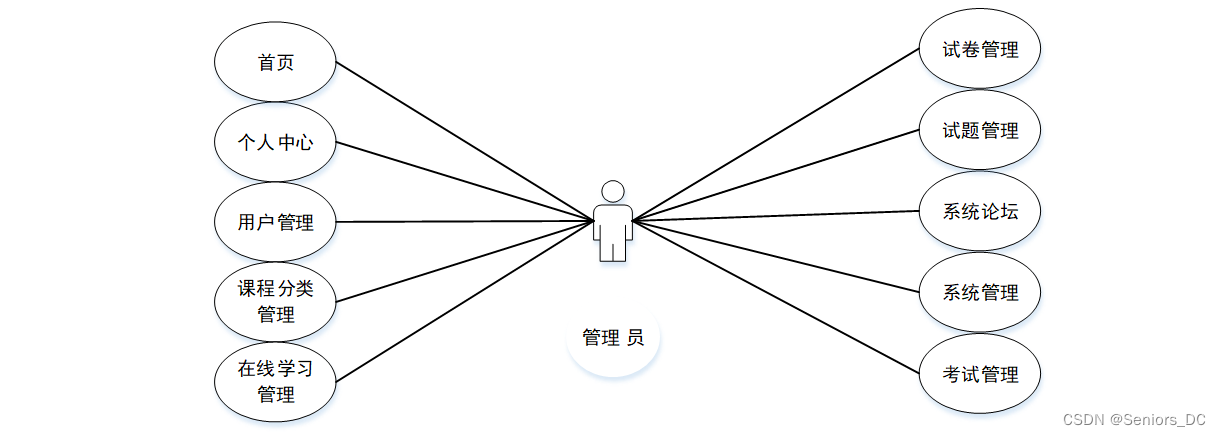
文章目录
- 一、前言
- 二、data2vec 2.0 是如何工作的
- 三、使用 data2vec 2.0 提高效率
- 四、总结
CSDN 叶庭云:https://yetingyun.blog.csdn.net/
一、前言
论文地址:Data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language

人工智能最近的许多突破都是由自监督学习(self-supervised learning)推动的,它使机器不依赖于标记数据进行学习。
但是目前的算法都有一些明显的局限性:
- 通常包括专门用于单一模态(如图像或文本),并需要大量的计算资源(算力和内存);
- 这与人类的学习形成了鲜明的对比:人类似乎比当前的人工智能学习效率更高,而且也以类似的方式从不同模态的信息(视觉、听觉、嗅觉)中学习,而不是依赖于图像、文本、语音和其他形式的单独学习机制。
Meta AI 在今年早些时候解决了这些限制之一,当时发布了 data2vec,这是第一个高性能的自监督学习算法,可以用同样的方式学习三种不同的模态:语音、视觉和文本。data2vec 使得将文本理解等前沿的研究进展应用于图像分割或语音翻译任务变得更加容易。
Meta AI 开源的 data2vec 2.0,这是一种新的算法,它的效率大大提高且性能优于其前身。它达到了与现有最流行的计算机视觉自监督算法相同的精度,但是速度快了 16 倍。为了使 data2vec 对其他研究人员开放,Meta AI 开源了代码和预训练好的模型。
二、data2vec 2.0 是如何工作的
自监督学习的基本思想是让机器通过观察世界自主来学习图像、语音和文本的结构,而无需标记信息。自监督学习的进展导致了语音(如 wave2vec)、计算机视觉(如 Masked Autoencoders)和自然语言处理(如 BERT)研究领域的许多突破。但是现代系统可能需要大量计算资源,因为训练非常大的模型需要许多 GPUs。
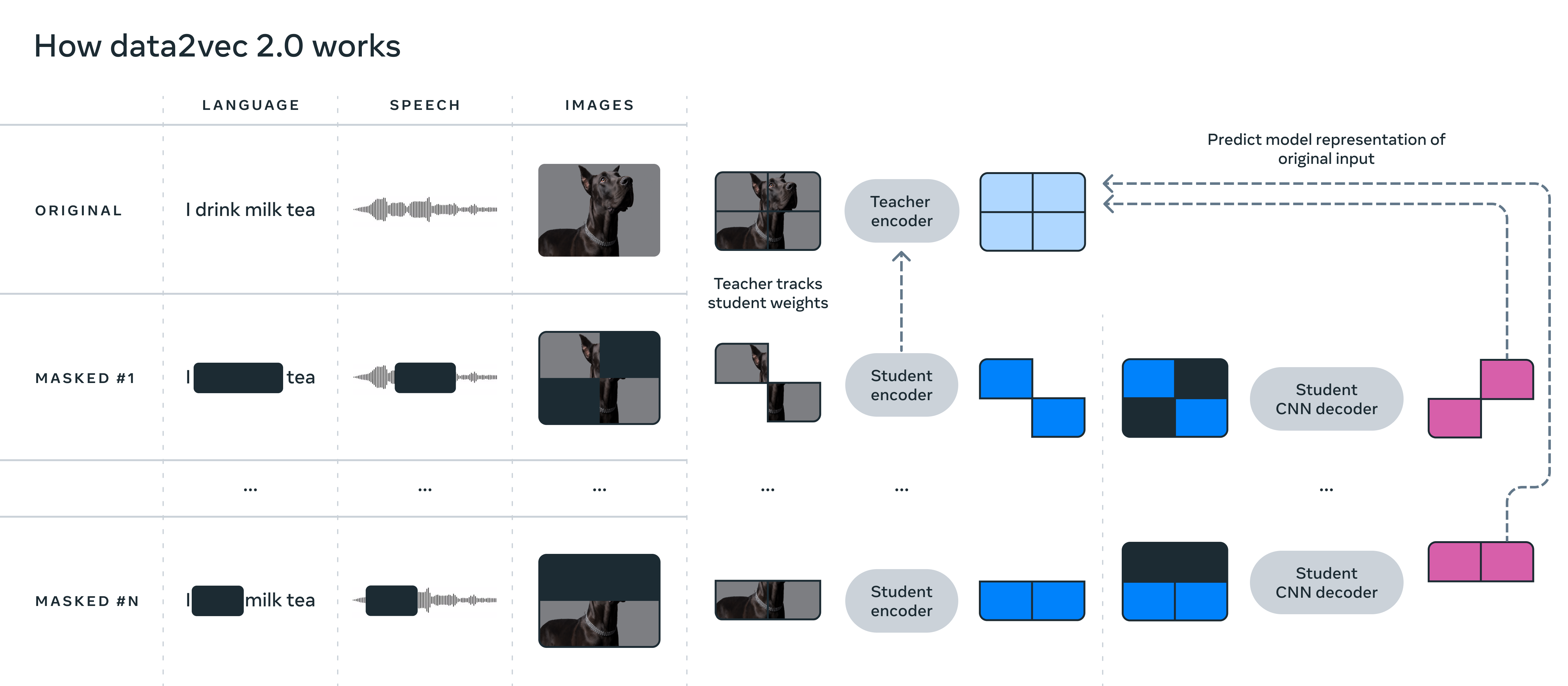
上图展示了 data2vec 2.0 训练的工作原理,可以单独对文本、语音或图像进行训练。
与最初的 data2vec 算法类似,data2vec 2.0 预测数据的上下文化表示(contextualized representations)或神经网络的 layers,而不是图像的像素、文本段落的词语或语音。与大多数其他算法不同,这些所谓的目标表示是 contextualized 的,这意味着它们将整个训练示例考虑在内。例如,单词 bank 的表示基于单词出现的整个句子来考虑,因此更容易表示单词的正确意思(“金融机构” 或 “河边的土地”)。研究者相信上下文化的目标(contextualized targets)会促进更丰富的学习任务,并使 data2vec 2.0 比其他算法学习得更快。
通过几种方式提高了原始 data2vec 算法的效率:
- 首先,获取为特定训练示例构建的目标表示,并将它们重用于掩码版本(在掩码版本中,隐藏了训练示例的不同随机部分);将每个版本提供给学生模型(student model),学生模型为不同的 masked versions 预测相同的上下文化的目标表示;这有效地分摊了创建目标表示所需的计算工作。
- 其次,类似于 masked autoencoders,对于训练示例中被删除的部分(在实验的例子中大约是图像的 80%)不运行学生编码器网络,从而显著节省了计算周期。
- 最后,使用了一个更有效的解码器模型,它不依赖于 Transformer 网络,而是依赖于一个多层卷积网络。
三、使用 data2vec 2.0 提高效率
将 data2vec 2.0 训练到与同一硬件上流行的现有算法相同的精度时,相对训练时间得到明显改善。如下图所示:
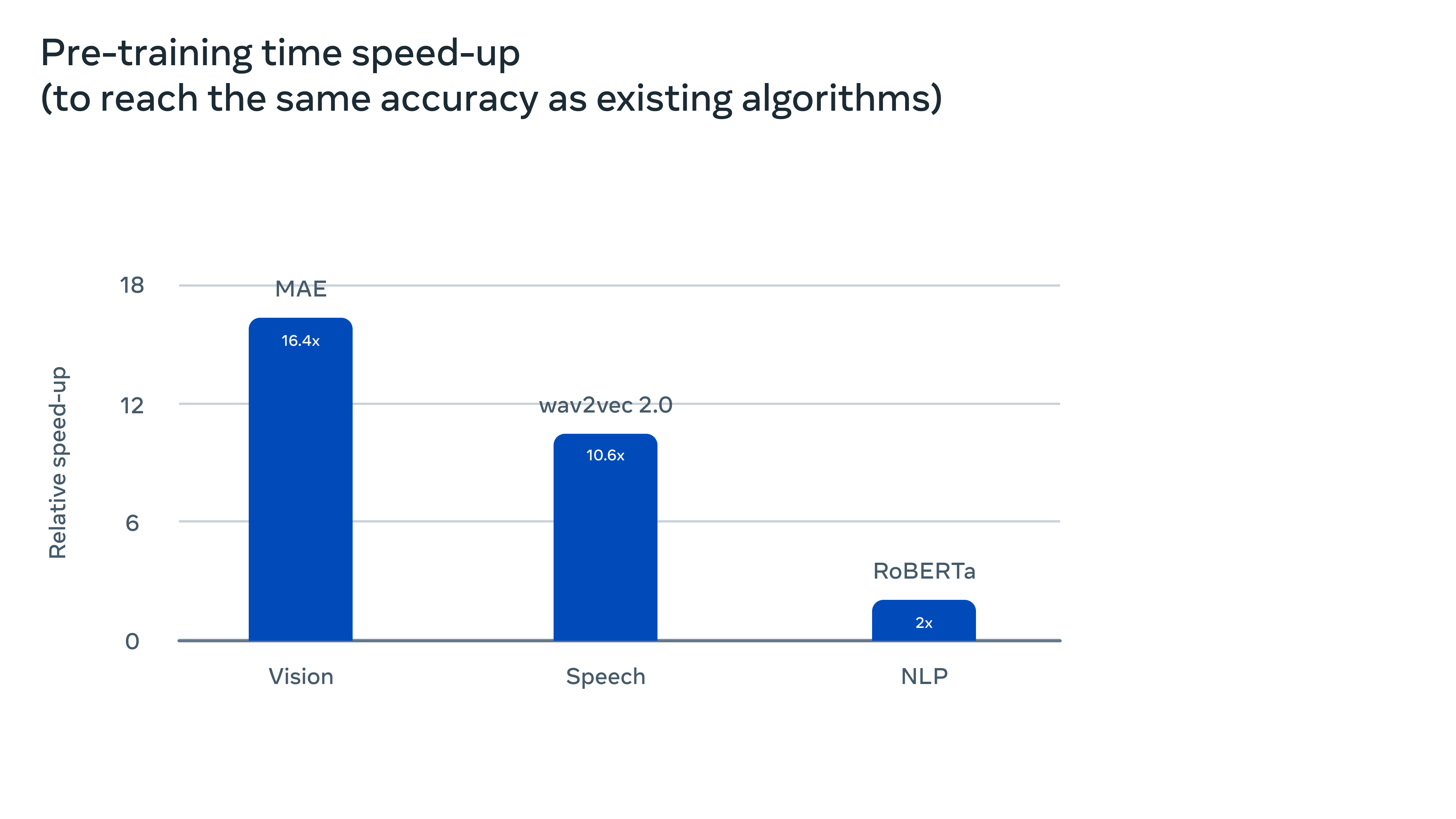
为了更好地理解 data2vec 2.0 比它的前辈和其他算法高效多少,研究者在计算机视觉、语音和文本任务上对它进行了广泛使用的基准测试。考虑最终的精确度以及预训练模型所需的时间,在相同的硬件上测量了算法的速度(GPU 的数量等等)。
对于计算机视觉,在标准 ImageNet-1K 图像分类基准上评估了 data2vec 2.0,在那里它学会了表示图像。Data2vec 2.0 获得等同于掩码自动编码器(MAE)的准确性时,速度要快 16 倍(在对等设置中以挂钟时间衡量)。如下所示:
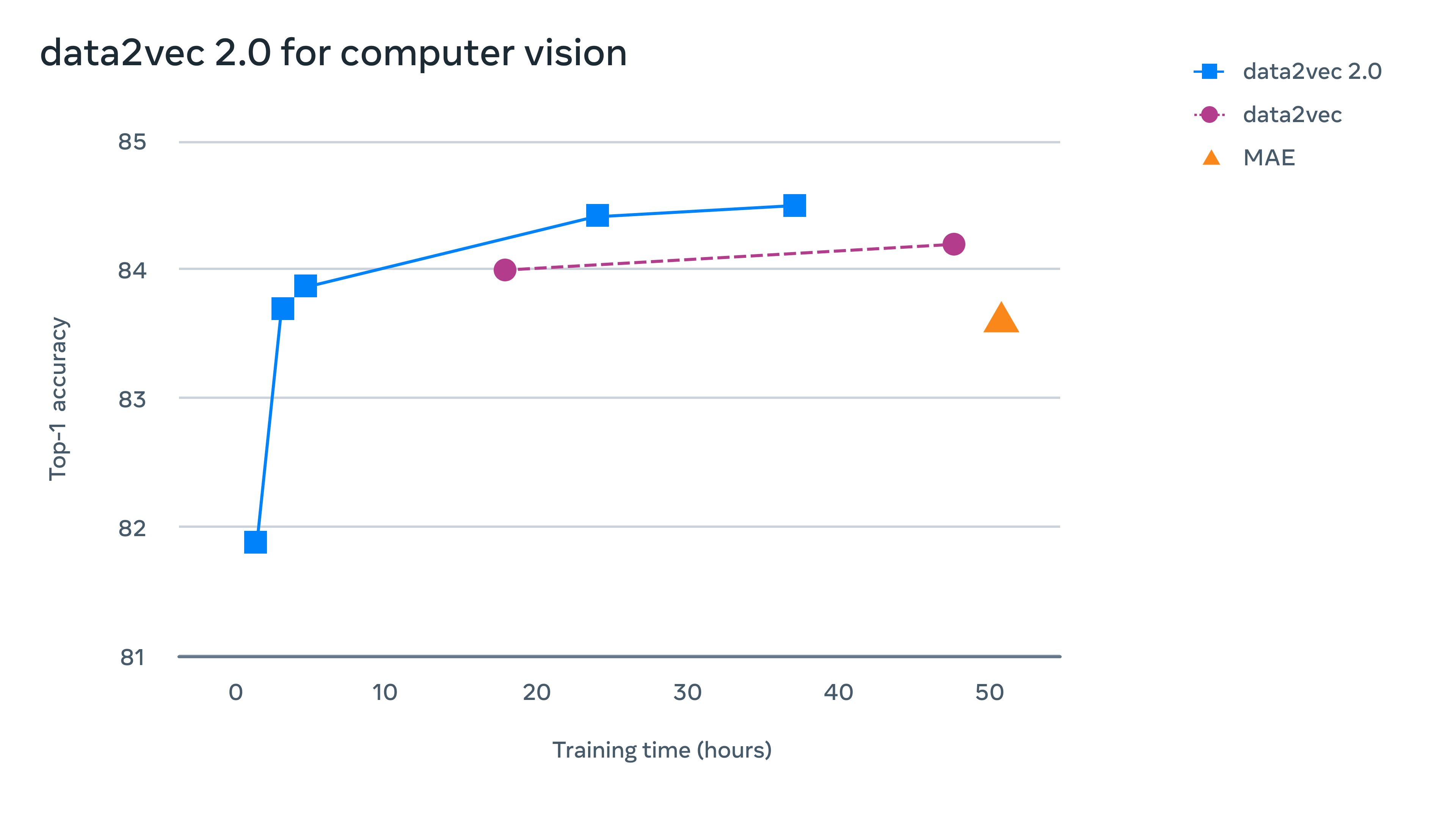
用于计算机视觉的 Data2vec 2.0:该图显示了在流行的 ImageNet-1K 基准数据集上不同算法的速度和图像分类精度。
对于语音,在 LibriSpeech 语音识别基准上进行了测试,它的表现比 wav2vec 2.0 快 11 倍以上,而且准确率相似。对于自然语言处理(NLP),在流行的通用语言理解评估(GLUE)基准上评估了 data2vec 2.0,在一半的训练时间内,它达到了与 RoBERTa (BERT 的重新实现)相同的精度。
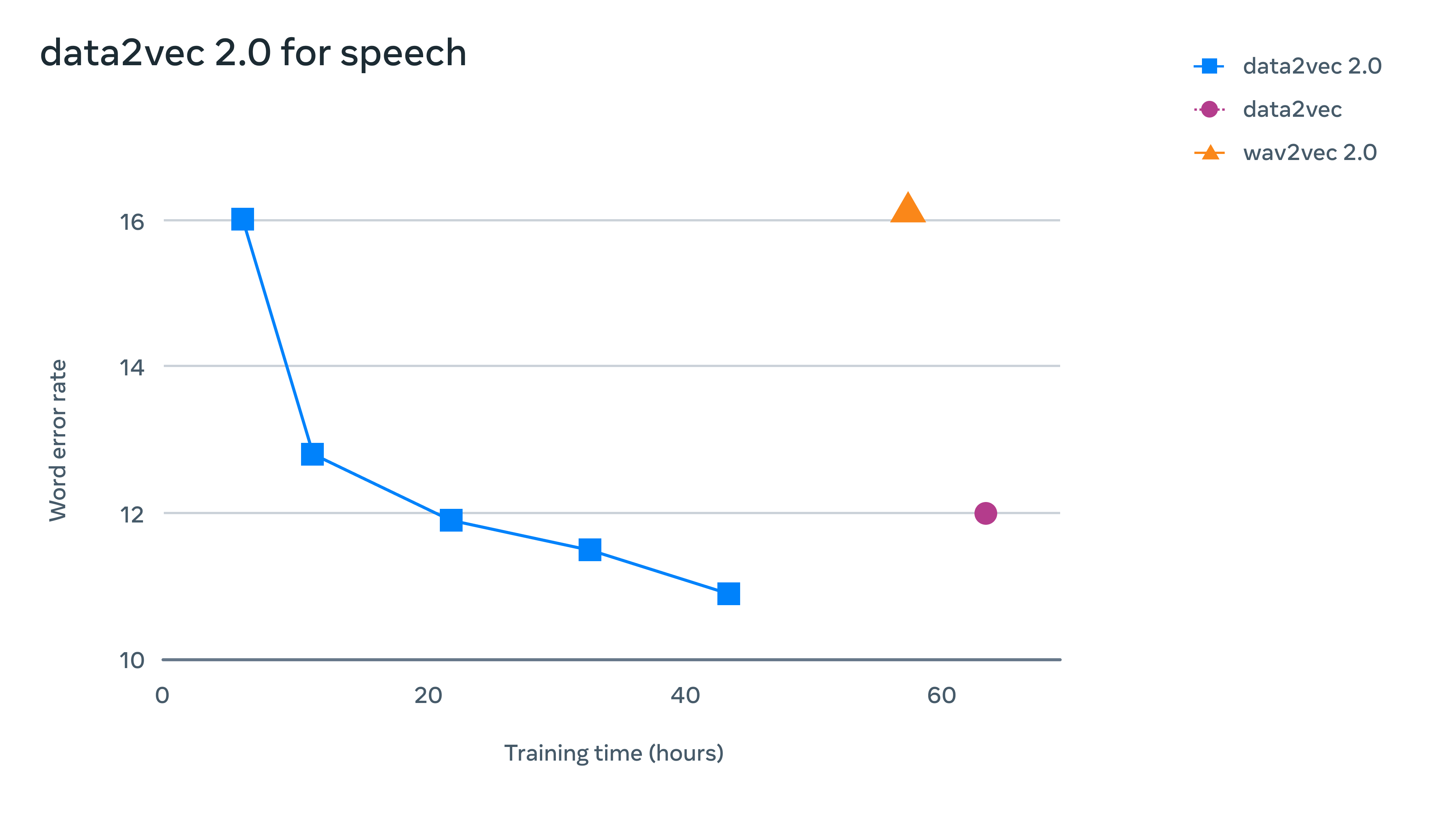
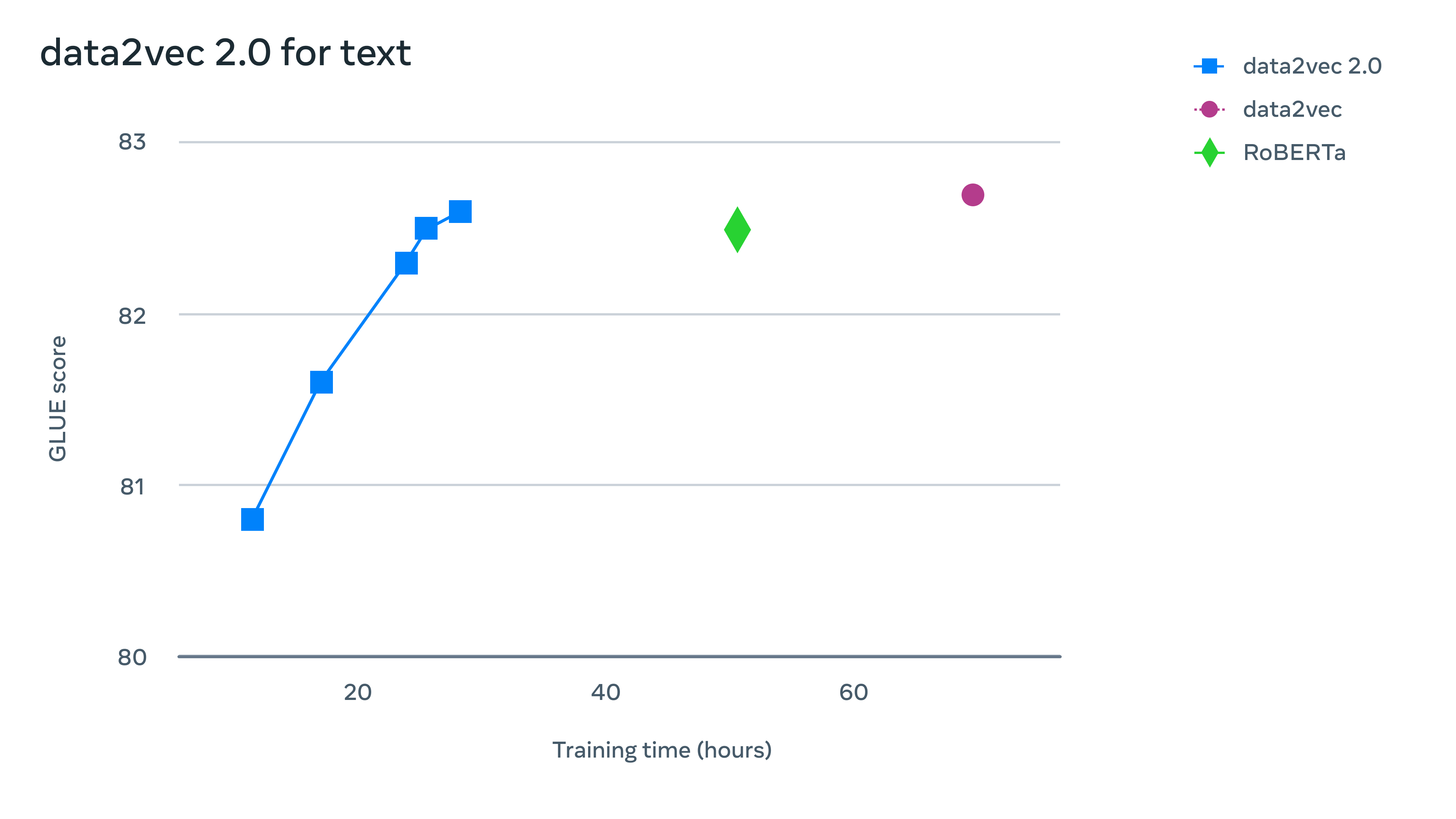
如上所示,用于语音和 NLP 的 data2vec 2.0:第一张图显示了在 LibriSpeech 上预训练的模型的速度与语音识别单词错误率,在 10 小时的 Libri-light 数据上进行了微调,然后在 dev-other 上评估。第二张图显示了使用原始 BERT 设置时 GLUE 基准的自然语言理解准确性。
四、总结
Meta AI 宣布推出 data2vec 2.0,这是一种由 Meta AI 为语音、视觉和文本构建的新型通用自监督算法,在达到相同精度的同时,训练模型的速度比最流行的现有图像算法快 16 倍。
迈向高效学习的机器。Meta AI 正在构建一个更通用和有效的自监督学习算法,使用一个单一的学习目标却能从不同的模态有效学习。更有效地学习的能力对于视频这样的模态尤其重要,因为它需要大量的计算工作来处理。我们希望像 data2vec 2.0 这样更有效的自监督学习算法将使机器能够深入理解极其复杂的数据,例如整部电影的内容。
Github 代码:https://github.com/facebookresearch/fairseq/tree/main/examples/data2vec
论文:Data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
参考资料:
- Meta AI | Data2vec 2.0: Highly efficient self-supervised learning for vision, speech and text
- 论文 | Data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language

![[附源码]Python计算机毕业设计Django基于SpringBt的演唱会购票系统论文2022](https://img-blog.csdnimg.cn/ca065841e7154c4683b166faa9c6e6bd.png)



![[附源码]Python计算机毕业设计SSM基于JAVA语言的国风画展网站(程序+LW)](https://img-blog.csdnimg.cn/30bbb9415dc34032bb777c9df6742ef7.png)