本文对应Aggregation Operations — MongoDB Manual

正文
此章节主要介绍了Aggregation Pipeline,其实就是将若干个聚合操作放在管道中进行执行,每一个聚合操作的结果作为下一个聚合操作的输入,每个聚合指令被称为一个stage。
在正式开始学习聚合操作前,请先按照下面的方式在你的mongodb中创建数据可和插入记录:
首先通过创建数据库和表,我这里为了方便直接使用可视化工具Robo3T(官网推荐)来进行操作
然后直接通过下面指令添加记录
db.orders.insertMany( [
{ _id: 0, name: "Pepperoni", size: "small", price: 19,
quantity: 10, date: ISODate( "2021-03-13T08:14:30Z" ) },
{ _id: 1, name: "Pepperoni", size: "medium", price: 20,
quantity: 20, date : ISODate( "2021-03-13T09:13:24Z" ) },
{ _id: 2, name: "Pepperoni", size: "large", price: 21,
quantity: 30, date : ISODate( "2021-03-17T09:22:12Z" ) },
{ _id: 3, name: "Cheese", size: "small", price: 12,
quantity: 15, date : ISODate( "2021-03-13T11:21:39.736Z" ) },
{ _id: 4, name: "Cheese", size: "medium", price: 13,
quantity:50, date : ISODate( "2022-01-12T21:23:13.331Z" ) },
{ _id: 5, name: "Cheese", size: "large", price: 14,
quantity: 10, date : ISODate( "2022-01-12T05:08:13Z" ) },
{ _id: 6, name: "Vegan", size: "small", price: 17,
quantity: 10, date : ISODate( "2021-01-13T05:08:13Z" ) },
{ _id: 7, name: "Vegan", size: "medium", price: 18,
quantity: 10, date : ISODate( "2021-01-13T05:10:13Z" ) }
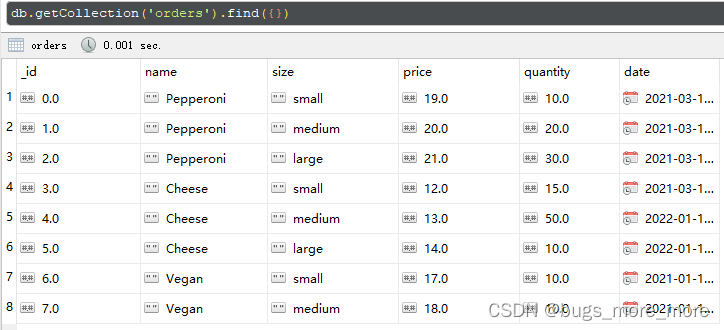
] )上面插入的数据,用Robo3T的表格形式显示一下如下:
现在有了数据后,我们开始正式学习聚合操作相关的指令
运行聚合操作,使用的命令为
db.collection.aggregate() 下面开始学习聚合相关的指令
- $match
$match相当于sql中的where条件,来看例子:
例子:将表中,size字段为medium的记录查询出来db.orders.aggregate( [ { $match: { size: "medium" } } ] )
- $group
$group就是分组的意思,看例子
例子:查找size为medium,并且对其进行分组显示db.orders.aggregate( [ // Stage 1: Filter pizza order documents by pizza size { $match: { size: "medium" } }, // Stage 2: Group remaining documents by pizza name and calculate total quantity { $group: { _id: "$name", totalQuantity: { $sum: "$quantity" } } } ] )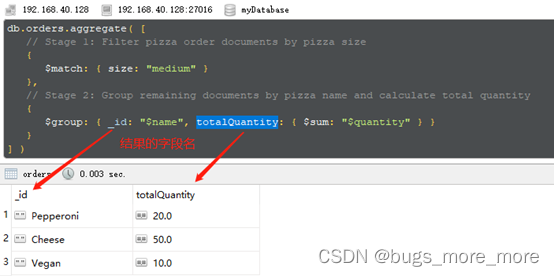
在这个例子中我们就会看到聚合操作中所谓的pipeline的用法,例子中我们用了$match和$group两个指令,他们的执行是分为2个阶段(stage),第一个阶段通过$match来进行数据的过滤,将满足的数据作为$group指令的输入,$group指令将$match的结果进行分组。后面的例子中全都是这种pipeline方式的聚合操作。
-
$project
$project用来指定只输出哪些字段,看例子
例子:查询name字段为Pepperoni的记录,并且只显示_id和name两个字段db.orders.aggregate( [ { $match: { name: "Pepperoni"} }, { $project: { _id: 1, name: 1} } ] )
通过$project我们指定结果中只显示_id和name字段,注意的是,在$match这个阶段输出的结果中包含了所有的字段,而只有在$project这个阶段,才将所以字段中的_id和name两个字段拿出来显示。 -
$sort
$sort就是就它上面阶段输出的内容进行排序的作用,看例子
例子:查询name字段为Pepperoni的记录按照_id进行排序,并且只显示_id和name两个字段.db.orders.aggregate( [ // Stage 1: Filter pizza order documents by date range { $match: { name: "Pepperoni"} }, { $project: { _id: 1, name: 1} }, { $sort:{_id:-1} // -1:倒序 | 1:正序 } ] )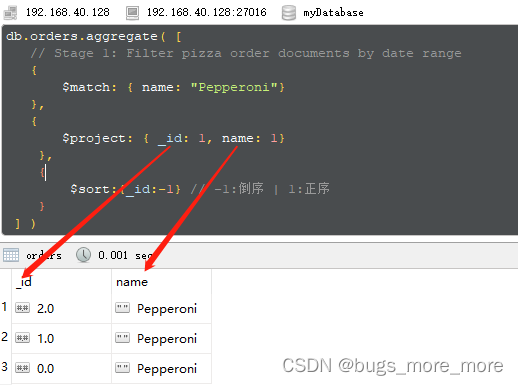
关于更多的aggregate Pipeline的的指令这里就全部列出来了,大家可以到官网中查询剩余的其他指令,下面讲一下关于使用aggregate pipeline的一些限制
- 在使用aggregate命令执行聚合操作是,对于发挥结果是由限制的,也就是你返回的json内容大小不能超过16 megabyte(16MB)
- 上面介绍的这些例如$project,$sort这些用在pipeline中的指令不能超过1000个(每个指令被称为一个阶段stage)阶段
- 当查询结果大于16MB时,会默认使用磁盘来存储结果,可以通过
{ allowDiskUse: false }来禁用这个写入磁盘的操作。
Aggregation Pipeline and Sharded Collections
就是当我们的mongdb是在分片模式下,如何使用聚合操作