- 1. 哈希桶概念
- 2. 哈希桶的基础模型
- 3. 哈希桶的插入
- 4. 哈希桶的删除
- 5. 哈希桶的查找
1. 哈希桶概念
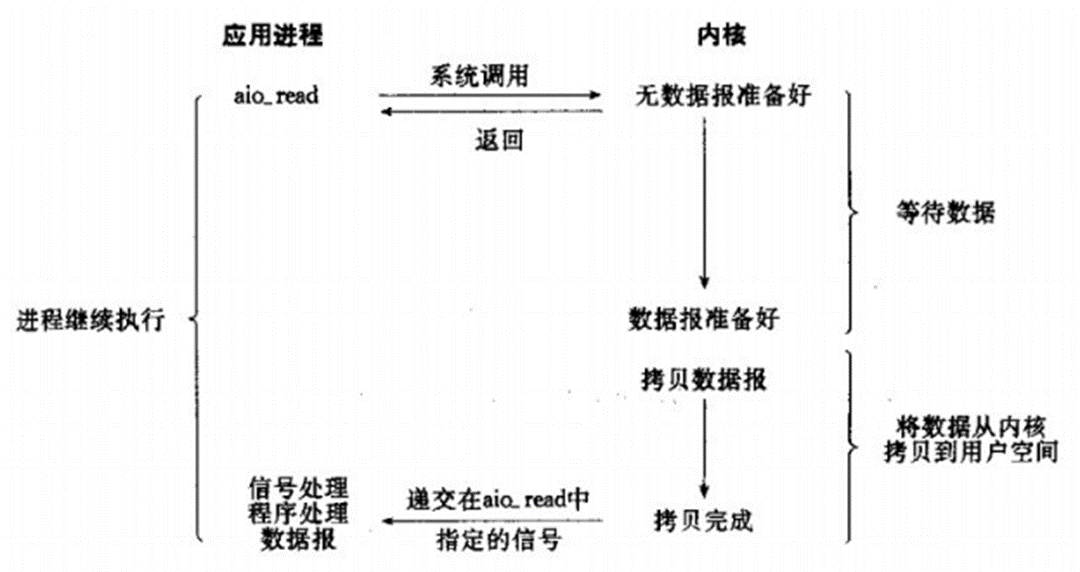
在C++中,哈希桶是一种用于实现哈希表的数据结构。哈希表是一种高效的数据结构,用于存储键值对,并支持快速的插入、查找和删除操作。
哈希桶的基本思想是通过将键映射到桶中的索引来存储和访问数据。具体实现中,通常使用一个数组来表示桶,每个桶可以存储一个或多个键值对。为了将键映射到桶中的索引,通常使用哈希函数来计算键的哈希值,然后对桶的数量取模,得到键的索引。
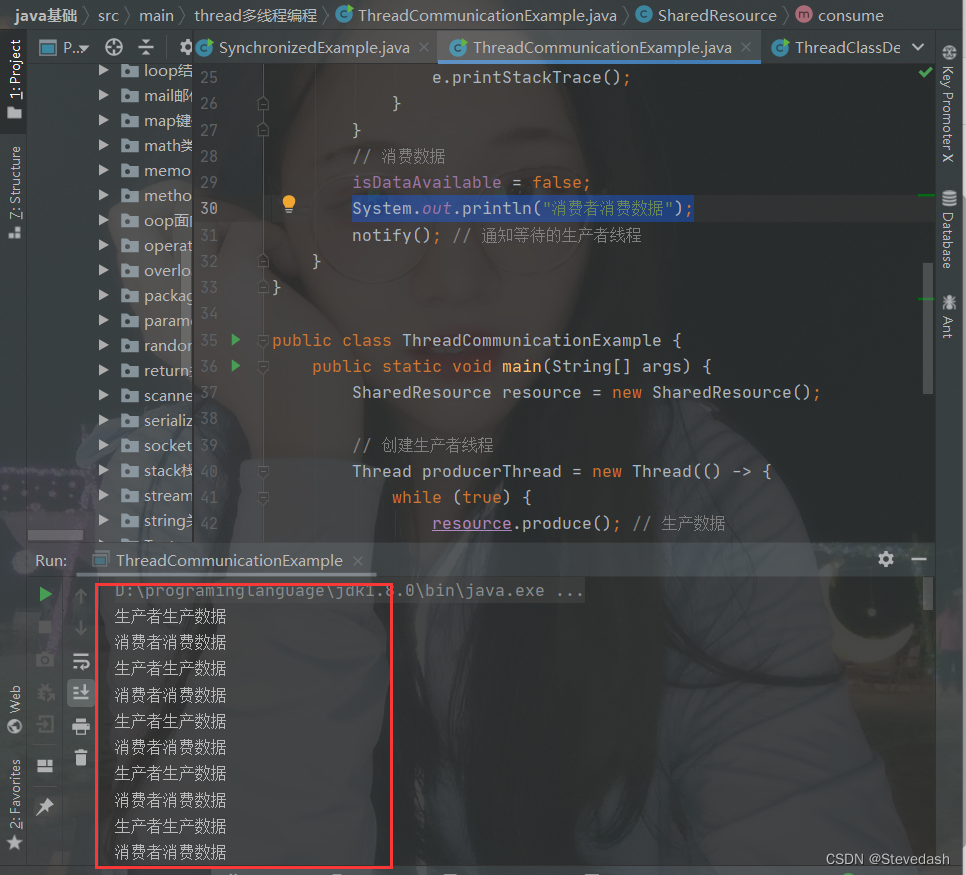
哈希桶可以理解为一个指针数组,数组的每个元素都是一个指针,而这个指针是一个单链表的表头,数组的每一个位置都挂着一个单链表。
如图所示:

这一个个的单链表你可以把他当成桶来看。哈希桶又名链地址法,因此元素是一个个的单链表。
2. 哈希桶的基础模型
class HashBucket
{
typedef HashBucketNode<V> Node;
typedef Node* PNode;
public:
HashBucket(size_t capacity)
: _table(GetNextPrime(capacity))
, _size(0)
{}
~HashBucket()
{
Clear();
}
private:
vector<Node*> _table;
size_t _size; // 哈希表中有效元素的个数
};
3. 哈希桶的插入
哈希桶的插入有以下步骤
- 先用哈希函数找到要插入的位置
- 再用头插法插入到单链表中
注意:
- 这里的插入都是不插入重复元素
- 注意扩容的问题
代码如下:
Node* Insert(const V& data)
{
// 0. 检测是否需要扩容
CheckCapacity();
// 1. 通过哈希函数计算data所在的桶号
size_t bucketNo = HashFunc(data);
// 2. 检测该元素是否在bucketNo桶中
// 本质:检测链表中是否存在data的节点
Node* pCur = _table[bucketNo];
while (pCur)
{
if (pCur->_data == data)
return nullptr;
pCur = pCur->_pNext;
}
// 插入新节点
pCur = new Node(data);
pCur->_pNext = _table[bucketNo];
_table[bucketNo] = pCur;
++_size;
return pCur;
}
扩容的代码:
void CheckCapacity()
{
if (_size == _table.capacity())
{
// 将旧哈希桶中的节点直接向新哈希桶中搬移
for (size_t i = 0; i < _table.capacity(); ++i)
{
Node* pCur = _table[i];
while (pCur)
{
// 将pCur节点从旧哈希桶搬移到新哈希桶
// 1. 将pCur节点从旧链表中删除
_table[i] = pCur->_pNext;
// 2. 将pCur节点插入到新链表中
size_t bucketNo = ht.HashFunc(pCur->_data);
// 3. 插入节点--->头插
pCur->_pNext = ht._table[bucketNo];
ht._table[bucketNo] = pCur;
}
}
this->Swap(ht);
}
}
4. 哈希桶的删除
删除有以下步骤
- 先用哈希函数找到删除元素的位置
- 从该位置的头节点开始,遍历链表
- 找到元素,开始删除,变换节点
代码如下:
bool Erase(const V& data)
{
size_t bucketNo = HashFunc(data);
Node* pCur = _table[bucketNo];
Node* pPre = nullptr;
while (pCur)
{
if (data == pCur->_data)
{
// 删除
if (_table[bucketNo] == pCur)
{
// 删除第一个节点
_table[bucketNo] = pCur->_pNext;
}
else
{
// 删除的不是第一个节点
pPre->_pNext = pCur->_pNext;
}
delete pCur;
--_size;
return true;
}
pPre = pCur;
pCur = pCur->_pNext;
}
return false;
}
5. 哈希桶的查找
查找的步骤如下:
- 先用哈希函数确定元素的位置
- 遍历该位置的链表,找到元素
Node* Find(const V& data)
{
size_t bucketNo = HashFunc(data);
Node* pCur = _table[bucketNo];
while (pCur)
{
if (data == pCur->_data)
return pCur;
pCur = pCur->_pNext;
}
return nullptr;
}




![[C++] 模板template](https://img-blog.csdnimg.cn/img_convert/accb02c07b7c4ff4adbd7c2ca2138fe6.png)