【Pytroch】基于决策树算法的数据分类预测(Excel可直接替换数据)
- 1.模型原理
- 2.数学公式
- 3.文件结构
- 4.Excel数据
- 5.下载地址
- 6.完整代码
- 7.运行结果
1.模型原理
决策树是一种常用的机器学习算法,用于分类和回归任务。它通过树状结构表示数据的决策过程,将数据集划分为不同的子集,并在每个子集上进行决策。决策树分类的原理可以概括如下:
-
特征选择: 决策树的分类过程始于根节点,根据某个特征将数据集划分为不同的子集。选择哪个特征用来进行划分是决策树算法的关键之一。常见的特征选择标准包括信息增益、基尼不纯度、方差等。信息增益表示划分前后熵的差异,基尼不纯度测量随机选择两个样本,其类别不一致的概率。
-
递归划分: 一旦选择了划分特征,数据集就会被分为多个子集,每个子集对应于划分特征的不同取值。对每个子集,都会重复进行相同的特征选择和划分过程,直到满足终止条件。终止条件可能包括以下情况:
- 所有数据点属于同一类别。
- 到达了事先设定的树的深度。
- 某个节点上的数据点数目低于某个阈值。
-
叶节点分类: 当达到终止条件时,形成了决策树的叶节点。每个叶节点对应于一个分类标签,即决策树预测的输出。该标签可以是子集中样本最常见的标签,或者由其他方法确定。
-
预测: 对于新的未见样本,决策树通过从根节点开始,根据特征值依次沿着树的分支进行遍历,直到到达叶节点。在叶节点上的标签即为预测的类别。
-
剪枝(可选): 构建决策树时,可能会出现过拟合问题,即模型在训练数据上表现良好,但在新数据上表现较差。为了避免过拟合,可以进行剪枝操作,即通过移除某些分支来简化树的结构。
决策树的优点包括易于理解和解释、可处理数值型和分类型数据、能够处理缺失值等。然而,它也存在一些局限性,如容易过拟合、对数据的小变化敏感等。为了应对这些问题,通常会使用集成方法(如随机森林和梯度提升树)来进一步提升决策树的性能。
总的来说,决策树分类是一种基于树状结构的机器学习方法,通过特征选择和递归划分,将数据映射到不同的类别。其简单性和可解释性使其成为许多机器学习问题的有力工具。
2.数学公式
当涉及决策树算法的数学公式时,我们主要关注以下几个方面:信息增益、基尼不纯度以及决策树的构建和预测过程。
-
信息增益(Information Gain): 信息增益用于衡量特征选择的好坏,它表示在给定特征下,数据集的不确定性减少了多少。信息增益越大,意味着使用该特征进行划分可以获得更多的信息。
信息增益 = 划分前的熵 − 加权划分后的熵 \text{信息增益} = \text{划分前的熵} - \text{加权划分后的熵} 信息增益=划分前的熵−加权划分后的熵
划分前的熵:
H ( D ) = − ∑ i = 1 c p i log 2 ( p i ) H(D) = - \sum_{i=1}^{c} p_i \log_2(p_i) H(D)=−i=1∑cpilog2(pi)
划分后的加权熵:
H ( D ∣ A ) = ∑ i = 1 v ∣ D i ∣ ∣ D ∣ ⋅ H ( D i ) H(D|A) = \sum_{i=1}^{v} \frac{|D_i|}{|D|} \cdot H(D_i) H(D∣A)=i=1∑v∣D∣∣Di∣⋅H(Di)
其中, H ( D ) H(D) H(D) 是数据集的熵, p i p_i pi 是数据集中类别 i i i 的概率, H ( D ∣ A ) H(D|A) H(D∣A) 是在特征 A A A 下的条件熵, v v v 是特征 A A A 的取值数量, ∣ D i ∣ |D_i| ∣Di∣ 是属于取值 i i i 的样本数量。
-
基尼不纯度(Gini Impurity): 基尼不纯度用于衡量在数据集中随机选择两个样本,其类别不一致的概率。
基尼不纯度 = 1 − ∑ i = 1 c p i 2 \text{基尼不纯度} = 1 - \sum_{i=1}^{c} p_i^2 基尼不纯度=1−i=1∑cpi2
其中, p i p_i pi 是数据集中类别 i i i 的概率。
-
决策树的构建过程: 决策树的构建过程基于递归,以下是一个简化的伪代码表示:
function BuildDecisionTree(data, target, features): if all samples in target belong to the same class: return a leaf node with the class label if features is empty: return a leaf node with the most common class label in target choose the best feature based on information gain or Gini impurity create a decision node for the best feature for each unique value v of the best feature: create a branch from the decision node for value v recursively call BuildDecisionTree with subset data, target, and updated features return the decision node decision_tree = BuildDecisionTree(training_data, training_target, all_features) -
决策树的预测过程: 决策树的预测过程通过从根节点开始沿着树的分支进行遍历,直到到达叶节点为止。
function PredictSample(tree, sample): if tree is a leaf node: return the class label of the leaf node else: get the feature value from the sample if the value leads to a known branch: recursively call PredictSample on the branch else: return the most common class label among the leaf nodes' labels
这些数学公式和伪代码描述了决策树分类的核心原理,涉及到特征选择、信息增益、基尼不纯度以及决策树的构建和预测过程。实际实现中,可能还会涉及到剪枝等细节,但以上内容已经涵盖了决策树分类的基本原理。
3.文件结构

iris.xlsx % 可替换数据集
Main.py % 主函数
4.Excel数据

5.下载地址
- 资源下载地址
6.完整代码
import torch
import pandas as pd
from sklearn.model_selection import train_test_split # Add this line
import numpy as np
import matplotlib.pyplot as plt
class DecisionTreeNode:
def __init__(self, feature_index=None, label=None):
self.feature_index = feature_index # 特征索引
self.label = label # 叶节点标签
self.children = {} # 子节点字典
def entropy(labels):
_, counts = torch.unique(labels, return_counts=True)
probabilities = counts.float() / len(labels)
return torch.sum(-probabilities * torch.log2(probabilities))
def information_gain(data, feature_index, target):
feature_values = data[:, feature_index]
unique_values = torch.unique(feature_values)
total_entropy = entropy(target)
weighted_entropy = 0.0
for value in unique_values:
mask = feature_values == value
subset_target = target[mask]
subset_entropy = entropy(subset_target)
weighted_entropy += (len(subset_target) / len(target)) * subset_entropy
return total_entropy - weighted_entropy
def build_decision_tree(data, target, features, max_depth=None, min_samples_split=2, current_depth=0):
# 若样本中所有标签相同,则返回叶节点
if torch.unique(target).size(0) == 1:
return DecisionTreeNode(label=target[0].item())
# 若达到最大深度或样本数不足以继续划分,则返回叶节点,将标签设为样本中最常见的标签
if current_depth == max_depth or len(target) < min_samples_split:
label = torch.mode(target).values.item()
return DecisionTreeNode(label=label)
# 若没有特征可用,则返回叶节点,将标签设为样本中最常见的标签
if features.size(0) == 0:
label = torch.mode(target).values.item()
return DecisionTreeNode(label=label)
best_feature_index = None
best_info_gain = -1.0
for feature_index in range(features.size(0)):
info_gain = information_gain(data, feature_index, target)
if info_gain > best_info_gain:
best_info_gain = info_gain
best_feature_index = feature_index
if best_info_gain == 0:
label = torch.mode(target).values.item()
return DecisionTreeNode(label=label)
best_feature = features[best_feature_index]
decision_tree = DecisionTreeNode(feature_index=best_feature_index)
unique_values = torch.unique(data[:, best_feature_index])
for value in unique_values:
mask = data[:, best_feature_index] == value
subset_data = data[mask]
subset_target = target[mask]
subset_features = features[features != best_feature]
decision_tree.children[value.item()] = build_decision_tree(subset_data, subset_target, subset_features, max_depth, min_samples_split, current_depth + 1)
return decision_tree
def predict_sample(tree, sample):
if tree.label is not None:
return tree.label
feature_value = sample[tree.feature_index]
if feature_value in tree.children:
return predict_sample(tree.children[feature_value], sample)
else:
# 若在训练时未见过该特征值,则返回叶节点中最常见的标签
labels = [child.label for child in tree.children.values()]
return max(set(labels), key=labels.count)
def predict(tree, data):
predictions = []
for sample in data:
prediction = predict_sample(tree, sample)
predictions.append(prediction)
return torch.tensor(predictions)
def accuracy(y_true, y_pred):
return torch.sum(y_true == y_pred).item() / len(y_true)
def plot_confusion_matrix(conf_matrix, classes):
plt.figure(figsize=(8, 6))
plt.imshow(conf_matrix, cmap=plt.cm.Blues, interpolation='nearest')
plt.title("Confusion Matrix")
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes)
plt.yticks(tick_marks, classes)
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.tight_layout()
plt.show()
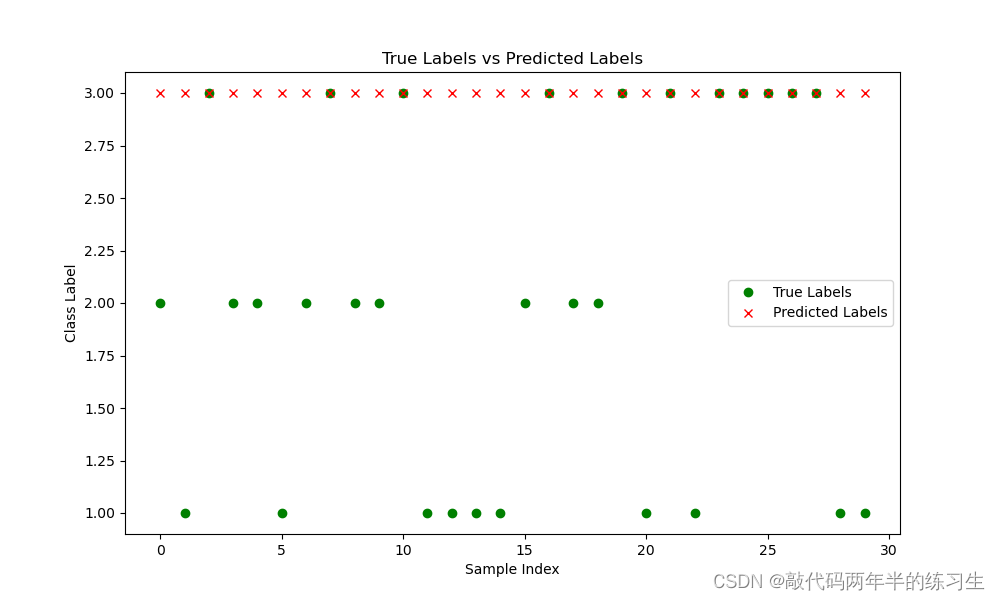
def plot_predictions_vs_true(y_true, y_pred):
plt.figure(figsize=(10, 6))
plt.plot(y_true, 'go', label='True Labels')
plt.plot(y_pred, 'rx', label='Predicted Labels')
plt.title("True Labels vs Predicted Labels")
plt.xlabel("Sample Index")
plt.ylabel("Class Label")
plt.legend()
plt.show()
def main():
# 读取Data.xlsx文件并加载数据
data = pd.read_excel("iris.xlsx")
# 划分特征值和标签
features = torch.tensor(data.iloc[:, :-1].values, dtype=torch.float32)
labels = torch.tensor(data.iloc[:, -1].values, dtype=torch.long)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# 构建决策树
# 构建决策树,限制最大深度为5,叶节点至少包含5个样本
decision_tree = build_decision_tree(X_train, y_train, torch.arange(X_train.size(1)), max_depth=5,
min_samples_split=5)
# 进行预测
y_pred = predict(decision_tree, X_test)
# 计算准确率
acc = accuracy(y_test, y_pred)
print("模型的准确率:", acc)
# 绘制混淆矩阵
from sklearn.metrics import confusion_matrix
conf_matrix = confusion_matrix(y_test, y_pred)
classes = ['class_0', 'class_1', 'class_2']
plot_confusion_matrix(conf_matrix, classes)
# 绘制真实标签与预测标签对比图
plot_predictions_vs_true(y_test, y_pred)
if __name__ == "__main__":
main()
7.运行结果