本文主要分享如何快速上手ARM汇编开发的经验、汇编开发中常见的Bug以及Debug方法、用的Convolution Dephtwise算子的汇编实现相对于C++版本的加速效果三方面内容。

前言
神经网络模型能够在移动端实现快速推理离不开高性能算子,直接使用ARM汇编指令来进行算子开发无疑会大大提高算子的运算性能。初次接触汇编代码可能会觉得其晦涩难懂然后望而却步,但ARM汇编开发一旦入门就会觉得语言优美简洁,如果再切换到ARM INTRISIC指令开发反而觉得没有直接写汇编码来的方便。我会在第一节分享纯小白如何快速上手ARM汇编开发的经验,第二节会列举在汇编开发中常见的Bug以及Debug方法,第三节会展示常用的Convolution Dephtwise算子的汇编实现相对于C++版本的加速效果。如果你已经能很熟练地使用ARM汇编指令进行开发了,可以跳过第一节。

从简单函数上手
学习汇编开发重要的一点是通过学习现有函数的汇编代码来实现自己的需求
我写的第一个汇编算子是MaxPooling算子,算子本身的计算过程非常简单。但当我开始实现MaxPooling的汇编代码时,我不知道第一行代码怎么写,不知道开头和结尾怎么写,不知道中间的计算逻辑怎么写。当时我就在MNN库的source文件夹下面找到了一份逻辑简单的、自己非常熟悉的Relu算子当做参照来实现MaxPooling. 之所以我推荐用一个逻辑简单的、自己非常熟悉的算子当做学习汇编的模版,是因为当算子的计算逻辑简单时,我们才能把注意力放在汇编函数的声明、传参、读取数据、存储结果、返回等等这些大的流程上面,至于内部的函数实现(如何计算一行数据的最大值,如何去计算一个寄存器中所有数据的累加和等等)可以暂时不去关注。学习一个新的东西时,我们找的例子模版不能过于复杂,因为这会导致我们将注意力放在例子本身的实现细节中,而忽略了如何去入门,这样会增加我们的学习成本。
▐ 汇编函数的开头与结尾
函数定义以asm_function开头,后加函数名(以MNNAvgPoolInt8 ARM64为例):
asm_function MNNAvgPoolInt8
// 加上函数的传参注释,方便后续对照使用对应的寄存器
// void MNNAvgPoolInt8(int8_t* dst, int8_t* src, size_t outputWidth,
// size_t inputWidth, size_t kernelx, size_t kernely, size_t stridesx,
// ssize_t paddingx, ssize_t factor);
// Auto load: x0: dst, x1: src, x2: outputWidth, x3: inputWidth,
// x4: kernelx, x5: kernely, x6: stridesx, x7: paddingx
// Load from sp:
// w8: factor传参:ARM64 用于传参的寄存器有8个:x0-x7. 如果函数的参数大于8,就需要使用sp寄存器读取剩余参数。例如AvgPoolInt8算子中的第9个参数factor读取:
// x8寄存器存储参数factor的值,不是必须使用x8寄存器,用其他寄存器也是可以的。
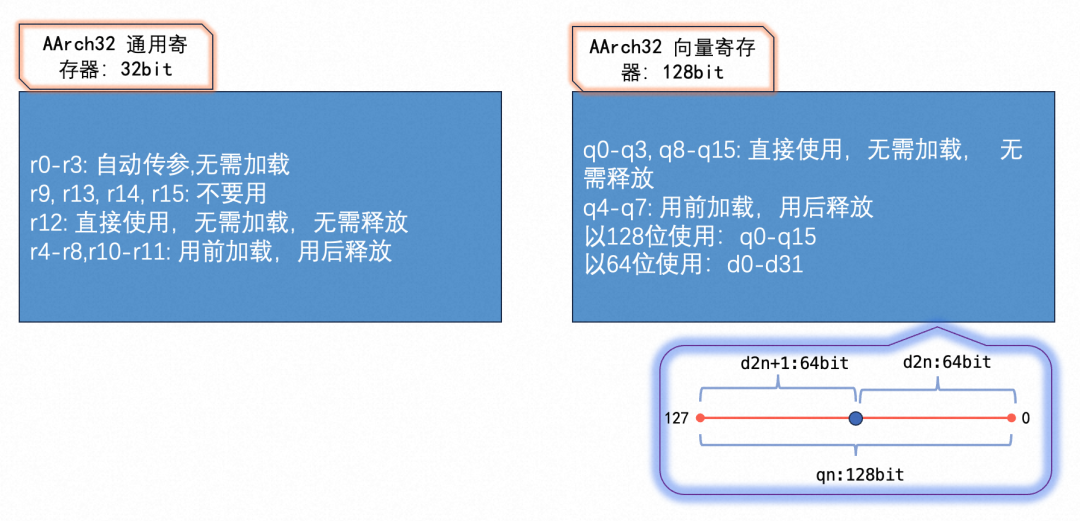
ldr x8, [sp, #0]ARM寄存器使用不当会导致程序crash。这里总结了ARM32和AMR64的寄存器基本使用规则。ARM32中通用寄存器和向量寄存器都有16个,每个向量寄存器的最大使用长度是128位。ARM32中用于传参的寄存器有4个:r0-r3。ARM32中r13寄存器就是sp寄存器,指向栈顶;r14寄存器也叫lr寄存器,存储函数的返回值地址;r15寄存器也叫pc寄存器,存储将要执行的下一条指令的地址。在进行汇编开发时,一般不使用r13和r15寄存器来存储临时变量。r9寄存器的使用在各个平台上可能不同,为了防止出错,一般也不用来存储临时变量。当不需要使用r14存储返回值地址的信息时,也可以使用其存储临时变量。下图中我总结了ARM32中寄存器的基本使用规则,关于各寄存器更加详细的介绍参考https://developer.arm.com/documentation/den0013/d/Application-Binary-Interfaces/Procedure-Call-Standard。
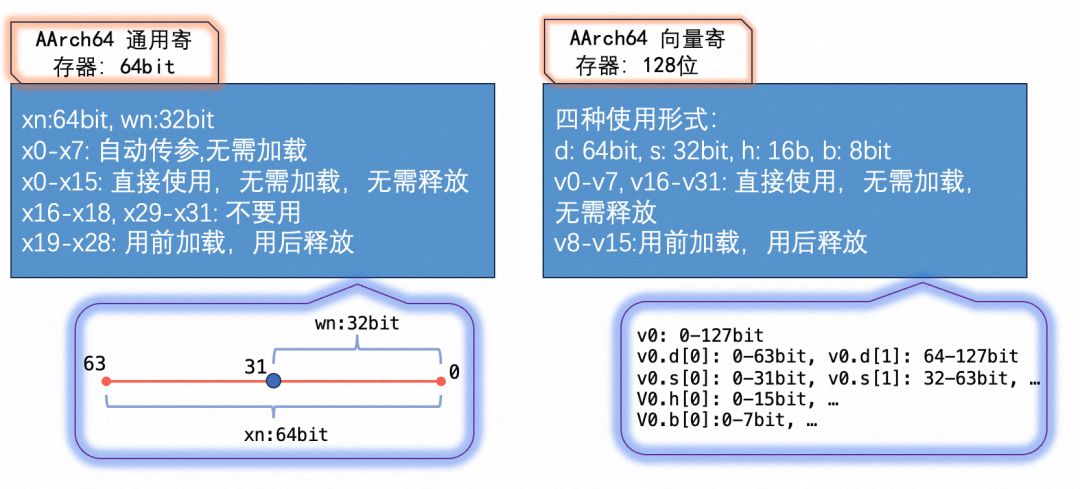
ARM64中通用寄存器和向量寄存器的个数比ARM32多一倍,有32个。ARM64中向量寄存器的使用更加灵活,可以8bit,16bit,32bit,64bit使用。例如,v0表示128位的向量寄存器,d0,s0,h0分别表示v0的低64位,32位,16位。注意,d1,s1,h1表示v1寄存器的低64位,32位,16位,而不是紧接着v0的第二个相应位。ARM64的寄存器使用见下图。
我们可以用浮点操作指令把向量寄存器中的数当做标量来进行计算,需要注意在ARMV8中浮点操作指令不支持对16bit的浮点数进行计算,仅支持做16bit和32bit, 64bit之间的转换。
fadd Sd, Sn, Sm // 32bit Single precision
fsub Dd, Dn, Dm // 64bit Double precision
fcvt Sd, Hn // half-precision to single-precision
fcvt Dd, Hn // half-precision to double-precision
fcvt Hd, Sn // single-precision to half-precision
fcvt Hd, Dn // double-precision to half-precision对上图中的“用完恢复”寄存器的使用:一些复杂的函数需要的向量寄存器或者通用寄存器可能会非常多,那就需要我们在开头加载这些寄存器,不然会报错segment fault.加载方法如下:
// d8-d15表示使用v8-v15这8个寄存器的64位, (2* 64)/8=16,
// 这就是每次sp移位时(#16*i)中16的来源。
stp d14, d15, [sp, #(-16 * 9)]!
stp d12, d13, [sp, #(16 * 1)]
stp d10, d11, [sp, #(16 * 2)]
stp d8, d9, [sp, #(16 * 3)]
stp x27, x28, [sp, #(16 * 4)]
stp x25, x26, [sp, #(16 * 5)]
stp x23, x24, [sp, #(16 * 6)]
stp x21, x22, [sp, #(16 * 7)]
stp x19, x20, [sp, #(16 * 8)]在函数的结尾需要释放这些寄存器:
ldp x19, x20, [sp, #(16 * 8)]
ldp x21, x22, [sp, #(16 * 7)]
ldp x23, x24, [sp, #(16 * 6)]
ldp x25, x26, [sp, #(16 * 5)]
ldp x27, x28, [sp, #(16 * 4)]
ldp d8, d9, [sp, #(16 * 3)]
ldp d10, d11, [sp, #(16 * 2)]
ldp d12, d13, [sp, #(16 * 1)]
ldp d14, d15, [sp], #(16 * 9)
ret // 最后需加上ret返回ARM32中寄存器的数量只有ARM64的一半,自动传参的寄存器仅r0-r3这四个寄存器,其他寄存器的加载方式和ARM64也不同,我们依然以MNNAvgPoolInt8为例,代码的解释和新手闭坑的地方我直接在下面的注释中写明。
// 函数定义
asm_function MNNAvgPoolInt8
// void MNNAvgPoolInt8(int8_t* dst, int8_t* src, size_t outputWidth,
// size_t inputWidth, size_t kernelx, size_t kernely, size_t stridesx,
// ssize_t paddingx, ssize_t factor);
// Auto load: r0: dst, r1: src, r2: outputWidth, r3: inputWidth
// r4: kernelx, r5: kernely, r7: stridesx, r8: paddingx, lr: factor
// 其他寄存器加载, 注意lr寄存器每次必须被push进来(可以不使用),不然会报错segment fault.
push {r4-r8, r10-r11, lr}
// 上一行push了8个寄存器,那么sp指针会向低地址移动(8*4=32)个字节(ARM32每个指针占4个字节),
// 所以第五个参数“kernelx”加载时需要将sp的地址加(#32).
// 虚拟内存中栈是从高地址向低地址扩展的,而函数传参是从右往左传去栈中的,
// 所以后面的参数地址会比前面的高,即相对sp寄存器的地址增加的更多。
ldr r4, [sp, #32] // kernelx
ldr r5, [sp, #36] // kernely
ldr r7, [sp, #40] // stridesx
ldr r8, [sp, #44] // paddingx
ldr lr, [sp, #48] // factor
// 加载向量寄存器一定要放在利用sp寄存器来读取所有函数参数之后,
// 否则不能正常读取函数参数
vpush {q4-q7}ARM32 结尾对寄存器的释放
// 不需要pop lr寄存器,但是必须pop pc寄存器。
// ARM32结尾不需要写 ret, 这和ARM64不同。
vpop {q4-q7}
pop {r4-r8, r10-r11, pc}▐ 核心功能的实现
写汇编代码之前,我们一定要先实现C++版本的代码,保证C++版本的算子在ARM移动端的计算结果是正确的。这样做有两个目的:第一,保证我们对算子的理解是正确并清晰的,否则写汇编算子就是浪费时间;第二,为汇编算子的输出结果提供标准答案,因为同样的 C++ 代码在不同的平台上的计算结果可能会略有不同(但差异不会很大),我们需要保证汇编版本的算子和C++版本的算子计算结果在ARM平台上完全一致。
汇编代码中条件判断和分支跳转
MaxPooling算子通过遍历局部区域的所有元素,进而找到区域内的最大值。这就涉及到循环指令、地址跳转指令和比较两个向量寄存器中对应元素。关于指令的解释我直接在代码注释中写明。
比较两个向量寄存器中对应元素的大小
/*
smax, smin 比较整型数数据的大小
ARM汇编有符号整数的指令一般以s开头(signed int)
无符号整数的指令一般以u开头(unsigned int)
浮点数据的指令一般以f开头(float)
*/
// 比较v0和v1寄存器中的16个int8_t数据,
// 并将对应位置上的较大值存储在v2的相应位置上
// b 表示以8位来读取数据,相应的汇编中 h:16位, s:32位, d:64位
smax v2.16b, v0.16b, v1.16b
smin v10.4s, v11.4s, v12.4s //比较v11和v12的4个int32_t数据的大小循环执行某一段代码
如果需要在ARM汇编中循环执行一段代码,那我们需要自定义一个符号来标记这一段代码。以MaxPooling算子为例,假设每一个像素点含有16个Channel,我们需要得到被kernel覆盖到的9个像素点上对应Channel的最大值,即重复执行比较指令9次。例如用Loop来标记我们需要循环的代码段:
1. mov w7, #-0x80 // 给通用寄存器赋值-128,即int8_t类型的最小值
2. dup v0.16b, w7 // 初始化v0, v0中存储了16个-128
3. mov x10, #9 // 计数
// 循环
Loop:
3. ld1 {v1.16b}, [x0] // 从地址x0中加载16个int8的数据到v1寄存器,与v0做比较
4. smax v0.16b, v0.16b, v1.16b // 用v0记录最终的比较结果
5. add x0, x0, #1 // 移动像素点的地址,这里我们假设9个像素点是连续的
6. sub x10, x10, #1 // 比较完一个像素点的16个Channel大小后,计数减1
7. cmp x10, #0 // cmp是compare的缩写:比较x10和0的大小
8. bgt Loop // bgt是branch greater than的缩写,满足条件就跳到分支Loop执行
// 循环执行结束
9. st1 {v0}, [x1] // 存储寄存器v0中的16个int8_t数据到地址x1中
// ARM 汇编代码是按照从上到下的顺序来执行的,
// 所以跳出Loop不需要额外的指令来表示结束该分支
// 当不满足x10>0时,会直接执行第9行代码▐ 如何查找需要的指令
灵活地运用各种汇编指令往往能提高算子性能。
利用现成的汇编代码查找指令
当我们阅读一些汇编代码时,根据汇编指令去查询其功能是非常容易的,甚至根据指令名我们可以猜测出他的功能。但是当我们第一次写汇编代码时,想知道实现某个功能可以使用哪些指令往往很难。此时最关键的一点,需要我们思考哪个函数中会用到我将要实现的功能,然后去参考他的汇编实现过程。比如写Pooling算子的汇编代码时不知道如何去进行循环代码段的编写,我们就可以参考矩阵乘算子的汇编代码去学习分支跳转,寄存器的比较等指令。当我们不知道如何用汇编指令去实现浮点数转整数的四舍五入时,MNN中现成的Float2Int8函数一定会有相应的指令实现这个功能。当我们编写了越来越多的汇编代码,会接触到更多的汇编指令,解决问题的思路和视野也更开阔。
利用关键词在ARM官网查找指令
ARM官网列举了所有汇编指令的用法,其中ARM64的指令手册比ARM32更易查找和理解。一般ARM64的指令在ARM32系统都能找到对应的等效指令。偶尔我们也需要ARM Intrisic指令来完成一些简单函数的开发,Intrisic指令可以参考https://gcc.gnu.org/onlinedocs/gcc-4.6.4/gcc/ARM-NEON-Intrinsics.html?spm=ata.21736010.0.0.68f48710o8Vsk6。利用好功能的关键词能提高查找指令的速度。例如某次编程中我需要查找哪些指令能实现“int8+int16->int16"的功能,显然关键词是"add". 官网中会列举适用于各种场景的向量加法指令,很快就可以定位到"saddw v0.8h, v1.8h, v2.8b"指令。
ARM官网地址:https://developer.arm.com/documentation/dui0801/h/A64-SIMD-Vector-Instructions/?spm=ata.21736010.0.0.68f48710o8Vsk6

ARM汇编Debug方法和常见错误列举
▐ 利用好“打印printf”
汇编代码的调试一直是个难题,不能像C++代码那样一步步Debug查看变量的值,只能通过在函数调用的外层加打印的方式来查看汇编代码的执行结果。不过只要我们能利用好打印,汇编代码的BUG排查就能简单不少!具体来说,如果我们需要查看某个中间变量的值,我们可以在代码内部用返回值地址来存储该值,从而我们可以在汇编代码的外部打印该地址存储的内容,这样间接地检查代码执行的逻辑是否符合预期。
▐ 函数传参错误
函数传参错误非常容易被忽视,因为这个错误很少会直接报错"segment fault",而是发现汇编算子的结果和C++版本不一致时,经过一步步排查才发现传参就出现了错误。毕竟我们发现结果错误时,更习惯于去检查汇编代码中最复杂的逻辑,不太会想到代码开头的函数传参就已经错了。目前为止,我遇到过的传参错误就只有以下两种:
1、除了整型以外的数据传参应该用指针传入,而不是直接传入参数值。浮点参数传递方式与编译器及参数配置相关,可能不同平台下传递方式不一样。如果直接浮点数值传参,带来的结果有可能是:浮点参数后面的参数数值都是前一个参数的数据,也就是发生了传参的偏移,导致计算结果对不上;如果恰巧你需要从某个参数中load数据,该参数的值受到了浮点参数错误传递的影响,那有可能会报segment fault的错误。
// 正确传参,用指针传递浮点常数para0
void func(float* para0, float* dst)
// 错误传参,直接传入常数para0
void func(float para0, float* dst)2、传参寄存器使用错误
ARM64 自动传参的寄存器有8个:x0-x7,ARM32 自动传参的寄存器有4个: r0-r3。如果参数个数大于8(4),就需要从sp寄存器的相对位置来load参数。
asm_function MNNAvgPoolInt8
// 加上函数的传参注释,方便后续对照使用对应的寄存器
// void MNNAvgPoolInt8(int8_t* dst, int8_t* src, size_t outputWidth,
// size_t inputWidth, size_t kernelx, size_t kernely, size_t stridesx,
// ssize_t paddingx, ssize_t factor);
// Auto load: x0: dst, x1: src, x2: outputWidth, x3: inputWidth,
// x4: kernelx, x5: kernely, x6: stridesx, x7: paddingx
// Load from sp:
// w8: factor3、整型参数建议使用ssize_t和size_t传参
定义一个函数:void func(int8_t* dst, int8_t* src, float* params0, float* params1, int width, int height, int kernelx, int kernely, int needBroadcast)
按照前面的介绍,第9个参数needBroadcast应该由sp寄存器来加载,如:ldr x8, [sp, #0],如果我们需要比较needBroadcast和0的大小,写成:cmp x8, #0,无论x8是否为0,代码的判断结果都会是false.除非将判断语句写成:cmp w8, #0. 出现这种问题的原因在于,ssize_t和size_t这两种类型,ARM64和ARM32会将其分别看做是64位和32位的数据,而对于int类型的数据,ARM64和ARM32上都会是32位的数据,而ARM64的通用寄存器以x来使用是64位的(即x1,x2...),以w来使用才是32位的(即w1,w2...)。所以要比较x8与0的大小关系,应是:cmp,w8,#0.
对于上述问题的更好的解决办法是,函数声明时将needBroadcast参数的类型定义成ssize_t,因为该参数的取值可能是-1,1,0, 我们将其定义成有符号类型。在汇编代码中再次使用 cmp x8, #0来比较结果就是正确的了,当然此时我们还是用w8和0比较的话,结果也是正确的。
▐ ARM32 向量寄存器和参数加载的顺序问题
在汇编开发中我遇到过这样的问题,定义一个函数如下:
// void MNNAvgPoolInt8(int8_t* dst, int8_t* src, size_t outputWidth,
// size_t inputWidth, size_t kernelx, size_t kernely, size_t stridesx,
// ssize_t paddingx, ssize_t factor);
asm_function MNNAvgPoolInt8
// Auto load: r0: dst, r1: src, r2: outputWidth, r3: inputWidth
// Load from sp: r4: kernelx, r5: kernely, r7: stridesx, r8: paddingx, lr: factor
2. push {r4-r8, r10-r11, lr}
3. vpush {q4-q6}
4. ldr r4, [sp, #32]
5. ldr r5, [sp, #36]
6. ldr r7, [sp, #40]
7. ldr r8, [sp, #44]
8. ldr lr, [sp, #48] // lr: factor这样可能不会出现报错segment fault,但是参数的加载结果是错的。原因在于第3行vpush应该在通过sp加载完所有的函数参数之后,而不是在此之前。因为push了8个通用寄存器入栈之后,再push向量寄存器入栈,那么函数参数相对于sp寄存的位置就不再是(8x4=32). 相对位置的偏移发生了变化。第3行的代码应该在第8行后面。
▐ ARM64 通用寄存器的使用问题
在ARM64中给通用寄存器赋整型数值
// 通用寄存器的赋值只能用32位来使用寄存器
mov w10, #0 // right
mov x10, #0 // error
// 后续计算中要使用x10来进行加减乘的计算,需要将w10扩展成x10:
uxtw x10, w10 // w10中32位数据在x10的低32位中保持不变,x10的高32位填充为0.sub, add等指令只能对整型数据操作,浮点类型数据需要使用fsub, fadd等
fmov v1.4s, #1.0
fmov v2.4s, #0.2
fsub v1.4s, v1.4s, v2.4s▐ 四舍五入的问题
ARM32和ARM64中浮点数取整的方式不一样。ARM32中浮点数转换成整数的指令(vcvt.s32.f32)是向负无穷取整的,在ARM32中没有四舍五入的取整指令。需要在ARM32中实现四舍五入,可以这样做:
//对寄存器q3中的4个浮点数据做四舍五入取整
// q3: -1.4, 4.5, 1.1, -2.7 -> q3: -1, 4, 1, -3
vmov.f32 q1, #0.5
vmov.f32 q2, #-0.5
vcgt.f32 q12, q3, #0
vbsl.f32 q12, q1, q2 // bitwise select.
vadd.f32 q13, q12, q3
vcvt.s32.f32 q3, q13ARM64提供的取整指令更加灵活方便,有:
// q10: -1.4, 4.5, 1.1, -2.7
fcvtas q1, q10 // q1: -1, 5, 1, -3 就近取整
fcvtzs q2, q10 // q2: -1, 4, 1, -2 向0取整
fcvtms q3, q10 // q3: -2, 4, 1, -3 向负无穷取整
fcvtps q4, q10 // q4: -1, 5, 2, -3 向正无穷取整
fcvtns q4, q10 // q4: -2, 4, 2, -2 向最近的偶数取整▐ 整型数据和浮点数据进行数学运算的问题
整型数据与浮点数据进行相加或相乘等数学运算之前,一定要先将整型数据转换成浮点数据再进行数学运算,否则计算结果会出错。该过程经常出现在Int8量化算子的开发中,往往是量化算子很难消除的计算负担。用Binary multiply的Int8量化算子举例说明该过程:
// Int8 量化的乘法算子,输入和输出均是Int8类型,但考虑到int8xint8会可能会导致越界,
// 在量化算子的实现过程中会将两个输入数据分别转换成Float32数据之后相乘,
// 再将Float32的结果量化到Int8类型.
sxtl v0.8h, v0.8b // int8x8_t -> int16x8_t
sxtl v1.8h, v1.8b // int8x8_t -> int16x8_t
sxtl v2.4s, v0.4h // v0的低64位数据:int16x4_t -> int32x4_t
sxtl2 v3.4s, v0.8h // v0的高64位数据:int16x4_t -> int32x4_t
sxtl v4.4s, v1.4h
sxtl2 v5.4s, v1.8h
scvtf v2.4s, v2.4s // int32x4_t -> float32x4_t
scvtf v3.4s, v3.4s
scvtf v4.4s, v4.4s
scvtf v5.4s, v5.4s
fmul v2.4s, v2.4s, v6.4s // v6.4s: float32x4_t 量化scale参数
fmul v3.4s, v3.4s, v6.4s
fmul v4.4s, v4.4s, v6.4s
fmul v5.4s, v5.4s, v6.4s
...此处有同学可能会质疑这么麻烦还有必要开发Int8量化的乘法算子吗?具体原因可以参考之前关于开发Pooling量化算子的ATA文章,开头有说明原因。
▐ Segment fault出现的可能原因总结
在这里总结目前我遇到过的程序crash情况,后续也会在此添加更多的bug。
数据加载、存储时,地址寄存器使用错误
函数参数加载地址时是否使用了错误的寄存器;
写代码过程中,是否给存储地址的寄存器赋值了,导致寄存器的内容改变;
循环加载、存储数据时,原地址累加是否导致了越界;
寄存器开头和结尾是否相应地push\pop(stp\ldp)
通用寄存器的加减出错,大多由于赋值错误或函数加载错误而间接导致
通用寄存器的内容是否符合预期,可使用Printf的办法验证
ARM64和ARM32中用于自动加载函数参数的寄存器个数分别是8个、4个
ARM64中通用寄存器赋值只能用32位,即w0,w1...根据需要决定是否使用uxtw扩展到相应的x0,x1...
函数参数类型声明错误,导致加载错误
非整型函数参数一律用指针传递
整型常数参数尽量使用ssize_t, size_t
是否设置了循环退出条件,比如用于计数寄存器是否每次减1,循环退出条件是否能满足
有一些寄存器是否忘记push就直接使用了,参考1.1节中的图查询哪些寄存器需要用完恢复

ARM汇编的加速效果
拿ConvolutionDepthwise的Int8量化算子举例说明,C++版本的算子实现和ARM汇编版本的性能差距。测试模型中含有超过20个ConvolutionDepthwise算子。测试机我选择了高端机华为Mate40 Pro和中端机华为P30 Pro,并使用ARM V8.2平台的相关指令编写汇编算子。测试结果中显示的时间是该模型中所有ConvolutionDepthwise算子的耗时总和,显然在ARM V8.2 64位平台上,汇编算子的性能提高了约4.7倍。
| C++版本 | ARM V8.2 汇编 | |
|---|---|---|
| 华为Mate40 Pro | 11.28 ms | 1.98 ms |
| 华为P30 Pro | 12.83 ms | 2.22 ms |

团队介绍
大淘宝技术Meta Team,负责面向消费场景的3D/XR基础技术建设和创新应用探索,通过技术和应用创新找到以手机及XR 新设备为载体的消费购物3D/XR新体验。团队在端智能、商品三维重建、3D引擎、XR引擎等方面有深厚的技术积累。先后发布端侧推理引擎MNN,端侧实时视觉算法库PixelAI,商品三维重建工具Object Drawer等技术。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。
本篇内容作者:酒七
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法





![[足式机器人]Part5 机械设计 Ch00/01 绪论+机器结构组成与连接 ——【课程笔记】](https://img-blog.csdnimg.cn/74d59e1eaea643a8b8721b6172615477.png)