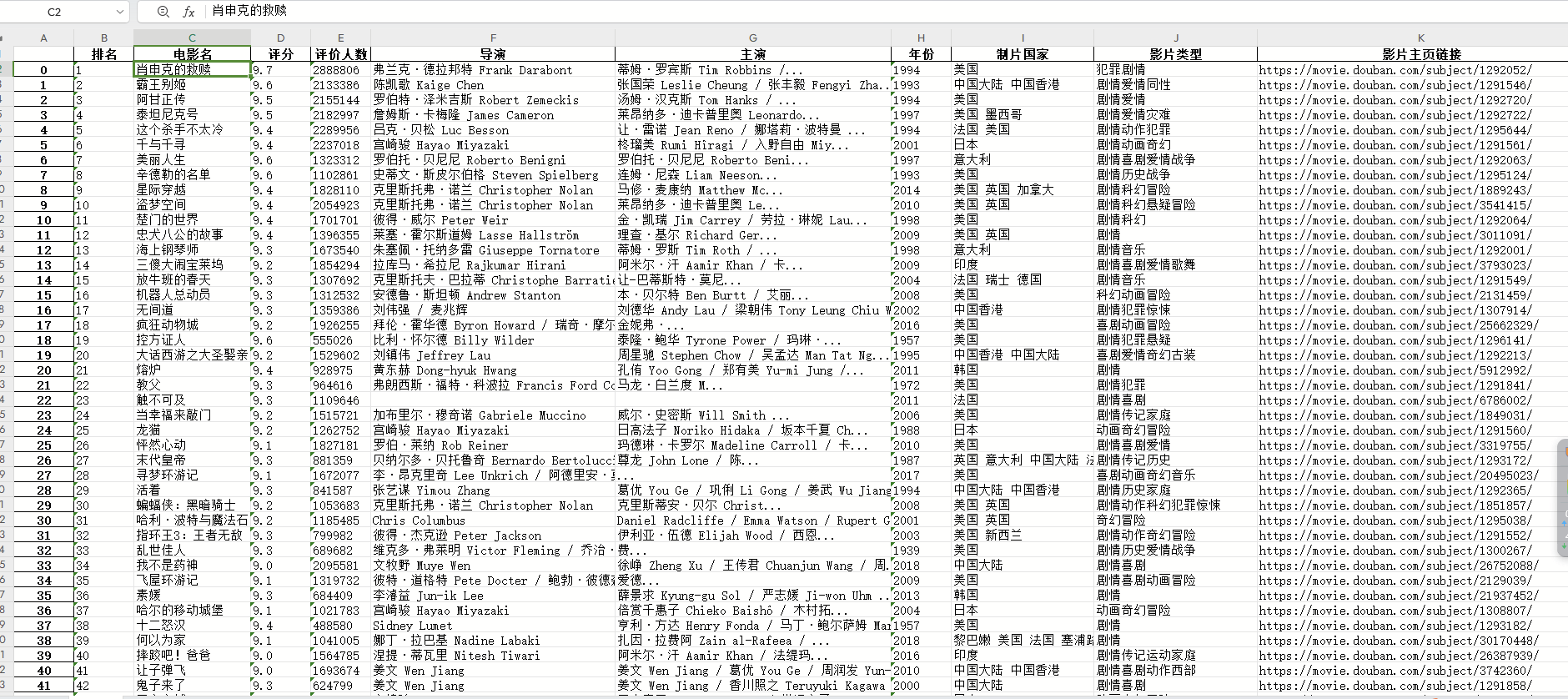
标题:Learning Visual Locomotion with Cross-Modal Supervision
作者:Antonio Loquercio, Ashish Kumar, Jitendra Malik
来源:2023 IEEE International Conference on Robotics and Automation (ICRA 2023)
这是佳佳怪分享的第4篇文章
摘要
在这项工作中,我们展示了如何学习仅使用单目 RGB 摄像头和本体感觉的视觉行走策略。由于模拟 RGB 比较困难,我们必须在真实世界中学习视觉。我们从模拟训练的盲目行走策略开始。这种策略可以穿越真实世界中的某些地形,但由于缺乏对即将到来的几何形状的了解,往往会陷入困境。利用视觉可以解决这个问题。我们在现实世界中训练视觉模块,利用我们提出的交叉模式监督(CrossModal Supervision,CMS)算法预测即将出现的地形。CMS 使用时移本体感觉来监督视觉,并允许策略随着更多的真实世界经验而不断改进。我们评估了基于视觉的行走策略在各种地形上的表现,包括楼梯(高达 19 厘米)、湿滑的斜坡(倾角为 35◦)、路边和高台阶(高达 20 厘米)以及复杂的离散地形。我们只用了不到 30 分钟的真实世界数据就实现了这一性能。最后,我们还展示了我们的策略能够在有限的实际经验中适应视野的变化。

图 1:上图所示的已部署行走策略仅使用单目眼心 RGB 数据流和本体感觉。地形包括楼梯(最多 19 厘米高)、路边(最多 20 厘米高)、斜坡(35°)、土路和非结构化建筑工地。其中有几种地形需要精确的支点位置,而这是通过视觉前瞻模块预测即将出现的地形来实现的。该模块完全在真实世界中进行训练。为此,我们提出的交叉模式监督(Cross-Modal Supervision,CMS)算法利用车载本体感觉对视觉模块进行监督。这自然允许策略在真实世界中利用自身经验不断学习。我们在底部展示了这样一个持续学习的过程,在不到 30 分钟的真实世界数据中,策略的成功率从最初的 40% 提高到了 100%。
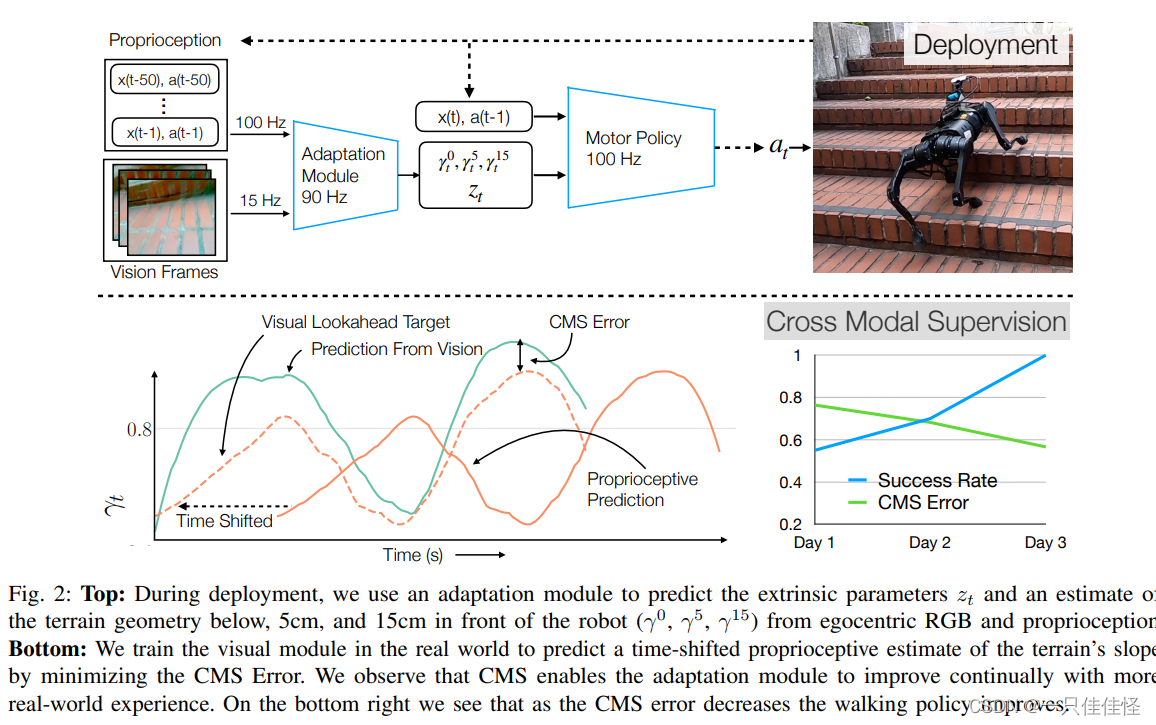
图 2:上图:在部署过程中,我们使用自适应模块来预测外在参数 zt,并根据自我中心 RGB 和本体感觉来估计机器人前方下方、5 厘米和 15 厘米处的地形几何形状(γ0、γ5、γ15)。底部: 我们在真实世界中训练视觉模块,通过最小化 CMS 误差来预测时移本体感觉对地形坡度的估计。我们观察到,CMS 可使适应模块随着实际经验的增加而不断改进。在右下方,我们可以看到随着 CMS 误差的减小,行走策略也得到了改善。
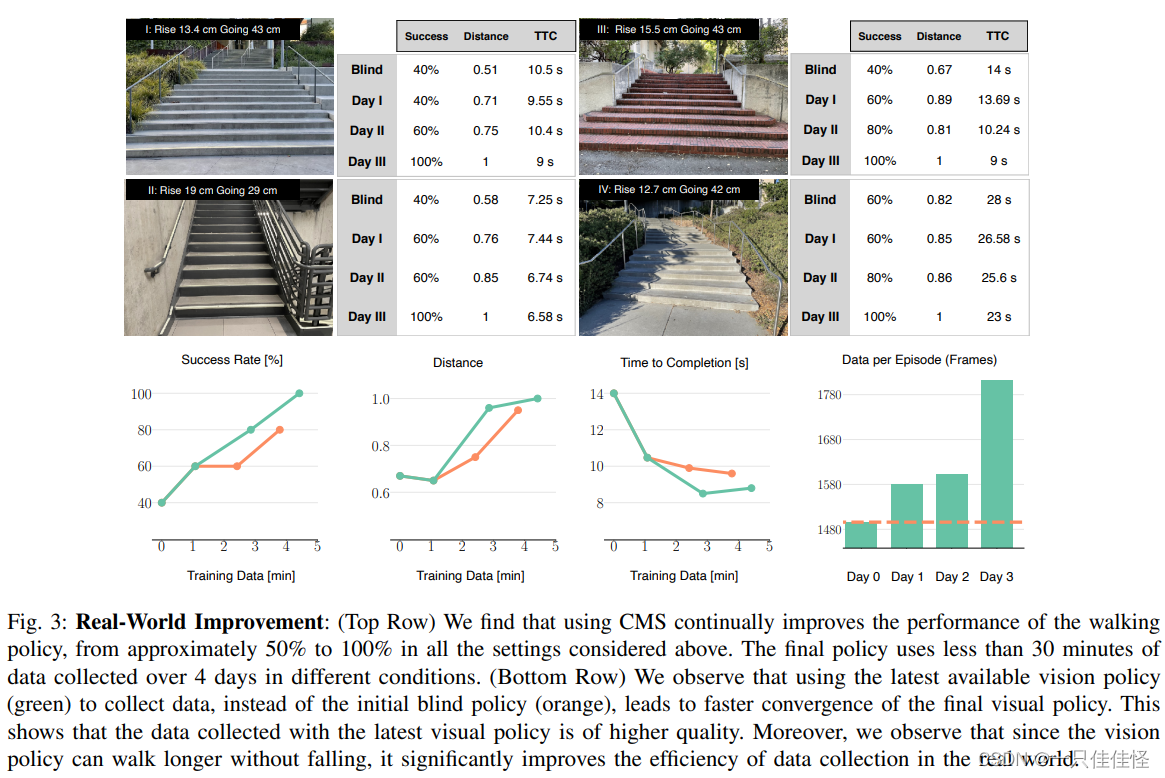
图 3:真实世界的改进:(最上面一行)我们发现,使用 CMS 可以持续改进步行策略的性能,在上述所有情况下,改进幅度从大约 50% 到 100% 不等。最终政策使用了 4 天内不同条件下收集的不到 30 分钟的数据。(下行)我们观察到,使用最新可用的视觉策略(绿色)而不是初始盲策略(橙色)来收集数据,可使最终视觉策略更快收敛。这表明使用最新视觉策略收集到的数据质量更高。此外,我们还观察到,由于视觉策略可以走得更远而不会摔倒,因此它大大提高了在现实世界中收集数据的效率。

图 4:Prism自适应测试: 我们在机器人上进行广为人知的Prism测试 [18]。
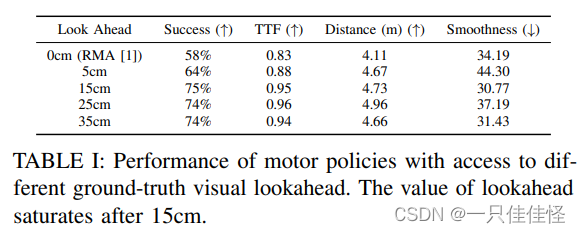
表 I: 获得不同地面实况视觉前瞻的电机策略性能。前瞻值在 15 厘米后达到饱和。
讨论
我们提出的 CMS 是一种利用从多种感官输入中收集的车载数据来不断提高性能的技术。虽然我们的工作仅使用视觉来预测环境几何的极低维度表示,但视觉流包含更多信息(如摩擦力、可穿越性等)。预测这些信息可能有助于在更复杂的地形上运动或高速运动。此外,我们的方法并不能改善真实世界中的运动系统。解决这些局限性是未来工作的一个令人兴奋的方向。




![[管理与领导-12]:IT基层管理者 - 绩效面谈 - 如何面谈,遇到问题员工怎么办?](https://img-blog.csdnimg.cn/869c44955b934d4696ef3b0a7159f946.png)

![c++学习(多线程)[33]](https://img-blog.csdnimg.cn/5f53410d7ff44da89c0a1ff71ebd8efa.png)