大夏天我好像二阳了真是要命啊。
现在找到工作了,感觉很快乐,但是也有了压力。
《论你靠吹牛混进公司后该怎么熬过试用期》
希望自己能保持学习的习惯!加油!
参考教程:
https://arxiv.org/pdf/2109.10852.pdf
https://github.com/google-research/pix2seq
https://zhuanlan.zhihu.com/p/421851551
https://github.com/moein-shariatnia/Pix2Seq
感觉自己理解的还是不太到位,主要是decoder相关的部分没有实践上使用过,纯理论不足以支撑完全弄清decoder的作用。
文章目录
- 背景
- 方法
- 从目标描述中构造序列
- architecture, objective and inference
- architecture
- objective
- inference
- 增强序列,整合先验
- altered sequence construction
- altered inference
- 代码实现
- tokenize
- 对单一坐标的处理
- 对一组输入的处理
- encode
- decode
- model
- encoder
- decoder
- __init__()
- forward()
背景
作者提出了一个用于目标检测的新框架Pix2Seq,把目标检测问题作为一个基于像素输入的语言建模任务。目标描述(包围框,类别)等以离散token的形式表示。
作者认为,现在有很多先进的目标检测方法在不同的领域取得显著的成就,但是任务的独特性和复杂性,让这些方法没有办法很好地泛化到更大范围的任务上,这也是这些方法的局限性。它们从先验知识中学习,但是又受限于先验知识。
pix2seq框架基于这种一种直觉:如果一个神经网络知道目标物体的种类和位置,那么我们只需要教会它怎么表达出来。通过学习“描述”对象,模型可以学习将“语言”建立在像素观测的基础上,从而获得有用的对象表示。给一种图像作为输入,pix2seq会产生一系列和目标描述相关的的离散token。
把目标检测任务当作一个基于像素输入的语言建模来作,可以使用比较generic and simple的模型框架和损失函数,而不是那些专门为目标检测任务设计的复杂组件。并且框架也可以轻松地被应用到别的领域上,它能为多种类型的视觉任务提供一个语言接口。
为了使用pix2seq解决目标检测任务,作者主要做了以下工作:
- 提出了一个量化序列化机制:将包围框和类别等信息转为离散的token序列。
- 利用encoder-decoder架构接受像素输入并生成目标序列。
- 目标函数使用基于像素输入和先验token的token的极大似然。
- 使用augmentation方法组合先验知识。
方法
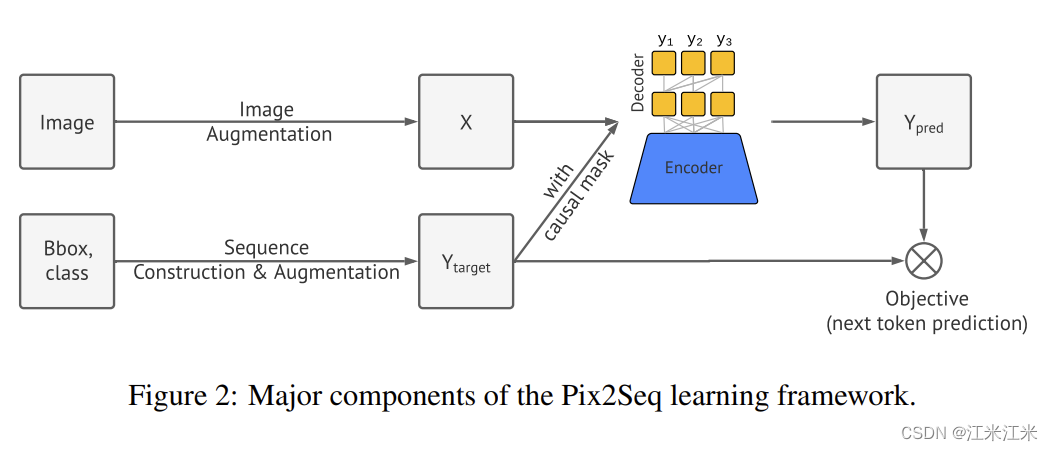
作者提出的pix2seq框架有四个主要的部分:
- Image Augmentation: 使用数据增强的方法来扩充训练数据,比如说随机缩放和裁剪。
- Sequence construction&augmentation: 把目标检测任务中常用的包围框和类别标注转换为一组离散的token。
- Architecture: 使用encoder-decoder模型,encoder获取图像像素输入,decoder生成目标序列。
- objective/loss function: 模型训练的目的是最大化基于图像输入的token的log似然函数。
【有一说一看完之后还是有点云里雾里的,比如说序列增强的部分,没太明白inference阶段的那个做法】
从目标描述中构造序列
在常见的目标检测数据集中,一个图像中可能有多个目标,用一组包围框和类别标签表示。在pix2seq中则是要转成离散的序列表示。
在包围框和类别两种标签中,类别标签是天然地表示成一个离散的token的形式的。而包围框通常是表示成两个角点(左上角和右下角)或者它的中心点与宽高。要把连续数字离散化后来表示它的坐标。具体来说,一个目标被表示成拥有五个离散token的序列: [ y m i n , x m i n , y m a x , x m a x , c ] [y_{min},x_{min},y_{max},x_{max},c] [ymin,xmin,ymax,xmax,c]。其中每个连续坐标被均匀地离散为介于 [ 1 , n b i n s ] [1,n_{bins}] [1,nbins]之间。所用的token共享一个词库,所以词库的大小等于bins的数量加class的数量。
对于一个600x600的图像,就是用600bins,比一般常用的语言模型的词库要小很多。下图显示了不同的bins带来的效果差异。使用的bins比较大的时候,小图像显示出很高的精度。

在得到每个目标的离散化的表达后,还需要把多个目标描述进行序列化的组合,来形成一个给定图像的整体描述。在目标检测中,目标的顺序对检测任务并没有什么影响,所以作者使用了随即顺序。作者也探究了别的排序方法,但是认为在网络能力足够的情况下,不同的顺序方法表现将一样好。
因为不同的图像会有不同个数的目标,生成的序列也会有不同的长度,使用一个EOS token来表示序列的结束。
不同顺序的序列表示如下:下图中使用的bins大小为1000,所以类别标签是从1000开始计数的。最后的0表示的是EOS token。

在论文附录中给出了比较简单的量化和反量化的代码。
-
Quantization of coordinates
def quantize(x, bins=1000): return int(x*(bins-1))这里的x是normalized的坐标,代表它相对原始图像边长的大小,范围在[0,1]之间。
-
Dequantization of discrete coordinates
def dequantize(x,bins=1000): return float(x)/(bins-1)就是将上面的结果复原的方法,两者可以说互为反函数。
architecture, objective and inference
architecture
使用一个encoder-decoder的结构。encoder用来把输入的图像编码成一个隐层表达,常用的可以是卷积网络或者transformer或者它们的组合。生成的部分,也就是decoder的部分,作者选用了transformer的decoder,它在语言模型中被广泛使用。每次可以基于先前生成的token和编码图像表达生成一个新的token。
objective
和一般的语言模型类似,pix2seq被训练来在给定图像和之前的token的情况下预测下一个token,使用极大似然损失:
m
a
x
i
m
i
z
e
∑
j
=
1
L
w
j
l
o
g
P
(
y
j
^
∣
x
,
y
1
:
j
−
1
)
maximize\sum_{j=1}^Lw_j logP(\hat{y_j}|x,y_{1:j-1})
maximizej=1∑LwjlogP(yj^∣x,y1:j−1)
inference
在推理阶段,作者从模型似然中进行token的采样。要么使用极大似然对应的token,要么使用别的随机采样的方法。作者发现使用nucleus采样会比使用最大似然采样取得更高的recall。等EOS序列被生成时,序列就会终止,接下来它会被直接用来转换成目标描述。
增强序列,整合先验
EOS token的存在允许模型去决定什么时候终止生成,但实际上我们发现模型总是在还没有预测完所有物体后就停止了。作者认为可能有以下两个原因:
- annoatation noise: 标注不完整,没有包括到所有的目标。
- uncertainty in recognizing or localizing: 可能模型的输出不是按照每个物体的置信度,因此对一些难检测的目标的置信度比较低,就会直接输出EOS,后面置信度高的目标就没机会输出了。
输出不完全的问题对精确度的影响不是很大,但是会带来比较大的召回问题。为了提升召回率,一个方案是延迟EOStoken的采样,但这样也会带来重复采样和噪声,从而造成精确率的降低,所以难点在于precision-recall的折衷。
另一个方案是序列增强,可以在task中引入一些先验知识。这一步有点像word2vec的做法,具体来说就是本来我们的token里面全是正样本,这样的话数据很不均衡,所以人为的在里面添加一些noise,帮助我们的模型学习真假标注,这样在延迟EOS到时候,模型可以有效过滤掉那些额外生成的噪声和重复采样。
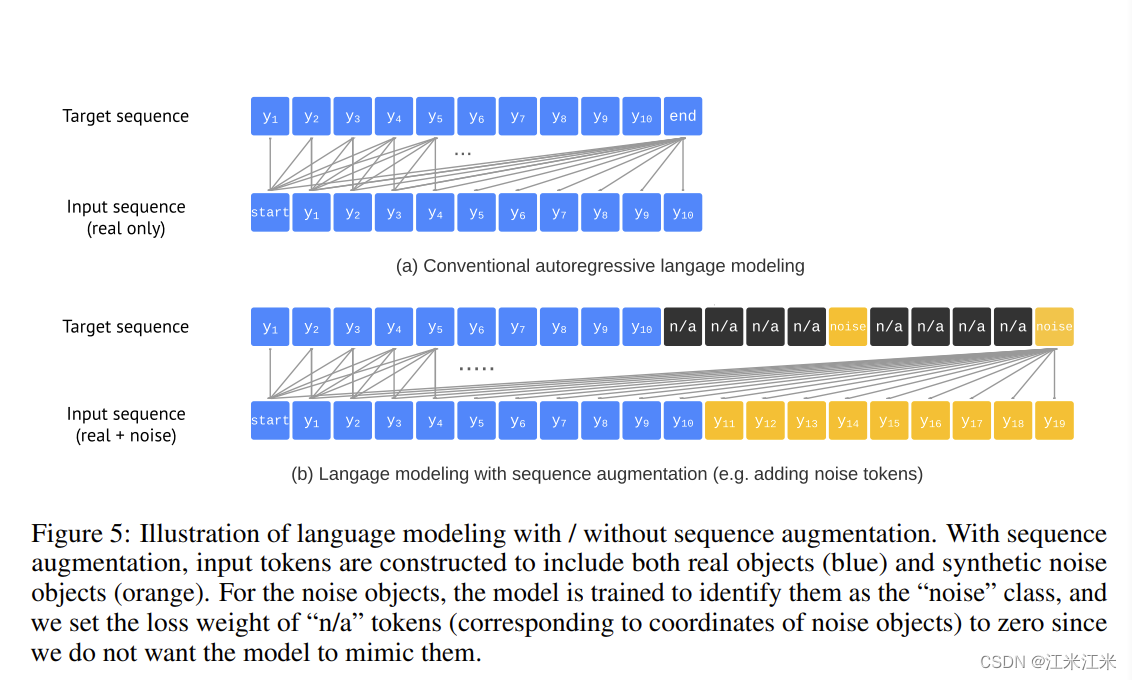
具体来说,就是对输入序列进行增强,除了真实的token外(图中蓝色的部分),还使用了合成的噪声token(图中黄色的部分)。同时,作者也对目标序列进行修改,让模型可以学习识别噪声token。
altered sequence construction
作者生成噪声来增强输入学习,使用以下两步:
- 在已有的ground-truth上增加噪声,比如随机缩放或平移。
- 生成一些完全随机的框(和随机的类别标签)。
一些噪声可能会独立或者和ground-truth有重叠,分别代表了noisy prediction和duplicated predictions。这些生成的假token会被放到原始输入的末尾,组成一个新的输入。
对于目标序列,noise的token会被设置为”nois”类别,对应的坐标被设置为“n/a"。损失权重被设为0。
altered inference
使用序列增强后,我们能够进行EOS token的延迟,从而在不损失精度的情况下提升召回率。因此,我们让这个模型尽可能预测一个最大的长度,产生固定数量的目标。当从生成的序列中提取包围框和类别的时候,会用极大似然的真实标签取代noise标签。
代码实现
官方源码使用的是tensorflow,因为我不太熟悉tensorflow,所以这一部分是参考的基于pytorch的非官方版本。这个版本比较简单,并且readme写的也很清晰。
首先我们回顾一下Pix2Seq的步骤:
- 序列增强,构建序列。
- encoder编码输入图像,生成隐层序列。
- decoder解码,获得目标token。也就是离散化的目标检测结果。
- 处理结果。
tokenize
首先来看一下如何构建输入序列。代码作者给出了一个比较详细的流程介绍。
- 使用特殊的token标记序列的开始和结尾。(BOS和EOS)
- 量化连续坐标值。
- 编码label。
- 随机排序,作为最终的序列。
具体的实现参考:https://github.com/moein-shariatnia/Pix2Seq/blob/master/tokenizer.py
我们可以分开来看。
对单一坐标的处理
对坐标量化和反量化的部分和论文附录中的简单做法一致。
具体来说,加入输入图像大小是224,那么你的bins至少要有224个,才能实现在每个像素上的划分。所以一般为了预测的准确,bins数量不能太少。
在代码解释中给了个例子,假如现在有一个bbox,坐标为 (12.2, 35.8, 68.1, 120.5),首先你要进行normalize将它归一化到0到1之间,如何直接执行int(x*(self.num_bins-1)),在bins数量是224的情况下,这样得到的结果是(12, 35, 67, 119)。因为int本身是向下取整的。这种情况下我们会丢失一些信息,假如这个时候你使用稍微大一点的bins,丢失的信息就会相对少一些。
但是也不能太大,因为bins达到一定程度后不会再有performance上的提升,反而很冗余。而且大bins也会带来更多的计算量。
def quantize(self, x: np.array):
"""
x is a real number in [0, 1]
"""
return (x * (self.num_bins - 1)).astype('int')
def dequantize(self, x: np.array):
"""
x is an integer between [0, num_bins-1]
"""
return x.astype('float32') / (self.num_bins - 1)
对一组输入的处理
我们分开来看序列的encode和decode。
encode
在encode部分,你输入的是labels和bboxes两个list。
- 对于label,label本身就是离散化的,你只需要将它更新成新label即可,举例来说就是加上bins的数量。
- 对于bboxes,你要先进去归一化,然后离散化。
- 将label和bboxes组合在一起,并且在开头加上BOS,结尾加上EOS。
这部分实现也比较简单。
对于label:
labels = np.array(labels)
labels += self.num_bins # label直接加上num_bins,形成新label
labels = labels.astype('int')[:self.max_len]
对于bboxes:
bboxes[:, 0] = bboxes[:, 0] / self.width
bboxes[:, 2] = bboxes[:, 2] / self.width
bboxes[:, 1] = bboxes[:, 1] / self.height
bboxes[:, 3] = bboxes[:, 3] / self.height
bboxes = self.quantize(bboxes)[:self.max_len]
对于序列:
tokenized = [self.BOS_code] # 加上bos
for label, bbox in zip(labels, bboxes):
tokens = list(bbox)
tokens.append(label)
tokenized.extend(list(map(int, tokens))) # label和bbox组合在一起
tokenized.append(self.EOS_code) # 加上eos
decode
在decode的部分,你输入的是token。需要使用encode的反向操作来获得结果。
对于序列:
tokens = tokens[1:-1] # 去掉bos和eos
assert len(tokens) % 5 == 0, "invalid tokens"
labels = []
bboxes = []
for i in range(4, len(tokens)+1, 5):
label = tokens[i] # 拿出label
bbox = tokens[i-4: i] # label前的四个数是bbox
labels.append(int(label))
bboxes.append([int(item) for item in bbox])
对于label:
labels = np.array(labels) - self.num_bins
对于bboxes:
bboxes = np.array(bboxes)
bboxes = self.dequantize(bboxes) # 反量化
bboxes[:, 0] = bboxes[:, 0] * self.width
bboxes[:, 2] = bboxes[:, 2] * self.width
bboxes[:, 1] = bboxes[:, 1] * self.height
bboxes[:, 3] = bboxes[:, 3] * self.height # 反归一化
model
模型部分由一个encoder和decoder组成。
encoder
encoder的作用是以图像为输入,并输出对应的隐层编码,或者话说就是图像的表达,图像的特征。
在这个版本的代码中,代码作中使用的是DeiT。相对VIT来说,DeiT在训练速度和数据利用上比较有优势。作者认为使用基于VIT类似的backbone,它会把图像分成不同的patch并像处理单词一样,对于每个patch都能获得独特的编码,可以把这些都送给decoder,这样就类似于在做一个语言翻译的工作。
作者直接使用timm中的DeiT作为encoder。
class Encoder(nn.Module):
def __init__(self, model_name='deit3_small_patch16_384_in21ft1k', pretrained=False, out_dim=256):
super().__init__()
self.model = timm.create_model(
model_name, num_classes=0, global_pool='', pretrained=pretrained)
self.bottleneck = nn.AdaptiveAvgPool1d(out_dim)
def forward(self, x):
features = self.model(x)
return self.bottleneck(features[:, 1:])
DeiT的输出理论上包括了一个cls token和所有的patch token,这个cls token作者没有使用,只使用了输出的patch token。
decoder
decoder的部分以输入图像的patch embbeding作为输入,并进行bboxes和label的预测。代码作者在这里直接使用了pytorch中transformerdecoder。
这里的做法真的很nlp,感觉自己也不是那么理解。具体来说首先还是构建一个词库,这个词库的大小是 n_bins+classes+3,这个3代表的是三个类型的标记符号。词库的维度在这里是256。这里做的主要是个词预测的工作。对于输入的图像特征和上一个token,比如说xmin,那么你要预测的下一个token是ymin。
init()
初始化的部分主要有以下几个重要部件:
- 词向量。对我们的输入序列进行编码。
- decoder。
- 位置编码。代码作者对encoder和decoder都准备了一个位置编码。
def __init__(self, vocab_size, encoder_length, dim, num_heads, num_layers):
super().__init__()
self.dim = dim
self.embedding = nn.Embedding(vocab_size, dim) # 这个是我们的词库,对每个像素位置都构建了一个embedding
self.decoder_pos_embed = nn.Parameter(torch.randn(1, CFG.max_len-1, dim) * .02) # 位置编码
self.decoder_pos_drop = nn.Dropout(p=0.05)
decoder_layer = nn.TransformerDecoderLayer(d_model=dim, nhead=num_heads)
self.decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_layers) # decoder
self.output = nn.Linear(dim, vocab_size)
self.encoder_pos_embed = nn.Parameter(torch.randn(1, encoder_length, dim) * .02) # encoder位置编码
self.encoder_pos_drop = nn.Dropout(p=0.05)
self.init_weights()
forward()
forward()部分直接理解起来就是,我们的输入有两种。
encoder_out,即encoder部分输出的图像的feature,它的大小是(N,L,D),N代表batchsize,L代表patch size,D代表token的维度。
tgt是我们的target token,更具体的说就是已经经过tokenize的目标序列。
理论上来说tgt的token长度和encoder_out的L应该是不一致的。对这个地方表示疑惑?????也有可能L只是个标记,没有别的意义。
首先对于输入的token,这里进行了一个mask。因为对于一个token,它在预测的时候只能看到前面的token,所以在它后面的token相对它都要被mask掉。
我们的token是被当作单词来做的,那么对于单词,我们要获得它的词向量。对于大小为(N,L)的输入,我们会获得(N,L,D)大小的输出的词向量。并加上了位置编码。encoder的输出也加上了位置编码。
将这些结果一起送到decoder中去。
decoder的输出大小应该和输入大小保持一致,也就是(N,L,D)。
最后接一个全连接层,将输出的最后一个维度映射为词库大小,因为在做输出的时候是用交叉熵做的,其实相对于对N*L个东西进行了词库大小维度的分类,每个东西找到对应的类别,也就是bins的index。
def forward(self, encoder_out, tgt):
"""
encoder_out: shape(N, L, D)
tgt: shape(N, L)
"""
tgt_mask, tgt_padding_mask = create_mask(tgt) # 获得mask
tgt_embedding = self.embedding(tgt)
tgt_embedding = self.decoder_pos_drop(
tgt_embedding + self.decoder_pos_embed
)
encoder_out = self.encoder_pos_drop(
encoder_out + self.encoder_pos_embed
)
encoder_out = encoder_out.transpose(0, 1)
tgt_embedding = tgt_embedding.transpose(0, 1)
preds = self.decoder(memory=encoder_out,
tgt=tgt_embedding,
tgt_mask=tgt_mask,
tgt_key_padding_mask=tgt_padding_mask)
preds = preds.transpose(0, 1)
return self.output(preds)