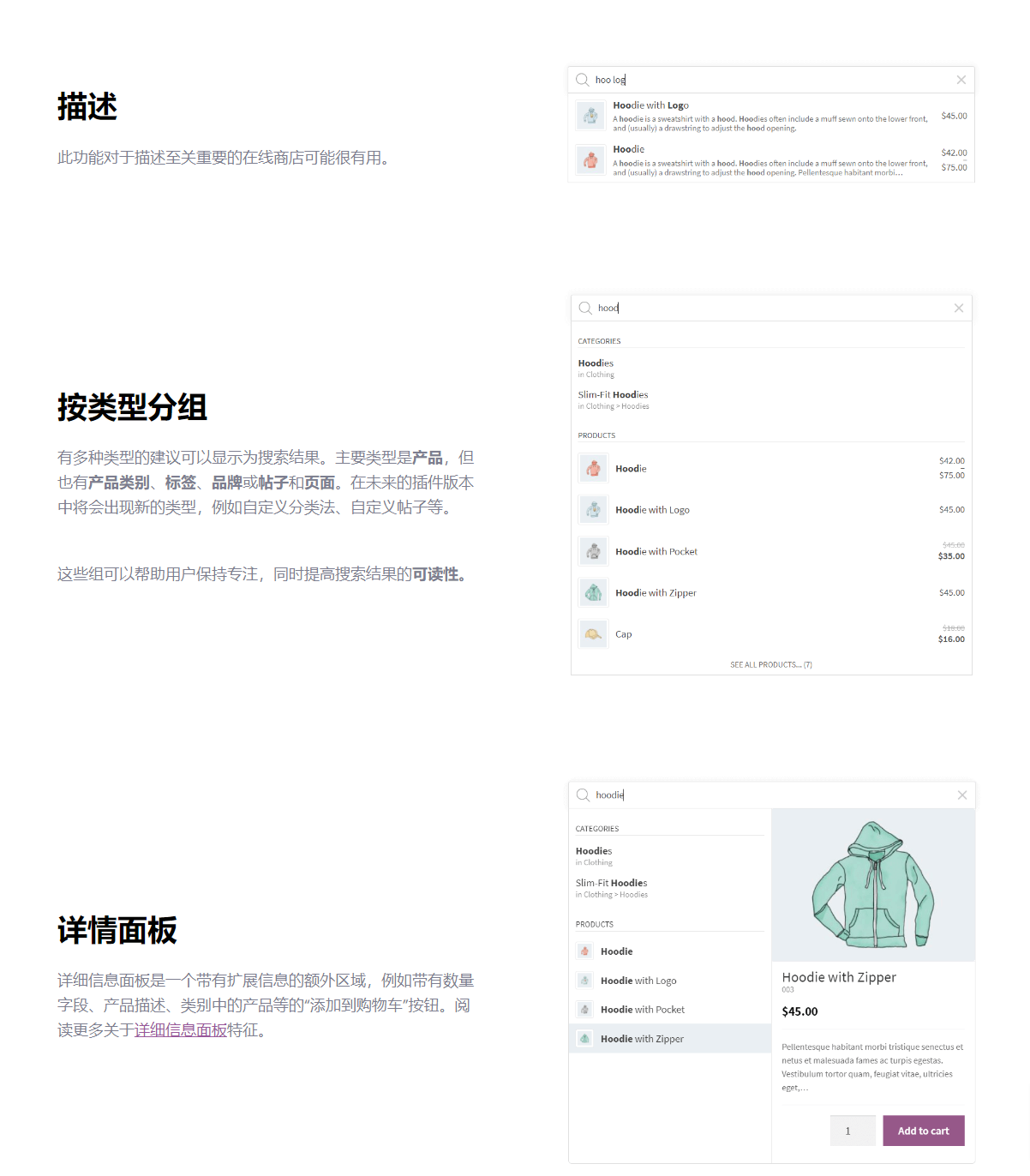
文章目录
- 摘要
- 一、引言
- 二、相关工作
- 三、Zero-1-to-3
- 3.1.学习如何控制照相机的视角
- 3.2.视角作为条件的扩散
- 3.3三维重构
- 3.4 数据集
- 四、One-2-3-45
- 4.1 Zero123: 视角条件的 2D Diffusion
- 4.2 NeRF优化:将多视图预测提升到三维图像
- 4.3 基于不完美多视图的 神经表面重建
- * 2阶段 源视图选择 和 Groundtruth预测 混合训练
- 4.4 像机位姿估计
- 总结
Zero-1-to-3: Zero-shot One Image to 3D Object
论文:https://arxiv.org/pdf/2303.11328.pdf
摘要
提示:这里可以添加本文要记录的大概内容:
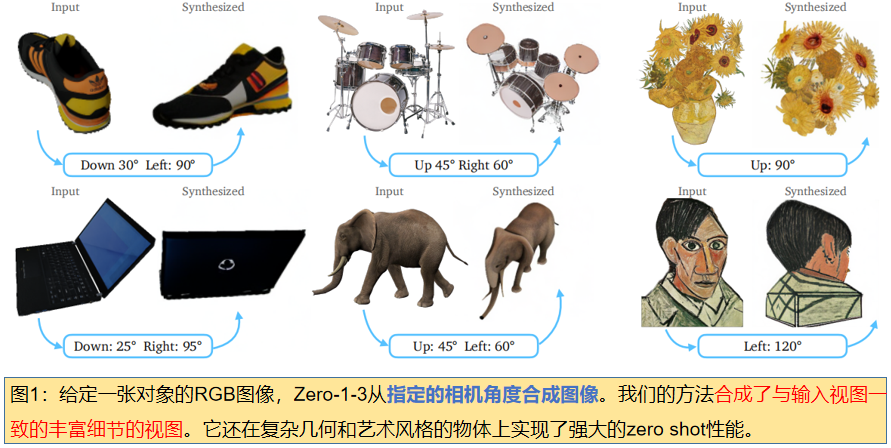
Zero-1-3:只给定一张RGB图像(为了在这种欠约束的设置下进行新的视图合成),利用大规模扩散模型,学习关于自然图像的几何先验。我们的条件扩散模型使用合成数据集来学习对相对摄像机视点的控制,这允许在特定的摄像机转换下生成同一对象的新图像。即使它是在合成数据集上训练的,我们的模型保留了对分布外数据集的zero shot 泛化能力,以及在野外的图像,包括印象派绘画。我们的视点条件扩散方法可以进一步用于从单幅图像的三维重建任务。
One-2-3-45则是在 Zero-123的基础上,进一步将不太一致的多视图像,提升到三维空间(mesh 或 sdf 形式)
一、引言
仅仅从一个相机的角度来看,人类通常能够想象一个物体的三维形状和外观。这种能力可以部分通过依赖几何先验来解释,事实上,我们可以预测在物理世界中不存在(甚至不可能存在)的物体的三维形状,这依赖于人类一生的视觉探索而积累起来的先验知识。
相比之下,大多数现有的3D图像重建方法都是在封闭的世界环境中运行的,因为它们依赖于昂贵的3D注释(如CAD模型)或针对特定类别的先验[37,21,36,67,68,66,25,24]。
在本文中,我们证明了大规模扩散模型,能够学习操纵摄像机视点的控制机制,如稳定扩散[44],以进行zero shot 新视图合成和三维形状重建。现代生成模型(超过50亿张图像),扩散模型是自然图像分布的最新表示,支持从许多角度涵盖了大量的对象。虽然它们是在没有摄像机对应的二维单眼图像上训练的,没有任何对应的图像,但我们可以微调模型,以学习在生成过程中相对摄像机旋转和平移的控制。这些控制允许我们编码任意图像解码到一个不同的我们选择的相机视点。图1显示了我们的结果的几个示例。
本文证明了大型扩散模型已经学习了关于视觉世界的丰富的三维先验,即使它们只在二维图像上进行了训练。第2节中简要回顾一下相关的工作。在第3节中,我们描述了通过微调大型扩散模型来学习相机外显器控制的方法。在第4节提出了几个定量和定性的实验来评估zero shot视图的合成和从单一图像的几何形状和外观的三维重建。
二、相关工作
略
三、Zero-1-to-3
给定一个物体的单一RGB图像 x∈RH×W×3,目标是从不同的相机角度合成该物体的图像。设R∈R3×3和T∈R3 分别为所需视点的相对摄像机旋转和平移。我们的目标是学习一个模型 f,它在这个相机转换下合成了一个新的图像:
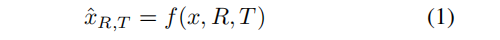
我们希望我们估计的
x
^
\hat{x}
x^ R.T 在感知上与真实但未被观察到的新视图 xR,T 相似。
由于其训练数据[47]的规模,预先训练好的扩散模型是当今自然图像分布的最先进的表示。然而,我们必须克服两个挑战来创造 f 。首先,大规模生成模型是在不同视点下的各种对象上进行训练的,这些表示并没有明确地编码视点之间的对应关系。其次,生成模型继承了互联网上反映的观点偏见。如下图2所示,稳定扩散倾向于生成具有规范姿态的前置椅子的图像。这两个问题极大地阻碍了从大规模扩散模型中提取三维知识的能力。

3.1.学习如何控制照相机的视角
由于扩散模型是在网络尺度数据上进行训练的,它们对自然图像分布的支持可能涵盖了大多数对象的大多数观点,但这些观点不能在预先训练的模型中得到控制。一旦我们能够教模型一种机制来控制捕捉照片的相机外部功能,那么我们就能解锁执行新视图合成的能力。
为此,给定成对图像及其相机外参的数据集{x,xR,T,R,T},如图3所示,我们微调预训练的扩散模型,以学习对相机参数的控制,而不破坏其他参数的表示。使用具有编码器、去噪U-Net和解码器的潜在扩散架构。在扩散时间步长t∼[1,1000],设c(x,R,T)作为输入视图和相对相机外部信息的嵌入。然后,我们求解以下目标来微调模型:
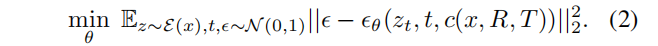
经过模型εθ 的训练后,推理模型 f 可以通过对以c(x,R,T)为条件的高斯噪声图像进行迭代去噪来生成图像。
推断出微调数据集中看到的对象之外的视角,最终的模型可以为缺乏3D assets 且永远不会出现在微调集中的对象类合成新的视图。
3.2.视角作为条件的扩散
从单一图像进行三维重建需要低级感知(深度、阴影、纹理等) 和高水平的理解(类型、功能、结构等)。因此,我们采用了一种混合调节机制:
在一个流上,将输入图像的CLIP嵌入与(R,T)连接,形成一个“posed CLIP”嵌入c(x,R,T)。我们将交叉注意作为去噪U-Net的条件,其 提供了输入图像的高级语义信息。
在另一个流上,输入图像与被去噪的图像进行通道连接,帮助模型保持被合成的对象的身份和细节。
为了能够应用无分类器引导[19],我们遵循[3:InstructPix2Pix]中提出的类似机制,将输入图像和假设的CLIP嵌入随机设置到一个零向量,并在推理过程中对条件信息进行缩放。
3.3三维重构
在许多应用中,合成一个物体的新视图是不够的。一个完整的三维重建,能够捕获对象的外观和几何形状是理想的。我们采用了一个最近的开源框架,Score Jacobian Chaining (SJC)[53],来优化一个从文本到图像扩散模型的先验的三维表示。然而,由于扩散模型的概率性质,梯度更新是高度随机的。受DreamFusion [38]的启发,SJC中使用的一个关键技术是将无分类器的引导值设置为明显高于通常的值。这种方法减少了每个样本的多样性,但提高了重建的保真度。
如图4所示,与SJC类似,我们随机抽样视点,并执行体渲染。然后,我们用高斯噪声 ε~N(0,1)对得到的图像进行扰动,并通过应用以输入图像x、假设CLIP嵌入c(x,R,、T)和时间步长T为条件的U-Net εθ 对其进行去噪,以近似于无噪声输入xπ:
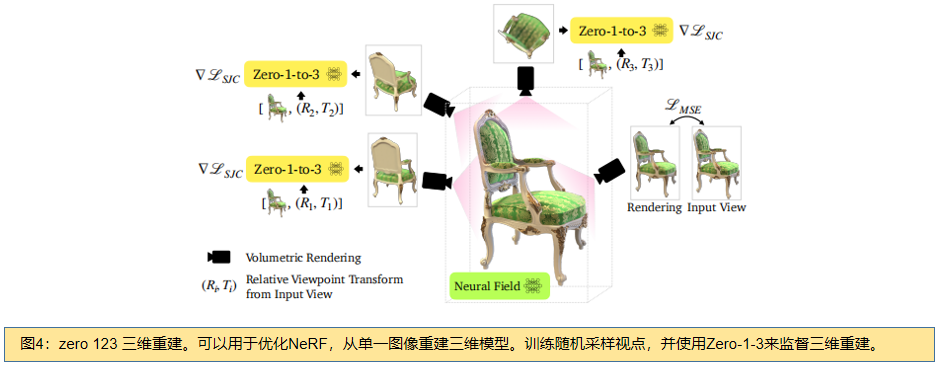
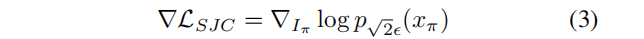
其中,∇LSJC 是由[53]引入的PAAS分数。此外,我们还使用MSE损失来优化输入视图。为了进一步规范NeRF表示,我们还对每个采样视点应用深度平滑性损失,并应用近视图一致性损失来规范附近视图之间的外观变化。
3.4 数据集
我们使用最近发布的Objaverse[8]数据集进行微调,这是一个大规模的开源数据集,包含由100K+艺术家创建的800K+ 3D模型。虽然它没有像ShapeNet [4]这样明确的类标签,但它体现了大量几何形状丰富的高质量3D模型,其中许多具有细粒度的细节和材料属性。对于数据集中的每个对象,我们随机抽取12个相机外部矩阵,我指向对象的中心,并使用光线追踪引擎渲染12个视图。在训练时,每个对象可以采样两个视图,形成一个图像对(x、xR,T)。相应的相对视点变换(R,T)去了两个视点之间的映射,可以很容易地从两个外部矩阵中导出。
四、One-2-3-45
给定一幅图像,首先使用 view-conditioned 二维扩散模型 Zero123,生成对应的多视图图像,然后将它们提升到三维空间。由于传统的重建方法存在不一致的多视图预测,我们基于sdf的广义神经表面重建方法构建了三维重建模块,并提出了几种关键的训练策略来实现360度网格(mesh)的重建,能产生更好的几何形状和三维一致的结果。此外,还集成了现成的文本到图像的扩散模型。
这项工作是一个通用的解决方案,将任何类别的图像,变成一个高质量的3D纹理网格(mesh)。与3D数据相比,2D图像更容易获得和可扩展。最近的二维生成模型(如DALLE 、Imagen 和Stable Diffusion)和视觉语言模型(如CLIP )通过对互联网规模的图像数据集进行预训练取得了重大进展。一个新兴领域,如DreamField, DreamFusion, and Magic3D,常用可微渲染和CLIP模型或二维扩散模型的指导来执行每个形状的优化。其中神经场是优化中最常用的表示。其缺点:1.耗时 2.内参紧张 3.三维不一致 4.不好的纹理。
4.1 Zero123: 视角条件的 2D Diffusion
最近的工作[23:Lora,91:Adding conditional control to text-to-image diffusion models]表明,预训练2D Diffusion 的微调允许我们在扩散模型中添加各种条件控制,并根据特定条件生成图像。条件,如canny 边缘、用户涂鸦、深度和法线图,已经被证明是有效的[91]。
Zero123 旨在为 2D Diffusion添加视点条件控制:微调成对图像上的相对相机转换,由大规模3D数据集[11]合成。其假设对象以坐标系的原点为中心,并使用一个球形摄像机,即摄像机被放置在球体的表面上,并且总是查看原点。对于两个相机姿态(θ1,ϕ1,r1)和(θ2,ϕ2,r2)分别表示极角、方位角和半径,目标模型:f(x1,θ2−θ1,ϕ2−ϕ1,r2−r1)在感知上与x2 相似,其中x1和x2是从不同视图捕获的一个物体的两幅图像。
4.2 NeRF优化:将多视图预测提升到三维图像
给定一张图像,首先使用Zero123生成32张多视图图像(相机姿态从球面均匀采样);然后用基于nerf的方法(TensoRF [48])和基于SDF的方法(NeuS [74]),分别优化密度和SDF场。效果如图3:由于zero 123预测不一致,产生了大量的扭曲和漂浮物。在图4中,我们将Zero123的预测与GroundTruth 的效果进行比较,总体PSNR不高,特别是当输入相对姿态很大或目标姿态在不寻常的位置(例如,从底部或顶部)。

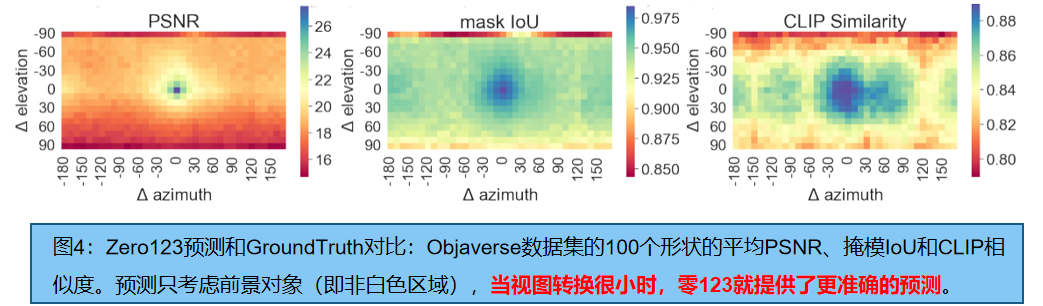
然而,mask IoU(大多数区域大于0.95)和CLIP相似性相对较好。表明Zero123倾向于产生在感知上与GroundTruth 相似的预测,并具有相似的轮廓或边界,但像素级的外观可能并不完全相同,这种不一致对于传统的基于优化的方法已经是致命的。
4.3 基于不完美多视图的 神经表面重建
不使用基于优化的方法,重建模块基于一个可推广的SDF重建方法SparseNeuS(MVSNeRF 的一个变体),它结合了多视图立体、神经场景表示和体积渲染。如图2所示,我们的重建模块将多个源图像与相应的摄像机位姿作为输入,并在一次前馈通道中生成一个纹理网格。
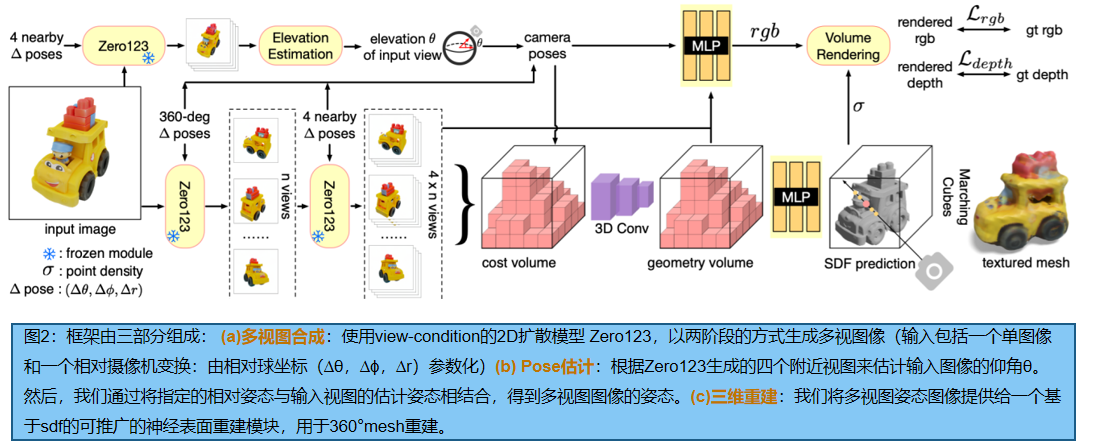
如图2所示,重建模块以m个姿态的源图像作为输入,首先使用二维特征网络提取 m 个二维特征图。接下来,该模块构建一个三维cost volume(代价体),其内容由 每个三维体素投影到m个二维特征平面,对应的 m 个投影二维位置的特征的方差计算得到。然后使用一个稀疏的3D CNN来处理cost volume,以获得一个对输入形状的基础几何形状进行编码的的几何 volume。为了预测任意三维点上的SDF,MLP网络从几何编码体中获取三维坐标及其相应的插值特征作为输入。为了预测一个三维点的颜色,另一个MLP网络以投影位置的二维特征,从几何体中插值特征,以及相对于源图像的查看方向的查询光线的查看方向作为输入。该网络预测每个源视图的混合权重,并将三维点的颜色预测为其投影颜色的加权和。最后,将一种基于sdf的渲染技术应用于两个MLP网络之上,用于RGB和深度渲染[74:Neus]。
* 2阶段 源视图选择 和 Groundtruth预测 混合训练
SparseNeuS 只演示了正面视图重建,但我们通过以特定的方式选择源视图并在训练过程中添加深度监督,在一次前馈通道中重建360度网格。具体来说,我们的重建模型是在一个三维对象数据集上训练的,同时冻结zero 123。我们遵循Zero123来规范化训练形状,并使用一个球形摄像机模型。对于每个形状,我们首先渲染n个GroundTruth RGB和来自n个相机姿态的深度图像,均匀地放置在球体上。对于n个视图中的每一个,我们使用Zero123来预测附近的四个视图。
训练时,我们将所有4个具有GroundTruth 姿态的×n预测输入重建模块,并随机选择n个地面真实RGB图像视图中的一个作为目标视图。我们将这种视图选择策略称为2阶段的源视图选择。我们用GT的RGB和深度值来监督训练。通过这种方式,该模块可以学习处理来自Zero123的不一致的预测,并重建一个一致的360◦网格。我们认为,我们的两级源视图选择策略是至关重要的,因为从球面统一选择n×4个源视图会导致相机姿态之间的距离更大。然而,基于cost volume 的方法[40,28,6]通常依赖于非常接近的源视图来找到局部相关性。此外,如图4所示,当相对姿态较小时(例如,相距10度),Zero123可以提供非常准确和一致的预测,因此可以用来寻找局部对应和推断几何形状。
训练时,我们在第一阶段使用n个GroundTruth 渲染,使深度损失更好的监督。然而,在推理过程中,我们可以用Zero123预测替换n个GroundTruth 渲染,如图2所示,并且不需要深度输入。我们将在实验中表明,这种GroundTruth 预测混合训练策略也很重要。为了导出纹理网格,我们使用 marching cubes [41]从预测的SDF字段中提取mesh,并查询 Neus 中描述的网格顶点的颜色。虽然我们的重建模块是在三维数据集上训练的,但我们发现它主要依赖于局部对应,可以很好地推广到看不见的形状。
4.4 像机位姿估计
我们的重建模块需要4×n源视图图像的像机位姿。请注意,我们采用Zero123来进行图像合成,它在一个标准的球面坐标系中,(θ,ϕ,r)中参数化摄像机。虽然我们可以任意调整方位角ϕ和半径r所有源视图图像同时,导致相应的旋转和比例重建对象,这个参数化需要知道一个相机的绝对仰角θ,在一个标准的XYZ框架中确定所有相机的相对位姿。具体地,相机(θ0,ϕ0,r0)和相机(θ0+∆θ,ϕ0+∆ϕ ,r0)对不同θ0 的相对姿态也不同,即使∆θ和∆ϕ是相同的。因此,同时改变所有源图像的elevation angle仰角(例如,上升30度或下降30度)将导致重建形状的扭曲(示例见图10)。
因此,我们提出了一个仰角估计模块来推断输入图像的仰角(elevation angle)。首先,我们使用Zero123来预测输入图像的四个附近视图。然后,我们以从粗到细的方式列举所有可能的仰角。对于每个高程候选角,我们计算四张图像对应的相机姿态,并计算这组相机姿态的重投影误差,以测量图像和相机姿态之间的一致性。通过结合输入视图的姿态和相对姿态,使用重投影误差最小的仰角来生成所有4×n源视图的相机姿态。(重投影误差,请参阅补充资料)。