电商系统中秒杀是一种常见的业务场景需求,其中核心设计之一就是如何扣减库存。本篇主要分享一些常见库存扣减技术方案,库存扣减设计选择并非一味追求性能更佳,更多的应该考虑根据实际情况来进行架构取舍。在商品购买的过程中,库存的抵扣过程通常包括以下步骤:
- 开启事务:在开始进行库存抵扣操作前,开启一个事务。
- 查询库存:根据商品ID,使用SELECT语句从库存表中查询该商品的当前库存数量。
- 检查库存是否足够:将查询到的库存数量与用户购买数量进行比较。如果库存数量大于或等于用户购买数量,则库存足够,可以继续下单。如果库存不足,需要采取相应的处理措施,例如提示用户库存不足或进行库存预订等。
- 扣减库存:如果库存足够,根据用户购买数量,使用UPDATE语句将库存表中对应商品的库存数量减去购买数量,得到最新的库存剩余值。
- 记录交易明细:在购买过程中,通常需要记录交易明细,例如生成订单记录或交易日志,以便后续查询和跟踪。
- 提交事务:以上操作通常会在一个事务中进行,确保操作的原子性。如果所有步骤都成功执行,则提交事务,库存扣减过程完成。如果在任何步骤中出现错误或异常,事务会回滚,恢复到操作前的状态,确保数据的完整性和一致性。
由于涉及到 SELECT后进行UPDATE,以上步骤中存在多事务并发时写覆盖的问题。
悲观锁更新库存
在数据库并发控制中,防止写覆盖是一个重要的问题,特别是在多个会话(事务)同时尝试修改同一行数据时。如果不进行适当的并发控制,可能会导致数据的不一致性和丢失更新。
为了解决这个问题,可以使用 SELECT FOR UPDATE语句。在使用SELECT FOR UPDATE时,数据库会将目标行的数据加上写锁,阻止其他事务在当前事务完成之前修改被锁定的数据。这样,其他会话无法同时修改同一行数据,从而避免了并发写入冲突。
需要注意的是,使用SELECT FOR UPDATE可能会引起一些并发性能问题,因为其他会话需要等待锁释放才能继续执行。因此,在设计并发控制策略时,需要综合考虑并发性能和数据一致性之间的平衡。
在上述流程中,步骤3 改为:
3. 查询库存并锁定:使用SELECT ... FOR UPDATE语句查询指定商品的库存,并将其锁定。这将确保其他并发事务在当前事务提交或回滚之前无法修改该商品的库存。
# 开始事务
connection.begin()
# 加锁(FOR UPDATE)并读取当前库存记录
cursor.execute("SELECT quantity FROM inventory WHERE id = ? FOR UPDATE", item_id)
current_quantity = cursor.fetchone()['quantity']
# 检查库存是否足够
if current_quantity >= requested_quantity:
# 计算更新后的库存数量
new_quantity = current_quantity - requested_quantity
# 更新库存
cursor.execute("UPDATE inventory SET quantity = ? WHERE id = ?", (new_quantity, item_id))
#{... 记录明细等操作}
# 提交事务
connection.commit()
return True
else:
# 库存不足,回滚事务
connection.rollback()
return False
乐观锁更新库存
除开悲观锁,自然也可以想到使用乐观锁的方式来进行更新;最常见的设计就是CAS + 版本号的更新来实现库存更新,在库存表中新加一个 version的字段。
# 开始事务
connection.begin()
# 读取当前库存记录和版本号
cursor.execute("SELECT quantity, version FROM inventory WHERE id = ?", item_id)
result = cursor.fetchone()
current_quantity = result['quantity']
current_version = result['version']
# 检查版本号是否匹配
if current_quantity >= requested_quantity:
# 计算更新后的库存数量和版本号
new_quantity = current_quantity - requested_quantity
new_version = current_version + 1
# 更新库存和版本号
cursor.execute("UPDATE inventory SET quantity=%s,version=%s WHERE id=%s AND version=%s"
,(new_quantity, new_version, item_id, current_version))
#{... 记录明细等操作}
# 检查是否有更新行数
if cursor.rowcount == 1:
# 提交事务
connection.commit()
return True
else:
# 更新失败,可能是由于版本号不匹配导致的并发操作问题
connection.rollback()
return False
else:
# 库存不足,回滚事务
connection.rollback()
return False
可以进一步思考,是否需要版本的概念;扣减库存流程中,如果将 SELECT 查询 作为库存超卖前置检查的(保障扣减成功率,减少不必要的写操作)是视角看待,其实需要保障的是扣减后的库存是否大于等于零。
如何理解前置检查视角?
用个卖西瓜的例子来说明,假如你今天微信问到楼下水果店老板有特价5毛一斤西瓜还有10个,这时你立刻下楼去购买。那么可能两种结果,结果一 你买到了特价西瓜;结果二 买的人太多,你到店的时候已经卖光了。从结果看,微信询问的消息只是决定你下不下楼购买,而并非决定真正买到(不影响库存);这种询问作用在于减少直接下楼购买花费体力。
# 读取当前库存记录
cursor.execute("SELECT quantity FROM inventory WHERE id = ? ", item_id)
current_quantity = cursor.fetchone()['quantity']
# 检查库存是否足够
if current_quantity >= requested_quantity:
# 开始事务
connection.begin()
# 更新库存
cursor.execute("UPDATE inventory SET quantity = quantity-? WHERE id = ? and quantity - ?>= 0"
, (requested_quantity, item_id,requested_quantity))
#{... 记录明细等操作}
# 检查是否有更新行数
if cursor.rowcount == 1:
# 提交事务
connection.commit()
return True
else:
# 更新失败
connection.rollback()
return False
else:
return False
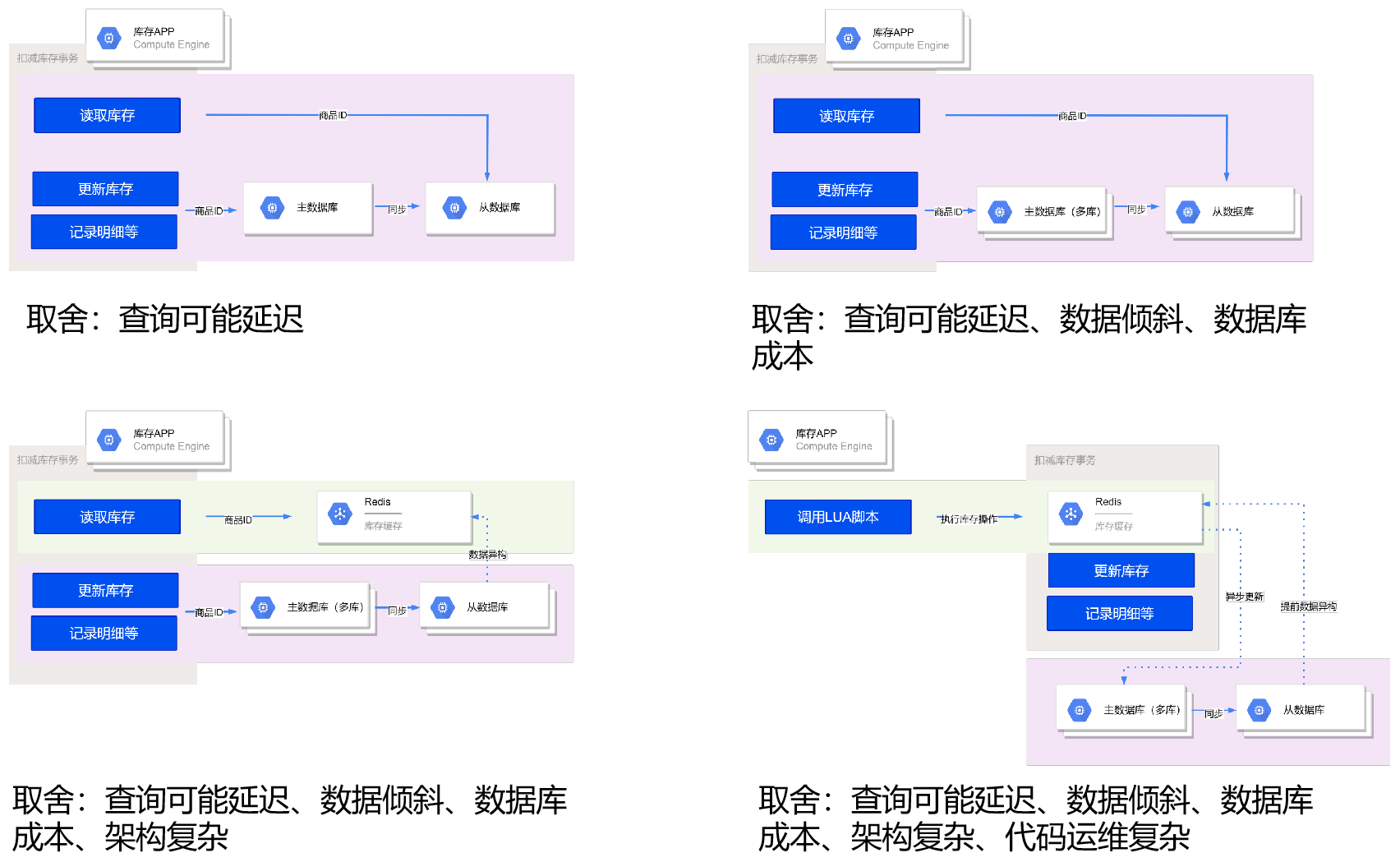
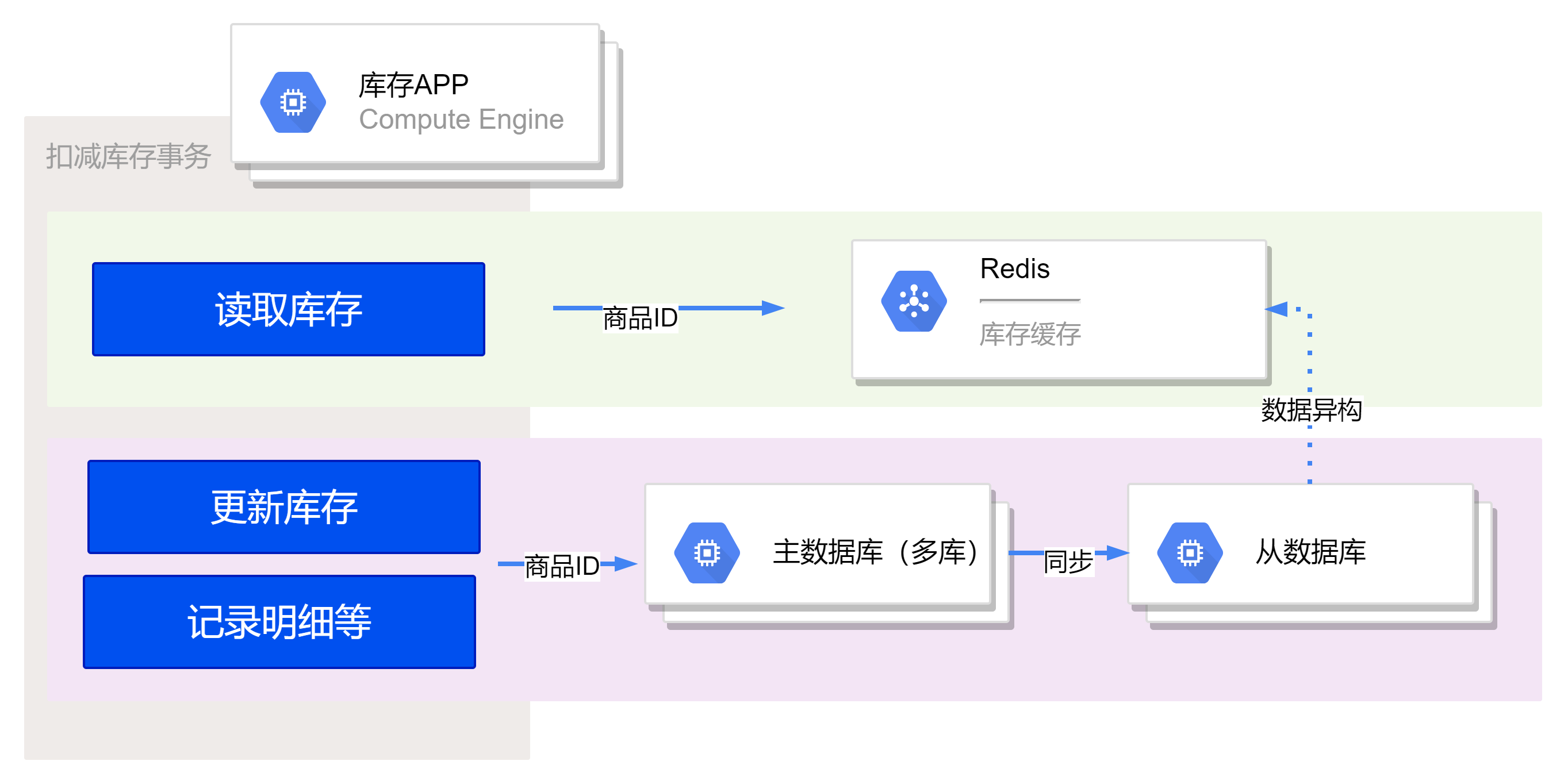
库存读写分离
再考虑一个极端的例子:假设有一个最新款的 iPhone 秒杀活动,库存只有 100 件,活动期间预估峰值每秒查询请求量(QPS)为 10 万次。在活动结束后,流水表最终只会插入 100 条记录,但是查询的 QPS 却接近 10 万次,导致读取的压力非常大。
在这种情况下,查询压力主要是由于活动期间大量的用户查询商品的秒杀状态和库存数量所导致的。虽然流水表最终只插入了 100 条记录,但是查询请求却非常频繁,可能会导致数据库性能问题。
优化首先可以想到是采用读写分离架构,通过新增一套从库来实现。借助MySQL自带的数据同步能力,可以将主库的数据同步到从库,从而在读取库存时可以直接查询从数据库。这样可以将读取请求分散到从库,减轻主库的查询压力。
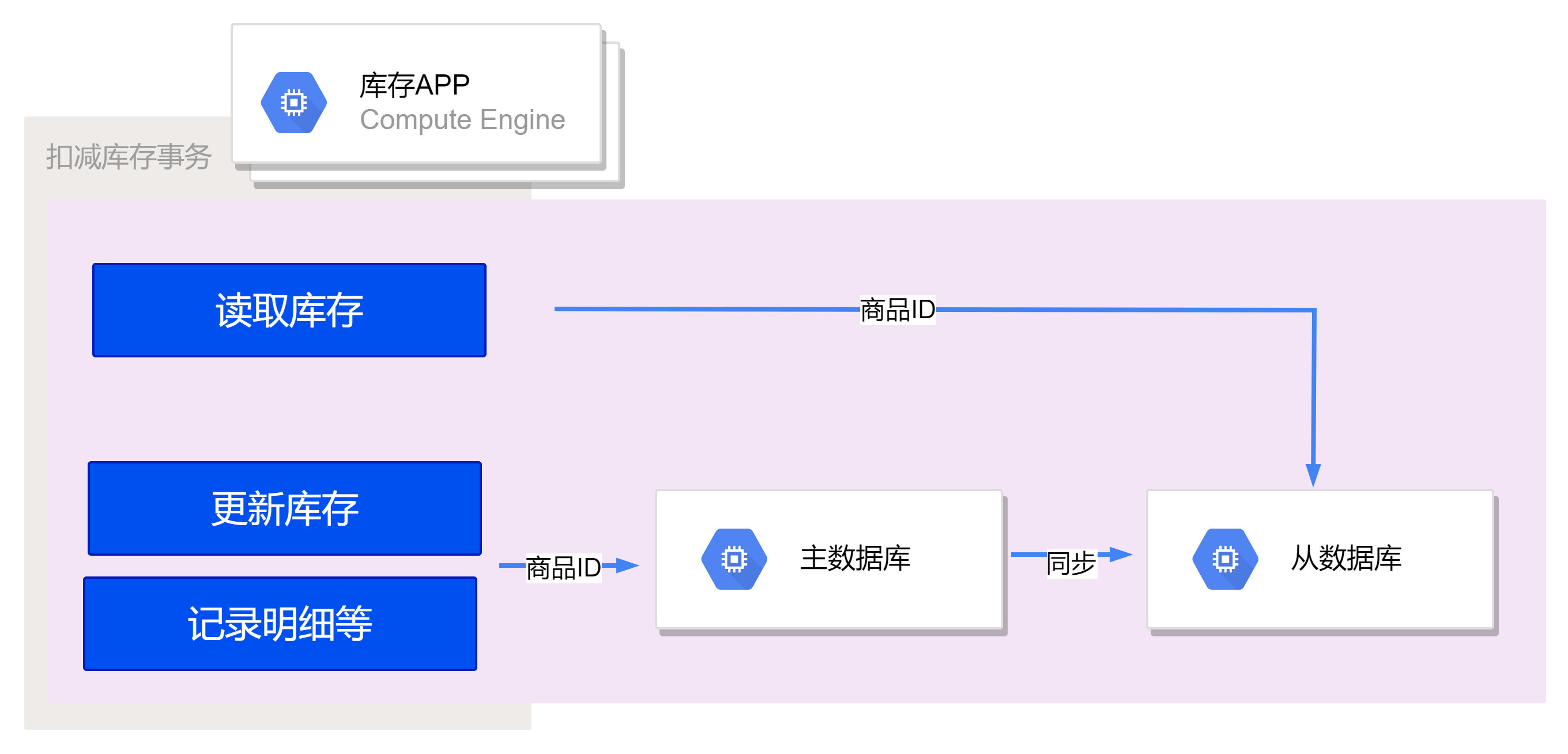
虽然读写分离可以提高查询性能,但需要注意从库的数据同步可能会有一定的时间延迟,导致从库的数据新鲜度(实时性)有一定的滞后性。(前置检查视角)在进行库存校验时,从库的数据并不一定完全准确,但可以拦截大部分无效流量,起到了一定的作用。
最终的购买决策仍然由主库的UPATE SQL语句来控制,以确保最终扣减的准确性。虽然从库的数据可能有一定的滞后,但并不会影响最终扣减的结果,因为购买操作仍然在主库上执行,确保了数据的一致性和准确性。
优点:1. 借助数据库的 ACID 特性,确保事务的原子性、一致性、隔离性和持久性,避免了超卖和少买等业务问题。
2. 实现简单,适用于项目工期紧张或开发资源有限的情况。
不足: 如果参与秒杀的 SKU(库存量单位)非常多,最终的写操作都是基于库存主库,可能会导致主库的性能压力较大。
这里 牺牲数据实时性(新鲜度) 来提升性能 是一种典型的 技术架构选型的 取舍方向。
库存分库分表
为了解决上述存在的容量和性能上限问题,库存分库分表会是一种优化选择。
-
将库存扣减表和扣减明细表根据商品ID进行水平拆分,将不同商品的记录存储在不同的分片中。这样可以将高并发的请求路由到不同的数据库实例上,分摊数据库负载。
-
在水平拆分的基础上,进一步考虑将不同商品的记录分布在不同的数据库实例中,每个实例称为一个库。对于每个库,可以再将表进行分表,将不同商品的记录分开存储。例如,可以按照商品ID的哈希值进行分表,或者按照一定的范围将商品ID进行分段,确保每个表的数据量均衡。
在实际应用中,系统需要根据商品ID来决定将请求路由到哪个数据库实例上。可以使用一致性哈希算法、分段路由规则等方式来实现请求的正确路由。这样可以确保同一商品的库存扣减和明细记录在同一个数据库实例上进行,保证事务的原子性和数据的一致性。
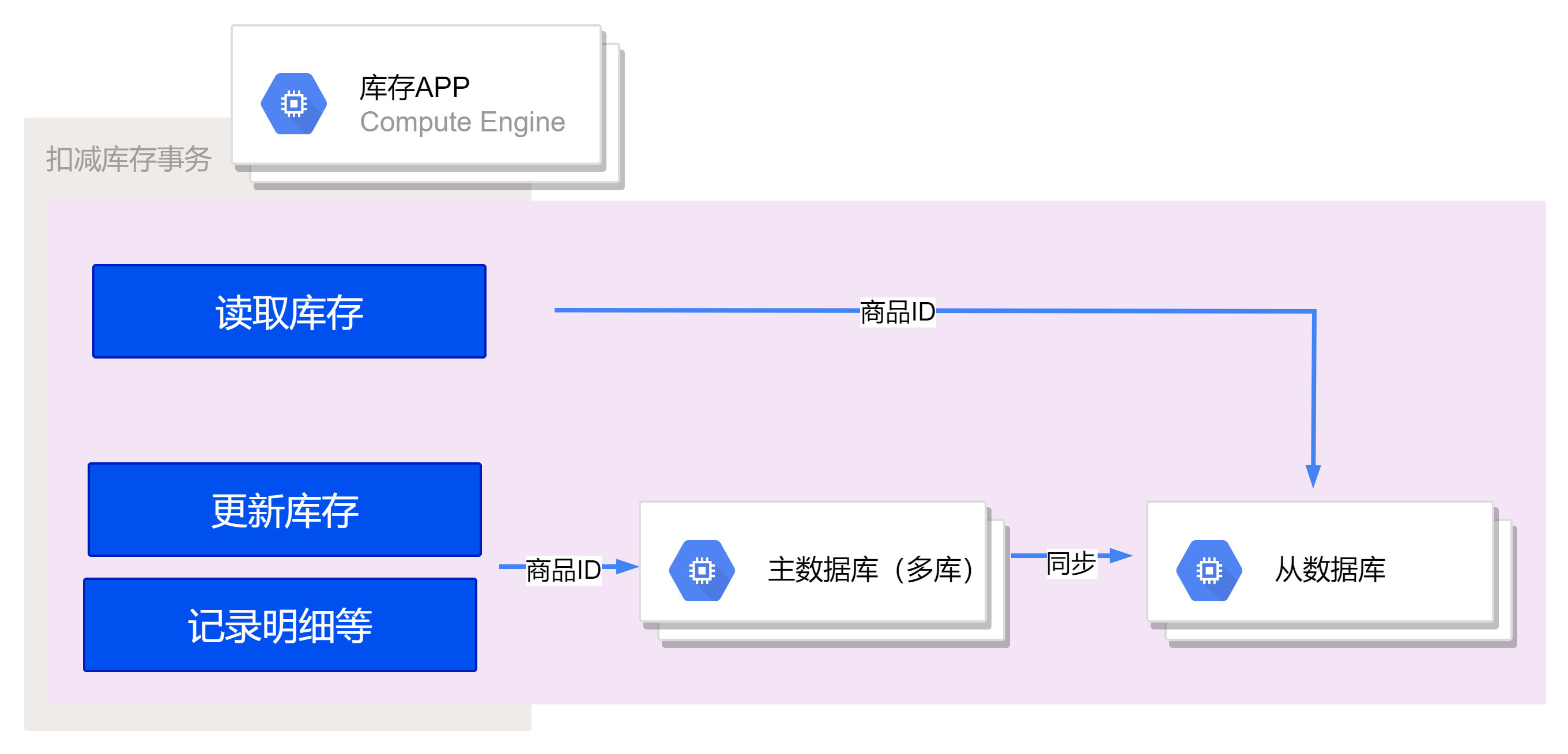
总体来说,通过水平拆分和分库分表的设计,可以有效地提高系统的吞吐量和性能,并减轻单一实例的容量限制。但是在实际应用中,需要仔细考虑数据库的选择、数据路由策略、数据一致性等问题,以确保系统的可用性和性能。同时,还需要合理评估业务需求和数据增长趋势,以选择合适的分片和数据库配置,避免出现过度分片或数据倾斜等问题。
缓存扣减库存
读写分离、分库分表确实能分摊主库很大一部分压力,但是如果面对是 单品万级QPS 的秒杀流量,MySQL 的千级 TPS 同样也支撑不了,需要进一步升级性能。
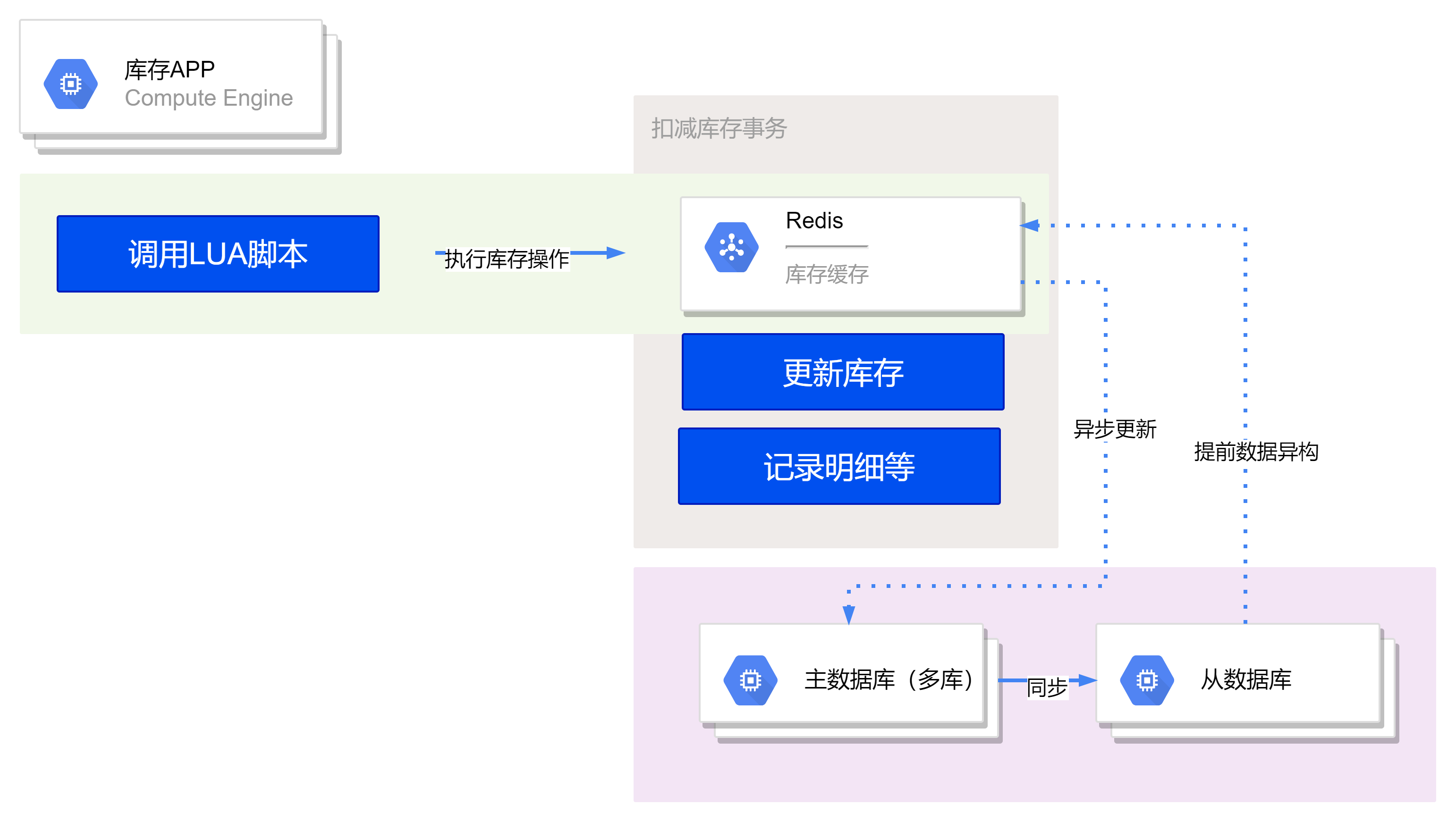
(读 改为 Redis)此时引入缓存中间件,将 MySQL 的数据定时同步到缓存中(可能存在延迟,库存显示不准确)。库存超卖前置检查,从 Redis 中查询剩余的库存数据,写入操作在数据库校验不准也不会超卖。 由于缓存基于内存操作,性能比数据库高出几个数量级,单台 Redis 实例可以达到 10W QPS 的读性能。
(读/写库存都为 Redis)对于扣减库存的操作,如果直接执行多个 Redis 命令,无法保证原子性。为了确保原子性,可以采用 Lua 脚本的形式,将多个 Redis 命令打包到一个脚本中,作为一个命令发送给 Redis 执行,从而保证了操作的原子性。
具体步骤如下:
- 使用 Lua 脚本:将扣减库存的多个 Redis 命令封装在一个 Lua 脚本中。这样可以确保这些命令在 Redis 中以原子方式执行,避免并发问题。
- 执行 Lua 脚本:将封装了扣减库存逻辑的 Lua 脚本作为一个整体命令发送给 Redis 执行。这样在 Redis 中执行脚本时,将按照脚本中的逻辑一次性执行多个命令。
- 异步保存到数据库:Redis 扣减库存成功后,将此次扣减操作异步化保存到数据库中进行持久化存储。
单品分桶扣减
在更大规模,针对单一商品的超高并发扣减的库存集群中,可能基于数据库内核的改造优化还无法满足业务需求。单一商品的超高并发扣减可能会影响到同一数据库实例上的其他商品扣减,同一个数据库实例上也可能存在多个热点商品造成互相影响,这时就考虑引入基于缓存的分桶扣减方案。
将商品ID按照一定的规则分成多个桶(Bucket),每个桶对应一个缓存项。例如,可以根据商品ID的哈希值或者取模运算的结果来分桶。分桶的目的是将不同商品的库存信息均匀地存储在不同的缓存项中,避免单个缓存项过大导致性能问题。
在进行库存扣减时,首先根据商品ID找到对应的缓存项。然后,在缓存中读取当前库存数量,并进行判断是否足够进行扣减操作。如果足够,更新缓存中的库存数量,并将扣减后的值存回缓存。如果不足,直接返回扣减失败。
其他解决方案
-
针对单品较多场景,也可以考虑批量扣减库存,批量处理库存的更新操作,这样可以大量的减少数据库事务。
-
基于消息的库存,下单完成后发生订单相关消息,库存通过消息消费的方式进行更新;优势在于库存的更新速率可控。
-
令牌库存,可控的时间内进行秒杀库存,提升用户秒杀感知。
以上综述
可以看到库存扣减方案场景多样,更多的 应该根据业务要求 以及 具体的流量进行选择,仅追求性能非好的选择;性能高的同时 往往意味 着其他方面的取舍,比如:代码复杂性、库存精准性、部署复杂性等等。