文章目录
- 数据无量纲化
- preprocessing.MinMaxScaler(归一化)
- 导库
- 归一化
- 另一种写法
- 将归一化的结果逆转
- preprocessing.StandardScaler(标准化)
- 导库
- 实例化
- 查看属性
- 查看结果
- 逆标准化
- 缺失值
- impute.SimpleImputer
- 另一种填充写法
- 处理分类型特征:编码与哑变量
- preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
- preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
- preprocessing.OneHotEncoder:独热编码,创建哑变量
- 处理连续性特征:二值化与分段
- sklearn.preprocessing.Binarizer
- preprocessing.KBinsDiscretizer
数据无量纲化

preprocessing.MinMaxScaler(归一化)

导库
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
归一化
# 实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #在这里本质是生成min(x), 和max(x)
result = scaler.transform(data) # 通过接口导出结果
result
另一种写法
scaler = MinMaxScaler() #实例化
result_ = scaler.fit_transform(data) # 训练和导出结果一步达成
result_


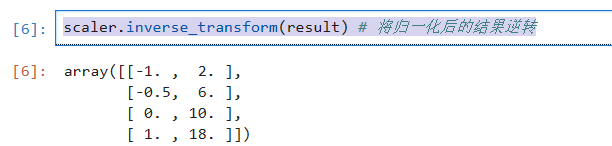
将归一化的结果逆转
scaler.inverse_transform(result) # 将归一化后的结果逆转

用numpy实现归一化
import numpy as np
X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
# 归一化
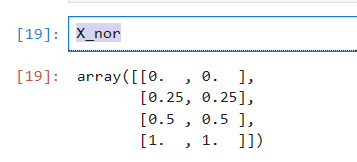
X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_nor
逆转
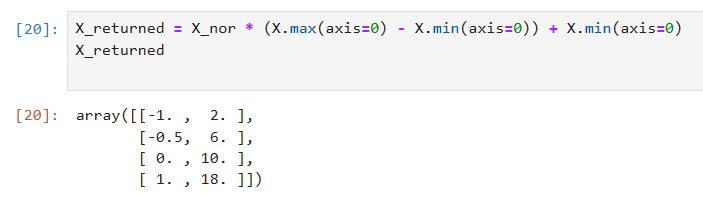
X_returned = X_nor * (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0)
X_returned
preprocessing.StandardScaler(标准化)

导库
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
实例化
scaler = StandardScaler() # 实例化
scaler.fit(data) # 本质是生成均值和方差
查看属性
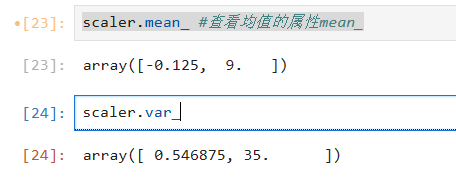
scaler.mean_ #查看均值的属性mean_
scaler.var_ # 查看方差的属性var_
查看结果
x_std = scaler.fit_transform(data)
x_std


逆标准化
return_x = scaler.inverse_transform(x_std)
return_x


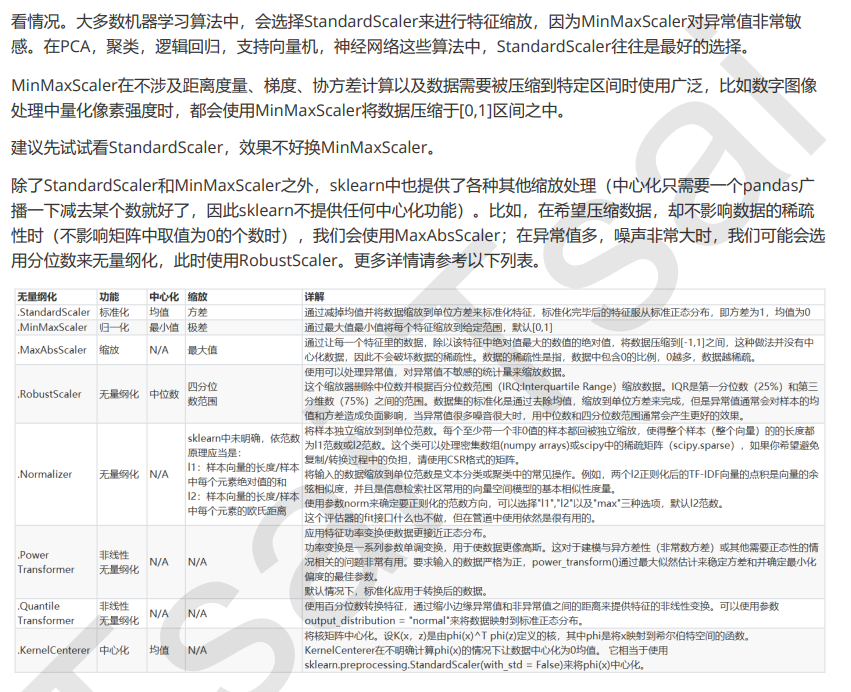
关于如何选择这两种无量纲化的方式要具体问题具体分析,但是我们一般在机器学习算法中选择标准化,这就好比我们能让他符合标准正态分布为什么不呢?而且MinMaxScaler对异常值很敏感,如果有一个很大的值会把其他值压缩到一个很小的区间内
缺失值

impute.SimpleImputer

导库
import pandas as pd
data = pd.read_csv(r"C:\Users\cxy\OneDrive\桌面\【机器学习】菜菜的sklearn课堂(1-12全课)\03数据预处理和特征工程\Narrativedata.csv"
,index_col=0 # 告诉python第0列是索引不是属性
)
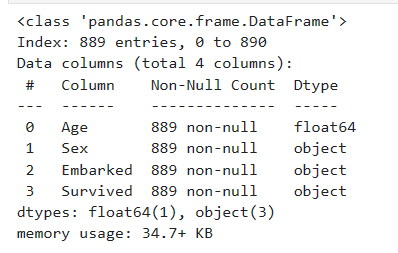
data.info()
提取出我们要填补的列
Age = data.loc[:, 'Age'].values.reshape(-1, 1) # reshape()能够将数据升维的方法
建模
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer() #实例化默认均值填补
imp_median = SimpleImputer(strategy='median') # 用中位数填补
imp_0 = SimpleImputer(strategy='constant', fill_value=0) # 用0填补
imp_mean = imp_mean.fit_transform(Age)
imp_median = imp_median.fit_transform(Age)
imp_0 = imp_0.fit_transform(Age)
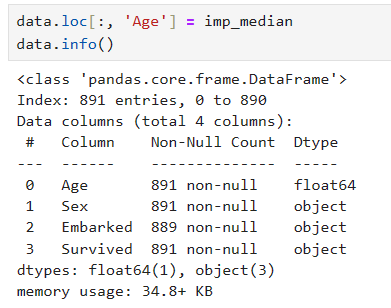
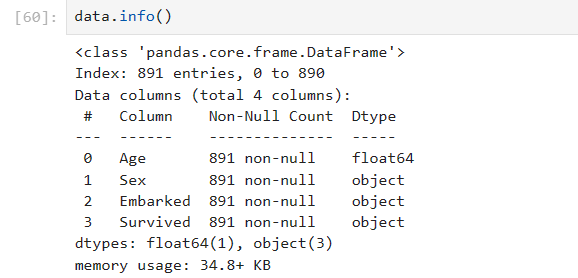
用均值填补的结果
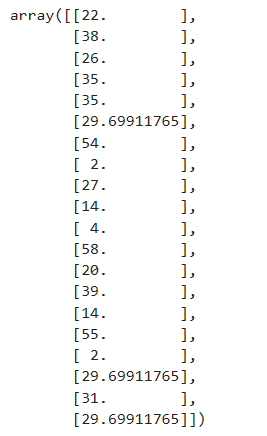
用中位数填补的结果

用0填补的结果

在实际中我们会直接把那两个缺失的数据直接删除
# 使用众数填补空缺值
Embarked = data.loc[:, 'Embarked'].values.reshape(-1, 1) # reshape()能够将数据升维的方法
imp_mode = SimpleImputer(strategy='most_frequent')
imp_mode = imp_mode.fit_transform(Embarked)
data.loc[:, "Embarked"] = imp_mode
另一种填充写法
导库
import pandas as pd
data_ = pd.read_csv(r"C:\Users\cxy\OneDrive\桌面\【机器学习】菜菜的sklearn课堂(1-12全课)\03数据预处理和特征工程\Narrativedata.csv"
,index_col=0 # 告诉python第0列是索引不是属性
)
data_.head()
填补
data_.loc[:, 'Age'] = data_.loc[:, 'Age'].fillna(data_.loc[:, 'Age'].median()) # fillna()在DataFrame里面直接进行填补
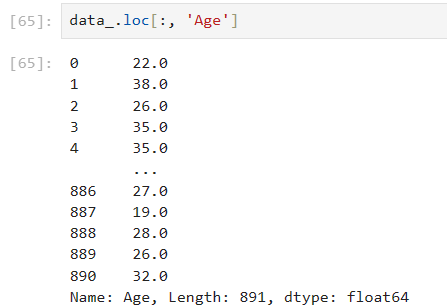
删除缺失值
data_.dropna(axis=0, inplace=True)
#axis=0表示删除所有有缺失值的行。inplace表示覆盖原数据,即在原数据上进行修改,当inplace = False时,表示会产生一个复制的数据
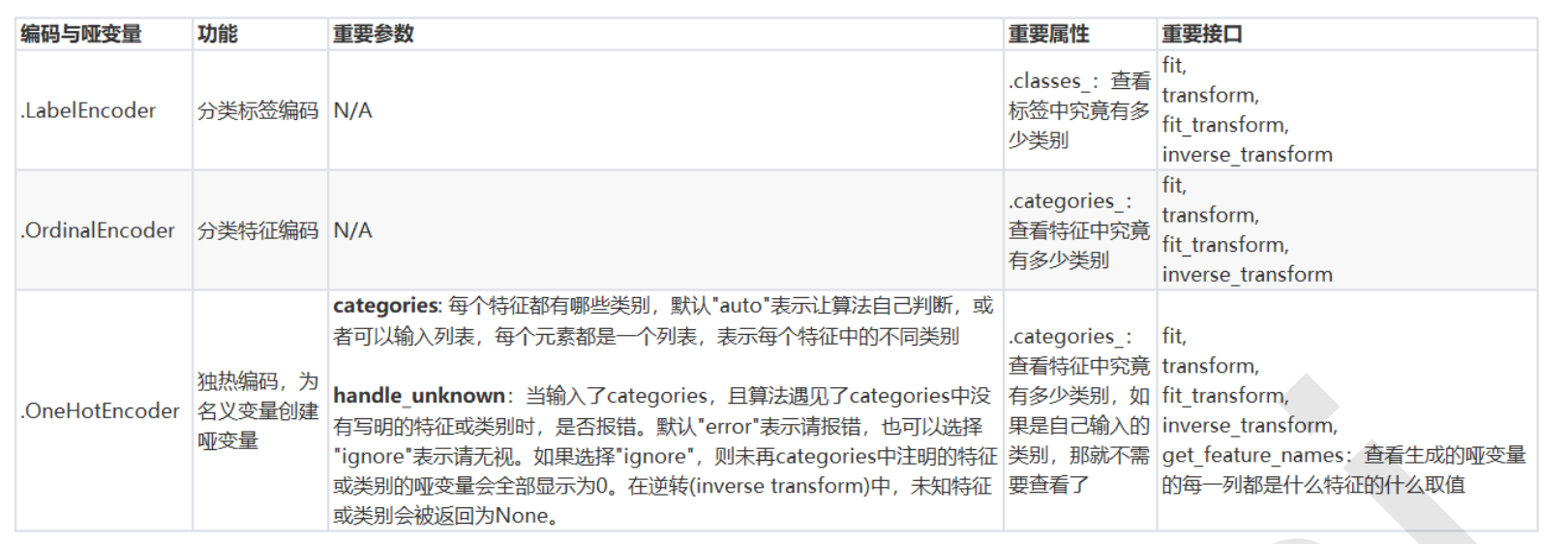
处理分类型特征:编码与哑变量

preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:, -1] # 要输入的时标签不是特征矩阵,允许一维
le = LabelEncoder()
le = le.fit_transform(y)
data.iloc[:,-1] = label
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
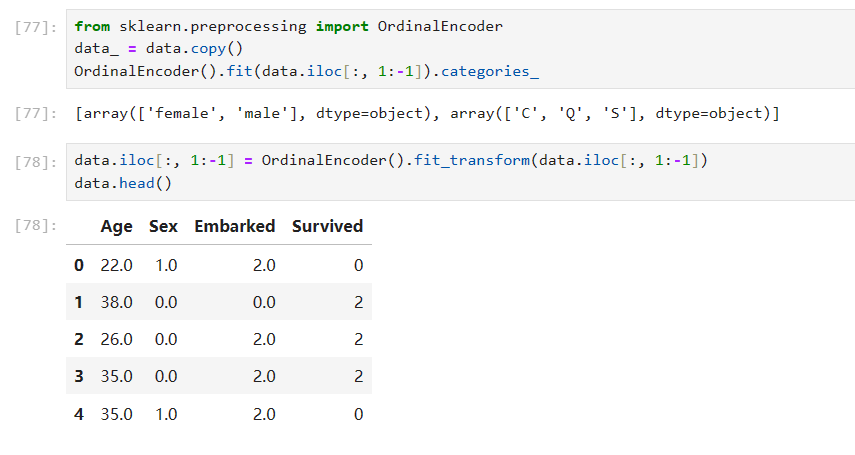
from sklearn.preprocessing import OrdinalEncoder
data_ = data.copy()
OrdinalEncoder().fit(data.iloc[:, 1:-1]).categories_
data.iloc[:, 1:-1] = OrdinalEncoder().fit_transform(data.iloc[:, 1:-1])
data.head()
preprocessing.OneHotEncoder:独热编码,创建哑变量


from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:1:-1]
result = OneHotEncoder(categories='auto').fit_transform(X).toarray() # 使用autopython会自己帮我们确定这个参数应该填什么
result



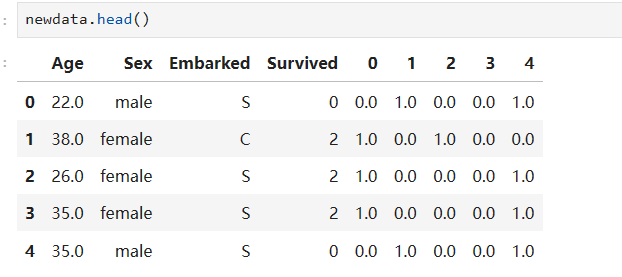
我们如何把我们新生成的哑变量放回去?
先将哑变量直接连在表的右边
newdata = pd.concat([data, pd.DataFrame(result)], axis=1)
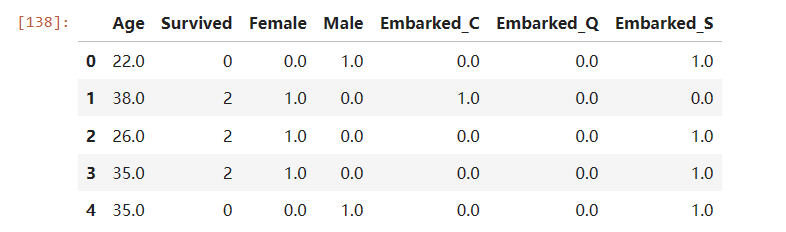
将不需要的列删除
newdata.drop(["Sex", "Embarked"], axis=1, inplace=True)
newdata.columns = ["Age", "Survived", "Female", "Male", "Embarked_C", "Embarked_Q", "Embarked_S"]
newdata.head()

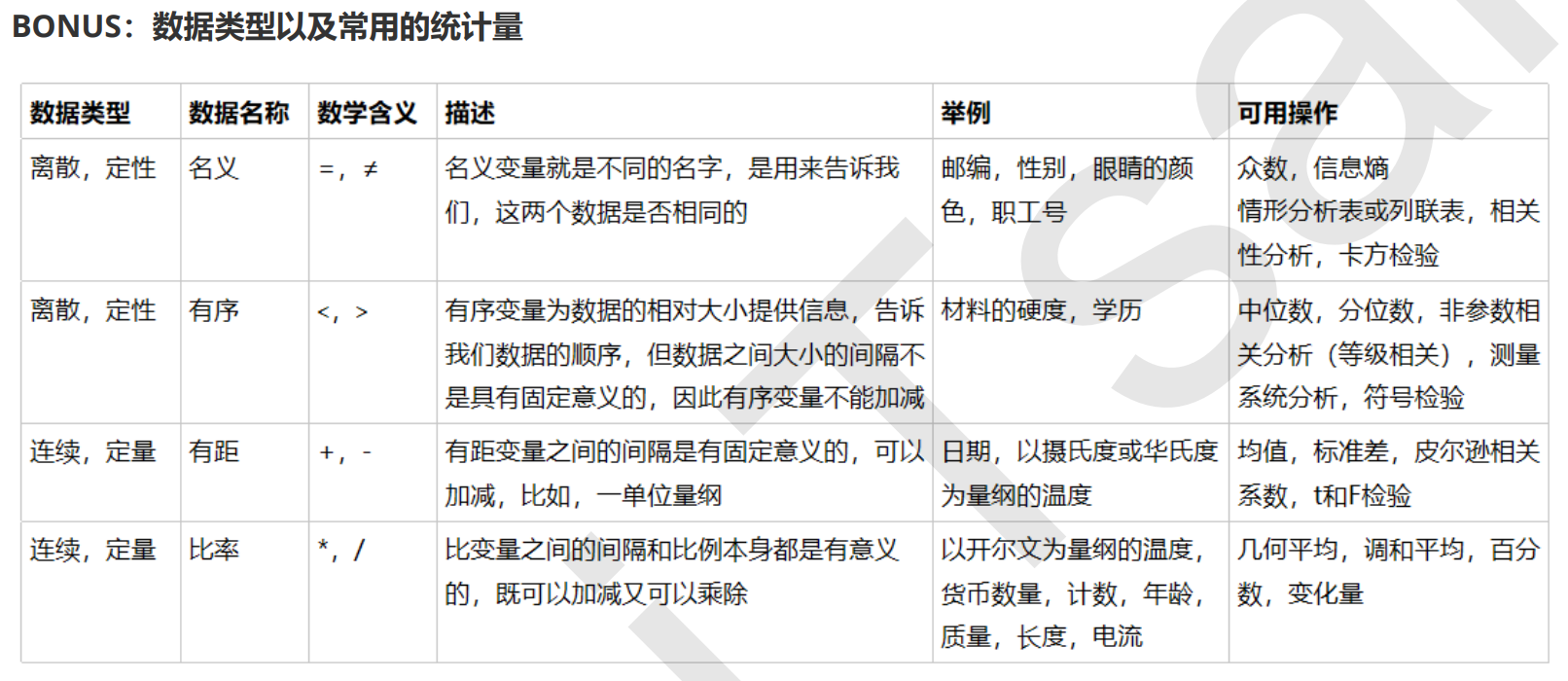
处理连续性特征:二值化与分段
sklearn.preprocessing.Binarizer

from sklearn.preprocessing import Binarizer
X = data_2.iloc[:,0].values.reshape(-1,1)
transformer = Binarizer(threshold=30).fit_transform(X)
preprocessing.KBinsDiscretizer

from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:, 0].values.reshape(-1, 1)
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit_transform(X)