题目描述:

题目参数
/**
* Return an array of arrays of size *returnSize.
* The sizes of the arrays are returned as *returnColumnSizes array.
* Note: Both returned array and *columnSizes array must be malloced, assume caller calls free().
*/
int** mergeArrays(int** nums1, int nums1Size, int* nums1ColSize, int** nums2, int nums2Size, int* nums2ColSize, int* returnSize, int** returnColumnSizes){
}
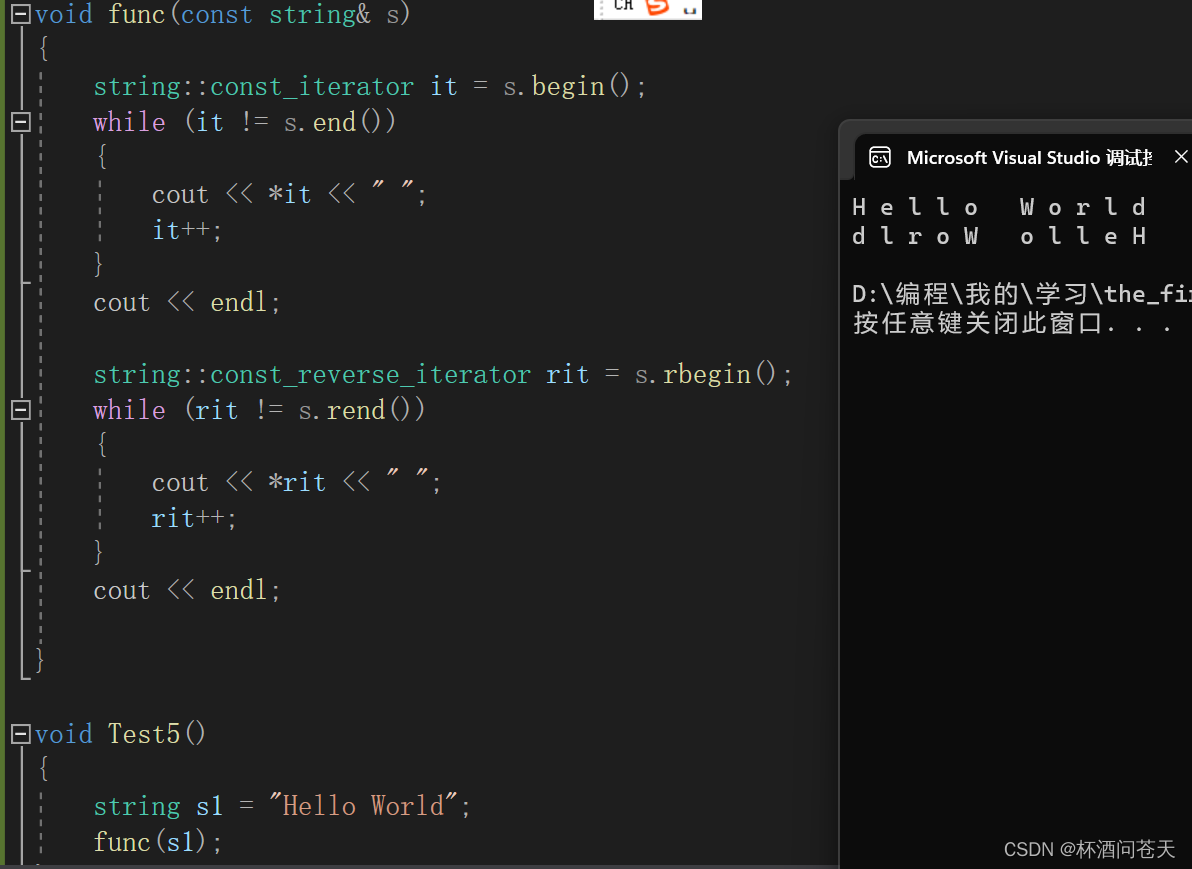
1.参数int **nums1 :表示二维数组 void fun(int (*p)[4] ) == void fun(int p[][4]) 二维数组,就是数组指针,这个指针指向的是这个数组,真正意义上的指向数组 ,不是指向数组第一个元素地址;
void test2(int *arr[])
{
}
int * arr2[10]={0}; 这条语句代表创建了一个指针数组arr2,数组有10个元素,每个元素的类型为int* ,并全部初始化为0。因此,我形参接受的时候也用一个指针数组类型接受,
void test2(int **arr)
{
}
arr2为一个指针数组类型,里面放的是指针。arr2代表这个指针数组的首元素的地址。arr2这个地址,存放的是一个int* 类型的指针。存放指针的地址,就是一个二级指针。因此实参本质上是一个二级指针,那形参我用一个二级指针接受当然可以。
二维数组首元素的地址为第一行的地址,即整个一维数组的地址。
2.int* nums1ColSize
nums1ColSize是一个指针,取*就是大小 == 2;表示每列有多少个元素;
3.int* returnSize, int** returnColumnSizes
- returnSize 表示返回的二维数组中一维数组个数有多少个 * returnSize = 4;(如上图)
** returnColumnSizes 表示
解题思路:
1.hash下标为nums1 和 nums2的下标id,值为val‘
2.对hash的key进行排序;
//二维数组排序 以第二维第一个元素为key进行升序排序
int cmp(const void *a, const void *b)
{
return (*(int **)a)[0] - (*(int **)b)[0];
}
int** mergeArrays(int** nums1, int nums1Size, int* nums1ColSize, int** nums2, int nums2Size, int* nums2ColSize, int* returnSize, int** returnColumnSizes){
//记录
int buckets[1001] = {0};
// 扫描两个数组,收集 id 和 val。id 就是下标。
for (int i = 0; i < nums1Size; i++) {
buckets[nums1[i][0]] = nums1[i][1];
}
for (int j = 0; j < nums2Size; j++) {
if (buckets[nums2[j][0]] != 0) {
buckets[nums2[j][0]] += nums2[j][1];
} else {
buckets[nums2[j][0]] = nums2[j][1];
}
}
int** ans = malloc(sizeof(int*) * 1001);
int p = 0; // 跟踪int**数组,尾指针。
*returnColumnSizes = malloc(sizeof(int) * 1001);
// 取出桶中所有不为0的元素,分配内存,记录id和val
for (int k = 0; k < 1001; k++) {
if (buckets[k] != 0) {
ans[p] = malloc(sizeof(int) * 2);
ans[p][0] = k;
ans[p][1] = buckets[k];
(*returnColumnSizes)[p] = 2;
p++;
}
}
// 最后按id排序
qsort(ans, p, sizeof(int*), cmp);
*returnSize = p;
return ans;
}