标题:Learning to Walk by Steering: Perceptive Quadrupedal Locomotion in Dynamic Environments
作者:Mingyo Seo , Ryan Gupta , Yifeng Zhu , Alexy Skoutnev , Luis Sentis , and Yuke Zhu
来源:2023 IEEE International Conference on Robotics and Automation (ICRA 2023)
这是佳佳怪分享的第3篇文章
摘要
我们要解决动态环境中的感知运动问题。在这个问题中,四足机器人必须针对环境杂波和移动障碍表现出稳健而敏捷的行走行为。我们提出了一个名为 PRELUDE 的分层学习框架,它将感知运动问题分解为预测导航指令的高层决策和实现目标指令的低层步态生成。在这一框架中,我们利用在可操纵小车上收集到的人类演示,通过模仿学习训练高级导航控制器,并利用强化学习(RL)训练低级步态控制器。因此,我们的方法可以 复杂的导航行为,并 因此,我们的方法可以从人类的监督中获取复杂的导航行为,并从试验和错误中发现多变的步态。我们展示了 我们在模拟和硬件实验中证明了我们方法的有效性。实验中展示了我们方法的有效性。
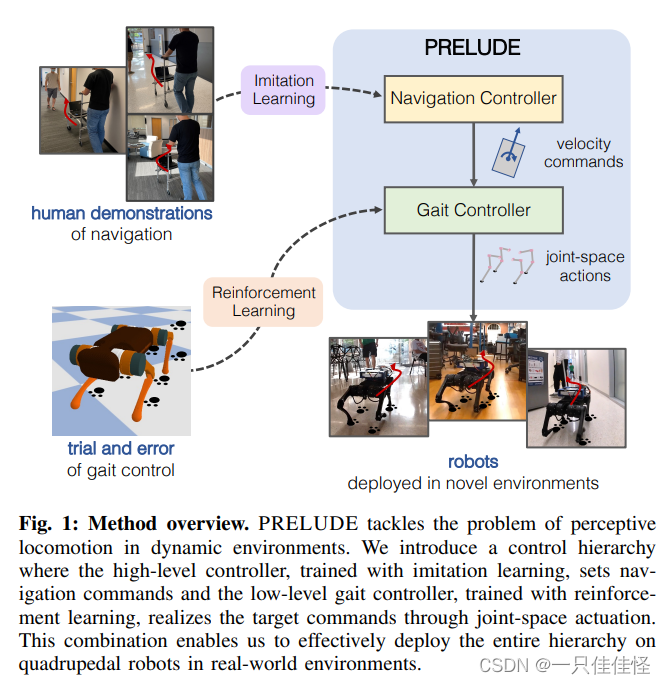
图 1:方法概述。PRELUDE 解决的是动态环境中的感知运动问题。我们引入了一种控制层级结构,其中高层控制器通过模仿学习训练来设定导航指令,低层步态控制器通过强化学习训练来通过联合空间执行来实现目标指令。这种组合使我们能够在真实世界环境中的四足机器人上有效地部署整个层次结构。
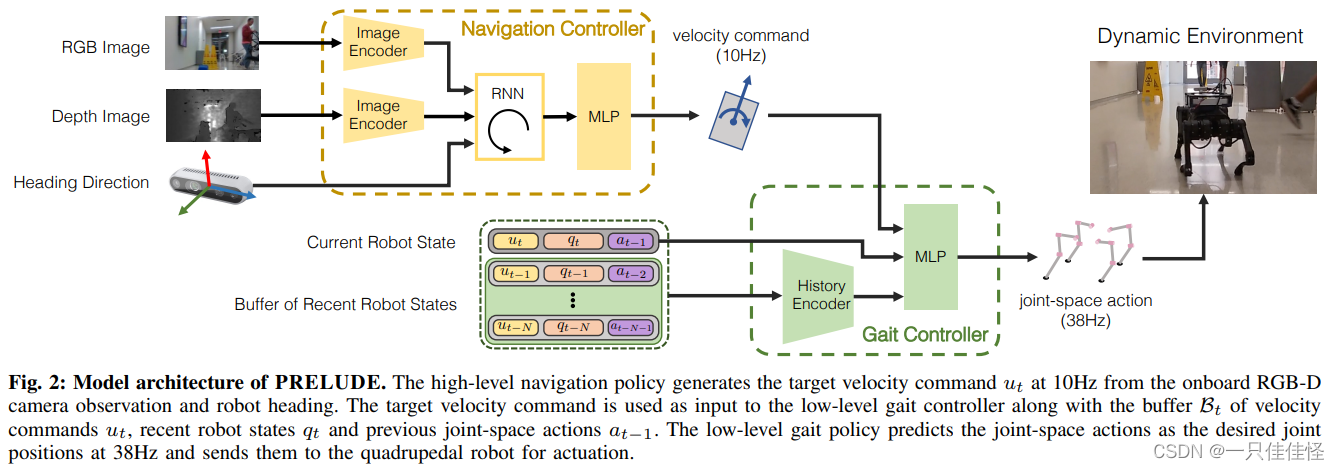
图 2:PRELUDE 的模型结构。高级导航策略根据机载 RGB-D 摄像头的观测数据和机器人航向,以 10Hz 的频率生成目标速度指令 ut。目标速度指令与速度指令缓冲区 Bt ut、最近的机器人状态 qt 和之前的关节空间动作 at-1 一起作为低级步态控制器的输入。低级步态策略以 38Hz 的频率将关节空间动作预测为所需的关节位置,并将其发送给四足机器人进行驱动。

图 3:硬件平台。专为收集人类导航演示而设计的可转向小车(左)和安装在小车高度上、带有以自我为中心的 RGB-D 摄像头的 Unitree A1 机器人(右)。它确保了根据演示数据训练的导航策略可以直接部署到机器人上。
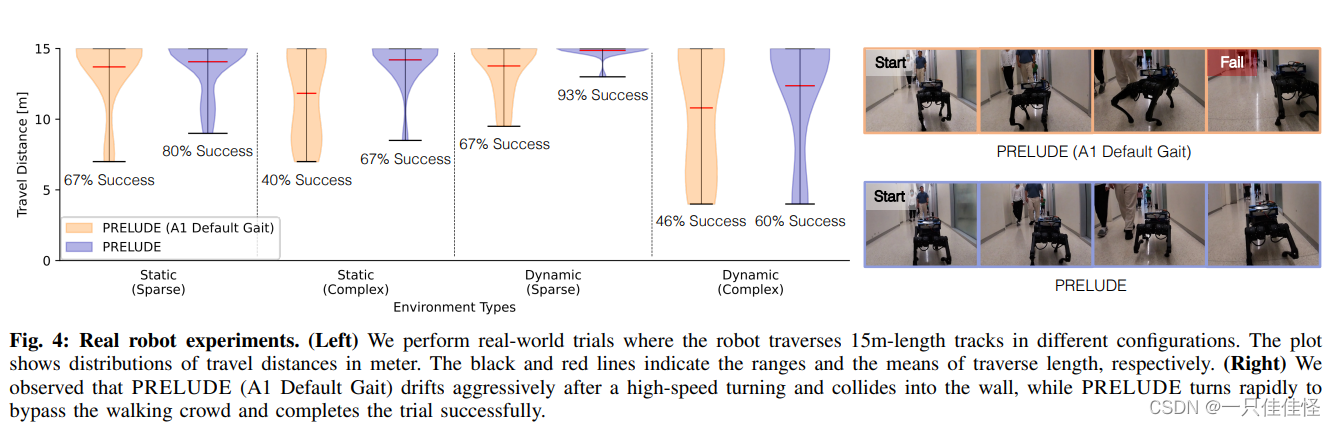
图 4:真实机器人实验。(左图)我们进行了真实试验,机器人以不同的配置穿越 15 米长的轨道。图中显示了以米为单位的行走距离分布。黑线和红线分别表示穿越长度的范围和平均值。(右图)我们观察到,PRELUDE(A1 默认步态)在高速转弯后猛烈漂移并撞上墙壁,而 PRELUDE 则快速转弯绕过行走的人群并成功完成试验。
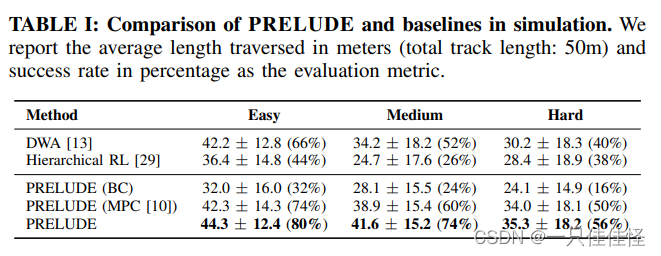
表 I: 模拟中 PRELUDE 与基线的比较。我们报告了以米为单位的平均穿越长度(轨道总长度:50 米)和以百分比为单位的成功率作为评估指标。
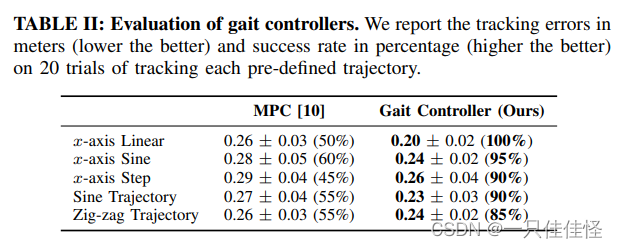
表二:步态控制器评估 我们以米为单位报告跟踪误差(越小越好),以百分比为单位报告跟踪成功率(越高越好)。
结论
我们介绍的 PRELUDE 是一种有效的方法,用于学习四足机器人的感知运动控制器,以穿越真实世界的动态环境。我们的方法结合了模仿学习和强化学习的互补优势,通过分层设计将运动问题分解为高级导航和低级步态生成。我们设计了一个可转向小车平台,用于收集复杂场景中的人类导航演示,并利用收集到的数据集训练高级导航策略。我们使用大规模强化学习在模拟中训练低级步态控制器,证明它能有效地转移到现实世界,并产生稳健而多变的运动。我们的工作主要集中在平地和室内环境,在这些环境中,人类的转向动作可以通过轮式平台方便地收集。在未来的工作中,我们希望将我们的轮式小车扩展到更复杂的机械设计中,以收集在室外崎岖地形上行走的人类数据集。