日常遍历的几种方式
首先我们先了解一下集合容器中日常遍历的几种方式:
List集合遍历方式(ArrayList)
// 遍历list集合
private static void listTest() {
List<String> list = new ArrayList<String>();
list.add("liubei");
list.add("guanyu");
list.add("zhangfei");
// 使用传统for循环进行遍历
for (int i = 0, size = list.size(); i < size; i++) {
String value = list.get(i);
System.out.println(value);
}
// 使用增强for循环进行遍历 与iterator迭代器一致
for (String value : list) {
System.out.println(value);
}
// 使用iterator遍历
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String value = it.next();
System.out.println(value);
}
//ArrayList 继承父类 Iterable 重写forEach 方法,进行相应校验判断,传统fori循环调用accept输出
list.forEach(new Consumer<String>() {
@Override
public void accept(String key) {
System.out.println(key);
}
});
//Lambda 函数式Consumer
list.forEach(key -> {
System.err.println(key);
});
}Set集合遍历方式(HashSet)
private static void setTest() {
Set<String> set = new HashSet<String>();
set.add("JAVA");
set.add("C");
set.add("C++");
// 使用iterator遍历set集合
Iterator<String> it = set.iterator();
while (it.hasNext()) {
String value = it.next();
System.out.println(value);
}
// 使用增强for循环遍历set集合 字节码查看底层实际也是Iterator迭代器实现,与上面一样,写法区别而已
for (String s : set) {
System.out.println(s);
}
//HashSet 继承父类 Iterable 直接调用父类forEach循环Consumer this 迭代器 循环accept方式
set.forEach(new Consumer<String>() {
@Override
public void accept(String key) {
System.err.println(key);
}
});
//Lambda 函数式Consumer
set.forEach(key -> {
System.err.println(key);
});
}Map集合容器的遍历方式(HashMap)
public static void mapTest() {
Map<String, String> maps = new HashMap<String, String>();
maps.put("1", "PHP");
maps.put("2", "Java");
maps.put("3", "C");
maps.put("4", "C++");
maps.put("5", "HTML");
Set<Map.Entry<String, String>> set = maps.entrySet();
//取key的增强遍历 实际 迭代器行为
Set<String> keySet = maps.keySet();
for (String s : keySet) {
String key = s;
String value = maps.get(s);
System.out.println(key + " : " + value);
}
// 增强循环 实际 迭代器行为
for (Map.Entry<String, String> entry : set) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " : " + value);
}
// 迭代器遍历。
Iterator<Map.Entry<String, String>> it = set.iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = (Map.Entry<String, String>) it.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " : " + value);
}
//HashMap 重写Map接口的forEach默认实现,进行相应的判断,传统fori遍历数组形式
maps.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.err.println(key + " : " + value);
}
});
//Lambda 函数式Consumer
maps.forEach((key,value)->{
System.err.println(key + " : " + value);
});
}for 增强循环遍历方式
for(声明语句 : 表达式)
{
//代码句子
}声明语句:
声明新的局部变量,该变量的类型必须和数组元素的类型匹配。其作用域限定在循环语句块,其值与此时数组元素的值相等。
表达式:
表达式是要访问的数组名,或者是返回值为数组的方法。
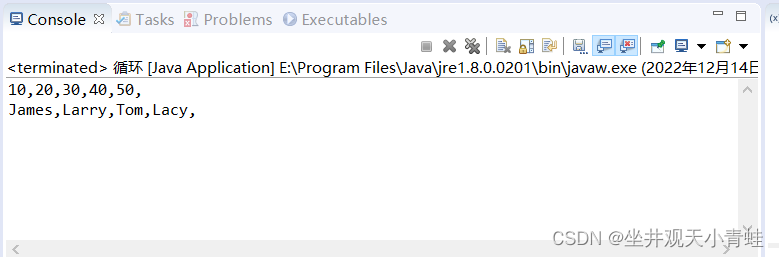
Java文件代码:
public class Test {
public static void main(String[] args){
int [] numbers = {10, 20, 30, 40, 50};
for(int x : numbers ){
System.out.print( x );
System.out.print(",");
}
System.out.print("\n");
String [] names ={"James", "Larry", "Tom", "Lacy"};
for( String name : names ) {
System.out.print( name );
System.out.print(",");
}
}
}
遍历对象
package two;
public class Test2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
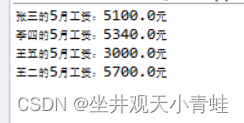
Employee[] em = new Employee[4];//创建一个Employee 数组em
em[0]=new SalariedEmployee("张三",5,5000);//创建一个子类的对象
em[1]=new HourlyEmployee("李四",3,30,172);
em[2]=new SalesEmployee("王五",4,10000,0.3);
em[3]=new BasePlusSalesEmployee("王二",5,20000,0.03,5000);
for(Employee e:em) {
System.out.println(e.getName()+"的5月工资:"+e.getSalary(5)+"元");
}
}
}
遍历的问题
1、用那种遍历更好呢!
2、遍历的时候能操作(增删)集合信息么!
3、遍历中断、跳过怎么玩的!
每次撸代码的时候都会或多或少的思考一下这些问题,这也是基本工。
第一个问题:用那种遍历更好呢!
个人理解,主要还是要看业务中需要遍历的是什么类型的集合(数组),内部需要怎么操作,有时候就是需要获取根据下标位置进行业务逻辑处理,那就需要传统的for循环了。若是只是遍历进行key处理不涉及下标位置的,一般会选择foreach形式,比较简单快捷,其内部原理还是Iterator迭代器行为,Iterator一般不写主要原因比较麻烦复杂了点。
![[附源码]Python计算机毕业设计房屋租赁系统Django(程序+LW)](https://img-blog.csdnimg.cn/3f551495df91423e919043919d2f7451.png)




![[附源码]Python计算机毕业设计Django基于SpringBt的演唱会购票系统论文2022](https://img-blog.csdnimg.cn/ca065841e7154c4683b166faa9c6e6bd.png)