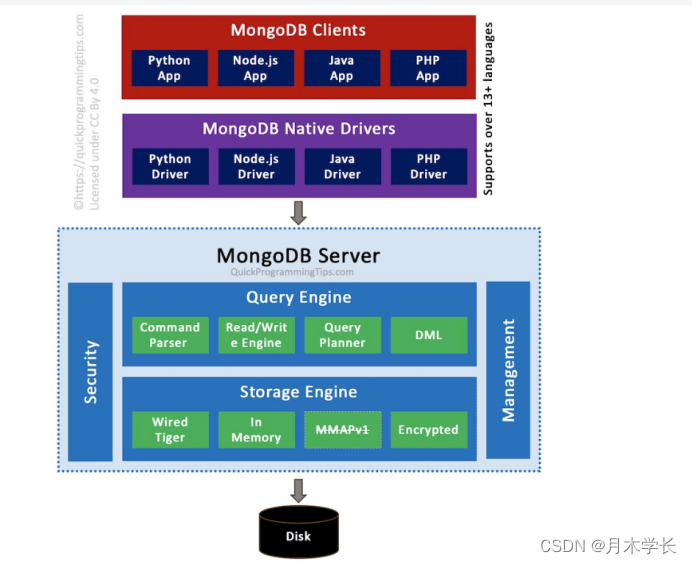
修改kafka的server.properties配置

概念
单播
一个消费组的消费者们只有一个能消费到消息。类似queue队列。
多播
不同的消费组的消费者能重复消费到消息,类似publish-subscribe模式
消费组偏移
kafka和别的消息中间件不一样,不同组可以重复消费,消费过的信息还在。默认不会删除,默认会保存7天,log.retention.hours设置
offset以组为单位。

topic-partition
topic是个逻辑概念
真的消息队列是partition
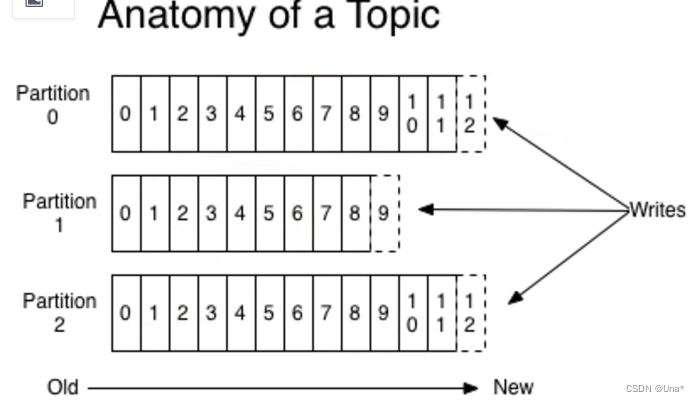
就有了partition,一个partition对应一个文件,可以放在不同机器,搞集群
partition是一个有序的message序列,这些message按照顺序添加到一个commit log文件,每个partition种的消息都有唯一编号offset用来唯一标识某个分区中的message。一个partition的message的offset都是唯一的,不同partition可能相同。
Kafka性能和存储的消息数据量大小无关。
每个consumer基于自己在commit log种消费进度(offset)进行工作,其由consumer自己维护,所以添加减少consumer对Kafka集群和其他消费者影响不大。
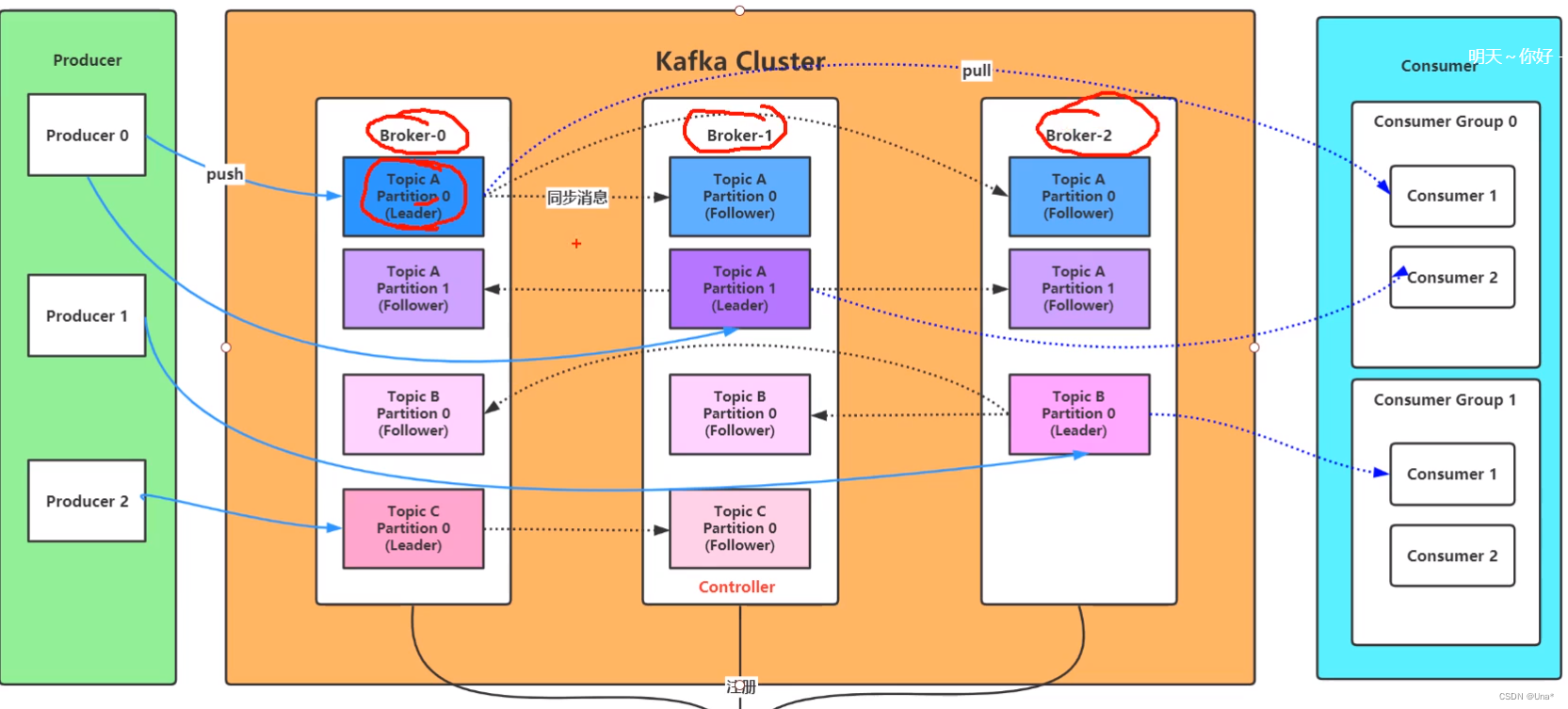
topic,partition,broker
topic是一个主题,逻辑概念,比如数据库表中order,user等。
partition是物理存储分区。
broker是每台机器的kafka的消息中间件进程。
kafka集群(针对partition不是机器
尽管只有一台机器,也叫做集群(天生即集群
例子:2个分区,3台kafka机器

Isr:已同步的副本
不同partition的leader不一样,避免同一台机器挂掉不能写,减压
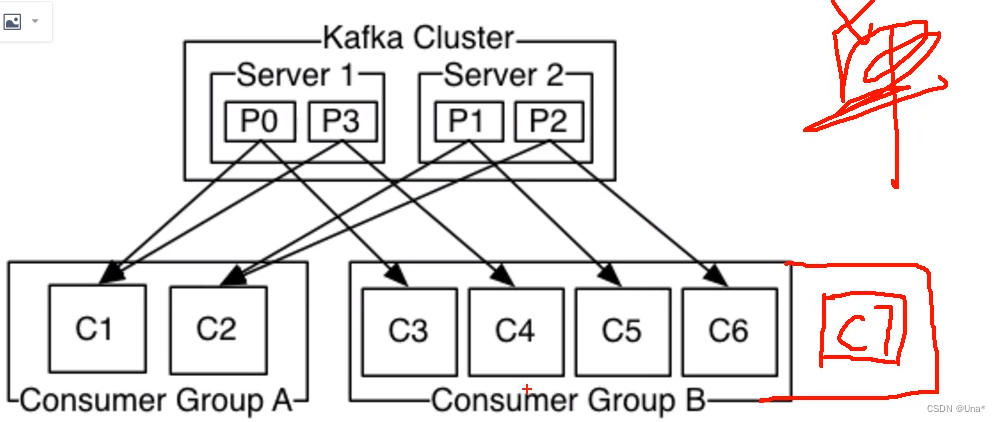
再加一个C7也没用不能消费partition了。所以线程并发四个就行。
Java api
分区是根据key来计算,哈希算法算出散列值,然后对分区数取模

Java 配置核心参数
producer端
acks
- acks = 0:producer不需要等待任何broker确认收到消息的回复就可以继续发送下一条消息,性能最高
- acks=1: 需要等leader写入本地log,但是如果follower没备份成功leader挂掉就丢消息,一般用这个
- acks=-1/all:min.insync.replicas配置大于等于2,写到副本节点。一般金融级别用,效率最低

重试
因为网络抖动发送失败会重试几次。可能会多发,重复了

重试间隔毫秒

缓冲区
客户端设置32MB的缓冲区buffer memory,
还有个缓冲区,卡夫卡本地线程从缓冲批量拉取消息,一次一batch16kb。
如果消息没满16kb,设置消息等待时间10ms,也会被发送到broker

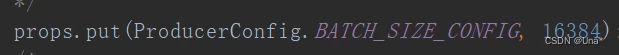

consumer端(长轮询,一秒内多次拉取。从broker拉取消息
指定消费分区

指定offset消费
从头消费:

指定offset

指定消费和offset提交没有关系。
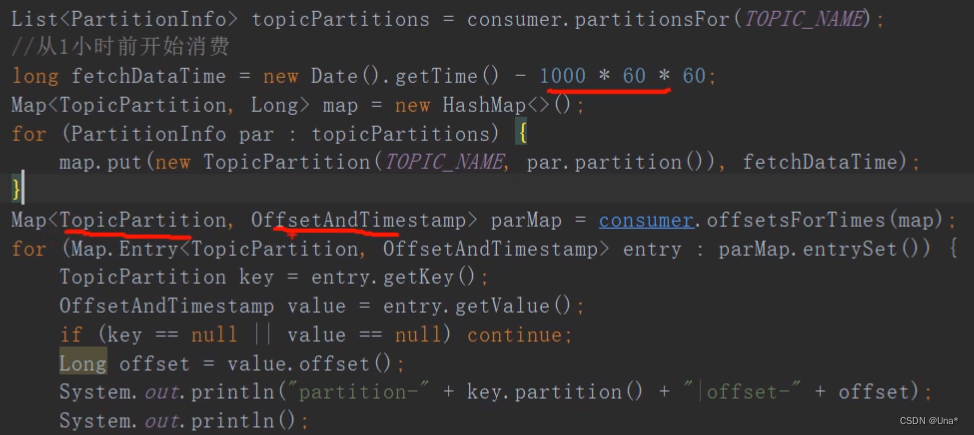
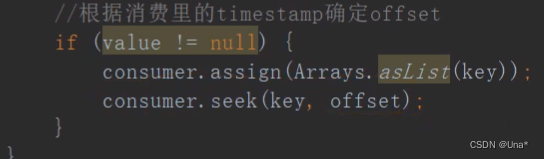
指定时间消费
从指定时间点开始消费
反序列化

offset
消费者需要提交offset给broker,但是一般不用自动提交,因为消费快了会重复消费,消费慢了挂掉会消费不到需要的数据。一般手动提交

心跳机制

消费能力

auto offset reset config
earliest:单次从头消费
latest:一般这个,每次都消费启动后的消息

手动同步提交offset(常用

手动异步提交offset
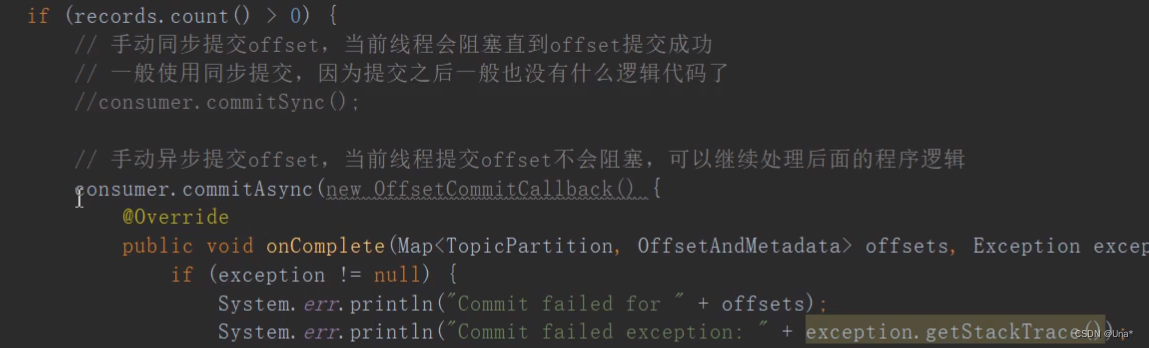
log,index,timeindex(稀疏索引)
kafka分segment存储log,有log文件,index文件,timeindex文件。
index存储对应的log文件的offset,以及pointer。查找时通过offset index二分查找得到pointer指向log文件里的位置数据。
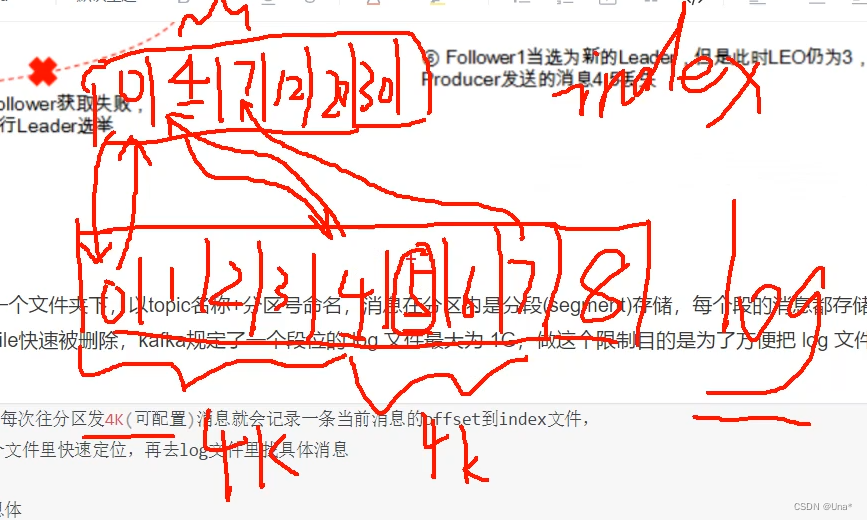
timeindex
存储的时间点和offset。通过时间二分查找到offset,再到index文件通过offset index查找到pointer。得到log 文件具体数据位置
spring boot整合
依赖包
spring-kafka
配置
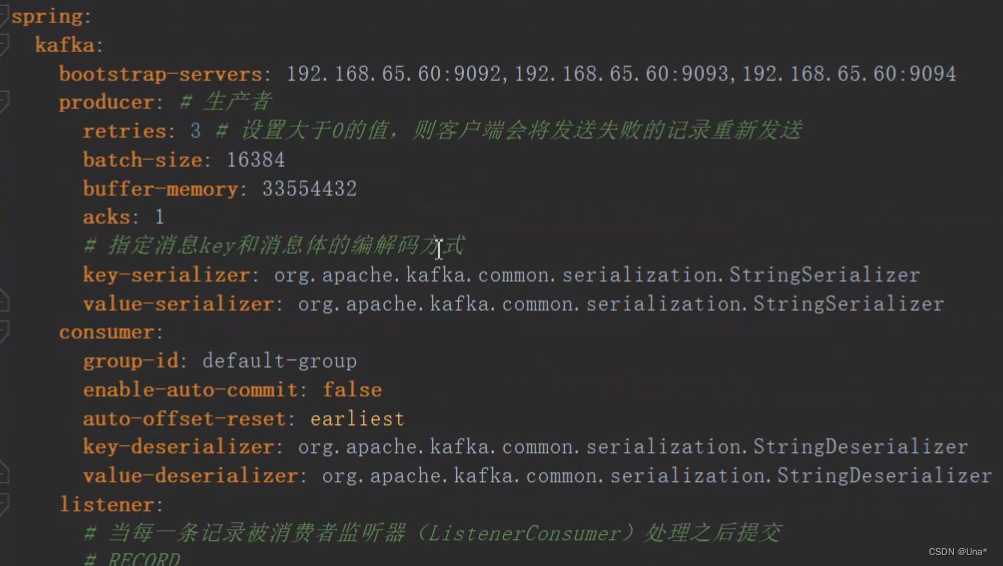
spring封装的操作模板类

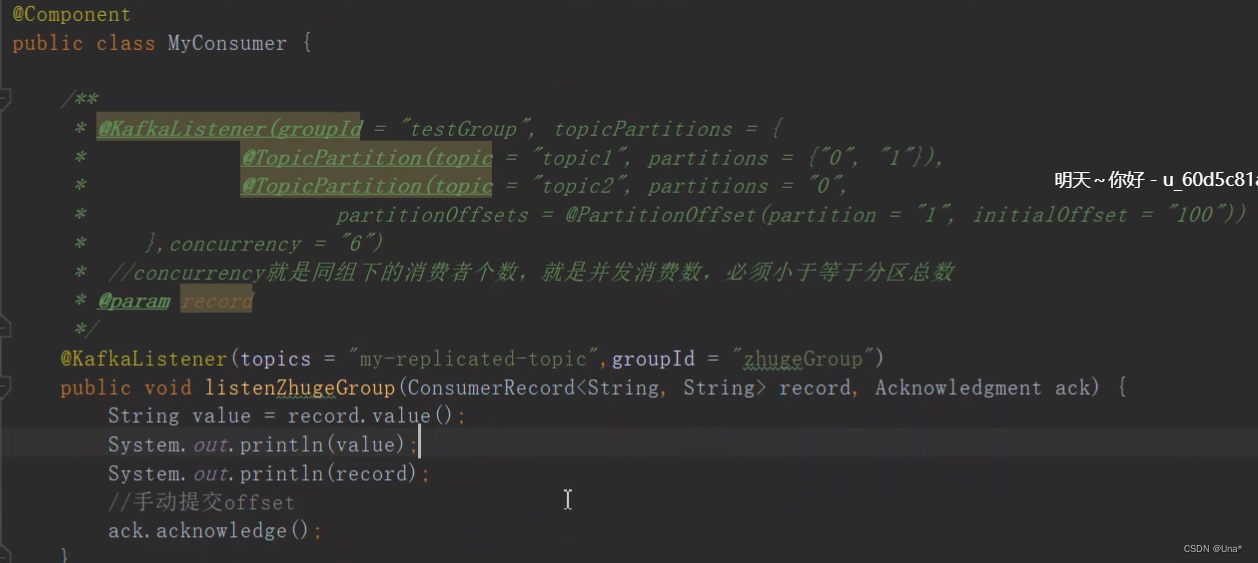
manual和batch比较常用

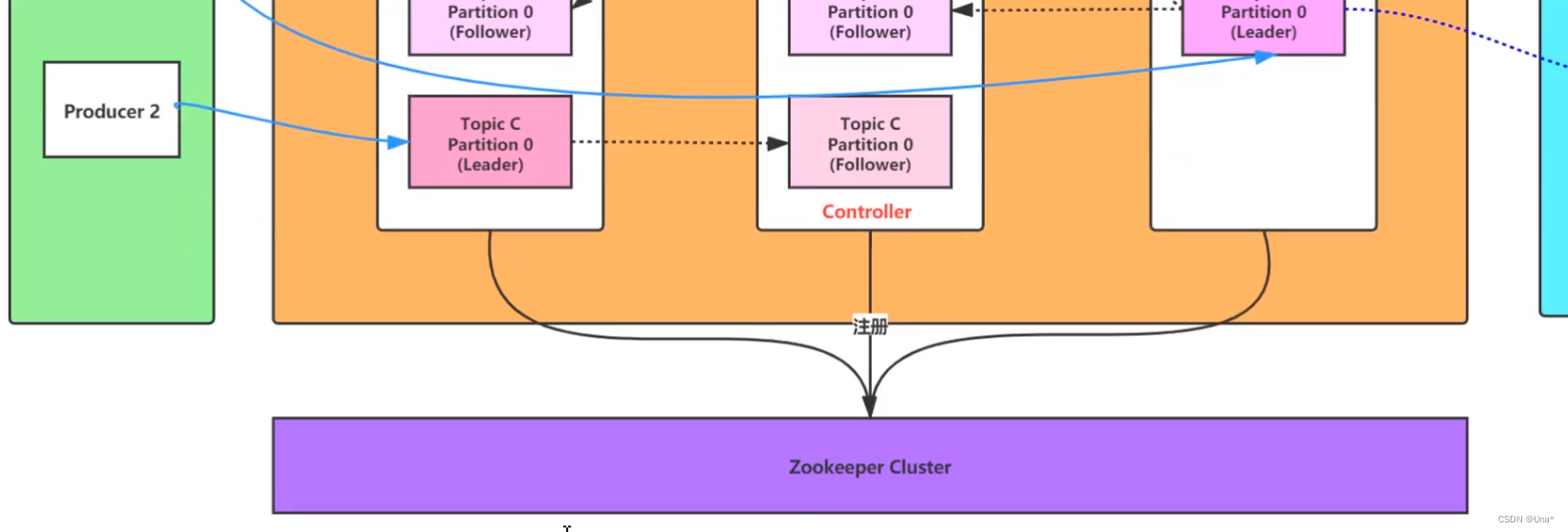
controller
kafka集群启动会选择一个broker作为controller管理整个集群,一般是按照先后顺序谁先启动谁就是,但是一般批量启动时都去zookeeper注册,去建立一个/controller临时节点,只能创建一个,所以谁先创建谁就是controller。如果挂掉了则会通过zk的watch机制(其他broker监听这个临时节点,发现临时节点消失了就会再次发起create -e controller)再次选举controller。
每个partition的leader也是controller控制的。
所以很多中间件借助zk来选举
controller监听/broker/ids(都是临时的,挂掉就会消失), /broker/topics
partition副本选举leader机制
借助controller选举
controller监听zk的/broker/ids,如果有broker挂了,就看该broker上的分区有哪些是leader将会对这些partition再次选举leader。从
Isr列表里(活着并且已经同步leader数据的)按照顺序选举leader。
消费者消费消息的offset记录机制
每个consumer会定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets,提交过去的时候,key是
consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的
那条数据
因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过
offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发
消费者rebalance机制
- 消费组里consumer增加减少
- 动态给topic增加partition
- 消费组订阅了更多的topic
rebalance过程该消费组不能消费消息,晚上做
分区分配策略
partition.assignment.strategy,默认range
range
按照分区序号排序,假设 n=分区数/消费者数量 = 3, m=分区数%消费者数量 = 1,那么前 m 个消费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区。
比如分区03给一个consumer,分区46给一个consumer,分区7~9给一个consumer
round-robin轮询分配
分区0、3、6、9给一个consumer,分区1、4、7给一个consumer,分区2、5、
8给一个consumer
sticky
初次分配和round-robin相似,rebalance时保持两原则
- 分区均匀
- 和上次尽量相同
比如对于第一种range情况的分配,如果第三个consumer挂了,那么重新用sticky策略分配的结果如下:
consumer1除了原有的0~3,会再分配一个7
consumer2除了原有的4~6,会再分配8和9
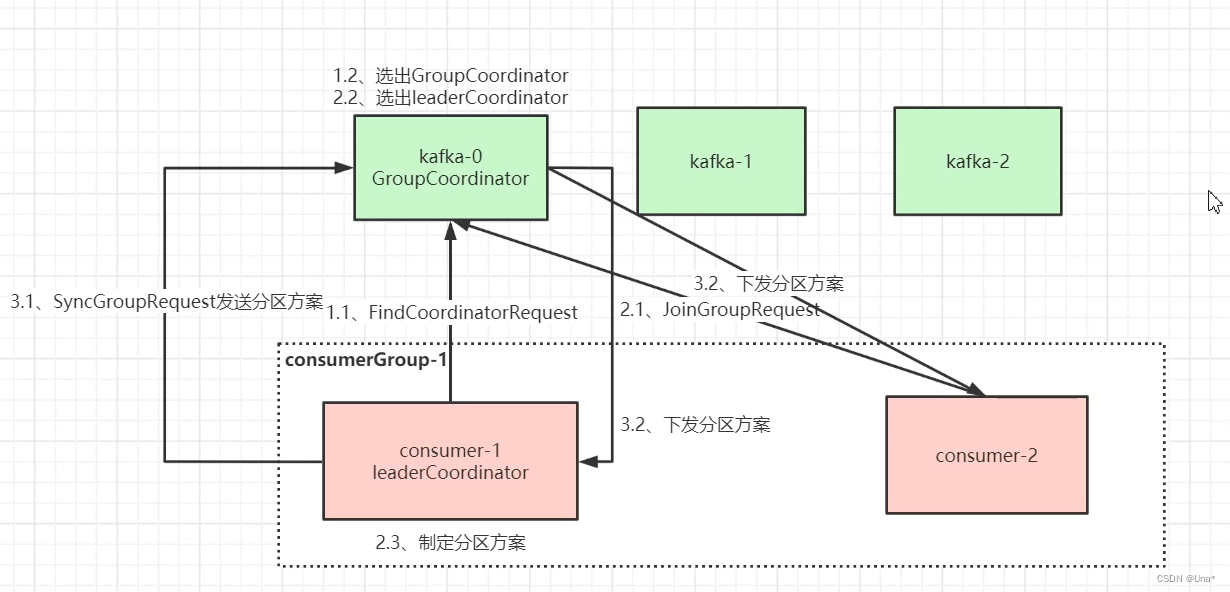
流程图
kafka和consumer两方都有个coordinator组长,由consumer方制定分区方案,告诉kafka,由kafka下发(通过心跳响应)。
高水位HW
HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,
此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broker的读取请求,没有HW的限制

Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率
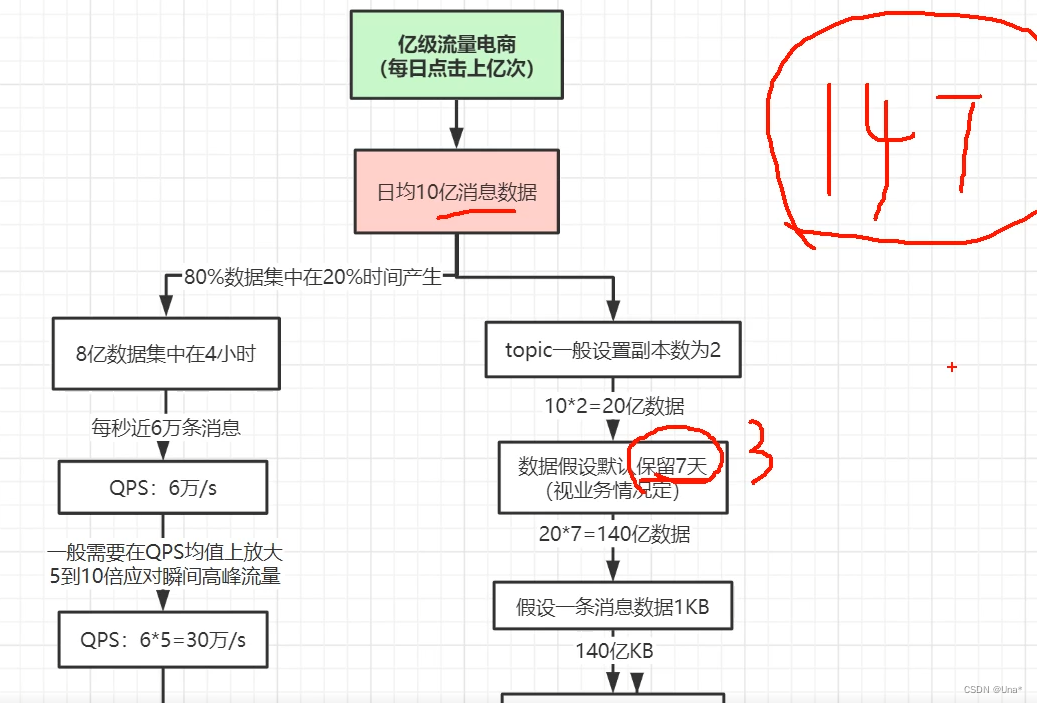
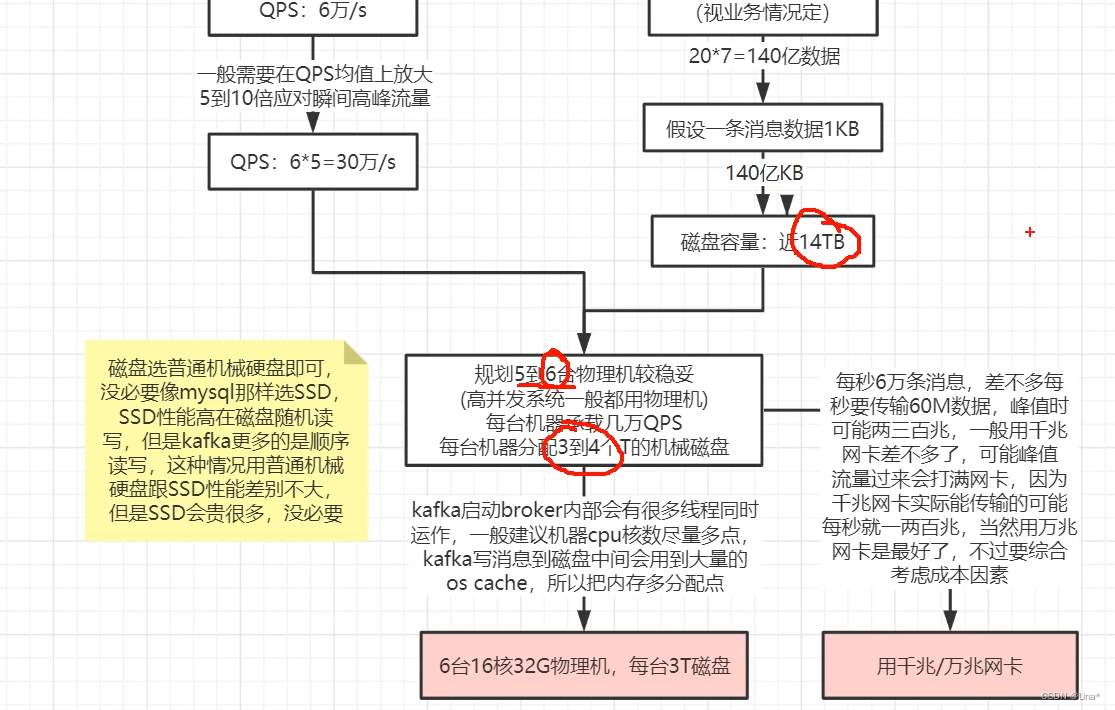
kafka线上容量规划