# 创建BinaryLabelDatasetMetric对象,传入原始训练数据集dataset_orig_train,以及privileged_groups和unprivileged_groups的定义
metric_orig_train = BinaryLabelDatasetMetric(dataset_orig_train,
unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups)
display(Markdown("#### Original training dataset"))
print("Difference in mean outcomes between unprivileged and privileged groups = %f" % metric_orig_train.mean_difference())
编译后显示差值为 -0.169905。
3.6、通过转换原始数据集来缓解偏差
尝试减轻训练数据集中的偏见被称为预处理去偏,因为它发生在创建模型之前。
AI Fairness 360 实现了多种预处理缓解算法,选择重新加权算法(通过改变样本权重的方式来减少数据集中不同群体之间的偏差),该算法在包中的类中实现。此算法将转换数据集,使其在特权组和非特权组的受保护属性的积极结果上具有更大的公平性。
metric_transf_train = BinaryLabelDatasetMetric(dataset_transf_train,
unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups)
display(Markdown("#### Transformed training dataset"))
print("Difference in mean outcomes between unprivileged and privileged groups = %f" % metric_transf_train.mean_difference())
DaVinci Resolve Studio 18是一款专业的视频编辑和调色软件,适用于电影、电视节目、广告等各种视觉媒体的制作。它具有完整的后期制作功能,包括剪辑、调色、特效、音频处理等。 以下是DaVinci Resolve Studio 18的主要特点: - 提供了全面的视…
es 概念
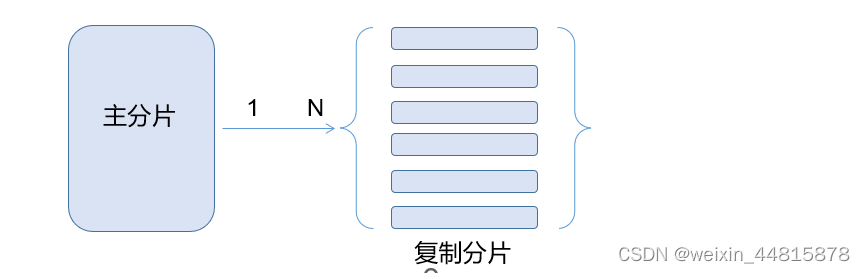
Elasticsearch是分布式实时搜索、实时分析、实时存储引擎,简称(ES)成立于2012年,是一家来自荷兰的、开源的大数据搜索、分析服务提供商,为企业提供实时搜索、数据分析服务,支持PB级的大数据。 -- …
msvcp140.dll是Windows操作系统的一个动态链接库文件,它是Microsoft Visual C Redistributable的一部分。这个文件在运行某些应用程序时非常重要。然而,在某些情况下,msvcp140.dll文件可能会损坏或遗失,导致应用程序无法正常运行。…












![[已解决]使用sqlplus连接oracle,提示ORA-01034和ORA-27101](https://img-blog.csdnimg.cn/1e5cbb04c1e74f8bbfc41e1dacc5956a.png)