发布于 2018-08-13 12:42
阅读原文:http://www.cccttt.me/blog/2018/04/10/ceph-performance-estimate
1、前言
最近在做Ceph性能测试相关工作,在测试初期由于没有得到理想的测试结果,因此对Ceph集群进行了优化,但是一直有个问题萦绕在我的脑海:基于当前硬件配置,这个Ceph集群的极限是多少?
由于这个问题和Ceph的配置息息相关,为了简化问题,在本文中我们只会会讨论3个变量:冗余策略(纠删码、多副本),读/写,ObjectStore。我们将会基于磁盘、网络、CPU性能来估算出一个集群的性能,除此以外的参数影响均归并到损耗系数μ这个变量。本文会分别解释写性能公式推演、读性能公式推演,并且在每个推演中加入冗余策略和ObjectStore的讨论。
2、ObjectStore简介
Ceph目前提供了三种存储后端:
-
FileStore
-
KStore
-
BlueStore
而KStore由于接纳程度不高,目前很少有厂商使用,因此在本文中只介绍和对比FileStore和BlueStore。
2.1 FileStore
在FileStore中,每个Ceph对象都被保存在本地文件系统中(XFS, ZFS等)。Ceph为了保证一致性,要求读写操作都是atomic的,因此会需要在Ceph内部做一次Journal,也就是说,每次客户端数据写入时,首先会采用Append-only的模式将数据写入到Journal中去,随后再执行真正的数据写入操作。然而在本地文件系统又会做一次Journal,因此就会产生Journaling of journal问题,也就是记录了2次Journal。为了提高写入性能,一般在部署Ceph集群时,会将单独划分SSD给Ceph journal。
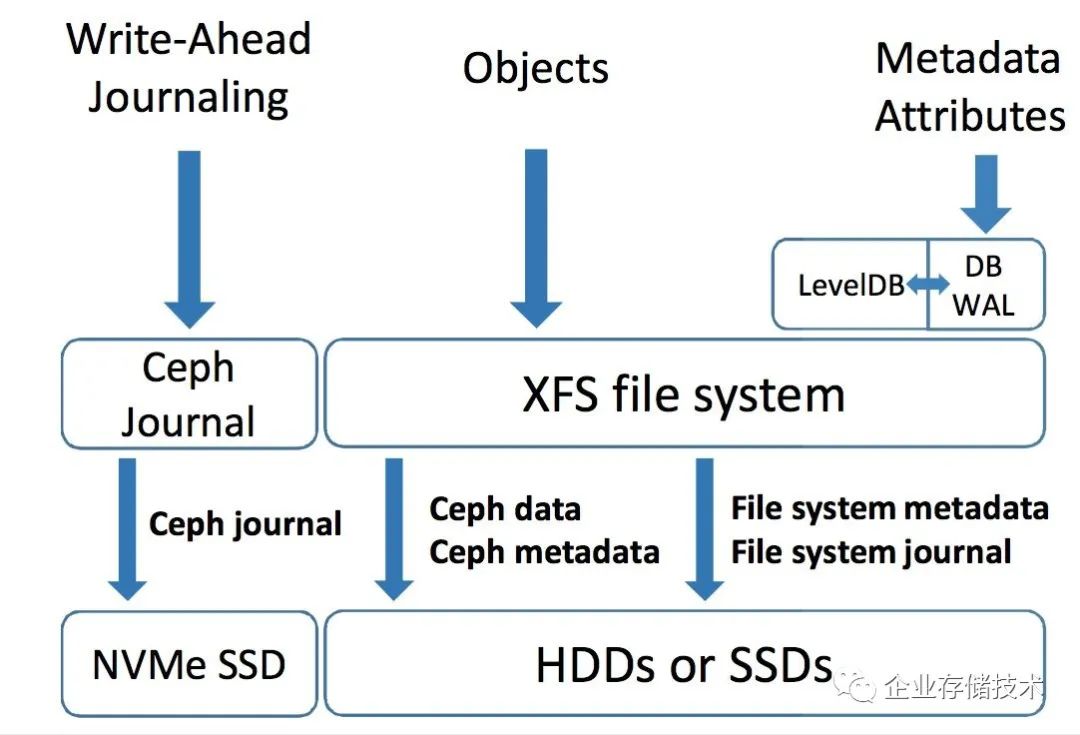
2.2 BlueStore
为了提高Ceph的写入性能,社区开发了BlueStore这一存储后端,让数据绕开了本地文件系统直接裸盘,从而解决了Journaling of journal问题。BlueStore采用RocksDB来管理对象元数据,因此为了跑RocksDB,BlueStore内部有一个微型用户态的文件系统-BlueFS。得益于RocksDB,Ceph可以很方便的获取和枚举所有的对象。
3. 读性能公式推演
读性能公式目前推测较为简单,无论在FileStore还是BlueStore下,均推断为 Wnμ
W: 单块裸盘读带宽
n: OSD数量
μ:损耗系数 一般为0.7~0.8
下面注重来介绍一下写性能公式推演:我们会逐一探讨:
-
FileStore + 多副本 写性能公式推演
-
BlueStore + 多副本 写性能公式推演
-
FileStore + 纠删码 写性能公式推演
-
BlueStore + 纠删码 写性能公式推演
4、写性能公式推演
4.1 FileStore + 多副本
在当前情况下,我们假设Ceph集群的ObjectStore是FileStore, 并且对应的Pool的冗余策略为多副本,SSD作为一个OSD,其journal和data都放在这块SSD上。因此我们一次写入的流程可以简化成下图:数据先写到Ceph的journal上,然后再写入data中,并且在本地文件系统会再做一次journal,由于journaling of journal问题,单个OSD的WAF(写放大系数)为2。在当前冗余策略下,一个文件写入需要产生多个副本N,因此集群放大系数为2*N。
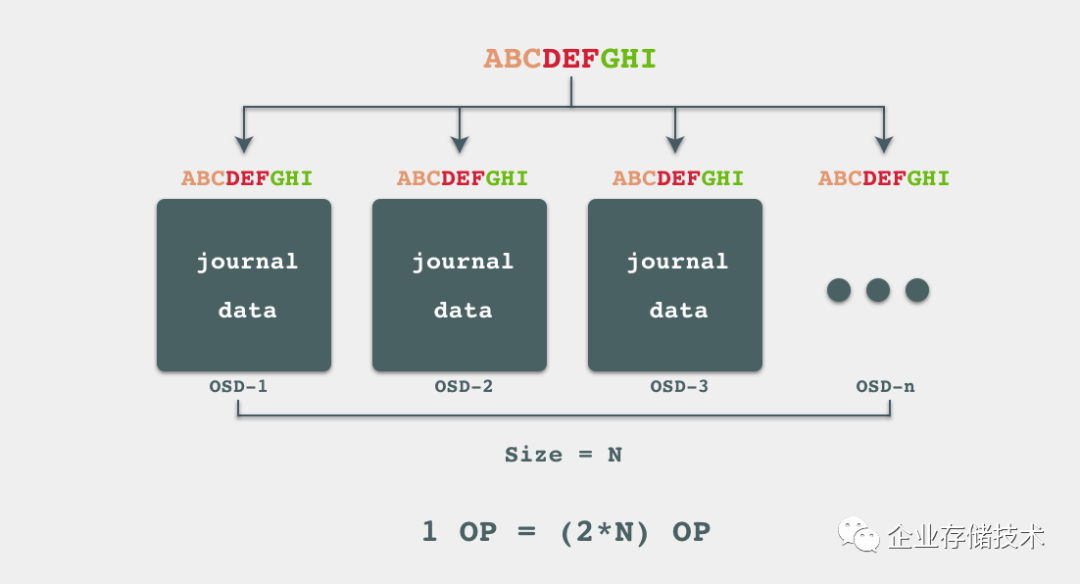
然而在写入对象时,我们写入的不单单是数据本身,在Ceph RBD的journal中,RBD写操作是变成transaction操作,transaction会包含一些元数据用于描述transaction,这些元数据也写到journal上,这就也会导致写放大。因此一次写入的WAF不仅仅需要考虑多副本、journaling of journal问题,还需要考虑transaction元数据。
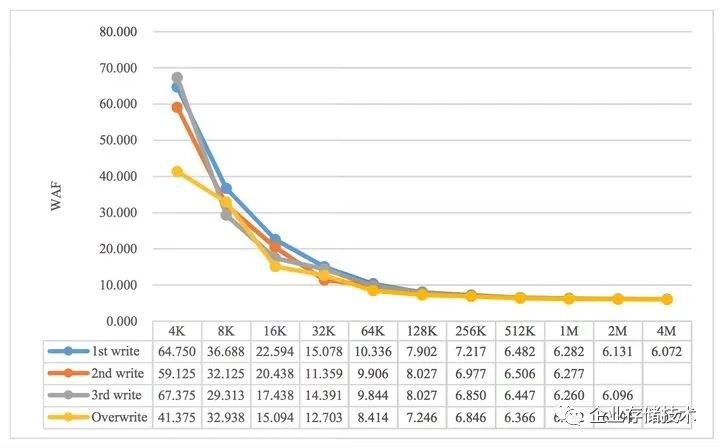
韩国成均馆大学曾经对Ceph存储后端对写入放大系数的影响做过一定的研究,在其发表的《Understanding Write Behaviors of Storage Backends in Ceph Object Store》论文中,测试了在3副本+FileStore情况下,用Ceph RBD写入不同数据块与WAF的关系。从Figure 5我们可以看到,当数据写入量较大时,WAF逐渐收敛于6,符合我们上文WAF=2*N的推理;但是当写入对象很小时,WAF则会很大。
这是因为当数据量很小时,同时完成的transaction元数据量所占比重会很大,根据上图数据,我推测每次写入所产生的transaction元数据大概在5KiB左右,因此可以推断,在包含transaction元数据的情况下,WAF为:
WAF=[(X+5)*2*N]/X
-
X为写入数据块大小(KiB)
-
N为副本数
随着数据块增大,在FileStore、多副本冗余策略下WAF最终将向2N收敛。假设我们知道了一块SSD的写性能可以达到W MB/s的带宽,那么在理想情况下,我们可以很容易推断出,一个大小为n的SSD集群的写带宽能达到 W*N MB/s。
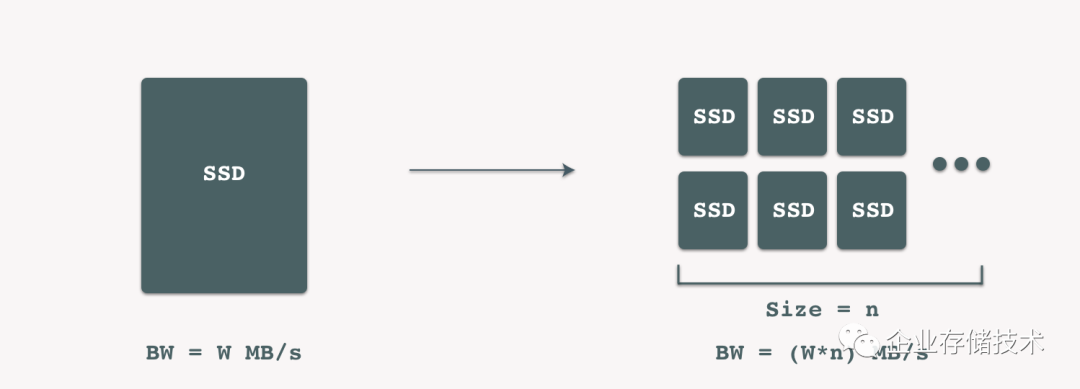
如果考虑外部因素多带来的损耗为μ,我们最终可以推断出BlueStore+多副本情况下,写性能可以达到:
BW=[(W*n)/WAF]*µ
WAF=[(X+5)*2*N]/X
-
WAF为写放大系数
-
X为写入数据块大小(KiB)
-
N为副本数
-
n为OSD数量
-
μ为损耗系数 一般为0.7~0.8
4.2 BlueStore + 多副本
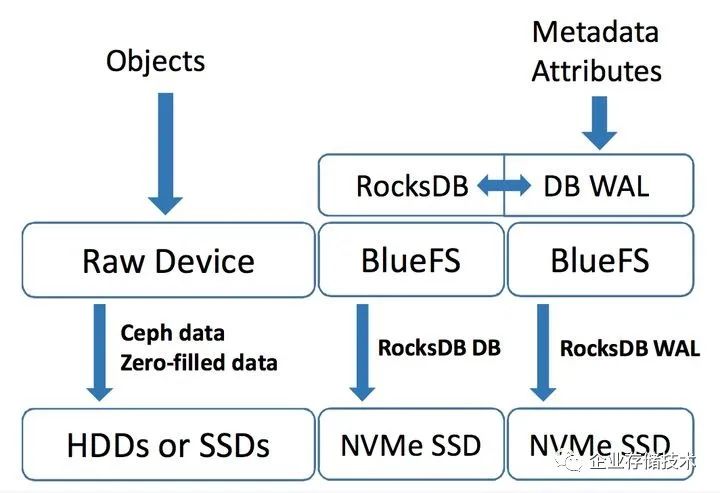
在当前情况下,我们假设Ceph集群的ObjectStore是BlueStore, 并且对应的Pool的冗余策略为多副本,SSD作为一个OSD,划分为2块分区,一个分区作为裸盘来写入数据,另一块做BlueFS用来跑RocksDB。因此我们一次写入的流程可以简化成下图:数据会被直接写入到data分区(裸盘)中,而对象元数据会被写到RocksDB和RocksDB的WAL中,随后RocksDB将数据压缩后存放到磁盘中。我们不再需要在文件系统层做journal,而WAL只在覆写操作时才会用到,因此在副本数量为N的条件下,我们可以推测WAF将收敛于N。
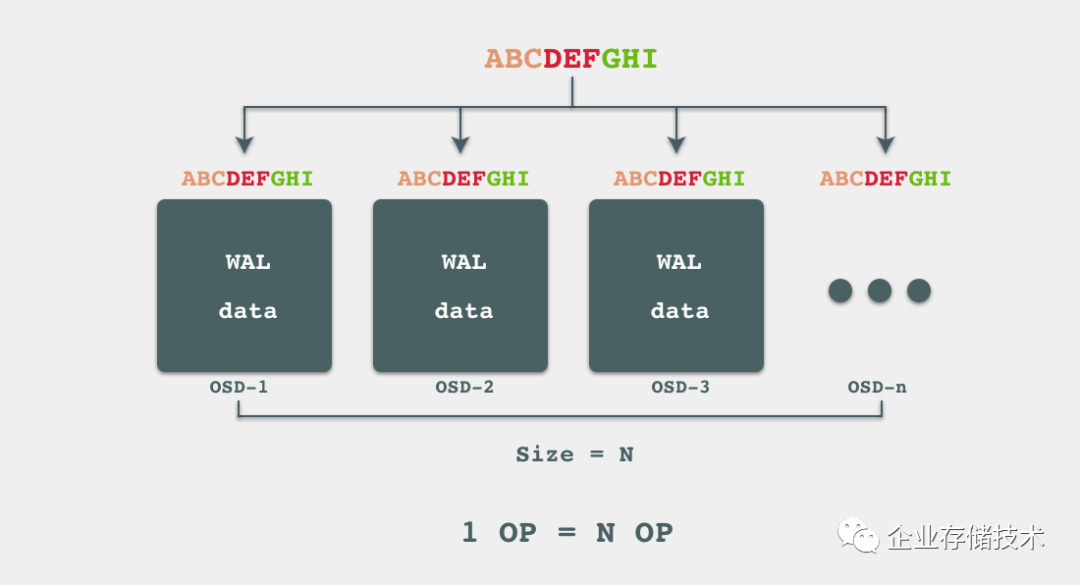
值得注意的一点,在BlueStore中,磁盘分区会以‘bluestore_min_alloc_size’的大小分配管理,这个数值默认为64KiB。也就是说,如果我们写入<64KiB的数据,剩余的空间会被0填充,也即是Zero-filled data,然后写入磁盘,也正是这样,BlueStore的小文件随机写性能并不好。
这里同样引用《Understanding Write Behaviors of Storage Backends in Ceph Object Store》论文中针对BlueStore在三副本策略下,不同数据块写入时WAF的变化图:
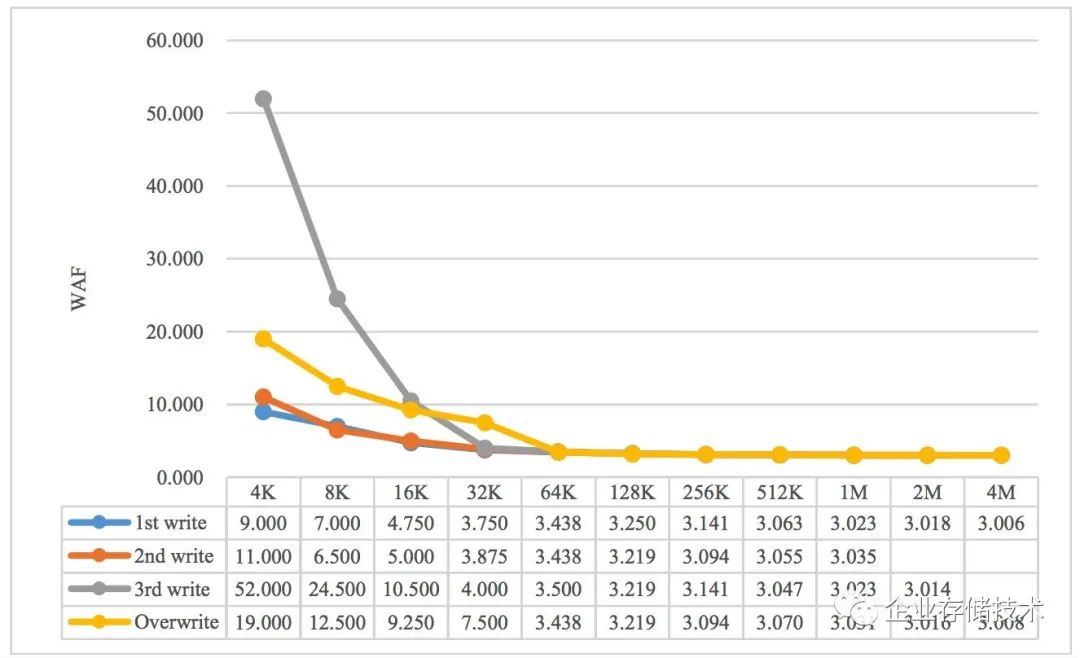
可以看到,当写入数据块很小时,WAF的数值很大。灰色曲线正是做了前文所说的‘小文件随机写’,因此性能较差;覆写操作时,由于Ceph为了保证一致性,会将数据先写入到RocksDB WAL中去,然后再由RocksDB WAL将数据落到磁盘上去,因此覆盖性能也会稍差一些。随着数据块的增大,所有曲线最终收敛于3,符合我们前文中推断的 WAF=N 。
综上所述,在多副本策略下,BlueStore的WAF的推演公式需要考虑:数据块大小,RocksDB压缩数据大小, Zero-filled数据大小以及副本数量。当随机写入小数据块的时候,会产生较多的Zero-filled数据,同时RocksDB压缩数据大小所占比重也会较大;当顺序写入大数据时,Zero-filled数据则基本为0,并且RocksDB压缩数据所占比重也可以忽略不计,因此公式整理如下:
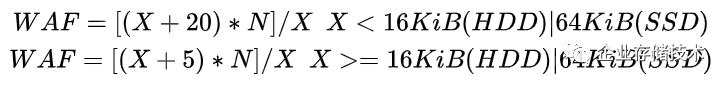
这里的推算主观性较强,当写入数据量小的时候( X < 16KiB(HDD)|64KiB(SSD) ),估算ceph会产生的zero-filled数据15kib和rocksdb压缩后存入磁盘的数据量5kib,共计20kib;而当写入数据量大时( X >= 16KiB(HDD)|64KiB(SSD) ),Zero-filled数据几乎为0,剩余RocksDB压缩后存入磁盘的数据量的5KiB。
如果考虑外部因素多带来的损耗为μ,我们最终可以推断出BlueStore+多副本情况下,写性能可以达到:
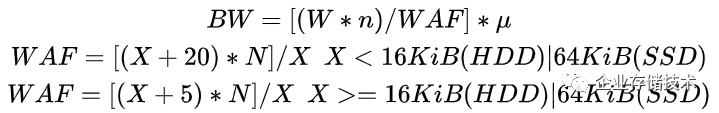
-
WAF为写放大系数
-
X为写入数据块大小(KiB)
-
N为副本数
-
n为OSD数量
-
μ为损耗系数 一般为0.7~0.8
4.3 FileStore + 纠删码
相比较多副本冗余策略,纠删码的出现大大节省了磁盘空间,以下图举例,如果我们有5个OSD,并且按照K=3, M=2配置纠删码冗余策略,当有一组数据写入时(ABCDEFGHI),该数据会被分成3份分别写入3个OSD中,同时Ceph也会生成2个编码块写入到另外2个OSD中,写就是说,一次写入操作,实际上会产生(K+M)/K倍的实际写入量。而由于这里使用的存储后端是FileStore,journaling of journal问题会让写放大两倍,因此结合纠删码本身特性,WAF最终会收敛于:
(K+M)/K*2
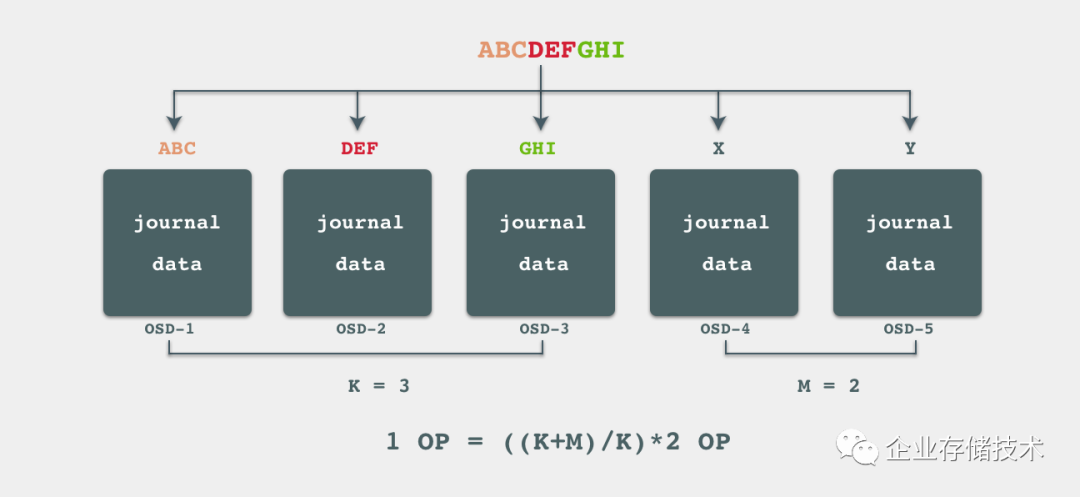
由FileStore+多副本的公式推演可知,在FileStore写入时,同时还需要考虑transaction元数据,每个对象大概是5KiB左右,因此在FileStore+纠删码策略下,集群可以达到的写性能为:
BW = [[(W*n)/WAF]*µ
WAF=[(X+5)*2*(K+M)/K]/X
-
WAF为写放大系数
-
X为写入数据块大小(KiB)
-
N为副本数
-
n为OSD数量
-
μ为损耗系数 一般为0.7~0.8
-
K为数据块的个数
-
M为校验块的个数
4.4 BlueStore + 纠删码公式
有了前文的铺垫后,相信到这一步大家能够自己推演出BlueStore在纠删码策略下的写入性能推导公式。由于解决了journaling of journal问题,每次写入不再需要通过文件系统,因此在WAF最终将会收敛于:
(K+M)/M
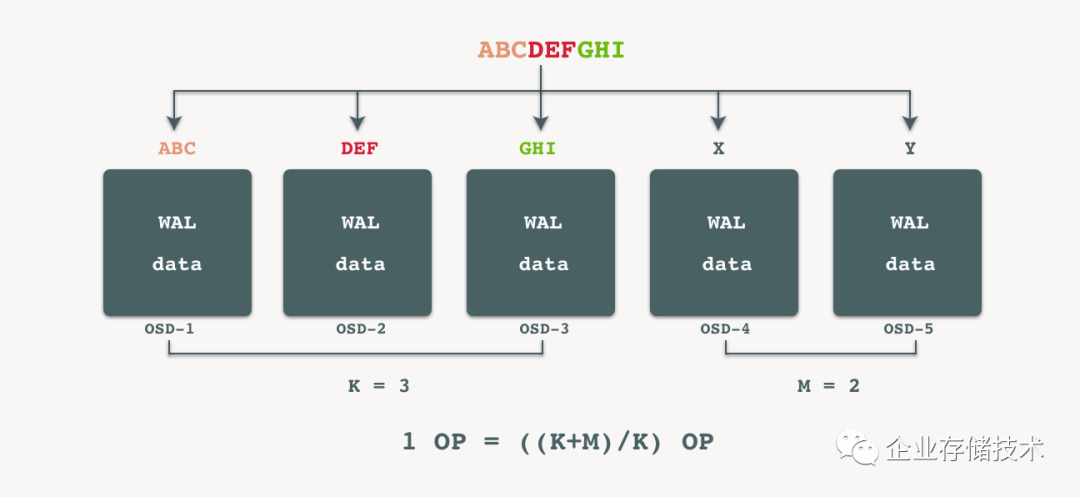
结合BlueStore+3副本的写入性能公式推导,我们可以大致推断出,BlueStore+纠删码的写入性能公式:
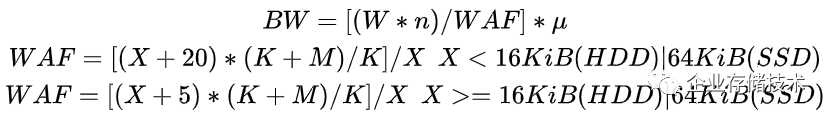
-
WAF为写放大系数
-
X为写入数据块大小(KiB)
-
N为副本数
-
n为OSD数量
-
μ为损耗系数 一般为0.7~0.8
-
K为数据块的个数
-
M为校验块的个数
5、Ceph写入性能公式总结
结合上文4个小节,我们最终得到了Ceph冗余策略和ObjectStore为变量的WAF推导公式:

Ceph集群写入性能可以大致推导为:
BW = [(W*n)/WAF]*µ
-
W: 单块裸盘写入带宽
-
n: OSD数量
-
WAF:写放大系数
-
μ:损耗系数
-
X: 写入数据块大小(KiB)
-
N: 多副本Size大小
-
K: 纠删码K值
-
M:纠删码M值
-
FileStore 5: 5KiB, FileStore中transaction元数据的数据量大小(推测值)
-
BlueStore 5: 5KiB, BlueStore中RocksDB的WAL数据大小(推测值)
-
BlueStore 20: 20KiB, BlueStore小文件写入时产生的Zero-filled数据块大小






![[保研/考研机试] 杨辉三角形 西北工业大学复试上机题 C++实现](https://img-blog.csdnimg.cn/8bb3bd8896b44b76ba106363166112ab.png)