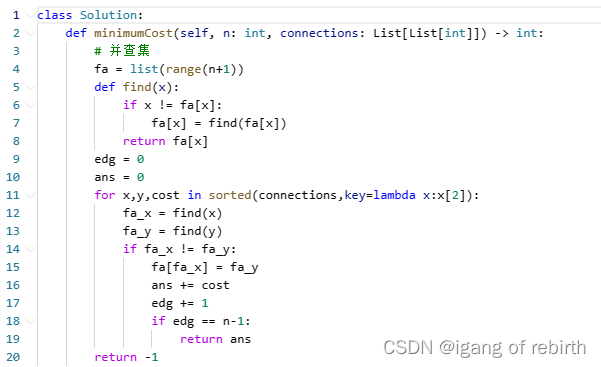
目录
- 前言
- 1. 生产者消费者模式
- 2. 问答环节
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 高级-future、promise、condition_variable
课程大纲可看下面的思维导图

1. 生产者消费者模式
这节我们继续学习多线程知识
在深度学习模型部署中,我们通常采用生产者消费者模型对算法进行包装,然后交给其他团队使用
所以我们有必要对生产者消费者模型进行学习和了解,在这里我们拿一个具体问题来分析,即队列溢出问题,生产太快,消费太慢。如何实现溢出限制?生产者如何拿到消费反馈?
接下来我们来看代码,我们先写一个最简单版本的消费者和生产者模式,代码如下所示:
#include <thread>
#include <queue>
#include <mutex>
#include <string>
#include <stdio.h>
#include <chrono>
using namespace std;
queue<string> qjobs_;
void video_capture(){
int img_id = 0;
while(true){
char name[100];
sprintf(name, "PIC-%d", img_id++);
printf("生产了一个新图片: %s\n", name);
qjobs_.push(name);
this_thread::sleep_for(chrono::milliseconds(1000));
}
}
void infer_worker(){
while(true){
if(!qjobs_.empty()){
auto img = qjobs_.front();
qjobs_.pop();
printf("消费掉一个图片: %s\n", img.c_str());
this_thread::sleep_for(chrono::milliseconds(1000));
}
this_thread::yield();
}
}
int main(){
thread t0(video_capture);
thread t1(infer_worker);
t0.join();
t1.join();
return 0;
}
这段代码展示了一个简单的生产者-消费者模式的示例,模拟了模型推理过程中的数据生产和消费过程。下面是对代码的详细分析:
1. queue<string> qjobs_;:定义了一个队列,用于存储生产者生成的图片任务。
2. void video_capture():这是生产者线程函数,模拟图片的采集过程。在一个无限循环中,不断生成新的图片名,并将图片名压入队列 qjobs_ 中,表示生成了一个新的图片任务。每个图片任务之间通过 this_thread::sleep_for 函数模拟间隔一秒的采集时间。
3. void infer_worker():这是消费者线程函数,模拟模型的推理过程。在一个无限循环中,不断检查队列 qjobs_ 是否为空,如果不为空,则从队列中取出一个图片任务,表示消费了一个图片。每个图片任务之间通过 this_thread::sleep_for 函数模拟模型推理的耗时过程,这里设置为一秒。
4. int main():在 main 函数中,通过创建两个线程 t0 和 t1 分别启动生产者线程video_capture和消费者线程infer_worker。
t0.join();和t1.join();:在main函数中,使用join函数等待两个线程的完成,这样保证了主线程等待生产者和消费者线程都完成后再退出。
上述代码模拟了生产者-消费者模式的应用场景,其中生产者线程负责不断生成新的图片任务,将其放入队列中,而消费者线程则负责从队列中获取图片任务并进行处理。通过这种方式,使得图片采集和模型推理过程可以并行进行,提高了系统的吞吐量和效率。
执行效果如下:

可以看到确实是生产一个消费一个,这时候就引入了第一个问题:共享资源访问问题
由于 STL 中的 queue 对象不是线程安全,因此要对其资源访问加上🔒,这是我们日常会遇到的问题,现在由于是 1s 一次,没有问题,但是当频次高时势必会崩溃,所以一定要加🔒,修改后的代码如下:
#include <thread>
#include <queue>
#include <mutex>
#include <string>
#include <stdio.h>
#include <chrono>
using namespace std;
queue<string> qjobs_;
mutex lock_;
void video_capture(){
int img_id = 0;
while(true){
{
lock_guard<mutex> l(lock_);
char name[100];
sprintf(name, "PIC-%d", img_id++);
printf("生产了一个新图片: %s\n", name);
qjobs_.push(name);
}
this_thread::sleep_for(chrono::milliseconds(1000));
}
}
void infer_worker(){
while(true){
if(!qjobs_.empty()){
{
lock_guard<mutex> l(lock_);
auto img = qjobs_.front();
qjobs_.pop();
printf("消费掉一个图片: %s\n", img.c_str());
}
this_thread::sleep_for(chrono::milliseconds(1000));
}
this_thread::yield();
}
}
int main(){
thread t0(video_capture);
thread t1(infer_worker);
t0.join();
t1.join();
return 0;
}
上述代码中使用的锁是 std::mutex,它是一个互斥锁。当一个线程获得这个锁时,其他所有线程都必须等待直到锁被释放。
lock_guard 是一个辅助对象,它在构造时自动锁定给定的互斥量,并在析构时自动解锁。这意味着,当控制流离开lock_guard 的作用域时,锁会被自动释放,无论是正常离开还是因为异常。
在代码中:
- 在 video_capture 函数中,您在向队列添加元素之前锁定了 lock_。这确保了在添加元素时,没有其他线程(如 infer_worker 线程)可以同时访问队列。
- 在 infer_worker 函数中,您首先检查队列是否为空,然后再次锁定 lock_ 以从队列中取出并处理元素。这确保了在消费队列中的元素时,video_capture 线程不会同时向队列中添加新元素。
这种加锁策略确保了队列的完整性和数据的一致性。
这个时候程序就是一个线程安全的操作了,这个时候就没有资源冲突问题了,
我们来看第二个问题:队列溢出问题,即生产太快,消费太慢
我们将生产时间修改为 0.5s, 消费时间不变,修改后的代码如下:
#include <thread>
#include <queue>
#include <mutex>
#include <string>
#include <stdio.h>
#include <chrono>
using namespace std;
queue<string> qjobs_;
mutex lock_;
void video_capture(){
int img_id = 0;
while(true){
{
lock_guard<mutex> l(lock_);
char name[100];
sprintf(name, "PIC-%d", img_id++);
printf("生产了一个新图片: %s, qjobs_.size = %d\n", name, qjobs_.size());
qjobs_.push(name);
}
this_thread::sleep_for(chrono::milliseconds(500));
}
}
void infer_worker(){
while(true){
if(!qjobs_.empty()){
{
lock_guard<mutex> l(lock_);
auto img = qjobs_.front();
qjobs_.pop();
printf("消费掉一个图片: %s\n", img.c_str());
}
this_thread::sleep_for(chrono::milliseconds(1000));
}
this_thread::yield();
}
}
int main(){
thread t0(video_capture);
thread t1(infer_worker);
t0.join();
t1.join();
return 0;
}
执行效果如下:

可以看到如果生产频率高于消费频率,则队列出现堆积现象,在目前场景,队列中是 string,所以堆积无所谓,但是在实际工作中队列中往往是一张图片,图片本身内存大,而程序需要长期运行,当显存/内存消耗殆尽时,程序会崩溃。
我们该如何实现溢出限制呢?其实就是设置一个上限,当队列中的数据达到一定上限时就不要再生产了,等着就行
我们要解决这个问题,需要引入一个新的知识点,即 condition_variable,
我们要实现的效果是如果队列满了,我不生产,我去等待队列有空间再生产,如下面的伪代码所示:
if(qjobs_.size() > limit)
wait();
我们还要考虑一件事,就是 wait 等待没问题,但是当队列中可再生产时你得告诉我,也就是通知的问题,如何通知到 wait,让它即时的可以退出
想要达到上述效果,可以使用 condition_variable 很优雅的做到这个事情
代码如下:
#include <thread>
#include <queue>
#include <mutex>
#include <string>
#include <stdio.h>
#include <chrono>
#include <condition_variable>
using namespace std;
queue<string> qjobs_;
mutex lock_;
condition_variable cv_;
const int limit_ = 5;
void video_capture(){
int img_id = 0;
while(true){
{
unique_lock<mutex> l(lock_);
char name[100];
sprintf(name, "PIC-%d", img_id++);
printf("生产了一个新图片: %s, qjobs_.size = %d\n", name, qjobs_.size());
cv_.wait(l, [](){
// return false,表示继续等待
// return true,表示不等待,跳出wait
return qjobs_.size() < limit_;
});
// 如果队列满了,我不生产,我去等待队列有空间再生产
// 通知的问题,如何通知到 wait,让它即时的可以退出
qjobs_.push(name);
}
this_thread::sleep_for(chrono::milliseconds(500));
}
}
void infer_worker(){
while(true){
if(!qjobs_.empty()){
{
lock_guard<mutex> l(lock_);
auto img = qjobs_.front();
qjobs_.pop();
// 消费掉一个,就可以通知 wait,去跳出等待
cv_.notify_one();
printf("消费掉一个图片: %s\n", img.c_str());
}
this_thread::sleep_for(chrono::milliseconds(1000));
}
this_thread::yield();
}
}
int main(){
thread t0(video_capture);
thread t1(infer_worker);
t0.join();
t1.join();
return 0;
}
在我们的代码使用了条件变量(std::condition_variable)来同步生产者和消费者,以确保队列的大小不超过给定的限制。当生产者试图添加到队列时,如果队列已满,它会等待直到消费者从队列中取出一张图片。
首先我们声明了一个条件变量 cv_ 和一个常量 limit_,表示队列的最大大小
然后在生产者线程中,使用了 cv_.wait() 方法。这个方法会阻塞当前线程直到满足给定的条件。
cv_.wait() 接受两个参数:
- l 是一个 unique_lock,它用于保护条件变量和相关资源(在这种情况下是队列 qjobs_)。
- Lambda 函数作为条件,当此函数返回 true 时,wait() 会返回并允许线程继续执行。如果条件不满足(返回 false),wait() 会自动释放锁并阻塞当前线程,直到条件变量被通知。
在代码中,条件检查队列的大小是否小于 limit_。如果队列已满(qjobs_.size() >= limit),生产者线程会被阻塞直到队列中有空间。
最后在消费者线程中,每次从队列中取出一张图片后,都会调用 cv_.notify_one()。这会唤醒一个(如果有的话)等待在条件变量上的线程。在这种情况下,它会唤醒生产者线程,如果生产者线程因为队列已满而被阻塞的话。
执行效果如下:

可以看到当队列中的数据等于 5 时,消费者和生产者达到了同频,达到了我们的预期
需要注意的是,wait 的流程是,一旦进入 wait 则解锁,一旦退出 wait 则加锁
这个问题解决了之后,我们来看下个问题:生产者如何拿到消费者的反馈
什么意思呢?就是说我消费者在拿到图片时是对图片做了处理的,比如说进行了模型推理,那拿到的推理结果我该如何送到生产者线程中呢?
那你可能会想,为什么要把它送回到生产者中去呢?送回去的意义是什么?
因为这符合我们实际的开发,正常来说 video_capture 把图片给消费者线程进行推理,我们希望拿到推理的结果,然后跟推理之前的图像一起进行画框,然后走下面的流程
那你可以又有疑问?为什么需要先把图片给消费者线程推理,然后把结果送回来去画框,这不多此一举吗?为什么不直接把模型推理一起放在生产者线程呢?
因为通常来说我们有多个模型,infer_worker 有多个,比如目标检测、目标分割、人脸检测、人脸识别等等,所以你会发现你有多个消费者,意味着你有多个队列,但是你又希望程序性能尽可能的好,如果你全部放在 video_capture 一个个去做的话,你会发现这个模式是串行的,性能很差,是同步模式。而如果你按照前面的做法则是异步模式,如下所示:
// 同步模式
// detection -> infer
// face -> infer
// feature -> infer
// 异步模式
// detection -> push
// face -> push
// feature -> push
同步模式下你要一个个模型推理,而异步模式下你只需要将图片一个个 push 就行,异步模式的优点在于你可以一次进行 3 个结果的回收,然后进行处理。同步模式还有个缺点,就是它对一个线程的负担很大,使得这个线程很"重",当需要调用你这个线程/算法时,由于你这个线程太"重"了,会使得它的性能比较差,使得每个操作都非常"重",因为你的线程上下文是需要初始化的,线程里面有很多内容是需要分配资源的。
因此如果说我调用的逻辑和推理的逻辑不在一个线程里面,就会使得我的调用非常的轻便,性能非常的好,接口也更简单,因此我们比较推荐第二种模式,即异步模式,也是我们后面高性能的保证,它是一个基础
废话少说,我们来看怎么把我们的结果从消费者线程返回到生产者线程,这个时候我们就引入下一个概念,即 future、promise
代码如下:
#include <thread>
#include <queue>
#include <mutex>
#include <string>
#include <stdio.h>
#include <chrono>
#include <condition_variable>
#include <memory>
#include <future>
using namespace std;
struct Job{
shared_ptr<promise<string>> pro;
string input;
};
queue<Job> qjobs_;
mutex lock_;
condition_variable cv_;
const int limit_ = 5;
void video_capture(){
int img_id = 0;
while(true){
Job job;
{
unique_lock<mutex> l(lock_);
char name[100];
sprintf(name, "PIC-%d", img_id++);
printf("生产了一个新图片: %s\n", name);
cv_.wait(l, [](){
// return false,表示继续等待
// return true,表示不等待,跳出wait
return qjobs_.size() < limit_;
});
// 如果队列满了,我不生产,我去等待队列有空间再生产
// 通知的问题,如何通知到 wait,让它即时的可以退出
job.pro.reset(new promise<string>());
job.input = name;
qjobs_.push(job);
// 等待这个 job 处理完毕,拿结果
// job.pro->get_future() 返回的其实是 future 对象
// .get 过后,实现等待,直到 promise->set_value 被执行了,这里的返回值就是 result
// 拿到推理结果,跟推理之前的图像一起进行画框,然后走下面的流程
}
auto result = job.pro->get_future().get();
printf("Job %s -> %s\n", job.input.c_str(), result.c_str());
this_thread::sleep_for(chrono::milliseconds(500));
}
}
void infer_worker(){
while(true){
if(!qjobs_.empty()){
{
lock_guard<mutex> l(lock_);
auto pjob = qjobs_.front();
qjobs_.pop();
// 消费掉一个,就可以通知 wait,去跳出等待
cv_.notify_one();
printf("消费掉一个图片: %s\n", pjob.input.c_str());
auto result = pjob.input + " --- infer";
// new_pic 送回到生产者,怎么办
pjob.pro->set_value(result);
}
this_thread::sleep_for(chrono::milliseconds(1000));
}
this_thread::yield();
}
}
int main(){
thread t0(video_capture);
thread t1(infer_worker);
t0.join();
t1.join();
return 0;
}
在上述代码中我们使用了 std::promise 和 std::future 来实现线程之间传递数据,并同步它们的执行。
首先我们定义了一个结构体 Job
struct Job{
shared_ptr<promise<string>> pro;
string input;
}
每个 Job 都包含一个指向 promise 的 shared_ptr 智能指针和一个输入,这个输入模拟的是要处理的图片,而 promise 将被用来在消费者线程中设置结果,并在生产者线程中获取这个结果
然后我们在生产者线程中,为每个新的 Job 创建了一个新的 promise 对象。然后,将这个 Job 添加到队列中,等待消费者线程处理它。
job.pro.reset(new promise<string>());
...
auto result = job.pro->get_future().get();
printf("Job %s -> %s\n", job.input.c_str(), result.c_str());
当消费者线程处理完一个 Job 并设置了结果后,生产者线程使用 job.pro->get_future().get() 来等待这个结果。这会阻塞生产者线程,直到消费者线程设置了 promise 的值。
在消费者线程中,处理了一个 Job 后,它创建一个结果字符串,模拟模型推理的结果,并使用 pjob.pro->set_value(result); 设置 promise 的值。这会立即解锁在生产者线程中等待这个 promise 的任何 future,并允许它继续执行。
这种方式在线程间传递数据非常有效,因为它允许生产者线程异步地等待消费者线程处理的结果,而不必使用复杂的同步机制。而且,由于 promise 和 future 之间的紧密关系,这种方法也是线程安全的。
运行效果如下:

可以看到符合我们的预期,我们成功的在生产者线程中拿到了消费者推理的结果
OK!生产者消费者模式我们就讲到这里。我们要合理的使用 future、promise、condition_variable,在实际的多线程任务中传递各种数据,去做各种封装,使得我们的性能足够友好,后面我们的封装课程中会大量使用 future、promise、condition_variable 这些东西
2. 问答环节
博主对多线程相关的知识不怎么了解,因此疯狂询问 chatGPT,故此做个记录方便下次查看,以下内容来自于博主和 chatGPT 之间的对话
问题1:我有一个疑问,在最开始的消费者生产者示例代码中,主程序在 main 函数中是自上而下执行的,因此代码先会去执行 t0.join() 再去执行 t1.join(),按理来说 t0.join() 会等待 t0 线程,而 t0 线程是一个生产者线程,会一直循环生产图片,并没有结束或者退出,那么为什么程序会执行到 t1.join() 呢?这个 join() 等待线程执行到底是等待线程执行结束还是说有别的含义呢?🤔
回答:您的代码中确实创建了两个线程:t0 和 t1,分别对应于 video_capture 和 infer_worker 函数。当您在 main 函数中调用 thread t0(video_capture); 和 thread t1(infer_worker);,这两个线程会立即开始运行。它们会并行执行,与主线程无关。
当主线程执行到 t0.join();,它会等待 t0 线程(即 video_capture 函数)完成。但这并不意味着 t1 线程(即 infer_worker 函数)不会运行。实际上,t1 会在后台并行执行,即使主线程被 t0.join(); 阻塞。
这意味着 video_capture 会定期生成图像,并将其放入队列中,而 infer_worker 会检查队列并处理图像。因为这两个线程是并行的,所以您会看到交替的"生产"和"消费"消息。
总之,尽管 t0.join(); 会阻塞主线程,但它不会阻止其他线程(如 t1)的执行。因此,video_capture 和 infer_worker 会并行运行,直到它们自己结束或程序被外部中断。
问题2:我还是有疑问,正常来说创建线程并不意味着启动线程吧,只有 join 才表示启动了线程,而按照你的说法 t0.join() 会阻塞主线程,它难道不会导致主线程即 main 程序无法向下运行吗?也就是 t1.join() 无法执行,即 t1 线程无法开启🤔
回答:很抱歉,我明白您的疑虑,但这里有些误解。
在 C++ 的 std::thread 中,线程在其对象创建时就开始执行。当您创建一个 std::thread 对象并传入一个函数,该函数在新的线程上立即开始执行。这与某些其他线程库的行为可能不同,但这确实是 C++ 标准库的行为。
在您的代码中,当执行以下代码时:
thread t0(video_capture); thread t1(infer_worker);两个线程 t0 和 t1 就已经开始并行执行了。主线程继续执行,而不必等待这两个线程。
关于 join(),这个方法并不是用来启动线程的。它的作用是等待关联的线程完成执行。当您调用一个线程对象的 join() 方法时,当前线程(在这个例子中是主线程)会被阻塞,直到被 join() 的线程完成执行。
所以,在您的代码中:
t0.join(); t1.join();当执行 t0.join(); 时,主线程会等待 t0 完成。但是,由于 video_capture 函数有一个无限循环,t0 实际上永远不会完成,所以主线程在这里被永久阻塞。但这并不影响 t0 和 t1 的执行,它们会继续并行执行。
为了更清晰地说明,您可以将 join() 方法视为一个同步点,它确保主线程等待其他线程完成执行,但它不启动或停止线程。线程的启动是在其对象创建时自动完成的。
问题3:为什么 STL 中的 queue 对象不是线程安全的呢?🤔
回答:大部分 STL 容器,包括 std::queue,都不是线程安全的。线程安全意味着多个线程可以同时访问一个对象而不需要外部同步。但在实际设计中,为了保持容器的高效性和灵活性,STL 容器通常不提供内置的线程安全机制。
如果两个或多个线程试图同时修改 std::queue(或其他 STL 容器),可能会出现未定义的行为。这意味着你可能会遇到如数据损坏、程序崩溃或其他不可预测的错误等问题。
问题4:lock_guard 是什么呢?它的功能是什么?🤔
回答:lock_guard 是一个 RAII (Resource Acquisition Is Initialization) 工具,它的设计目的是确保资源(在这种情况下是锁)在其生命周期内被适当地管理。当 lock_guard 对象被构造时,它会尝试获取传递给它的锁。当 lock_guard 对象超出其作用域或被销毁时,它会自动释放锁。
在代码中:
{ lock_guard<mutex> l(lock_); char name[100]; sprintf(name, "PIC-%d", img_id++); printf("生产了一个新图片: %s\n", name); qjobs_.push(name); }当控制流进入花括号 { 时,lock_guard 对象 l 被构造,并尝试获取 lock_ 锁。整个花括号内的代码都在锁的保护之下运行。当控制流离开花括号 } 时,lock_guard 对象 l 被销毁,导致 lock_ 锁被释放。
这种方法的优势是,即使在受保护的代码块中发生异常,lock_guard 的析构函数也会确保锁被正确释放,从而避免了潜在的死锁。
问题5:在利用条件变量解决队列溢出问题时,我们为什么在生产者线程中不再使用 lock_guard 而是使用 unique_lock?二者有什么区别吗?🤔
回答:是的,当与 std::condition_variable 一起使用时,通常选择 std::unique_lock 而不是 std::lock_guard。这两者都可以用来管理互斥锁,但它们在功能上有所不同,尤其是在与条件变量一起使用时。
以下是它们之间的主要区别:
1. 锁的灵活性:
- std::lock_guard:当 lock_guard 对象被创建时,它会自动锁定关联的互斥量。一旦锁定,不能再解锁,除非 lock_guard 对象被销毁。
- std::unique_lock:提供了更加灵活的锁管理。您可以明确地锁定和解锁关联的互斥量。这对于条件变量特别有用,因为 cv.wait() 在等待时需要临时解锁互斥量。
2. 与 std::condition_variable 的交互:
- std::lock_guard 不能与 std::condition_variable 一起使用,因为 std::condition_variable::wait() 需要能够临时解锁其关联的互斥量,而 lock_guard 不支持这个操作。
- std::unique_lock 可以与 std::condition_variable 一起使用,因为它支持锁的解锁和重新锁定。当调用 cv.wait() 时,互斥量会被临时解锁,并在返回之前重新锁定。
3. 性能开销:
- std::lock_guard 通常比 std::unique_lock 轻量,因为它只提供了基本的锁管理功能。
- std::unique_lock 更为灵活,但可能带来额外的性能开销(尽管在实际应用中这种开销通常可以忽略不计)。
总之,当您需要基本的锁管理并且不需要与 std::condition_variable 交互时,std::lock_guard 是一个简单而高效的选择。但当您需要更多的灵活性,特别是与条件变量一起使用时,std::unique_lock 是更合适的选择。
问题6:在利用 future 和 promise 解决线程间数据传递问题的代码中,我有注意到 promise 包装了一层 shared_ptr,这么做的优点在哪?为什么要多套一层,直接使用 promise 难道不行吗?🤔
回答:使用 shared_ptr 包装 promise 有几个可能的原因。虽然在代码示例中这种用法可能不是绝对必要的,但在某些场景下,使用 shared_ptr 对于管理对象的生命周期是有益的。以下是其中的一些理由:
1. 对象生命周期管理:使用 shared_ptr 可以确保 promise 的生命周期跨越多个作用域或函数调用,特别是在对象可能在多个地方被引用的情况下。当所有对应的 shared_ptr 都超出范围或被销毁时,promise 也会自动被销毁。
2. 线程安全的引用计数:shared_ptr 是线程安全的(至少在引用计数的更新上)。这意味着多个线程可以同时创建或销毁指向同一个对象的 shared_ptr 实例,而不会出现数据竞争。
3. 避免对象复制:std::promise 本身是不可复制的,但可以移动。如果您想在多个地方持有对同一个 promise 的引用,使用 shared_ptr 是有道理的,因为这样可以避免对象的移动操作,并确保多个地方都引用同一个 promise。
4. 与其他数据结构一起使用:一些数据结构,如标准库中的容器,需要其元素是可复制或可移动的。如果您打算将 promise 存储在这样的容器中,而又想避免移动操作,那么使用 shared_ptr 是有意义的。
在示例代码中,使用 shared_ptr 主要是为了便于管理和传递 promise,尤其是在多线程环境下。然而,如果您可以保证 promise 的生命周期,并确保只在一个地方使用它,那么直接使用 promise 也是可以的。
问题7:我不太能理解第四点,能详细解释下吗?🤔
回答:当然可以。让我们更深入地探讨第四点。
在 C++ 的 STL 容器中,许多操作可能会导致容器内元素的复制或移动。例如,当你向一个 std::vector 添加元素,超出其当前的容量时,它可能需要重新分配内存并移动其当前元素到新的内存位置。
考虑以下例子:
std::vector<std::promise<int>> promises;如果我们尝试将 std::promise 对象添加到此向量,可能会遇到问题。因为 std::promise 是不可复制的,当容器需要重新调整其大小或在其他情况下移动其元素时,我们不能简单地复制 promise。
那么,我们可以移动 promise 到容器中吗?尽管 std::promise 是可移动的,但这意味着原始的 promise 对象将不再是有效的,任何对其的进一步操作都是未定义的。如果我们的代码逻辑需要在添加到容器后继续使用原始的 promise 对象,这就会成为一个问题。
使用 shared_ptr 可以解决这个问题。当你有一个 shared_ptr<std::promise<int>>,你实际上是复制指针而不是它指向的对象。因此,无论容器如何复制或移动这些指针,指向的实际 promise 对象都保持不变,并且可以在容器外部安全地访问。
std::vector<std::shared_ptr<std::promise<int>>> promises;上面的容器包含指向 promise 的智能指针,而不是实际的 promise 对象。这意味着我们可以在容器重新分配或移动其内容时复制这些指针,而不用担心移动或使原始 promise 对象无效。
总之,第四点的核心思想是:使用 shared_ptr 可以避免直接在容器中复制或移动不可复制的对象(如 std::promise),而是复制指向这些对象的指针,这样可以确保对象的稳定性和持续可用性。
总结
本次课程我们学习了生产者和消费者模式,这在我们模型推理过程中非常常见,生产者线程负责读取图片,拿到推理结果进行画框可视化,消费者线程负责模型推理,将结果返回到生产者线程。我们在学习生产者和消费者模式过程中,解决了三个问题:
首先是共享资源访问问题,由于生产者和消费者线程要去队列中 push 和 pop 图片,而队列 queue 对象又不是线程安全的,因此我们要加上 🔒,在这里我们使用的是互斥锁 mutex,同时我们使用了 lock_guard 这个 RAII 工具确保了互斥量在进入作用域的时候加锁,离开作用域的时候解锁,防止程序忘记解锁而造成死锁的情况
其次是队列溢出问题,我们常常会遇到生产者太快,消费太慢的问题,我们创建了一个队列限制,限定队列最多可填充的图片数量,超过这个数量则等待消费者线程消费,而这里又涉及到生产者线程等待以及消费者线程通知的问题,我们是通过 condition_variable 来完成的,值得注意的是,在生产者线程中我们不再使用 lock_guard 而是要使用 unique_lock,因为我们在条件变量等待期间需要临时解锁,unique_lock 可以做到这件事而 lock_guard 对象一旦上锁除非离开作用域否则无法解锁。
最后是生产者如何拿到消费者的反馈问题,我们在考虑高性能的时候常常是异步模式,即生产者线程生成图片、画框,消费者线程推理出结果,这个时候生产者线程是需要拿到消费者线程的推理结果去画框的,我们采用 future 和 promise 来实现线程间数据共享的,在消费者线程通过 promise.set_value() 去设置值,在生成者线程中通过 future 对象的 get 方法去等待消费者线程的结果,值得注意的是,为了便于管理和传递,我们使用 shared_ptr 智能指针套了一层