在C++中,函数压栈(函数调用)和出栈(函数返回)是函数调用过程中的两个关键步骤。下面将逐步解释这两个过程:
一 函数压栈与出栈过程简介
函数压栈(函数调用)的过程如下:
- 调用指令:在函数调用点,会发出一个调用指令(如call指令),将控制权转移到被调用函数的入口点。
- 保存返回地址:调用指令执行前,当前函数的返回地址会被压入栈中,以便在函数执行完毕后返回到正确的位置。
- 参数压栈:函数调用时,将函数的参数按照一定的顺序压入栈中。通常,参数从右至左依次入栈。
- 保存寄存器值:在一些体系结构中,函数调用时需要保存一些寄存器的值,以便在函数执行完毕后能够恢复原始的寄存器状态。
- 帧指针与局部变量压栈:为了支持函数内的局部变量和堆栈的动态分配,通常会在栈上维护一个帧指针(frame pointer),它指向当前函数的栈帧(stack frame)的底部。同时,函数内部定义的局部变量也会在栈上分配空间。
- 执行函数体:一旦函数的参数、局部变量和其他上下文信息都被压入栈中,函数体中的代码开始执行。
函数出栈(函数返回)的过程如下:
- 恢复寄存器值:在一些体系结构中,函数返回时需要恢复之前保存的寄存器的值。
- 释放局部变量和帧指针:函数返回后,会释放函数内部定义的局部变量所占用的栈空间,并将帧指针恢复到上一层函数的栈帧。
- 弹出参数和返回地址:函数返回后,参数和返回地址会从栈中弹出,将控制权返回到调用函数的正确位置。
二 参数入栈顺序
c/c++中规定了函数参数的压栈顺序是从右至左
可以看如下例子:
// person.h
#include<string>
class Person
{
public:
Person(std::string name);
Person(const Person& p);
~Person();
private:
std::string m_name;
};
//------------------------
// person.cpp
#include "person.h"
#include<iostream>
Person::Person(std::string name):m_name(name)
{
std::cout << "Person constructor name: " << m_name << std::endl;
}
Person::~Person()
{
std::cout << "Person destructor name: " << m_name << std::endl;
}
Person::Person(const Person& p)
{
this->m_name = p.m_name;
std::cout << "Person copy constructor name: " << this->m_name << std::endl;
}
// -----------------------
// main.cpp
#include<iostream>
#include "person.h"
void testFunc1(Person p1, Person p2, Person p3)
{
Person pp1("pp1");
Person pp2("pp2");
}
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
Person p1("p1 ----");
Person p2("p2 ----");
Person p3("p3 ----");
std::cout << " --------------" <<std::endl;
testFunc1(p1,p2,p3);
return a.exec();
}
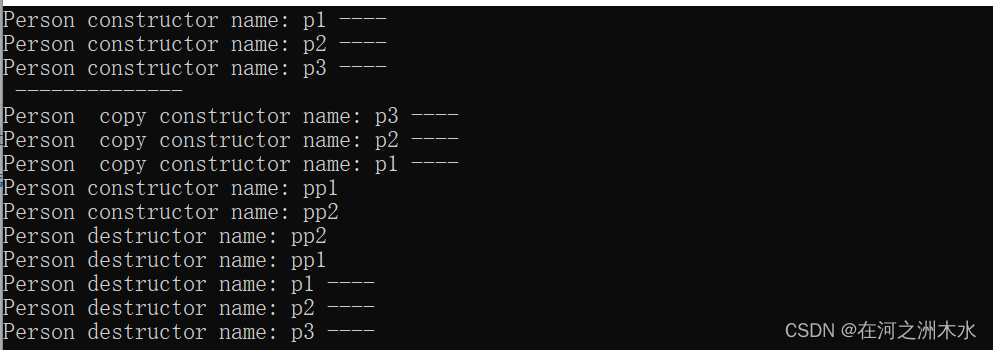
从输出结果可以看出,先执行的最右边的参数 p3 的拷贝构造函数,再依次执行 p2 、p1 参数
参考链接:c/c++参数入栈顺序和参数计算顺序 - 知乎 (zhihu.com)
C++ 函数压栈与出栈 - 知乎