封面由 Microsoft Designer 生成
在五月份的 QCon 大会上,我们分享了《探索软件开发新工序:LLM 赋能研发效能提升》。在那次分享里,我们重点提及了团队并非所有的时间在 SDLC 上,可能只有 30%~50% 时间在开发软件上,甚至于有可能只有晚上才有时间写代码。所以,LLM 对于总结的提升是有限的,加之工具本身的缺乏,有可能导致带来的提升更有限。
随后,我们开始重新思考,并分析在不同的阶段的时间花费,体系化思考如何减少团队摩擦,进一步减少团队在这段时间的浪费。
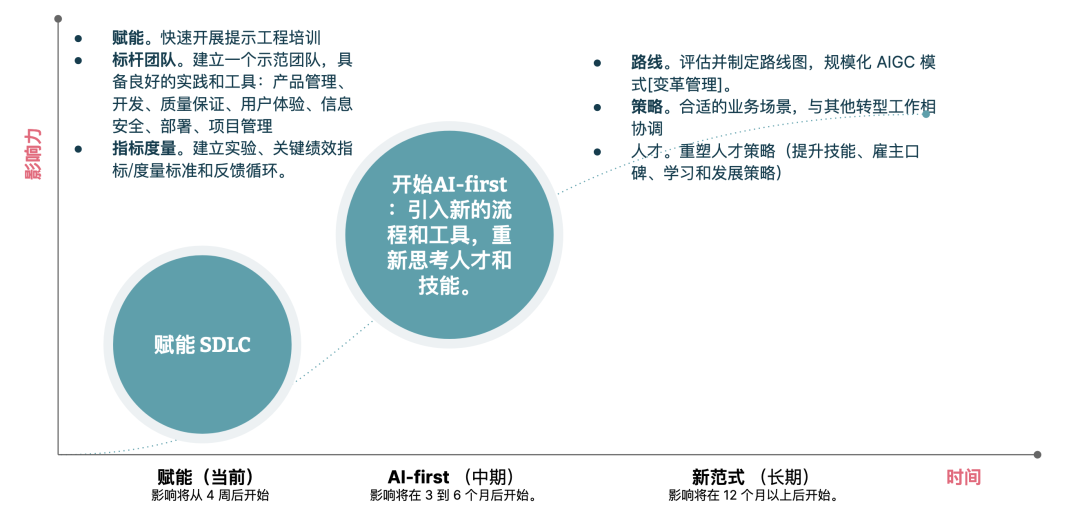
我们将此总结为 AI4SDLC 的第二个阶段,开始 AI-first:引入新的流程和工具,重新思考人才和技能。
开始之前:AIGC 并非银弹
AIGC 是无法直接成为跨团队的银弹,它只能改善现有的问题。而因为现阶段 AI 能力是有限的,人是不会听 AI 的,所以我们要先做发基本的心理预期建设。
当然,我们也可以结合 AIGC 一起改进现有流程与团队的这些问题。
我们应该优先关心 SDLC 的平台工程与流程
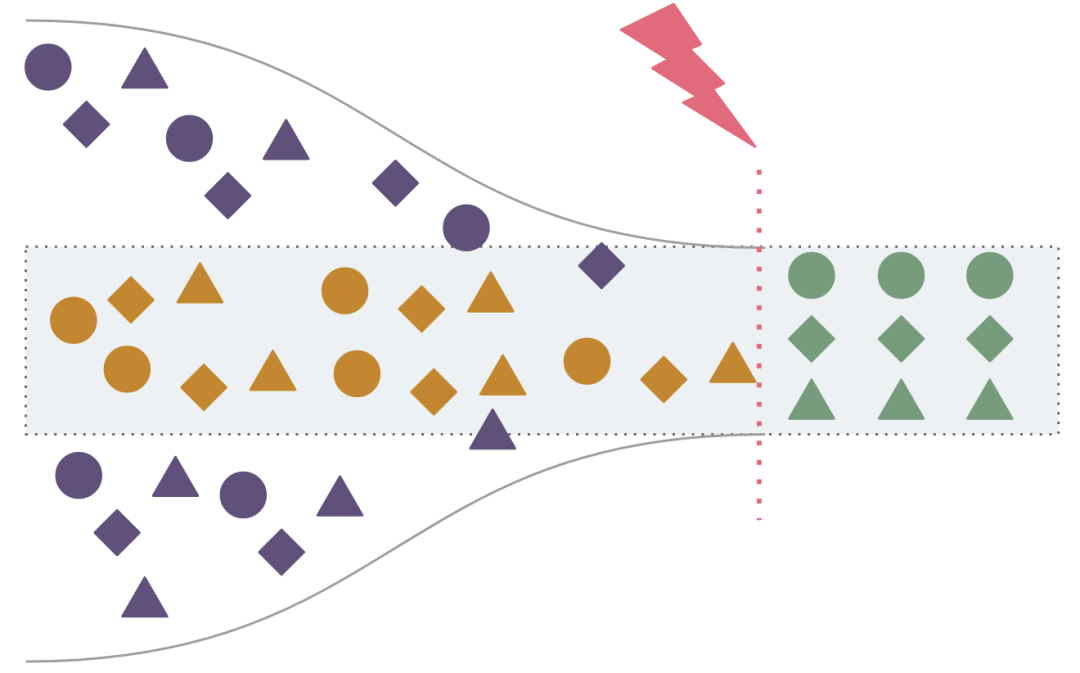
如果我们没有建设好 SDLC 相关的基础设施,那么就无法充分获得投资于 AI 2.0 所带来的全部价值。简单来说:AIGC 提效只是锦上添花,平台工程才是雪中送炭!
而随着更多代码的编写速度得到提升,拥有功能强大的自助式平台工程能力将变得至关重要。它可以快速构建、测试、部署和解决问题,以便充分利用生产力的提高。
我们的瓶颈可能会变成测试瓶颈、审批瓶颈、发布瓶颈等等。
我们还应该考虑组织结构与团队问题
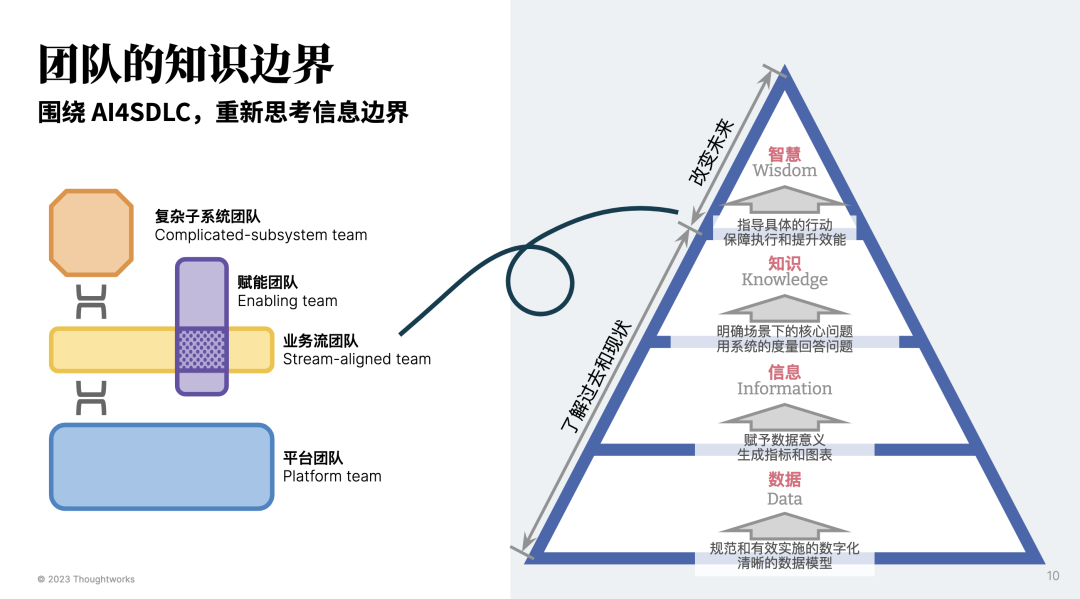
事实上,对于旧时代已经存在的团队与组织问题,《Team Topologies》(中文书名:《高效能团队模式》)一书已经给出了很好的总结 —— 软件边界大小匹配团队认知负荷。(团队认知负荷 ⇒ 团队成员在处理任务和信息时的认知压力和工作量)
为了减少团队成员额外的脑力开销,避免在 SDLC 以外的时间花费,我们可以:
提供团队优先的工作环境
缩减会议、减少邮件、专人答疑等减少打断团队
从文档、代码、API 等角度,改善开发者体验
设计专门为降低团队认识负载的平台
变革管理形态,沟通目标和产出而非观察过程
AIGC 可以帮助优化团队的认识负荷,但是能力是有限的。
我们还需要梳理软件研发中的常见阻碍

在进一步详细分析多个研发团队的日常活动,我们总结了如下的常见的阻碍生产力和阻断流程的摩擦点:
信息检索。诸如于:在找到正确的技术文档、知识文档花费大量的时间。
开发者体验障碍。诸如于:缺少合适的工具、有效的平台来辅助软件交付。
认知负载/任务切换。诸如于:团队经常在多个系统间切换,过大的团队。
质量反馈环滞后。诸如于:架构本身难以测试。
运营协作摩擦。诸如于:跨团队的摩擦、软件需求。
在这个更大的 topic 下,你会发现仅仅是引入编码工具,只能有限地提升开发者体验,对于总体的提升非常有限。在 AIGC 的能力之下,它们能帮助我们对简单、重复的任务进行最大的改进,而复杂任务,则收益不多。
LLM as Co-integrator:协同整合的 LLM

围绕上上述的五点研发阻碍,我们尝试用 AIGC 去解决其中的前四点问题。毕竟,运营协作的摩擦不是给了最优解能解决的。
构建多场景知识问答,降低知识检索成本
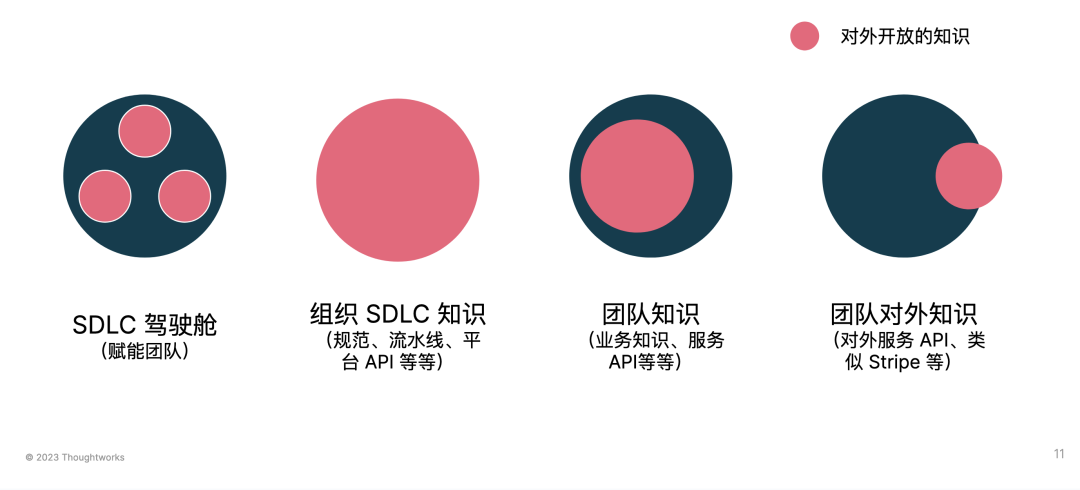
从 1 月份到现在,面向不同的使用场景(基于公开、非敏感信息),我们构建了一个个的知识检索:
TW Insights Bot(对外)。融合一系列对外 Thoughtworks 洞见文章的微调模型,以强化 AIGC 总结和介绍软件工程知识 AI。
ThoughtChat(对内)。面向 Thoughtworks 内部提供的知识问答助手,包含了大量的 Thoughtworks 最佳技术、业务实践材料。
面向特定领域的问答。根据不同的角色与业务领域,不同团队也包含了自身业务知识的知识问答。
而围绕于团队的拓扑结构,将将组织的团队类型划分为:复杂子系统团队、赋能团队、业务流团队、平台团队。再将其按各个团队的职责所在,将其重新分类,在软件开发领域,可以由下面的四个类型构成:
注意:这是从现有的混乱的 AI 局面所总结的,笔者相信在下一个阶段,它将会变成:“围绕数据权限 的知识问答“。
其中值得注意的是,在中大型组织里,都拥有一个很大的平台团队,对于这些平台团队来说,它们应该构建一个基于 LLM 的体系,以降低平台团队在支撑业务团队上的花费。诸如于 LangChain 文档、 Stripe 支付,都提供了类似的方式来降低使用框架的成本。
但是,值得注意的是:正如《平台工程中认知负荷的挑战》所引入的观点一样:“平台工程方式试图减轻开发团队的一些认知负荷,但这可能是以将认知负荷转移给平台团队为代价的。”
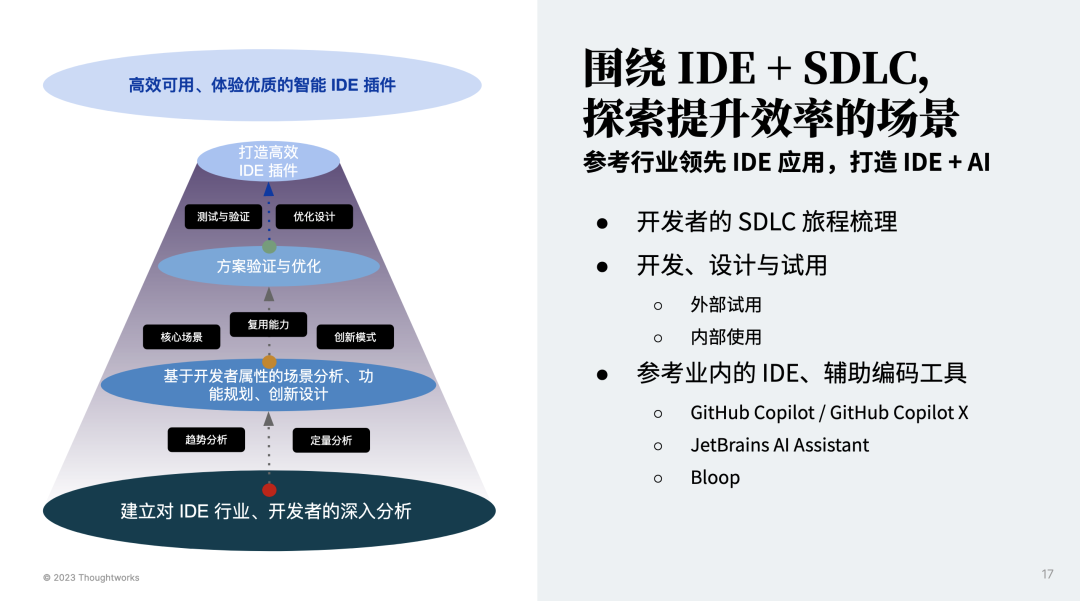
2. 端到端设计 AI 旅程,强化开发者体验
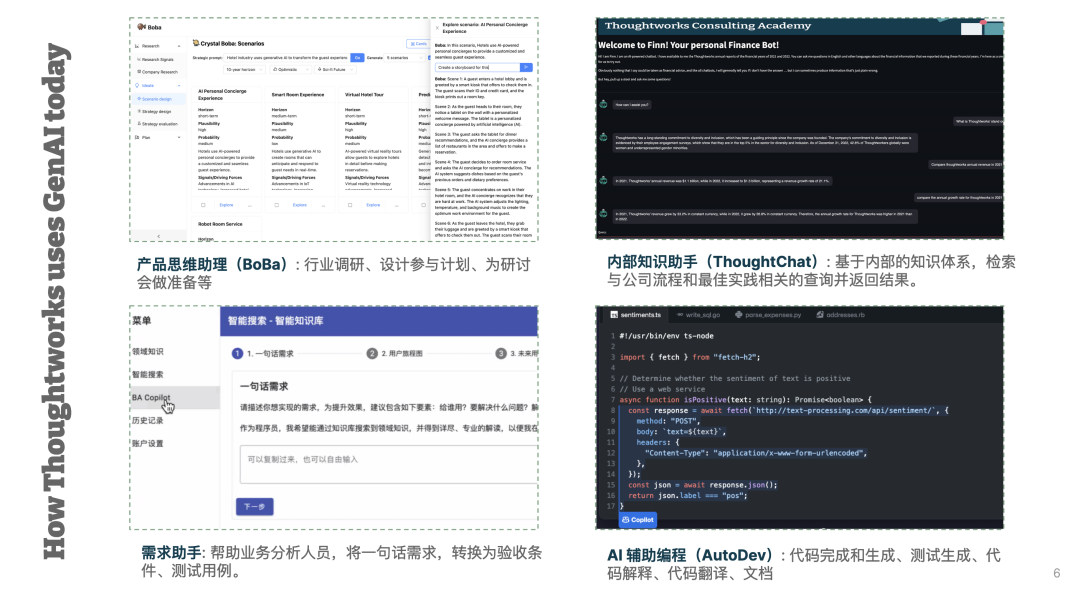
相似的,在 AIGC + SDLC 第一个阶段 LLM as Co-pilot 里,有大量的企业都开发了相关的辅助工具,在市面上,每天、每周、每月,我们都可以也看到了一系列的工具,从草图的生成到上线,再到部署平台的智能化。
在我们研究了一系列的工具之后,我们发现提供自定义能力是现阶段最需求的能力,下一个阶段则是端到端完整结合在一起。
我们也开发了一系列的工具,AI 产品助手 Boba、AI 辅助编程 AutoDev、智能需求助手等。虽然,我们还没有将这些工具端到端整合在一起。作为工具的第一个阶段,我们觉得它们依旧提供了非常好的实验示例,加速了团队的开发进度。
3. 设计团队 API,打造智能助理
在团队拓扑中,团队 API 包含了团队与其它任何交付的内容,诸如于代码、文档、工作信息、沟通工具等。
简单来说,当你负责的团队开发的是一个框架、平台时,你的团队成员有可能每天要面对一系列的信息轰炸。而有些简单的问题,可以直接由 AI 来代替人来完成,诸如上面提到的 Stripe 示例。而其实,多数情况,只是因为我们不希望:其它团队的人直接查看所有代码造成的。而,我们只要将由 LLM 来向量化这些信息,让它来帮助我们做一些处理即可。
因此,我们可以做事情是,将这些允许外部团队访问的文档、wiki、以及非敏感的代码,经过一些预处理,由交由 LLM 根据用户的输入来返回结果。
我们正在构建新的开源 LLM 工具 CoUnit,以帮助开发团队更好地进行团队内、跨团队的交互。
4. 强化质量工程,优化反馈速度
在需求阶段,我们会利用开发利用 LLM 的推理能力,快速写出高质量的测试用例、具备完善 AC 的需求文档。再结合现有的软件工程流程,AI 可以帮助我们进行测试设计、测试代码生成、测试问题解决、测试过程和结果分析,并对结果反馈分析。
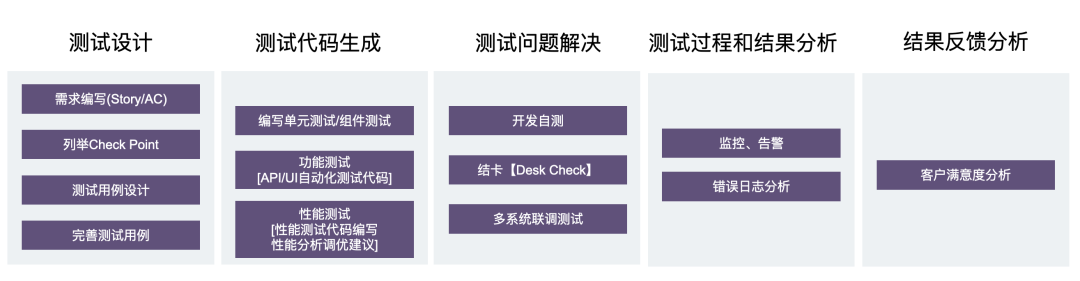
作为开发、测试沟通媒介的用例与文档,可以进一步借由 LLM 来改进质量工程。但是,我们依旧会遇到一个问题,复杂且脆弱的架构依旧是难以进行测试。
5. AI 降低运营协作摩擦
就现阶段而言,现有的 AI 能力并不足以解决团队间摩擦问题。
总结
由 ChatGPT 来帮助我们总结:
不要只顾着对AI抱太大期望,毕竟它的能力还有限,有时候比个拧螺丝还费劲。重要的是,得先整顿好自己的房子,也就是SDLC平台工程,才能真正让AI展示其魔法。
团队问题也是个大头。别让团队变成混乱的交通堵塞,把信息搞得像迷宫一样难找。就像是个会颠来倒去的拖拉机,让团队走得不累才是关键。
总之,要让AI成为你的超级助手,得先让自己的基础做得扎实,别让AI成了一只徒有其表的机器人。想让开发更轻松,就得让AI成为团队的好朋友,而不是个让你头疼的问题。
参考资料:
《高效能团队模式:支持软件快速交付的组织架构》
《平台工程中认知负荷的挑战》
《Stripe and OpenAI collaborate to monetize OpenAI’s flagship products and enhance Stripe with GPT-4》
《团队拓扑:在云原生时代,如何定位自身与团队?》