前言
在网络爬虫的开发过程中,经常会遇到需要处理一些反爬机制的情况。其中之一就是网站对于频繁访问的限制,即IP封禁。为了绕过这种限制,我们可以使用代理IP来动态改变请求的来源IP地址。在本篇博客中,将介绍如何使用代理IP的技术来爬取某瓣电影排行榜,并将结果写入Excel文件。
准备工作
首先,我们需要准备以下环境和工具:
-
Python编程语言
-
requests库:用于发送HTTP请求
-
BeautifulSoup库:用于解析HTML页面
-
openpyxl库:用于操作Excel文件
-
一个可用的代理IP池
步骤
1. 获取代理IP
使用搜索引擎搜索"免费代理IP",找到一个可用的代理IP网站。请注意,不同的网站可能有不同的获取代理IP的方式。你需要根据特定网站的规则来获取代理IP列表。
使用IP代理的必要性:
-
隐藏真实的访问源,保护个人或机构的隐私和安全。
-
绕过目标网站的访问限制,如IP封禁、地区限制等。
-
分散访问压力,提高爬取效率和稳定性。
-
收集不同地区或代理服务器上的数据,用于数据分析和对比。
爬虫是一种通过自动化方式从网站上获取数据的程序,而代理IP则是用于隐藏真实IP地址的中间服务器。
IP代理和爬虫的关系?

当你使用爬虫程序时,你的请求会发送到目标网站,并且网站可以看到你的真实IP地址。然而,如果你频繁地发送请求,可能会导致你的IP地址被封锁或限制访问。为了解决这个问题,可以使用代理IP。
代理IP充当了一个中间服务器的角色,将你的请求通过不同的IP地址发送到目标网站。这样,目标网站只能看到代理IP的地址,而不是你的真实IP地址。通过使用不同的代理IP轮换发送请求,可以减少被封锁或限制访问的风险。
另外,代理IP还可以用于绕过地理限制。有些网站或服务可能根据用户所在地区提供不同的内容或限制访问。通过使用代理IP,你可以模拟不同地区的访问,以便获取特定地区的数据。
2. 验证代理IP的可用性
将获取的代理IP列表保存到一个文件中(例如proxies.txt),然后编写代码来验证这些代理IP是否可用。我们可以通过发送请求到一个公开的IP查询API,来检查代理IP是否有效。
import requests
def check_proxy(proxy):
try:
response = requests.get("http://ip-api.com/json", proxies={"http": proxy, "https": proxy}, timeout=5)
if response.status_code == 200:
return True
except requests.exceptions.RequestException:
pass
return False
with open("proxies.txt", "r") as f:
proxies = f.read().splitlines()
valid_proxies = []
for proxy in proxies:
if check_proxy(proxy):
valid_proxies.append(proxy)
print(valid_proxies)3. 爬取某瓣电影排行榜
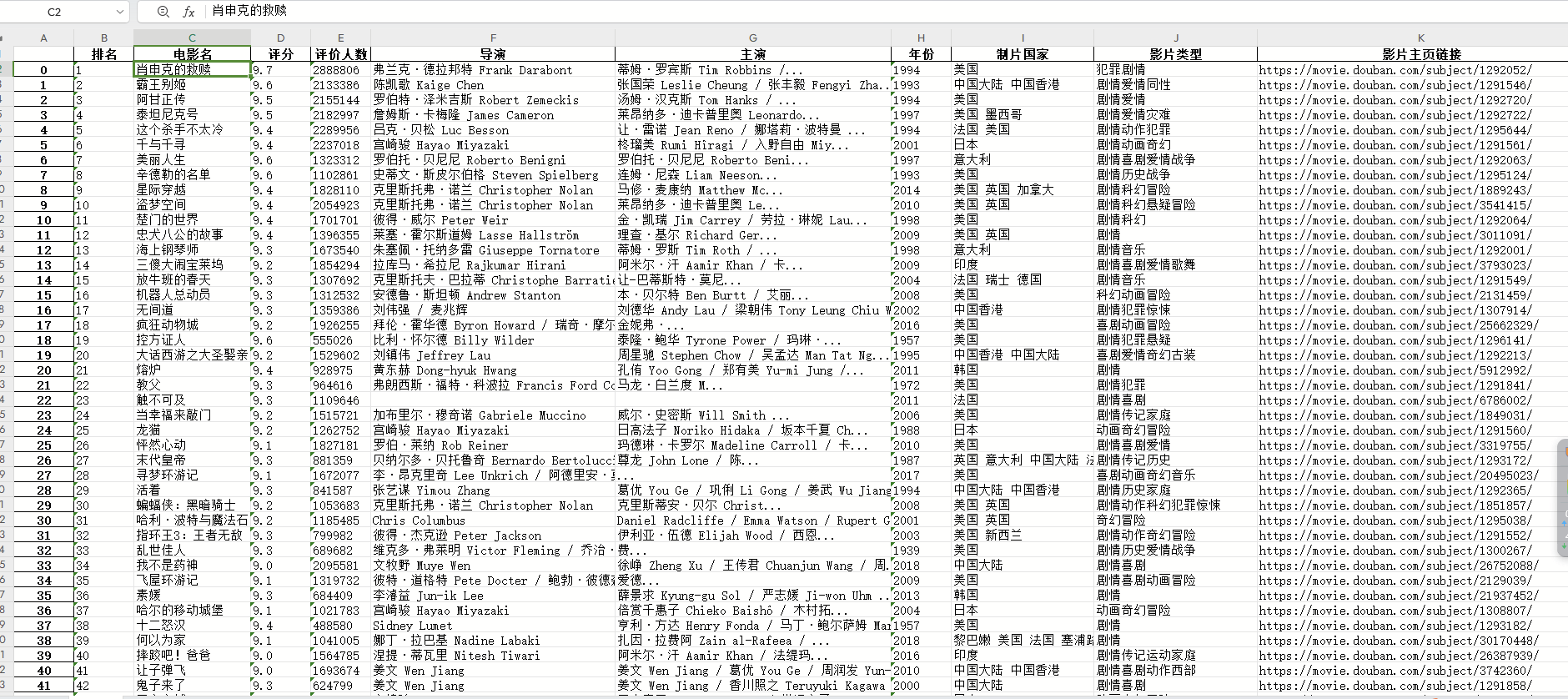
使用valid_proxies中的代理IP,编写代码来发送HTTP请求并解析网页内容。我们可以使用BeautifulSoup库来解析HTML页面,并提取所需的信息。
导入模块:
代码导入了所需要的库,包括re用于正则表达式操作,pandas用于写入Excel文件,requests用于发送HTTP请求,lxml用于解析HTML网页内容,time用于延时操作。
import re # 正则
import pandas as pd # pandas,写入Excel文件
import requests
from lxml import etree
import time
定义函数get_html_str(url),该函数用于发送HTTP请求并获取响应内容。函数中设置了请求头模拟浏览器,并可以添加代理IP进行请求。最后返回网页源码。
def get_html_str(url):
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
proxies = {
"http": "自己填一下子",
}
# 添加请求头和代理IP发送请求
response = requests.get(url, headers=headers, proxies=proxies) #
# 获取网页源码
html_str = response.content.decode()
# 返回网页源码
return html_str 定义函数get_data(html_str, data_list),该函数用于从网页源码中提取数据并存入列表。函数使用lxml将网页源码转换为Elements对象方便后续使用XPath进行解析。通过XPath取到所有的li标签,然后遍历每个li标签,利用XPath获取每个字段的信息,例如排名、电影名、评分等,并使用正则表达式进行字符串的提取和处理,最后将数据存入列表。
def get_data(html_str, data_list):
"""提取数据写入列表"""
# 将html字符串转换为etree对象方便后面使用xpath进行解析
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
li_list = html_data.xpath("//ol[@class='grid_view']/li")
# 打印一下li标签个数看是否和一页的电影个数对得上
print(len(li_list)) # 输出25,没有问题
# 遍历li_list列表取到某一个电影的对象
for li in li_list:
# 用xpath获取每一个字段信息
# 排名
ranking = li.xpath(".//div[@class='pic']/em/text()")[0]
# 电影名
title = li.xpath(".//div[@class='hd']/a/span[1]/text()")[0]
# 评分
score = li.xpath(".//span[@class='rating_num']/text()")[0]
# 评价人数
evaluators_number = li.xpath(".//div[@class='star']/span[4]/text()")[0]
evaluators_number = evaluators_number.replace('人评价', '') # 将'人评价'替换为替换为空,更美观
# 导演、主演
str1 = li.xpath(".//div[@class='bd']/p[1]//text()")[0]
# 利用正则提取导演名
try:
director = re.findall("导演: (.*?)主演", str1)[0]
director = re.sub('\xa0', '', director)
except:
director = None
# 利用正则提取主演
try:
performer = re.findall("主演: (.*)", str1)[0]
performer = re.sub('\xa0', '', performer)
except:
performer = None
# 上映时间、制片国家、电影类型都在这里标签下
str2 = li.xpath(".//div[@class='bd']/p[1]//text()")[1]
#
try:
# 通过斜杠进行分割
str2_list = str2.split(' / ')
# 年份
year = re.sub('[\n ]', '', str2_list[0])
# 制片国家
country = str2_list[1]
# 影片类型
type = re.sub('[\n ]', '', str2_list[2])
except:
year = None
country = None
type = None
url = li.xpath(".//div[@class='hd']/a/@href")[0]
print({'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,
'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})
data_list.append(
{'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,
'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})
定义函数into_excel(data_list),该函数用于将数据列表写入Excel文件。首先创建一个DataFrame对象,然后使用to_excel()方法将DataFrame写入Excel文件。
def into_excel(data_list):
# 创建DataFrame对象
df = pd.DataFrame(data_list)
# 写入excel文件
df.to_excel('电影Top250排行.xlsx')
定义了一个主函数main(),该函数用于控制流程。在主函数中,设置了翻页,循环遍历10页的数据。通过拼接URL,调用get_html_str()函数获取网页源码,然后调用get_data()函数提取数据,并将数据存入列表。为了控制爬取速度,使用time.sleep()方法进行延时操作。最后调用into_excel()函数将数据列表写入Excel文件。
def main():
data_list = [] # 空列表用于存储每页获取到的数据
# 1. 设置翻页
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i * 25) + '&filter='
# 2. 获取网页源码
html_str = get_html_str(url)
# 3. 提取数据
get_data(html_str, data_list)
# 4. 限制爬取的速度
time.sleep(5)
# 5. 写入excel
into_excel(data_list)
if __name__ == "__main__":
main()最终效果图
完整代码如下:
import re # 正则
import pandas as pd # pandas,写入Excel文件
import requests
from lxml import etree
import time
def get_html_str(url):
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
proxies = {
"http": "自己填一下子",
}
# 添加请求头和代理IP发送请求
response = requests.get(url, headers=headers, proxies=proxies) #
# 获取网页源码
html_str = response.content.decode()
# 返回网页源码
return html_str
def get_data(html_str, data_list):
"""提取数据写入列表"""
# 将html字符串转换为etree对象方便后面使用xpath进行解析
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
li_list = html_data.xpath("//ol[@class='grid_view']/li")
# 打印一下li标签个数看是否和一页的电影个数对得上
print(len(li_list)) # 输出25,没有问题
# 遍历li_list列表取到某一个电影的对象
for li in li_list:
# 用xpath获取每一个字段信息
# 排名
ranking = li.xpath(".//div[@class='pic']/em/text()")[0]
# 电影名
title = li.xpath(".//div[@class='hd']/a/span[1]/text()")[0]
# 评分
score = li.xpath(".//span[@class='rating_num']/text()")[0]
# 评价人数
evaluators_number = li.xpath(".//div[@class='star']/span[4]/text()")[0]
evaluators_number = evaluators_number.replace('人评价', '') # 将'人评价'替换为替换为空,更美观
# 导演、主演
str1 = li.xpath(".//div[@class='bd']/p[1]//text()")[0]
# 利用正则提取导演名
try:
director = re.findall("导演: (.*?)主演", str1)[0]
director = re.sub('\xa0', '', director)
except:
director = None
# 利用正则提取主演
try:
performer = re.findall("主演: (.*)", str1)[0]
performer = re.sub('\xa0', '', performer)
except:
performer = None
# 上映时间、制片国家、电影类型都在这里标签下
str2 = li.xpath(".//div[@class='bd']/p[1]//text()")[1]
#
try:
# 通过斜杠进行分割
str2_list = str2.split(' / ')
# 年份
year = re.sub('[\n ]', '', str2_list[0])
# 制片国家
country = str2_list[1]
# 影片类型
type = re.sub('[\n ]', '', str2_list[2])
except:
year = None
country = None
type = None
url = li.xpath(".//div[@class='hd']/a/@href")[0]
print({'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,
'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})
data_list.append(
{'排名': ranking, '电影名': title, '评分': score, '评价人数': evaluators_number, '导演': director,
'主演': performer, '年份': year, '制片国家': country, '影片类型': type, '影片主页链接': url})
def into_excel(data_list):
# 创建DataFrame对象
df = pd.DataFrame(data_list)
# 写入excel文件
df.to_excel('电影Top250排行.xlsx')
def main():
data_list = [] # 空列表用于存储每页获取到的数据
# 1. 设置翻页
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i * 25) + '&filter='
# 2. 获取网页源码
html_str = get_html_str(url)
# 3. 提取数据
get_data(html_str, data_list)
# 4. 限制爬取的速度
time.sleep(5)
# 5. 写入excel
into_excel(data_list)
if __name__ == "__main__":
main()
总结
通过使用代理IP技术,我们可以绕过网站的IP封禁限制,成功爬取某瓣电影排行榜的信息,并将结果写入Excel文件。这样,我们就可以方便地对电影信息进行整理和分析了。
![[管理与领导-12]:IT基层管理者 - 绩效面谈 - 如何面谈,遇到问题员工怎么办?](https://img-blog.csdnimg.cn/869c44955b934d4696ef3b0a7159f946.png)

![c++学习(多线程)[33]](https://img-blog.csdnimg.cn/5f53410d7ff44da89c0a1ff71ebd8efa.png)