)的指定位置(或者从最开始的日志)之后的日志内容。 2) Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。
返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 BinaryLog 中的位置。
3)Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的RelayLog (中继日志文件)文件(MySQL-relay-bin.xxxxxx)的最末端,并将读取到的Master 端的bin-log 的文件名和位置记录到master-info 文件中,
以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log 的哪个位置开始往后的日志内容,请发给我” 。 4)Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。
这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
主从复制原理图
一、概述
Mysql内建的复制功能是构建大型,高性能应用程序的基础。将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的 数据复制到其它主机(slaves)上,并重新执行一遍来实现的。复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将更 新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。当一个从服务器连接主服务器时,它通知主服务器从服 务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。
请注意当你进行复制时,所有对复制中的表的更新必须在主服务器上进行。否则,你必须要小心,以避免用户对主服务器上的表进行的更新与对从服务器上的表所进行的更新之间的冲突。
二、为什么要读写分离?
高并发场景下MySQL的一种优化方案,依靠主从复制使得MySQL实现了数据复制为多份,增强了抵抗 高并发读请求的能力,提升了MySQL查询性能同时,也提升了数据的安全性。当某一个MySQL节点,无论是主库还是从库故障时,还有其他的节点中存储着全量数据,保证数据不会丢失。
主库将变更写binlog日志,然后从库连接到主库后,从库有个I/O线程,将主库的binlog日志拷贝到本地,写入一个中继日志。 接着从库中有一个SQL线程会从中继日志读取binlog,然后执行binlog日志中的内容。即在本地再次执行一遍SQL,确保跟主库的数据相同。
简单点说:读写分离的实现是基于主从复制架构:单主单从或一主多从,只写主库,主库会自动将数据同步到从库。
三、mysql支持的复制类型
1、基于语句的复制statement:
在主服务器上执行的SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率比较高。如果要用精确复制时,还是建议使用基于行的复制。
2、基于行的复制row:
把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从mysql5.0开始支持
3、混合类型的复制mixed:
默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
具体基于哪种类型其实还是要看你的BINLOG日志类型。
四、MYSQL主从复制集群解决的问题
MySQL复制技术有以下一些特点:
(1) 数据分布 (Data distribution )
(2) 负载平衡(load balancing)
(3) 备份(Backups)
(4) 高可用性和容错行 ( High availability and failove )
五、MYSQL主从复制集群种类
一主一从/一主多从
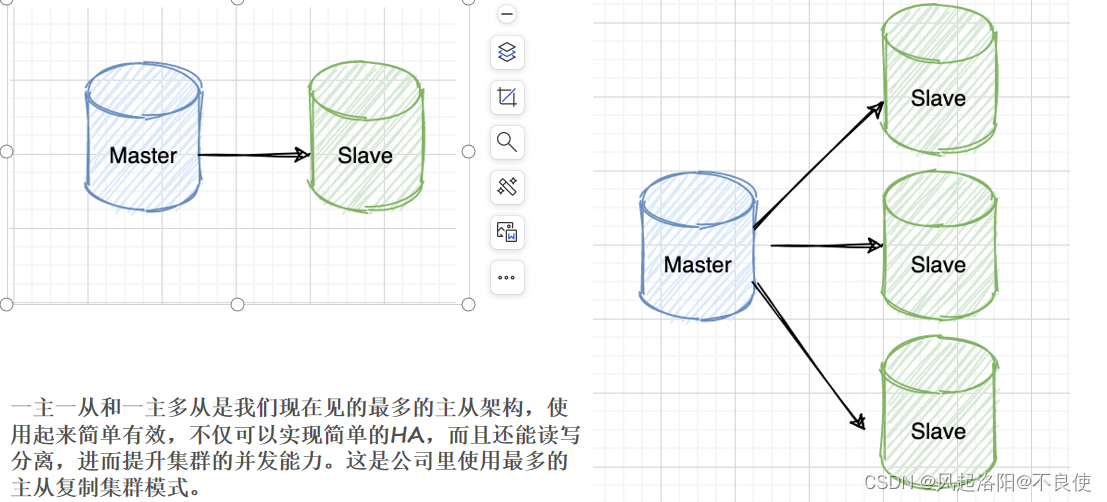
一主一从和一主多从是我们现在见的最多的主从架构,使用起来简单有效,不仅可以实现简单的HA,而且还能读写分离,进而提升集群的并发能力。这是公司里使用最多的主从复制集群模式。
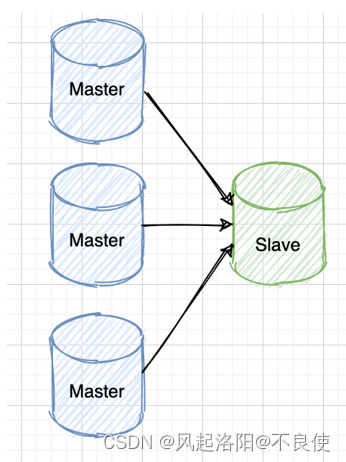
多主一从
多主一从:多主一从可以将多个 MySQL 数据库备份到一台存储性能比较好的服务器上。
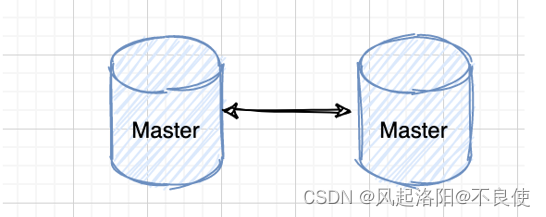
双主复制:
双主复制,也就是可以互做主从复制,每个 master 既是 master,又是另外一台服务器的 salve。这样任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
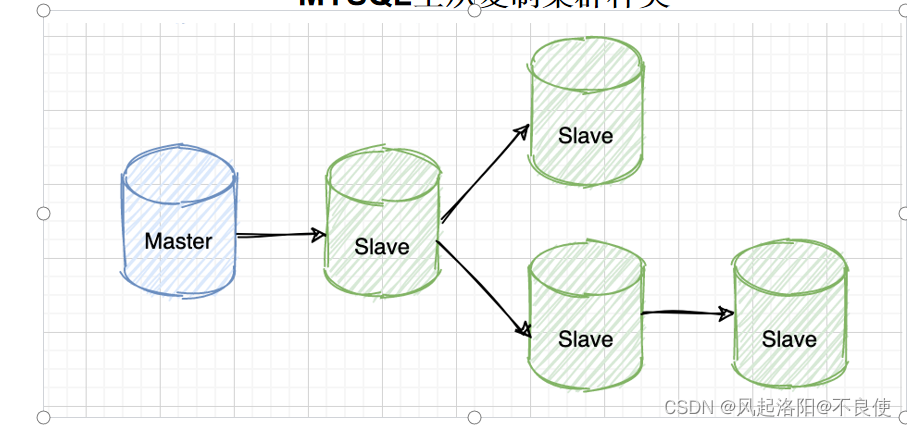
级联复制:
级联复制模式下,部分 slave 的数据同步不连接主节点,而是连接从节点。因为如果主节点有太多的从节点,就会损耗一部分性能用于 replication ,那么我们可以让 3~5 个从节点连接主节点,其它从节点作为二级或者三级与从节点连接,这样不仅可以缓解主节点的压力,并且对数据一致性没有负面影响。
六、Replication(复制
这里是引用
)管理和排错
1)show master status ; 查看master的状态, 尤其是当前的日志及位置
2)show slave status; 查看slave的状态.
3)reset slave (all); 重置slave状态,用于删除SLAVE数据库的relaylog日志文件,并重新启用新的relaylog文件.会忘记 主从关系,它删除master.info文件和relay-log.info 文件
4)start slave ; 启动slave 状态(开始监听mastter的变化)
5)stop slave; 暂停slave状态;
6)set global sql_slave_skip_counter = n 跳过导致复制终止的n个事件,仅在slave线程没运行的状况下使用