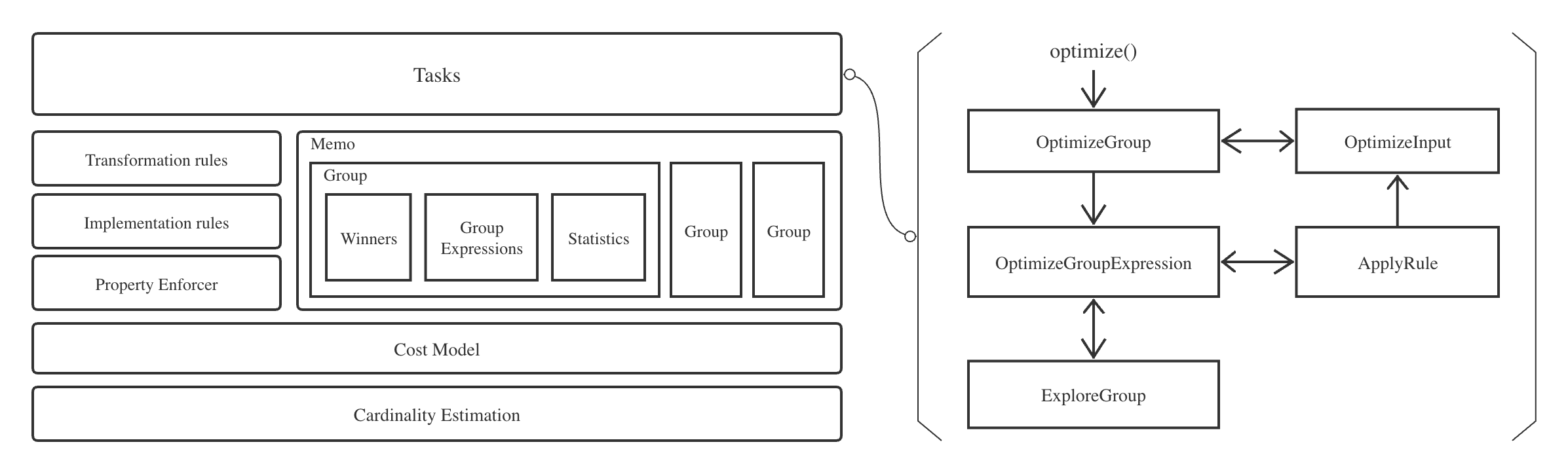
文章目录
- 前言:
- 什么是RAII?
- 指针/智能指针:
- 使用智能指针管理内存资源:
- `unique_ptr`的使用:
- 自定义删除器:
- `shared_ptr`的使用:
- `shared_ptr`指向同一个对象的不同成员:
- 自定义删除函数:
- 循环引用的问题:
- `weak_ptr`引入解决循环引用的问题:
- 指针作为函数参数传递:
- 利用栈特性自动释放锁:
- 手动实现`RAII`管理`mutex`资源:
- C++11中`RAII`管理互斥资源 `lock_guard` :
- c++11的`unique_lock`独占式锁包装器:
- C++14的`shared_lock`共享锁包装器:
- C++17的`scoped_lock`免死锁`RAII`封装器:
- 重载`new`和`delete`运算符:
- 为何要重载`new`和`delete`?
- 重载全局`new`和`delete`运算符:
- 重载类成员`new`和`delete`运算符:
- 分配器:
- `allocator`:
- 自定义分配器:
- 未初始化内存算法:
- 限制栈中创建对象, 限制调用 delete 销毁对象 :
- c++多线程从原理到线程池实现:
- 多线程概用途:
- c++11多线程基础:
- 线程等待与分离:
- `thread`的参数传递:
- 线程入口函数:
- 普通函数:
- 类成员函数:
- lambda表达式:
- `call_once`多线程调用时仅调用一次:
- 多线程通信和同步:
- 线程状态说明:
- 竞争状态和临界区:
- 互斥体和锁:
- `try_lock(std::mutex)`尝试加锁:
- `try_lock_for(std::timed_mutex)`超时锁:
- 递归锁(可重入锁)`recursive_mutex` 和`recursive_timed_mutex` 用于业务组合:
- 共享锁shared_mutex:
- 利用栈自动释放锁:
- 条件变量:
- 不同线程通信方式实现线程池:
- 基于互斥锁和`sleep`实现:
- 基于条件变量实现:
- 智能指针管理和异步获取结果的实现:
- lambda表达式的实现原理:
- c++11中call_once函数的使用:
前言:
- c++程序大部分的问题,都是内存调试的问题。
- c++新特性中,智能指针和内存池使用时,如果使用不熟练也会存在很大问题。
什么是RAII?
RAII(Resource Acquisition is Initialization)资源获取即初始化,即构造函数中申请分配资源,在析构函数中释放资源。因为C++的语言机制保证了,当一个对象创建时自动调用构造函数,当对象超出作用域时会自动调用析构函数。所以在RAII的指导下,我们应该使用类来管理资源并将资源和对象的生命周期绑定,从而可将局部类对象生命周期交由操作系统来管理无需人工介入,避免了忘记释放资源而导致的死锁或内存泄露。
指针/智能指针:
使用智能指针管理内存资源:
智能指针(std::shared_ptr、std::unique_ptr)即RAII最具代表的实现,使用智能指针可以实现自动的内存管理,再也不需要担心忘记delete造成的内存泄漏。毫不夸张的讲,有了智能指针,代码中几乎不需要再出现delete了。
unique_ptr的使用:
独占所有权并在unique_ptr离开作用域时释放该对象的智能指针。
- 管理单个对象,如以 new 分配;
- 管理动态分配的对象数组,如以 new[] 分配;
- 可移动构造
Move Constructible和移动赋值Move Assignable, 但不可拷贝构造Copy Constructible或拷贝赋值Copy Assignable。
注意:两个unique_ptr之间的需要通过move进行移动拷贝或移动复制,不建议用普通指针初始化unique_ptr避免两者中任一一个释放造成另一个非法访问。
自定义删除器:
通过函数表达式或lambda表达式释放unique_ptr指向的内存空间。
#include <iostream>
#include <memory>
#include <functional>
struct Foo
{
Foo() { std::cout << "Foo...\n"; }
~Foo() { std::cout << "~Foo...\n"; }
};
struct D
{
void bar() { std::cout << "Call deleter D::bar()...\n"; }
void operator()(Foo* p) const
{
std::cout << "Call delete for Foo object...\n";
delete p;
}
};
int main()
{
std::unique_ptr<Foo, D> up(new Foo(), D());
D& del = up.get_deleter();
del.bar();
// 注意:这里会去调用`void D::operator()(Foo* p) const`函数,会导致up指向的内存被释放
//,但unique_ptr出作用域还会再释放一次从而导致内存“二次释放”的问题!!!,除非你将它的“所有权剥夺”。
del(up.get());
up.release();
std::cout << "Custom lambda-expression deleter demo\n";
{
std::unique_ptr<Foo, std::function<void(Foo*)>> p(new Foo, [](Foo* ptr) {
std::cout << "destroying from a custom deleter...\n";
delete ptr;
}); // p 占有 Foo 对象所在的内存
} // 调用上述 lambda 并销毁 Foo 对象
}
shared_ptr的使用:
共享所有权(即多个shared_ptr指向同一对象),并在指向的内存块的引用计数为0时,释放该内存块。

- 可拷贝构造
Copy Constructible、可拷贝赋值Copy Assignable; - 数据访问非线程安全;
- shared_ptr 的控制块是线程安全,即引用计数是线程安全的;
shared_ptr指向同一个对象的不同成员:
#include <iostream>
#include <memory>
using namespace std;
class A
{
public:
int index1;
int index2;
};
int main()
{
shared_ptr<A> shptr1(new A);
shared_ptr<int> shptr2(shptr1, &(shptr1->index1));
shared_ptr<int> shptr3(shptr1, &(shptr1->index2));
cout << shptr1.use_count() << endl;
return 0;
}
自定义删除函数:
通过可调用对象(即函数对象、仿函数或lambda表达式)释放shared_ptr指向的内存空间。
#include <memory>
#include <iostream>
struct Foo {
Foo() { std::cout << "Foo...\n"; }
~Foo() { std::cout << "~Foo...\n"; }
};
struct D {
void operator()(Foo* p) const {
std::cout << "Call delete from function object...\n";
delete p;
}
};
void Deleter(Foo* p)
{
std::cout << "Call delete from function object...\n";
delete p;
}
int main()
{
std::shared_ptr<Foo> sh1(new Foo, D());
std::shared_ptr<Foo> sh2(new Foo, [](auto p) {
std::cout << "Call delete from lambda...\n";
delete p;
});
std::shared_ptr<Foo> sh3(new Foo, Deleter);
return 0;
}
循环引用的问题:
#include <iostream>
#include <memory>
using namespace std;
class B;
class A
{
public:
A() { cout << "A::A()" << endl; }
~A() { cout << "A::~A()" << endl; }
shared_ptr<B> b;
};
class B
{
public:
B() { cout << "B::B()" << endl; }
~B() { cout << "B::~B()" << endl; }
shared_ptr<A> a;
};
int main()
{
{
auto aObj = make_shared<A>(); // aObj指向的内存块的引用计数为1
auto bObj = make_shared<B>(); // bObj指向的内存块的引用计数为1
aObj->b = bObj; // bObj指向的内存块的引用计数为2
bObj->a = aObj; // aObj指向的内存块的引用计数为2
cout << aObj.use_count() << ", " << bObj.use_count() << endl;
}
// 此时,出现了问题,aObj和bObj两个指向的内存块的引用计数均为1,并不能使两者指向的内存块释放!!!
return 0;
}
weak_ptr引入解决循环引用的问题:
expired检查被引用的对象是否已删除;lock创建/管理被引用的对象的shared_ptr;
注意::weak_ptr无法直接访问其指向的对象。要访问对象,必须先将weak_ptr转换为shared_ptr。
#include <iostream>
#include <memory>
using namespace std;
/* ............. 使用`weak_ptr`,打破了循环引用,避免了内存泄漏 ............. */
class B;
class A
{
public:
A() { cout << "A::A()" << endl; }
~A() { cout << "A::~A()" << endl; }
void Do()
{
cout <<"A::Do(), b.use_count() = "<< b.use_count() << endl;
if (!b.expired())
{
auto b_ = b.lock(); // 复制一个共享智能指针 引用计数+1
cout << "b指向的内存块未被释放" << endl;
}
cout << "A::Do(), b.use_count() = " << b.use_count() << endl;
}
//shared_ptr<B> b;
weak_ptr<B> b;
};
class B
{
public:
B() { cout << "B::B()" << endl; }
~B() { cout << "B::~B()" << endl; }
//shared_ptr<A> a;
weak_ptr<A> a;
};
int main()
{
auto aObj = make_shared<A>(); // =1
auto bObj = make_shared<B>(); // =1
aObj->b = bObj; // =1
cout << "aObj->b = bObj, bObj.use_count()=" << bObj.use_count() << endl;
aObj->Do();
bObj->a = aObj; // +1 =2
cout << "bObj->a = aObj, aObj.use_count()=" << aObj.use_count() << endl;
return 0;
}
// 当B对象使用weak_ptr指向A对象时,A对象的引用计数不会增加。因此,在aObj和bObj超出作用域时,它们的析构函数会被调用,导致A对象和B对象的引用计数各自减1。
// 1)A对象的引用计数变为0,它将被自动销毁。
// 2)B对象的成员变量a_ptr不再指向任何对象,因此B对象的引用计数也降为0,它也将被自动销毁
指针作为函数参数传递:
-
传递输入内存,需要提供内存大小,并设置为
const;#include <iostream> using namespace std; void func1(const char* data, size_t size) { cout << size << "," << sizeof(data) << endl; } void func2(const char data[]) { cout << sizeof(data) << endl; } template <class Ty, size_t Size> void testMemArr(Ty(&data)[Size]) { cout << sizeof(data) << endl; } int main() { char data[] = "hello"; func1(data, sizeof(data)); func2(data); testMemArr(data); return 0; } -
传递输出内存,也需要提供内存大小作为返回值,防止内存溢出。
#include <iostream> using namespace std; // 返回值:函数内部给其指向的内存空间分配的堆空间的大小 size_t func(char** data) { int size = 1024; *data = new char[size]; return size; } int main() { char* data = nullptr; cout << func(&data) << endl; delete data; data = nullptr; return 0; } -
unique_ptr作为参数和返回值:特别关注作为返回值时,会调用移动构造函数。#include <iostream> #include <memory> using namespace std; unique_ptr<int> func(unique_ptr<int> data) { cout << *data <<endl; unique_ptr<int> data_(new int(10)); // 这里编译器会进行优化,如果返回值支持move则编译器会自动调用move进行移动拷贝构造,否则调用拷贝构造。 return data_; } int main() { unique_ptr<int> data1(new int(12)); auto data2 = func(std::move(data1)); cout << *data2 << endl; return 0; } -
shared_ptr作为参数和返回值:特别关注作为返回值时,会调用移动构造函数。#include <iostream> #include <memory> using namespace std; shared_ptr<int> func(shared_ptr<int> data) { cout << *data <<endl; shared_ptr<int> data_(new int(10)); // 这里编译器会进行优化,如果返回值支持move则编译器会自动调用move进行移动拷贝构造,否则调用拷贝构造。 return data_; } int main() { shared_ptr<int> data1(new int(12)); //auto data2 = func(std::move(data1)); auto data2 = func(data1); cout << *data2 << endl; cout << data1.use_count() << ", " << data2.use_count() << endl; return 0; }
利用栈特性自动释放锁:
手动实现RAII管理mutex资源:
class XMutex
{
public:
XMutex(mutex& mtx) : mtx_(mtx)
{
cout << "Lock" << endl;
mtx_.lock();
}
~XMutex()
{
cout << "UnLock" << endl;
mtx_.unlock();
}
private:
std::mutex& mtx_;
};
static std::mutex mtx;
void TestMtx()
{
// 这里通过XMutex的局部类对象,可实现自动的释放锁,即RAII的思想(局部对象来管理资源,同时局部对象的生命周期由操作系统管理)
XMutex lock(mtx);
// ...
}
C++11中RAII管理互斥资源 lock_guard :
C++11的lock_guard 实现,基于作用域的互斥体所有权包装器。
/* _Mutex可为:mutex互斥锁、shared_mutex共享锁、timed_mutex超时锁、recursive可重入的递归锁 */
template <class _Mutex>
class lock_guard
{
public:
using mutex_type = _Mutex;
explicit lock_guard(_Mutex& _Mtx) : _MyMutex(_Mtx) // construct and lock
{ MyMutex.lock(); }
lock_guard(_Mutex& _Mtx, adopt_lock_t) : _MyMutex(_Mtx) // construct but don't lock
{ }
~lock_guard() noexcept // destructor and unlock a mutex
{ _MyMutex.unlock(); }
// Disable copy construction and copy replication
lock_guard(const lock_guard&) = delete;
lock_guard& operator=(const lock_guard&) = delete;
};
- 通过
{}控制锁的临界区; - C++11中,
adopt_lock类型为adopt_lock_t,假设调用方已拥有互斥的所有权;
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
static mutex mtx;
void ThreadMainMtx(int i)
{
mtx.lock();
{
// 已经拥有锁,不lock
lock_guard<mutex> lock(mtx, adopt_lock);
// 出作用域,释放锁
}
for (;;)
{
{
// lock_guard用来自动管理互斥量的生命周期,在作用域内通过构造函数给关联的互斥量加锁,离开作用域后通过析构函数给关联的互斥量解锁。这有助于避免忘记解锁、死锁等问题出现。
lock_guard<mutex> lock(mtx);
cout << i << "[in]" << endl;
this_thread::sleep_for(1000ms);
}
// 等待内核调度其他线程抢占资源
this_thread::sleep_for(10ms); // 等待10ms是为了避免该线程一直占用CPU资源,导致其他线程没有机会执行
}
}
int main(int argc, char* argv[])
{
for (int i = 0; i < 10; ++i)
{
thread th(ThreadMainMtx, i);
th.detach();
}
while (1)
{ } // 避免主线程退出,造成子线程获取全局静态锁mtx失败,而导致的程序崩溃。
return 0;
}
c++11的unique_lock独占式锁包装器:
C++11的unique_lock实现,可移动的互斥体所有权包装器。
template<class _Mutex>
class unique_lock
{
public:
typedef _Mutex mutex_type;
// default construct
unique_lock() : _Pmtx(nullptr), _Owns(false) noexcept
{ }
// construct and lock
explicit unique_lock(_Mutex& _Mtx) : _Pmtx(_STD addressof(_Mtx)), _Owns(true)
{
_Pmtx->lock();
}
// construct and assume already locked
unique_lock(_Mutex& _Mtx, adopt_lock_t) : _Pmtx(_STD addressof(_Mtx)), _Owns(true)
{ }
// construct but don't lock
unique_lock(_Mutex& _Mtx, defer_lock_t) : _Pmtx(_STD addressof(_Mtx)), _Owns(false) noexcept
{ }
// construct and try to lock
unique_lock(_Mutex& _Mtx, try_to_lock_t) : _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock())
{ }
// construct and lock with timeout
/*template<class _Rep, class _Period>
unique_lock(_Mutex& _Mtx, const chrono::duration<_Rep, _Period>& _Rel_time) : _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock_for(_Rel_time)) */
template<class _Clock, class _Duration>
unique_lock(_Mutex& _Mtx, const chrono::time_point<_Clock, _Duration>& _Abs_time) : _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock_until(_Abs_time))
{ }
// try to lock until _Abs_time
unique_lock(_Mutex& _Mtx, const xtime *_Abs_time) : _Pmtx(_STD addressof(_Mtx)), _Owns(false)
{
_Owns = _Pmtx->try_lock_until(_Abs_time);
}
unique_lock(unique_lock&& _Other) : _Pmtx(_Other._Pmtx), _Owns(_Other._Owns) noexcept
{
_Other._Pmtx = nullptr;
_Other._Owns = false;
}
unique_lock& operator=(unique_lock&& _Other)
{
// different, move contents
if (this != _STD addressof(_Other))
{
if (_Owns)
{
_Pmtx->unlock();
}
_Pmtx = _Other._Pmtx;
_Owns = _Other._Owns;
_Other._Pmtx = nullptr;
_Other._Owns = false;
}
return (*this);
}
// clean up
~unique_lock() noexcept
{
if (_Owns)
{
_Pmtx->unlock();
}
}
// Disable Copy construction and Copy assignment
unique_lock(const unique_lock&) = delete;
unique_lock& operator=(const unique_lock&) = delete;
// lock the mutex
void lock()
{
_Validate();
_Pmtx->lock();
_Owns = true;
}
// try to unlock the mutex
void unlock()
{
if (!_Pmtx || !_Owns)
{
_THROW(system_error(_STD make_error_code(errc::operation_not_permitted)));
}
_Pmtx->unlock();
_Owns = false;
}
// try to lock the mutex
_NODISCARD bool try_lock()
{
_Validate();
_Owns = _Pmtx->try_lock();
return (_Owns);
}
// try to lock mutex for _Rel_time
template<class _Rep, class _Period>
_NODISCARD bool try_lock_for(const chrono::duration<_Rep, _Period>& _Rel_time)
{
_Validate();
_Owns = _Pmtx->try_lock_for(_Rel_time);
return (_Owns);
}
/*// try to lock mutex until _Abs_time
template<class _Clock, class _Duration>
_NODISCARD bool try_lock_until(const chrono::time_point<_Clock, _Duration>& _Abs_time)*/
// try to lock the mutex until _Abs_time
_NODISCARD bool try_lock_until(const xtime *_Abs_time)
{
_Validate();
_Owns = _Pmtx->try_lock_until(_Abs_time);
return (_Owns);
}
// swap with _Other
void swap(unique_lock& _Other) noexcept
{
_STD swap(_Pmtx, _Other._Pmtx);
_STD swap(_Owns, _Other._Owns);
}
// disconnect
_Mutex* release() noexcept
{
_Mutex *_Res = _Pmtx;
_Pmtx = nullptr;
_Owns = false;
return (_Res);
}
// return true if this object owns the lock
/*_NODISCARD bool owns_lock() const noexcept*/
explicit operator bool() const noexcept
{
return (_Owns);
}
// return pointer to managed mutex
_NODISCARD _Mutex *mutex() const noexcept
{
return (_Pmtx);
}
private:
_Mutex* _Pmtx;
bool _Owns;
// check if the mutex can be locked
void _Validate() const
{
if (!_Pmtx)
{
_THROW(system_error(_STD make_error_code(errc::operation_not_permitted)));
}
if (_Owns)
{
_THROW(system_error(_STD make_error_code(errc::resource_deadlock_would_occur)));
}
}
};
-
支持临时释放锁
unlock; -
支持
adopt_lock(已拥有锁,不加锁,出栈区会释放);{ mtx.lock(); // ... // 已拥有锁,不加锁,出栈区解锁 unique_lock<mutex> lock(mtx, adopt_lock); // ... } -
支持
defer_lock(延后加锁,不拥有,出栈区不释放);{ // 延迟加锁,不拥有锁,出栈区不释放 unique_lock<mutex> lock(mtx, defer_lock); // ... // 加锁,退出栈区解锁 lock.lock(); } -
支持
try_to_lock尝试获得互斥的所有权而不阻塞 ,获取失败退出栈区不会释放;通过
owns_lock()函数判断,是否加锁成功;staticmutex mtx; { // ... // 尝试加锁,不阻塞,失败不拥有锁 unique_lock<mutex> lock(mtx, try_to_lock); if (lock.owns_lock()) { cout << "owns lock" << endl; } else { cout << "not owns lock" << endl; } // ... } -
支持超时参数,超时不拥有锁;
C++14的shared_lock共享锁包装器:
C++14的shared_lock实现,可移动的“共享”互斥体所有权封装器。
template<class _Mutex> // shareable lock <==> std:shared_mutex
class shared_lock
{
public:
typedef _Mutex mutex_type;
// default construct
shared_lock() : _Pmtx(nullptr), _Owns(false) noexcept
{ }
// construct with mutex and lock shared
explicit shared_lock(mutex_type& _Mtx) : _Pmtx(_STD addressof(_Mtx)), _Owns(true)
{
_Mtx.lock_shared();
}
// construct with unlocked mutex
shared_lock(mutex_type& _Mtx, defer_lock_t) : _Pmtx(_STD addressof(_Mtx)), _Owns(false) noexcept
{ }
// construct with mutex and try to lock shared
shared_lock(mutex_type& _Mtx, try_to_lock_t) : _Pmtx(_STD addressof(_Mtx)), _Owns(_Mtx.try_lock_shared())
{ }
// construct with mutex and adopt ownership
shared_lock(mutex_type& _Mtx, adopt_lock_t) : _Pmtx(_STD addressof(_Mtx)), _Owns(true)
{ }
/*// construct with mutex and try to lock for relative time
template<class _Rep, class _Period>
shared_lock(mutex_type& _Mtx, const chrono::duration<_Rep, _Period>& _Rel_time) : _Pmtx(_STD addressof(_Mtx)), _Owns(_Mtx.try_lock_shared_for(_Rel_time))*/
// construct with mutex and try to lock until absolute time
template<class _Clock, class _Duration>
shared_lock(mutex_type& _Mtx, const chrono::time_point<_Clock, _Duration>& _Abs_time) : _Pmtx(_STD addressof(_Mtx)), _Owns(_Mtx.try_lock_shared_until(_Abs_time))
{ }
// destroy the lock
~shared_lock() noexcept
{
if (_Owns)
{
_Pmtx->unlock_shared();
}
}
// construct by moving _Other
shared_lock(shared_lock&& _Other) : _Pmtx(_Other._Pmtx), _Owns(_Other._Owns) noexcept
{
_Other._Pmtx = nullptr;
_Other._Owns = false;
}
// copy by moving _Right
shared_lock& operator=(shared_lock&& _Right) noexcept
{
if (_Owns)
{
_Pmtx->unlock_shared();
}
_Pmtx = _Right._Pmtx;
_Owns = _Right._Owns;
_Right._Pmtx = nullptr;
_Right._Owns = false;
return (*this);
}
// Disable Copy construct and Copy
shared_lock(const shared_lock&) = delete;
shared_lock& operator=(const shared_lock&) = delete;
// lock the mutex
void lock()
{
_Validate();
_Pmtx->lock_shared();
_Owns = true;
}
// try to lock the mutex
_NODISCARD bool try_lock()
{
_Validate();
_Owns = _Pmtx->try_lock_shared();
return (_Owns);
}
/*// try to lock the mutex for _Rel_time
template<class _Rep, class _Period>
_NODISCARD bool try_lock_for(const chrono::duration<_Rep, _Period>& _Rel_time)*/
// try to lock the mutex until _Abs_time
template<class _Clock, class _Duration>
_NODISCARD bool try_lock_until(const chrono::time_point<_Clock, _Duration>& _Abs_time)
{
_Validate();
_Owns = _Pmtx->try_lock_shared_for(_Rel_time);
return (_Owns);
}
void unlock()
{ // try to unlock the mutex
if (!_Pmtx || !_Owns)
{
_THROW(system_error(_STD make_error_code(errc::operation_not_permitted)));
}
_Pmtx->unlock_shared();
_Owns = false;
}
// MUTATE
void swap(shared_lock& _Right) noexcept
{ // swap with _Right
_STD swap(_Pmtx, _Right._Pmtx);
_STD swap(_Owns, _Right._Owns);
}
// release the mutex
mutex_type* release() noexcept
{
_Mutex *_Res = _Pmtx;
_Pmtx = nullptr;
_Owns = false;
return (_Res);
}
// return true if this object owns the lock
_NODISCARD bool owns_lock() const noexcept
{
return (_Owns);
}
explicit operator bool() const noexcept
{
return (_Owns);
}
// return pointer to managed mutex
_NODISCARD mutex_type *mutex() const noexcept
{
return (_Pmtx);
}
private:
_Mutex* _Pmtx;
bool _Owns;
// check if the mutex can be locked
void _Validate() const
{
if (!_Pmtx)
{
_THROW(system_error(_STD make_error_code(errc::operation_not_permitted)));
}
if (_Owns)
{
_THROW(system_error(_STD make_error_code(errc::resource_deadlock_would_occur)));
}
}
};
// 共享锁
static shared_timed_mutex st_mtx;
{
// ...
// 读取锁,即为共享锁
{
// 调用共享锁
shared_lock<shared_timed_mutex> lock(st_mtx);
// ... read data ...
// 出栈区,释放共享锁
}
// 写入锁,即为互斥锁
{
unique_lock<shared_timed_mutex> lock(st_mtx);
// ... write data ...
}
// ...
}
C++17的scoped_lock免死锁RAII封装器:
C++17的scoped_lock实现,用于多个互斥体的免死锁 RAII 封装器,类似lock。
// class with destructor that unlocks mutexes
template<class... _Mutexes>
class scoped_lock
{
public:
// construct and lock
explicit scoped_lock(_Mutexes&... _Mtxes) : _MyMutexes(_Mtxes...)
{
_STD lock(_Mtxes...);
}
// construct but don't lock
explicit scoped_lock(adopt_lock_t, _Mutexes&... _Mtxes) : _MyMutexes(_Mtxes...)
{ }
// unlock all
~scoped_lock() noexcept
{
_For_each_tuple_element(_MyMutexes, [](auto& _Mutex) noexcept { _Mutex.unlock(); });
}
scoped_lock(const scoped_lock&) = delete;
scoped_lock& operator=(const scoped_lock&) = delete;
private:
tuple<_Mutexes&...> _MyMutexes;
};
// specialization for a single mutex
template<class _Mutex>
class scoped_lock<_Mutex>
{
public:
typedef _Mutex mutex_type;
// construct and lock
explicit scoped_lock(_Mutex& _Mtx) : _MyMutex(_Mtx)
{
_MyMutex.lock();
}
// construct but don't lock
explicit scoped_lock(adopt_lock_t, _Mutex& _Mtx) : _MyMutex(_Mtx)
{ }
// unlock
~scoped_lock() noexcept
{
_MyMutex.unlock();
}
scoped_lock(const scoped_lock&) = delete;
scoped_lock& operator=(const scoped_lock&) = delete;
private:
_Mutex& _MyMutex;
};
// specialization for no mutexes
template<>
class scoped_lock<>
{
public:
explicit scoped_lock()
{ /* no effects */ }
explicit scoped_lock(adopt_lock_t)
{ /* no effects */ }
~scoped_lock() noexcept
{ /* no effects */ }
scoped_lock(const scoped_lock&) = delete;
scoped_lock& operator=(const scoped_lock&) = delete;
};
死锁的情况:
#include <iostream>
#include <mutex>
#include <thread>
using namespace std;
static mutex mtx1, mtx2;
// testThread1和testThread2线程中,加锁顺序不一致,导致出现了“死锁”
void testThread1()
{
mtx1.lock();
cout << this_thread::get_id() << ", mtx1 has been locked" << endl;
mtx2.lock();
cout << this_thread::get_id() << ", mtx2 has been locked " << endl;
// ...
mtx1.unlock();
mtx2.unlock();
}
void testThread2()
{
mtx2.lock();
cout << this_thread::get_id() << ", mtx2 has been locked" << endl;
mtx1.lock();
cout << this_thread::get_id() << ", mtx1 has been locked " << endl;
// ...
mtx2.unlock();
mtx1.unlock();
}
int main()
{
thread th1(testThread1);
thread th2(testThread2);
th1.join();
th2.join();
return 0;
}
C++17的scoped_lock实现,用于多个互斥体的免死锁 RAII 封装器,类似lock。
// c++17的scoped_lock,类似于c++11的lock,保证了锁顺序的一致,避免“死锁”
static mutex mtx1, mtx2;
// C++11 lock(...MutexType) 需要手动释放锁资源
{
lock(mtx1, mtx2);
mtx1.unlock();
mtx2.unlock();
}
// C++17 scoped_lock(...MutexType) 可实现RAII管理资源,即局部对象(局部对象由操作系统管理)来管理资源
{
scoped_lock lock(mtx1, mtx2);
}
重载new和delete运算符:
为何要重载new和delete?
- 监测内存创建销毁;
- 统计和监控泄漏;
- 内存对齐的处理;
- 特定应用:例如多进程内存共享;
重载全局new和delete运算符:
#include <iostream>
using namespace std;
void* operator new(size_t size)
{
cout << "perator new: " << size << " Bytes" << endl;
void* mem = malloc(size);
if (!mem)
{
throw std::bad_alloc();
}
return mem;
}
void* operator new [](size_t size)
{
cout << "perator new [] : " << size << " Bytes" << endl;
void* mem = malloc(size);
if (!mem)
{
throw std::bad_alloc();
}
return mem;
}
void operator delete(void* ptr)
{
std::cout << "operator delete " << std::endl;
std::free(ptr);
}
void operator delete[](void* ptr)
{
std::cout << "operator delete []" << std::endl;
std::free(ptr); // 因malloc时分配的是连续的内存空间,故直接free即可
}
class A
{
public:
A() { cout << "A::A()" << endl; }
~A() { cout << "A::~A()" << endl; }
int val;
};
int main()
{
A* aPtr = new A;
delete aPtr; aPtr = nullptr;
int* IntegerPtr = new int;
delete IntegerPtr; IntegerPtr = nullptr;
A* aArr = new A[2];
delete[] aArr; aArr = nullptr;
int* IntegerArr = new int[2];
delete[] IntegerArr; IntegerArr = nullptr;
return 0;
}
重载类成员new和delete运算符:
#include <iostream>
using namespace std;
class A
{
public:
A() { cout << "A::A()" << endl; }
~A() { cout << "A::~A()" << endl; }
void* operator new(size_t size)
{
cout << "perator new: " << size << " Bytes" << endl;
void* mem = malloc(size);
if (!mem)
{
throw std::bad_alloc();
}
return mem;
}
void* operator new [](size_t size)
{
cout << "perator new [] : " << size << " Bytes" << endl;
void* mem = malloc(size);
if (!mem)
{
throw std::bad_alloc();
}
return mem;
}
void operator delete(void* ptr)
{
std::cout << "operator delete " << std::endl;
std::free(ptr);
}
void operator delete[](void* ptr)
{
std::cout << "operator delete []" << std::endl;
std::free(ptr); // 因malloc时分配的是连续的内存空间,故直接free即可
}
private:
int val;
};
int main()
{
A* aPtr = new A;
delete aPtr; aPtr = nullptr;
int* IntegerPtr = new int;
delete IntegerPtr; IntegerPtr = nullptr;
A* aArr = new A[2];
delete[] aArr; aArr = nullptr;
int* IntegerArr = new int[2];
delete[] IntegerArr; IntegerArr = nullptr;
return 0;
}
放置 placement new 和 delete,new 的空间指向已有的地址中
- 普通
new申请空间是从堆中分配空间,一些特殊的需求要在已分配的空间中创建对象,就可以使用放置placement new操作; placement new生成对象,既可以在栈上也可以在堆上;placement new生成对象销毁,要手动调用析构函数;
#include <iostream>
using namespace std;
class A
{
public:
A() { cout << "A::A()" << endl; }
~A() { cout << "A::~A()" << endl; }
// placement new
void* operator new (size_t size, void* ptr)
{
cout << "placement new" << endl;
return ptr;
}
private:
int val;
};
int main()
{
/* ... placement new 的核心思想:直接使用已分配好的内存空间 ... */
int buf1[1024] = { 0 };
A* a1 = new(buf1) A; // placement new 初始化栈区的内存
cout << "buf1 addr:" << buf1 << endl;
cout << "a1 addr:" << a1 << endl;
a1->~A(); // 栈区的内存不能手动释放,需要自己调用析构函数,释放后系统会回收栈区内存
int* buf2 = new int[1024]{ 0 };
auto a2 = new(buf2) A; // placement new 初始化堆区的内存
delete a2;
return 0;
}
分配器:
使用allocator将内存分配、对象构造分离开,修改空间申请到内存池。
使用过程中,可以先分配内存,对象不构造,使用时再构造。

allocator:
- 分配器用于实现容器算法时,将其与存储细节隔离从而解耦合;
- 分配器将对象的内存分配和构造分离,提供存储分配与释放的标准方法;
- STL 实现了一个标准的分配器 allocator;
#include <iostream>
using namespace std;
class XData
{
public:
XData()
{
cout << "Create XData" << endl;
}
~XData()
{
cout << "Drop XData" << endl;
}
};
int main(int argc,char *argv[])
{
allocator<XData> xdata_allco;
int size = 3;
// 分配对象空间,但不调用构造
auto dataArr = xdata_allco.allocate(size);
for (int i = 0; i < size; i++)
{
/*
// allocator_traits 类模板提供访问分配器 (Allocator) 各种属性的标准化方式
template<class T, class... Args>
static void construct(Alloc& a, T* p, Args&&... args); (C++11 起 / C++20 前)
template<class T, class... Args>
static void deconstruct(Alloc& a, T* p); (C++11 起 / C++20 前)
*/
// 调用构造函数
allocator_traits<decltype(xdata_allco)>::construct(xdata_allco, &dataArr[i]);
// 调用析构函数
allocator_traits<decltype(xdata_allco)>::destroy(xdata_allco, &dataArr[i]);
}
// 释放对象内存,但不调用析构
xdata_allco.deallocate(dataArr, size);
return 0;
}
自定义分配器:
- 可实现
vector数据直接到数据库、共享内存或者文件中的存取、内存泄漏探测,预分配对象存储、内存池; - 演示自定义 vector 和 list 分配器,并分析其源码;
#include <iostream>
#include <vector>
using namespace std;
class A
{
public:
A() : val(0) { cout << "A::A()" << endl; }
~A() { cout << "A::~A()" << endl; }
A(const A& a) { cout << "A::A(const A& a)" << endl; }
private:
int val;
};
template <typename Ty>
class MyAllocator
{
public:
using value_type = Ty;
MyAllocator() {}
template <typename OtherTy>
MyAllocator(const MyAllocator<OtherTy>&)
{ cout << "MyAllocator::Allocator()" << endl; }
void deallocate(Ty* const ptr, size_t count)
{
cout << "Deallocate " << sizeof(Ty) * count << " bytes." << endl;
free(ptr);
}
Ty* allocate(size_t count)
{
cout << "count : " << count << ", " << typeid(Ty).name() << endl;
cout << "Allocate " << sizeof(Ty) * count << " bytes." << endl;
return static_cast<Ty*>(malloc(sizeof(Ty) * count));
}
};
int main()
{
vector<A, MyAllocator<A>> vctor;
vctor.push_back(A());
vctor.push_back(A());
vctor.push_back(A());
return 0;
}
未初始化内存算法:
uninitialized_copy将范围内的对象拷贝构造到未初始化的内存区域,避免内部有堆栈空间时可能产生问题。
#include <iostream>
#include <memory>
#include <cstring>
using namespace std;
class XData
{
public:
XData() : index(-1) { cout << "XData::XData()" << endl; }
~XData() { cout << "XData::~XData(), " << index << endl; }
XData(const XData& d)
{
this->index = d.index;
cout << "XData::XData(const XData& d), " << index << endl;
}
XData& operator=(const XData& d)
{
this->index = d.index;
cout << "XData& XData::operator=(const XData& d), " << index << endl;
return *this;
}
int index;
};
int main(int argc, char* argv[])
{
XData datas[3];
unsigned char buf[1024] = { 0 };
cout << "============memcpy============" << endl;
memcpy(buf, &datas, sizeof(datas));
cout<< "==============copy=============" << endl;
std::copy(std::begin(datas), std::end(datas), (XData*)(buf)); // 内部会调用XData的拷贝复制运算符
cout << "============uninitialized_copy=========" << endl;
uninitialized_copy(std::begin(datas), std::end(datas), (XData*)buf); // 内部会调用XData的拷贝构造函数
return 0;
}
限制栈中创建对象, 限制调用 delete 销毁对象 :
class TestMem
{
public:
static TestMem* Create()
{
return new TestMem();
}
static void Drop(TestMem* tm)
{
delete tm;
}
private:
TestMem() { cout << "TestMem::TestMem()" << endl; }
~TestMem() { cout << "TestMem::~TestMem()" << endl; }
};
int main()
{
// 限制栈中创建对象,限制调用 delete 销毁对象
TestMem* tm = TestMem::Create();
TestMem::Drop(tm);
return 0;
}
c++多线程从原理到线程池实现:
多线程概用途:
- 任务分解:耗时操作的任务分解;
- 数据分解:充分利用多核CPU处理数据;
- 数据流分解:读写分离,解耦设计;
c++11多线程基础:
线程等待与分离:
一般如果主线程和子线程通过detach设置了分离状态,则可能主线程先退出从而导致子线程崩溃。
- 原因:主线程负责管理程序的资源,如内存分配、文件句柄等,主线程的导致这些资源的释放,从而导致子线程非法的访问而崩溃。
- 解决方方法:主线程中
join()阻塞等待子线程的结束。
thread的参数传递:
// C++11 std::thread源码
class thread
{
// .....
thread() noexcept : _Thr{} {}
template <class _Fn, class... _Args, enable_if_t<!is_same_v<_Remove_cvref_t<_Fn>, thread>, int> = 0>
explicit thread(_Fn&& _Fx, _Args&&... _Ax) {
using _Tuple = tuple<decay_t<_Fn>, decay_t<_Args>...>;
auto _Decay_copied = _STD make_unique<_Tuple>(_STD forward<_Fn>(_Fx), STD forward<_Args>(_Ax)...);
constexpr auto _Invoker_proc = _Get_invoke<_Tuple>(make_index_sequence<1 + sizeof...(_Args)>{});
Thr._Hnd = reinterpret_cast<void*>(_CSTD _beginthreadex(nullptr, 0, _Invoker_proc, Decay_copied.get(), 0, &_Thr._Id));
}
~thread() noexcept {
if (joinable()) {
STD terminate();
}
}
};
参数传递的一些坑:
- 传递空间已经销毁
- 多线程共享访问一块空间
- 传递的指针变量的生命周期小于线程
#include <iostream>
#include <thread>
using namespace std;
struct TPara
{
string name;
};
// 子线程入口函数
void ThreadMain(TPara* str)
{
this_thread::sleep_for(1000ms);
// str已经销毁
cout << " 进入子线程" << std::this_thread::get_id() << ", ";
cout << static_cast<string>(str->name).c_str() << endl;
}
void ThreadMain(TPara& str)
{
this_thread::sleep_for(1000ms);
// str已经销毁
cout << " 进入子线程" << std::this_thread::get_id() << ", ";
cout << static_cast<string>(str.name).c_str() << endl;
}
// 主线程入口
int main(int argc, char* argv[])
{
// 创建并启动子线程, 进入线程函数
thread th;
{
TPara a;
a.name = "test string in A";
th = thread(ThreadMain, std::ref(a)); // th = thread(ThreadMain, &a);
//th.join();
} // 退出作用域a对象被销毁,导致子线程的无法访问。
cout << "等待子线程退出" << endl;
th.join();
cout << "等待子线程返回" << endl;
return 0;
}
线程入口函数:
普通函数:
这里就正常调用,注意传递参数的生命周期的问题就行。
类成员函数:
#include <iostream>
#include <thread>
using namespace std;
class MyThread
{
public:
void Main()
{
cout << "MyThread Main " <<name<< endl;
}
string name;
};
int main()
{
MyThread myth;
myth.name = "test mythread";
thread th(&MyThread::Main,&myth);
th.join();
return 0;
}
#include <iostream>
#include <thread>
using namespace std;
// 封装一个抽象的线程基类
class XThread
{
public:
XThread() : is_exit_(false)
{}
// 启动线程
void Start()
{
is_exit_ = false;
th_ = thread(&XThread::Main, this);
}
// 设置阻塞等待线程退出
void Wait()
{
if (th_.joinable())
{
th_.join();
}
}
// 设置退出标志并等待
void Stop()
{
is_exit_ = true;
Wait();
}
bool is_exit() { return is_exit_; }
private:
virtual void Main() = 0;
bool is_exit_;
thread th_;
};
class TestXThread : public XThread
{
public:
virtual void Main() override
{
cout << "........ subthread begin ........" << endl;
while (!is_exit())
{
std::this_thread::sleep_for(1s);
cout << "+" << flush;
}
cout << "\n........ subthread end ........" << endl;
}
};
int main()
{
TestXThread testXThread;
testXThread.Start();
std::this_thread::sleep_for(10s);
testXThread.Stop(); // 主线程通知子线程结束,并阻塞等待其结束
return 0;
}
lambda表达式:
基本格式:[捕捉列表] (参数) mutable -> 返回值类型 {函数体}
// 线程函数为 lambda 表达式,并捕获外部变量和传递参数
int val1 = 0;
thread th([&val1](int val2) {
std::cout << "subthread begin --> " << val1 << ", " << val2 << std::endl;
}, 123);
// 线程入口为类成员 lambda 函数
class A
{
public:
void start()
{
std::thread th([&this]() {
cout << "subthread begin --> " << a << endl;
});
th.join();
}
int a;
}
call_once多线程调用时仅调用一次:
c++11标准库中,新引入的call_once函数可确保多线程环境下某个“函数”或“可调用对象”只被执行一次。
#include <iostream>
#include <mutex>
#include <thread>
void out()
{
std::cout << "void out()" << std::endl;
}
void CallOnce()
{
std::once_flag initFlag;
std::call_once(initFlag, out);
}
int main()
{
for (int i = 0; i < 10; ++i)
{
std::thread th(CallOnce);
th.join();
}
return 0;
}
多线程通信和同步:
线程状态说明:

- 初始化(Init):该线程正在被创建。
- 就绪(Ready):该线程在就绪列表中,等待 CPU 调度。
- 运行(Running):该线程正在运行。
- 阻塞(Blocked):该线程被阻塞挂起。Blocked 状态包括:pend(锁、事件、信号量等阻塞)、suspend(主动 pend)、delay(延时阻塞)、 pendtime(因为锁、事件、信号量时间等超时等待)。
- 退出(Exit):该线程运行结束,等待父线程回收其控制块资源。
竞争状态和临界区:
竞争状态(Race Condition):多线程同时读写共享数据;
临界区(Critical Section):多线程同时读写共享数据的代码片段;
原则:避免竞争状态策略, 对临界区进行保护,同时只能有一个线程进入临界区。
互斥体和锁:
try_lock(std::mutex)尝试加锁:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
static mutex mtx;
void ThreadMainMtx(int i)
{
/*for (;;)
{
{
// lock_guard用来自动管理互斥量的生命周期,在作用域内通过构造函数给关联的互斥量加锁,离开作用域后通过析构函数给关联的互斥量解锁。这有助于避免忘记解锁、死锁等问题出现。
lock_guard<mutex> lock(mtx);
//mtx.lock(); // 尝试获取锁,获取不到则阻塞等待
cout << i << "[in]" << endl;
this_thread::sleep_for(1000ms);
//mtx.unlock();
}
this_thread::sleep_for(10ms); // 这里等待10ms是为了避免该线程一直占用CPU资源,导致其他线程没有机会执行。
// 等待内核调度其他线程抢占资源。
}*/
for (;;)
{
// try_lock尝试获取锁,即显示多线程竞争锁mtx的过程
if (!mtx.try_lock())
{
cout << ".";
this_thread::sleep_for(10ms); // 这里注意try_lock有一定的开销,故一般尝试获取锁失败后,需要等一段时间才能再次获取,避免资源的无意义的消耗。
continue;
}
cout << i << "[in]" << endl;
mtx.unlock();
this_thread::sleep_for(10ms); // 这里等待10ms是为了避免该线程一直占用CPU资源,导致其他线程没有机会执行。
// 等待内核调度其他线程抢占资源。
}
}
int main(int argc, char* argv[])
{
for (int i = 0; i < 10; ++i)
{
thread th(ThreadMainMtx, i);
th.detach();
}
while (1)
{ } // 避免主线程退出,造成子线程获取全局静态锁mtx失败,而导致的程序崩溃。
return 0;
}
try_lock_for(std::timed_mutex)超时锁:
c++11超时锁通常指,在指定的时间内无法获取timed_mutex/recursive_timed_mutex锁,则放弃锁定操作,防止线程在等待锁时无限阻塞,从而影响程序的响应速度。
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
using namespace std;
// 超时锁:主要是为了避免长时间死锁
static timed_mutex t_mtx;
void ThreadMainTimedMtx(int i)
{
for (;;)
{
/* 在1000ms内,不断的尝试加锁,一旦超时后仍未获取到锁则立即报false,否则true */
if (!t_mtx.try_lock_for(chrono::milliseconds(1000)))
{
cout << i << "[try_lock_for] timeout" << endl;
/* 可记录锁获取情况,多次超时,可以记录日志,获取错误情况 */
continue;
}
cout << i << "[in]" << endl;
this_thread::sleep_for(2000ms);
t_mtx.unlock();
this_thread::sleep_for(10ms); /* 这里等待10ms是为了避免该线程一直占用CPU资源,导致其他线程没有机会执行 */
}
}
int main(int argc, char* argv[])
{
for (int i = 0; i < 10; ++i)
{
thread th(ThreadMainTimedMtx, i);
th.detach();
}
while (1)
{ } // 避免主线程退出,造成子线程获取全局静态锁mtx失败,而导致的程序崩溃。
return 0;
}
递归锁(可重入锁)recursive_mutex 和recursive_timed_mutex 用于业务组合:
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
using namespace std;
/* 递归锁(可重入)recursive_mutex 和 recursive_timed_mutex:同一个线程中的同一把锁可以锁多次。避免了一些不必要的死锁 */
static std::recursive_mutex r_mtx;
void Task1()
{
r_mtx.lock();
// 组合业务 用到同一个锁 避免出现死锁
cout << "task1 [in]" << endl;
r_mtx.unlock();
}
void Task2()
{
r_mtx.lock();
// 组合业务 用到同一个锁 避免出现死锁
cout << "task2 [in]" << endl;
r_mtx.unlock();
}
void ThreadMainRec(int i)
{
for (;;)
{
r_mtx.lock();
/* 组合业务 用到同一个锁 */
/* 这里不解锁直接进入该Task1、Task2函数,避免了其他线程抢占锁 */
Task1(); Task2();
cout << i << "[in]" << endl;
this_thread::sleep_for(2000ms);
r_mtx.unlock();
this_thread::sleep_for(10ms); /* 这里等待10ms是为了避免该线程一直占用CPU资源,导致其他线程没有机会执行 */
}
}
int main(int argc, char *argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(ThreadMainRec, i);
th.detach();
}
while (true)
{ } // 避免主线程退出,造成子线程获取全局静态锁mtx失败,而导致的程序崩溃。
return 0;
}
共享锁shared_mutex:
在很多业务场景中,读取只能有一个线程进入,则没有充分利用 cpu 资源。共享锁可以解决这种问题,如下两种共享锁:
- c++14 共享超时互斥锁
shared_timed_mutex - c++17 共享互斥
shared_mutex

#include <iostream>
#include <thread>
#include <shared_mutex>
#include <chrono>
using namespace std;
shared_mutex s_mtx; // C++14
shared_timed_mutex st_mtx; // C++17
void ThreadWrite(int i)
{
for (;;)
{
st_mtx.lock_shared();
// 读数据
st_mtx.unlock_shared();
st_mtx.lock();
cout << i << " Write" << endl;
this_thread::sleep_for(100ms);
st_mtx.unlock();
this_thread::sleep_for(3000ms); /* 这里等待3000ms是为了避免该线程一直占用CPU资源,导致其他线程没有机会执行 */
}
}
void ThreadRead(int i)
{
for(;;)
{
st_mtx.lock_shared();
cout << i << " Read" << endl;
this_thread::sleep_for(500ms);
stmux.unlock_shared();
this_thread::sleep_for(50ms); /* 这里等待50ms是为了避免该线程一直占用CPU资源,导致其他线程没有机会执行 */
}
}
int main(int argc,char *argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(ThreadWrite, i + 1);
th.detach();
}
this_thread::sleep_for(100ms);
for (int i = 0; i < 3; i++)
{
thread th(ThreadRead, i + 1);
th.detach();
}
while (true)
{ } // 避免主线程退出,造成子线程获取全局静态锁mtx失败,而导致的程序崩溃。
return 0;
}
利用栈自动释放锁:
详见“什么是RAII?”。
条件变量:
-
生产者-消费者模型生产者和消费者共享资源变量(list队列);
-
生产者生产一个产品,通知消费者消费;
std::condition_variable cond; std::mutex mtx; std::list<std::string> msgs_; { unique_lock<mutex> lock(mtx); msgs_.push_back(data); lock.unlock(); cond.notify_one(); // 通知处于wait状态的一个线程 //cond.notify_all(); // 通知所有处于wait状态的线程 } -
消费者阻塞等待信号-获取信号后消费产品(取出list队列中数据);
// wait for signal void wait(unique_lock<mutex>& _Lck) { // Nothing to do to comply with LWG‐2135 because std::mutex lock/unlock are nothrow Check_C_return(_Cnd_wait(_Mycnd(), _Lck.mutex()‐>_Mymtx())); } // wait for signal and test predicate template <class _Predicate> void wait(unique_lock<mutex>& _Lck, _Predicate _Pred) { while (!_Pred()) { wait(_Lck); } }{ unique_lock<mutex> lock(mtx); // 解锁lock,并阻塞等待 notify_one / notify_all 通知 // 接收到通知会再次获取锁,也就是说如果此时mux资源被占用,wait函数会阻塞 /*while (msgs_.empty()) { cond.wait(mtx); }*/ cond.wait(mtx, [](this)->bool { return !msgs_.empty(); }); // 处理数据 msgs_.front(); msgs_.pop_front(); std::this_thread::sleep_for(std::chrono::millseconds(10)); // 防止该线程一直占用锁读数据,导致其他线程无法获取锁 }
不同线程通信方式实现线程池:
基于互斥锁和sleep实现:
- 封装线程基类
XThread;- 控制线程启动
Start()和停止Wait()/Stop(),模拟消息服务器线程; Main()函数:接收字符串消息,并模拟处理;
- 控制线程启动
- 通过
unique_lock和mutex互斥访问list<string>; - 消息队列主线程,定时发送消息给子线程,并通过子线程输出消息到终端屏幕上;
XThread.hpp
#include <iostream>
#include <thread>
// 封装一个抽象的线程基类
class XThread
{
public:
XThread() : is_exit_(false)
{}
// 启动线程
void Start()
{
is_exit_ = false;
th_ = std::thread(&XThread::Main, this);
}
// 设置阻塞等待线程退出
void Wait()
{
if (th_.joinable())
{
th_.join();
}
}
// 设置退出标志并等待
void Stop()
{
is_exit_ = true;
Wait();
}
bool is_exit() { return is_exit_; }
private:
virtual void Main() = 0;
bool is_exit_;
std::thread th_;
};
MsgServer.hpp:
#include <iostream>
#include <mutex>
#include "XThread.hpp"
class MsgServer : public XThread
{
public:
// 给当前主线程发送消息
void SendMsg(std::string msg)
{
std::unique_lock<std::mutex> lock(mtx_);
msgs_.push_back(msg);
std::this_thread::sleep_for(std::chrono::milliseconds(10)); // 等待一段时间,避免一直占用锁mtx_,导致“其他线程无法从消息队列中,读消息”,无法适应实时性要求较高的场景
}
private:
// 处理消息的子线程入口函数
virtual void Main() override
{
while (!is_exit())
{
std::this_thread::sleep_for(std::chrono::milliseconds(10)); // 等待一段时间,避免一直占用锁mtx_,导致“其他线程无法给消息队列中,加消息”,导致主线程和子线程均处于阻塞状态
std::unique_lock<std::mutex> lock(mtx_);
while (!msgs_.empty())
{
std::cout << "received " << msgs_.front() << std::endl;
msgs_.pop_front();
}
}
}
// 保证消息队列的线程安全
std::mutex mtx_;
// 消息缓冲队列
std::list<std::string> msgs_;
};
main.cpp:
#include <iostream>
#include <sstream>
#include "MsgServer.hpp"
int main()
{
MsgServer server;
server.Start();
for (int i = 0; i < 10; ++i)
{
std::stringstream ss;
ss << "msg : " << i + 1;
server.SendMsg(ss.str());
}
server.Stop();
return 0;
}
基于条件变量实现:
XThread.hpp:
#include <iostream>
#include <thread>
// 封装一个抽象的线程基类
class XThread
{
public:
XThread() : is_exit_(false)
{}
// 启动线程
void Start()
{
is_exit_ = false;
th_ = std::thread(&XThread::Main, this);
}
// 设置阻塞等待线程退出
void Wait()
{
if (th_.joinable())
{
th_.join();
}
}
// 设置退出标志并等待
virtual void Stop()
{
is_exit_ = true;
Wait();
}
bool is_exit() { return is_exit_; }
protected:
bool is_exit_;
private:
virtual void Main() = 0;
std::thread th_;
};
MsgServer.hpp:
#include <iostream>
#include <mutex>
#include <condition_variable>
#include "XThread.hpp"
class MsgServer : public XThread
{
public:
// 给当前主线程发送消息
void SendMsg(std::string msg)
{
std::unique_lock<std::mutex> lock(mtx_);
msgs_.push_back(msg);
lock.unlock();
cond_.notify_one();
}
virtual void Stop() override
{
is_exit_ = true;
// 通知所有在wait状态的线程
cond_.notify_all();
Wait();
}
private:
// 处理消息的子线程入口函数
virtual void Main() override
{
while (!is_exit())
{
std::unique_lock<std::mutex> lock(mtx_);
// 解锁并等待notify_one/notify_all的通知后,重新加锁
cond_.wait(lock, [this]()->bool {
// 存在的隐患:如果发送消息的线程不则发消息且msgs_为空,则该消费消息线程接收不到通知可能会一直阻塞
//,故需要在MsgServer中,重写基类XThread的Stop()函数,并在Wait()调用前通知所有wait的线程
if (is_exit()) // 一旦不在发送消息且消息队列为空,则在主线程调用Stop后is_exit_=true且给子线程发送信号,故接收到信号后,lambda表达式返回true,之后跳出阻塞等待并顺利结束该子线程。
{
return true;
}
return !msgs_.empty();
});
while (!msgs_.empty())
{
std::cout << "received " << msgs_.front() << std::endl;
msgs_.pop_front();
}
}
}
// 条件变量,用于线程间的信号同步通知
std::condition_variable cond_;
// 保证消息队列的线程安全
std::mutex mtx_;
// 消息缓冲队列
std::list<std::string> msgs_;
};
智能指针管理和异步获取结果的实现:
XThreadPool.hpp:
#include <iostream>
#include <atomic>
#include <mutex>
#include <chrono>
#include <thread>
#include <sstream>
#include <string>
#include <functional>
#include <future>
#include <condition_variable>
// 任务的抽象基类,需要被子类重写Run()
class XTask
{
public:
virtual int Run() = 0;
// 用来给MyTask通知,当Stop()后,任务也会直接中断
std::function<bool()> is_exit = nullptr; // 在XThreadPool::AddTask中初始化
int get_value()
{
return p_.get_future().get();
}
void set_value(int val)
{
p_.set_value(val);
}
private:
std::promise<int> p_;
};
class XThreadPool
{
public:
XThreadPool() : is_exit_(false)
{ }
// 初始化线程:
void Init(int thread_nums)
{
std::unique_lock<std::mutex> lock(mtx_);
thread_nums_ = thread_nums;
std::cout << "XThreadPool initialize successfully, " << thread_nums_ << std::endl;
}
// 启动所有线程:必须先调用Init()
void Start()
{
if (thread_nums_ <= 0)
{
std::cerr << "Please firstly initialize XThreadPool!" << std::endl;
return;
}
if (!threads_.empty())
{
std::cout << "XThreadPool has been initialized." << std::endl;
return;
}
// 创建线程,并用Run()线程函数(不断地尝试从task_中获取任务),填充线程池threads_
for (int i = 0; i < thread_nums_; ++i)
{
threads_.push_back(std::make_shared<std::thread>(&XThreadPool::Run, this));
}
}
// 通知所有线程,线程池已经退出
void Stop()
{
is_exit_ = true;
cond_.notify_all();
for (int i = 0; i < thread_nums_; ++i)
{
threads_[i]->join();
}
std::unique_lock<std::mutex> lock(mtx_);
threads_.clear();
}
// 给tasks_中插入任务,并通知线程池处理
void AddTask(std::shared_ptr<XTask> xTask)
{
std::unique_lock<std::mutex> lock(mtx_);
tasks_.push_back(xTask);
xTask->is_exit = [this]() { return is_exit_; };
// 解锁并通知子线程获取tasks_中的任务并执行
lock.unlock();
cond_.notify_one();
}
// 阻塞等待从tasks_中,获取任务
std::shared_ptr<XTask> GetTask()
{
std::unique_lock<std::mutex> lock(mtx_);
if (tasks_.empty())
{
cond_.wait(lock); // 解锁等待通知后,重新加锁,并继续向下执行
}
// 这里保证了当主线程调用XThreadPool::Stop()后,子线程能收到通知并返回nullptr,进而在XThreadPoo::Run()中正常退出
//,最后主线程给join等待所有子线程退出后,正常退出
if (tasks_.empty() || is_exit_)
{
return nullptr;
}
std::shared_ptr<XTask> task = tasks_.front();
tasks_.pop_front();
return task;
}
// 线程池中,线程的入口函数
void Run()
{
// 将日志加入logs中
{
std::unique_lock<std::mutex> lock(mtx_);
ss << "thread_id " << std::this_thread::get_id();
logs.push_back(static_cast<std::string>(ss.str()));
}
while (!is_exit_)
{
std::shared_ptr<XTask> task = GetTask();
if (task == nullptr)
{
continue;
}
++taskCnts_;
try {
task->set_value(task->Run());
}
catch (...) {
std::cerr << "XThreadPool::Run() exception!" << std::endl;
}
--taskCnts_;
}
}
int getTaskCount() { return taskCnts_; }
private:
bool is_exit_;
std::condition_variable cond_;
int thread_nums_;
std::list< std::shared_ptr<XTask>> tasks_;
std::mutex mtx_;
std::vector<std::shared_ptr<std::thread>> threads_;
std::stringstream ss;
std::vector<std::string> logs;
// 记录正在运行的任务数量
std::atomic<int> taskCnts_;
};
main.cpp:
class MyTask : public XTask
{
public:
virtual int Run() override
{
std::cout << "...................." << std::endl;
std::cout << "MyTask::Run(), " << name_ << std::endl;
while (true)
{
std::cout << std::this_thread::get_id() << " is processing." << std::endl;
if (is_exit()) // 当主线程调用Stop()后,子线程收到通知,终止执行的任务
{
break;
}
}
std::cout << "...................." << std::endl;
return 50;
}
std::string name_;
};
int main()
{
XThreadPool threadPool;
threadPool.Init(8);
threadPool.Start();
std::shared_ptr<MyTask> task1 = std::make_shared<MyTask>();
task1->name_ = "nini";
threadPool.AddTask(task1);
std::shared_ptr<MyTask> task2 = std::make_shared<MyTask>();
task2->name_ = "mimi";
threadPool.AddTask(task2);
std::shared_ptr<MyTask> task3 = std::make_shared<MyTask>();
task3->name_ = "kiki";
threadPool.AddTask(task3);
std::this_thread::sleep_for(std::chrono::microseconds(5));
std::cout << "<<<<<<<<<<" << threadPool.getTaskCount() << ">>>>>>>>>>" << std::endl;
threadPool.Stop();
std::cout << "<<<<<<<<<<" << threadPool.getTaskCount() << ">>>>>>>>>>" << std::endl;
// 异步获取子线程中的任务的执行结果(此时,子线程中任务已终止结束)
std::cout << task1->get_value() << ", " << task2->get_value() << ", " << task3->get_value() << ", " << std::endl;
return 0;
}
lambda表达式的实现原理:
c++中,lambda表达式(匿名函数)是一种方便编写的短小、简洁的函数对象的方法,编译器根据lambda表达式的捕获列表和参数、返回值,来实现一个匿名类(闭包类型)其包含了成员变量(即捕获列表中捕获的外部参数),构造函数(初始化成员变量)、重载operator()运算符(用来传入参数和返回返回值)。
int x = 0, y = 1;
auto lambda_ = [=x, &y](int z)->int {
cout << x << ", " << y << ", " << z << endl;
return 0;
;}
lambda_(2); // 调用lambda_表达式函数
/* 编译器根据lambda表达式的定义,构建出来的匿名类(闭包类型) */
class Anonymous
{
public:
Anonymous(int& x, int y) : x_(x), y_(y)
{ }
int operator()(int z)
{
cout << x << ", " << y << ", " << z << endl;
return 0;
}
private:
int& x_;
int y_;
};
Anonymous anonymous(x, y);
anonymous(2);
c++11中call_once函数的使用:
c++11标准库中,新引入的call_once函数,可确保多线程环境下某个“函数”或“可调用对象”只被执行一次。
应用场景:
-
单类模式:确保多线程同时尝试创建一个的单类的实例时,只有一个能创建成功。
#include <mutex> #include <memory> class Singleton { public: Singleton* getInstance() { // 该call_once中的函数或可调用对象一旦执行过一次,initFlag的状态就会改变。 // 下次再调用时,会首先检查initFlag的状态,故不会再执行其中的函数或可调用对象。 std::call_once(initFlag, [&this]() { singleton = new Singleton(); }); return *singleton; } private: std::unique_ptr<Singleton> singleton; // std::once_flag对象是一个不可复制、不可移动的对象,但可被默认构造。 // 作用:跟踪call_once中,函数或可调用对象的是否已经被执行。 std::once_flag initFlag; Singleton() = default; Singleton(const Singleton&) = delete; Singleton& operator=(const Singleton&) = delete; }; -
多线程条件下,的入口函数执行一次。