文章目录
- 前言
- 一 PyMysql入门
- 二 综合案例
- 2.1 案例需求
- 2.2 DDL定义
- 2.3 实现步骤
- 2.4 参考代码
- 2.4.1 封装数据对象
- 2.4.2 读取文件数据对象
- 2.4.3 连接并写入数据库对象
- 2.5 `1045`错误解决
- 三 今日作业
- 3.1 实现思路
- 3.2 参考代码
- 3.2.1 对象类的封装
- 3.2.2 操作代码
- 3.3 出现的错误
- 3.3.1 日期转换json:TypeError
- 3.3.2 原因分析:date未定义类型,却成为 datetime.date 对象
- 3.3.3 省份中文内容乱码
- 3.4.4 原因分析:文件乱码
- 3.3.5 解决方法
- 四 补充内容
- 4.1 enumerate内置方法
- 4.2 补充: json.dumps() 方法参数
前言
- 由于本博主已经系统学习过mysql,所以这里就不再讲解Mysql的相关内容。需要学习的小伙伴,可以看看其他优秀博主的Mysql入门博客
一 PyMysql入门
- PyMySQL是一个开源的Python库,它提供了一种使用Python与MySQL数据库进行交互的方式。它允许连接到MySQL数据库,执行SQL查询,获取结果,并使用Python代码管理数据库操作。
使用PyMySQL的基本概述:
-
安装:首先,需要安装PyMySQL。
pip install pymysql -
连接数据库:安装后,导入PyMySQL模块并与MySQL数据库建立连接:
from pymysql import Connection # 建立连接 conn = Connection( host="localhost", # 主机名(IP) port=3306, # 端口 user="xxx", # 账户 password="密码", # 密码 ) -
执行SQL查询:一旦建立了连接,你可以创建一个游标对象并使用它来执行SQL查询:
#获取到游标对象 cursor = conn.cursor() # 选择数据库 conn.select_db("world") # 执行查询 得到全部的查询结果封装入元组内 query = "SELECT * FROM 表名" cursor.execute(query) # 获取结果 results = cursor.fetchall() # 对结果进行处理 for row in results: print(row)fetchall()是 PyMySQL 中用于从执行查询后的游标对象中获取所有结果的方法。- 这个方法会返回一个包含查询结果的列表,列表的每个元素都是一个表示数据库中一行数据的元组或元组的元组。每个元组中的元素对应查询中的列。
-
提交更改:如果对数据库进行了更改,例如插入、更新或删除记录,则需要提交这些更改:
- 也可以再构建连接对象的时候,设置自动提交的属性
connection.commit()from pymysql import Connection # 建立连接 conn = Connection( host="localhost", # 主机名(IP) port=3306, # 端口 user="xxx", # 账户 password="密码", # 密码 autocommit=True # 设置自动提交 ) -
关闭连接:在完成数据库操作后,确保关闭连接:
connection.close()
- PyMySQL是与MySQL数据库交互的常用库,但也有其他库(例如
mysql-connector-python)以及内置的sqlite3库用于SQLite数据库,它们提供类似的功能。
二 综合案例
2.1 案例需求
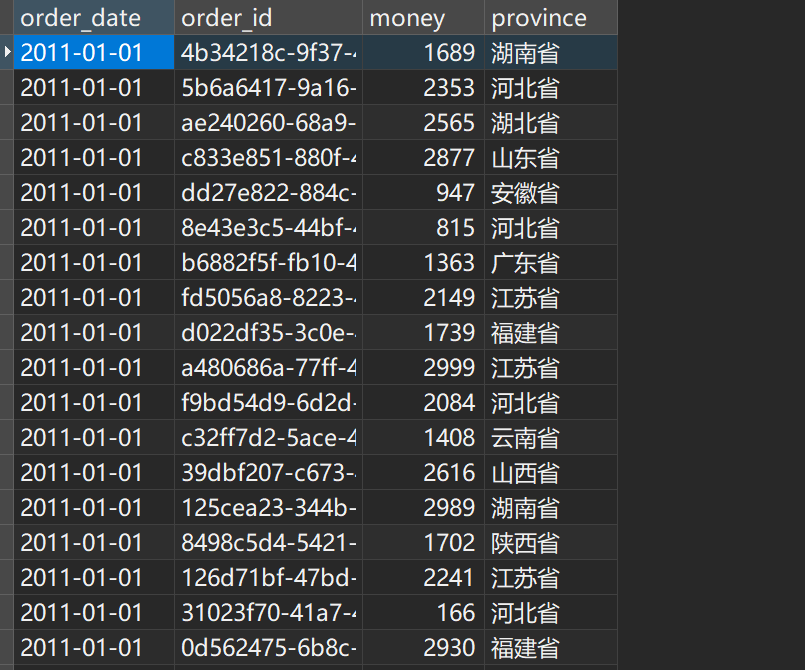
- 使用《面向对象》章节案例中的数据集,完成使用Python语言,读取数据,并将数据写入MySQL的功能。
- 数据内容
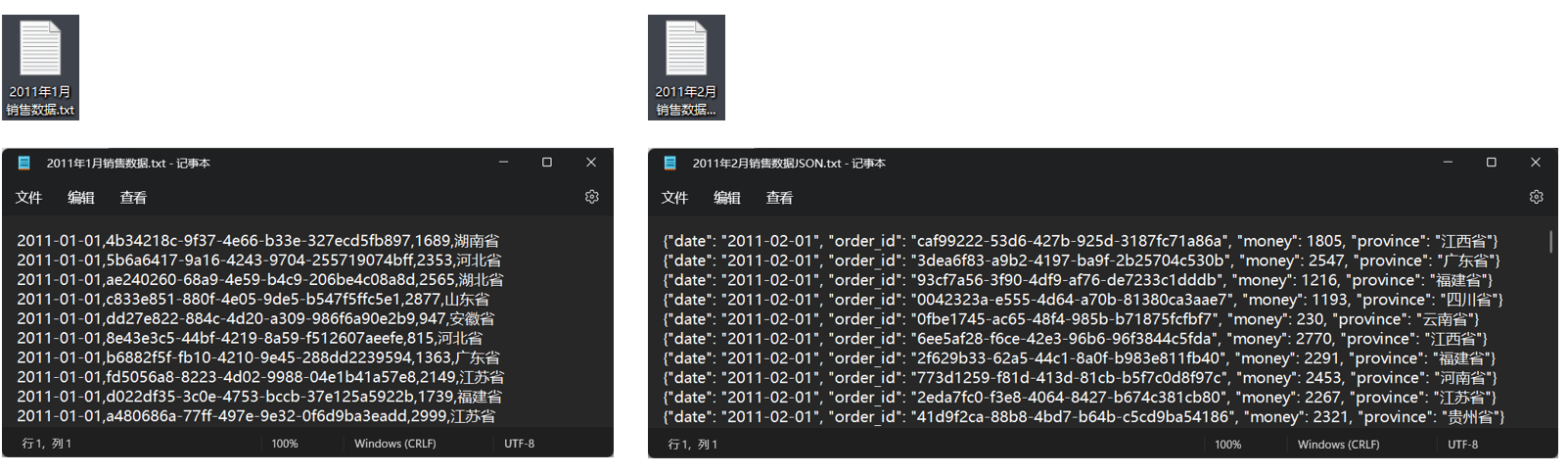
- 1月份数据是普通文本,使用逗号分割数据记录,从前到后分别是(日期,订单id,销售额,销售省份)
- 2月份数据是JSON数据,同样包含(日期,订单id,销售额,销售省份)
2.2 DDL定义
- 本次需求开发我们需要新建一个数据库来使用,数据库名称:py_sql,基于数据结构,可以得到建表语句:
CREATE DATABASE IF NOT EXISTS py_sql;
USE py_sql;
CREATE TABLE IF NOT EXISTS orders(
order_date DATE,
order_id VARCHAR(255),
money INT,
province VARCHAR(10)
);
2.3 实现步骤
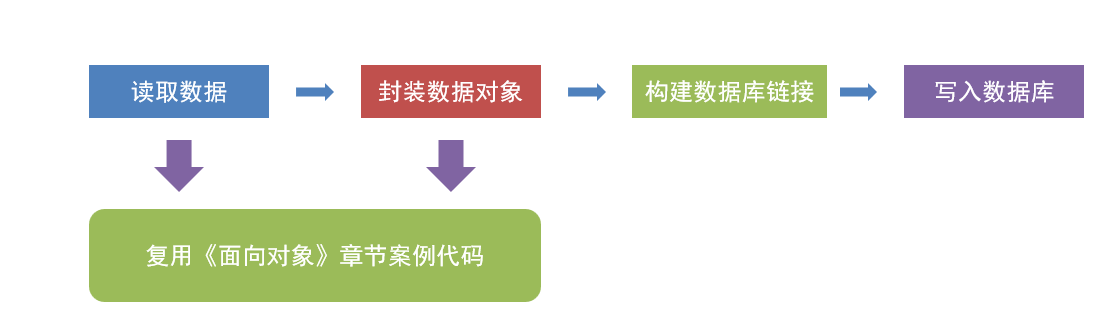
2.4 参考代码
2.4.1 封装数据对象
data_define.py""" 数据定义的类 """ class Record: def __init__(self, date, order_id, money, province): self.date = date # 订单日期 self.order_id = order_id # 订单ID self.money = money # 订单金额 self.province = province # 销售省份 def __str__(self): return f"{self.date}, {self.order_id}, {self.money}, {self.province}" def to_json(self): d = {"date": self.date.isoformat(), "order_id": self.order_id, "money": self.money, "province": self.province} import json return json.dumps(d,ensure_ascii=False)
2.4.2 读取文件数据对象
file_define.py
"""
和文件相关的类定义
"""
import json
from data_define import Record
# 先定义一个抽象类用来做顶层设计,确定有哪些功能需要实现
class FileReader:
def read_data(self) -> list[Record]:
"""读取文件的数据,读到的每一条数据都转换为Record对象,将它们都封装到list内返回即可"""
pass
class TextFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
# 复写(实现抽象方法)父类的方法
def read_data(self) -> list[Record]:
f = open(self.path, "r", encoding="UTF-8")
record_list: list[Record] = []
for line in f.readlines():
line = line.strip() # 消除读取到的每一行数据中的\n
data_list = line.split(",")
record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])
record_list.append(record)
f.close()
return record_list
class JsonFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件的路径
def read_data(self) -> list[Record]:
f = open(self.path, "r", encoding="UTF-8")
record_list: list[Record] = []
for line in f.readlines():
data_dict = json.loads(line)
record = Record(data_dict["date"], data_dict["order_id"], int(data_dict["money"]), data_dict["province"])
record_list.append(record)
f.close()
return record_list
2.4.3 连接并写入数据库对象
main.py
"""
SQL 综合案例,读取文件,写入MySQL数据库中
"""
from file_define import TextFileReader, JsonFileReader
from data_define import Record
from pymysql import Connection
text_file_reader = TextFileReader("D:/2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:/2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.read_data()
feb_data: list[Record] = json_file_reader.read_data()
# 将2个月份的数据合并为1个list来存储
all_data: list[Record] = jan_data + feb_data
# 构建MySQL链接对象
conn = Connection(
host="localhost",
port=3306,
user="root",
password="密码",
autocommit=True
)
# 获得游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db("py_sql")
# 组织SQL语句
for record in all_data:
# 反斜杠 \ 用于连接多行字符串
sql = f"insert into orders(order_date, order_id, money, province) " \
f"values('{record.date}', '{record.order_id}', {record.money}, '{record.province}')"
# 执行SQL语句
cursor.execute(sql)
# 关闭MySQL链接对象
conn.close()
2.5 1045错误解决
pymysql.err.OperationalError: (1045, "Access denied for user 'root'@'localhost' (using password: YES)")
- 这个错误提示是由于连接到 MySQL 数据库时使用的用户名和密码不正确,或者用户没有足够的权限来连接数据库。
- 解决方法:查看密码和用户名是否正确
三 今日作业
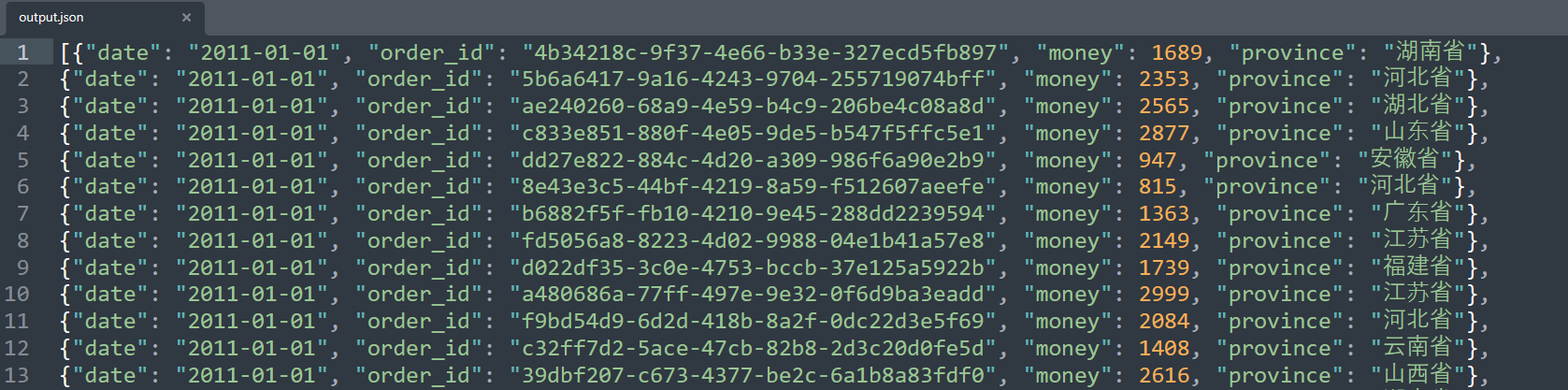
- 将写入到MySQL的数据,通过Python代码读取出来,在反向写出到TXT文件
3.1 实现思路

3.2 参考代码
3.2.1 对象类的封装
data_define.py
"""
数据定义的类
"""
import json
class Record:
def __init__(self, date, order_id, money, province):
self.date = date # 订单日期
self.order_id = order_id # 订单ID
self.money = money # 订单金额
self.province = province # 销售省份
def __str__(self):
return f"{self.date}, {self.order_id}, {self.money}, {self.province}"
def to_json(self):
d = {"date": self.date.isoformat(), "order_id": self.order_id, "money": self.money, "province": self.province}
return json.dumps(d,ensure_ascii=False)
3.2.2 操作代码
main.py
from data_define import Record
from pymysql import Connection
f = open("C:/Users/HP/Desktop/output.json", "w", encoding="UTF-8")
f.write("[")
# 构建MySQL链接对象
conn = Connection(
host="localhost",
port=3306,
user="root",
password="密码",
autocommit=True
)
# 获得游标对象
cursor = conn.cursor()
# 选择数据库
conn.select_db("py_sql")
# 查询
cursor.execute("SELECT * FROM orders")
result = cursor.fetchall()
for idx, r in enumerate(result):
record = Record(r[0], r[1], r[2], r[3])
f.write(record.to_json())
if idx < len(result) - 1:
f.write(",\n") # 添加逗号分隔,除了最后一个记录之外
else:
f.write("\n")
# 关闭MySQL链接对象
conn.close()
f.write("]")
f.close()
3.3 出现的错误
3.3.1 日期转换json:TypeError
Traceback (most recent call last):
File "C:\Users\HP\Desktop\program\python\python-learn\12_sql\main2.py", line 22, in <module>
f.write(record.to_json())
^^^^^^^^^^^^^^^^
File "C:\Users\HP\Desktop\program\python\python-learn\12_sql\data_define.py", line 22, in to_json
return json.dumps(d)
^^^^^^^^^^^^^
File "C:\environment\Python3.11.4\Lib\json\__init__.py", line 231, in dumps
return _default_encoder.encode(obj)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\environment\Python3.11.4\Lib\json\encoder.py", line 200, in encode
chunks = self.iterencode(o, _one_shot=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\environment\Python3.11.4\Lib\json\encoder.py", line 258, in iterencode
return _iterencode(o, 0)
^^^^^^^^^^^^^^^^^
File "C:\environment\Python3.11.4\Lib\json\encoder.py", line 180, in default
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type date is not JSON serializable
- 在尝试将
date类型的对象转换为 JSON 格式时出现了问题。date类型对象不是默认可序列化为 JSON 的数据类型,所以需要进行额外的处理来将其转换为可序列化的格式。
在 Python 中,可以使用 datetime 模块的 isoformat() 方法将日期对象转换为字符串格式,以便于 JSON 序列化。
def to_json(self):
d = {"date": self.date.isoformat(), "order_id": self.order_id, "money": self.money, "province": self.province}
return json.dumps(d,ensure_ascii=False)
日期序列化问题: 请确保 self.date 是一个 datetime.date 对象,而不是 Python 内置的 date 模块。因为后者是模块名,可能会导致冲突。如果你使用的是 datetime.date 对象,那么在 to_json 方法中的 isoformat() 方法调用是正确的。
3.3.2 原因分析:date未定义类型,却成为 datetime.date 对象
-
从 MySQL 数据库读取的是
DATE数据类型的数据,那么在 Python 中使用 PyMySQL 库时,这些数据会以datetime.date对象的形式返回。 -
datetime.date对象表示一个具体的日期,包括年、月、日。它不包含时间部分。这与 MySQL 中的DATE数据类型相对应,因为 MySQL 的DATE数据类型只包含日期部分,不包括时间。 -
所以,当从 MySQL 数据库中读取
DATE类型的数据时,PyMySQL 库会将这些数据转换为 Python 的datetime.date对象。如此一来才出现了,上面json序列化失败的问题。
3.3.3 省份中文内容乱码
打开生成的json文件,湖南省份的值为\u6e56\u5357\u7701
3.4.4 原因分析:文件乱码
-
问题出现在 JSON 字符串中的 Unicode 转义序列。
\u6e56和\u5357分别是"湖"和"南"的 Unicode 编码。这是因为默认情况下,json.dumps()函数会将非 ASCII 字符转义为 Unicode 转义序列,以确保生成的 JSON 字符串是 ASCII 编码的。 -
希望生成的 JSON 字符串中包含原始的 Unicode 字符,而不是转义序列,可以通过设置
ensure_ascii参数为False来解决。在json.dumps()中,将ensure_ascii参数设置为False可以确保保留原始的 Unicode 字符。
3.3.5 解决方法
- 方法一:在调用方法时,设置
```python
for idx, r in enumerate(result):
record = Record(r[0], r[1], r[2], r[3])
# 将 ensure_ascii 参数设置为 False,保留原始 Unicode 字符
json_str = record.to_json(ensure_ascii=False)
f.write(json_str)
if idx < len(result) - 1:
f.write(",\n") # 添加逗号分隔,除了最后一个记录之外
else:
f.write("\n")
```
- 方法二:在封装对象中设置
```python
"""
数据定义的类
"""
import json
class Record:
def __init__(self, date, order_id, money, province):
self.date = date # 订单日期
self.order_id = order_id # 订单ID
self.money = money # 订单金额
self.province = province # 销售省份
def __str__(self):
return f"{self.date}, {self.order_id}, {self.money}, {self.province}"
def to_json(self):
d = {"date": self.date.isoformat(), "order_id": self.order_id, "money": self.money, "province": self.province}
return json.dumps(d,ensure_ascii=False)
```
四 补充内容
4.1 enumerate内置方法
-
enumerate(result)是一个内置函数,它将一个序列(这里是result列表)作为输入,并返回一个可以产生元组的迭代器,每个元组包含两个值:索引和序列中对应索引的值。 -
idx是一个变量,它在循环中存储每个元素的索引。 -
r是一个变量,它在循环中存储序列中对应索引的值。 -
for idx, r in enumerate(result)这行代码是一个循环语句,用于遍历一个序列(这里是result列表),同时获取每个元素的索引和值。所以,在循环中,idx会依次取遍result列表中每个元素的索引,而r会依次取遍result列表中每个元素的值。这样,在每次循环迭代中,可以同时访问列表中的索引和值,方便处理数据。
4.2 补充: json.dumps() 方法参数
-
json.dumps()函数在 Python 中有一些可选参数,可以用来控制 JSON 输出的格式和编码方式。下面是一些常用的参数: -
indent: 这个参数用来指定缩进级别,可以让生成的 JSON 字符串更易读。例如,
json.dumps(d, indent=4)会让 JSON 字符串每个嵌套层级缩进 4 个空格。 -
ensure_ascii: 默认情况下,
ensure_ascii参数是True,它会将非 ASCII 字符转义为 ASCII 编码。如果你想保留原始的 Unicode 字符,可以将它设置为False。 -
sort_keys: 默认情况下,
sort_keys参数是False,这意味着生成的 JSON 字符串中键的顺序是未排序的。如果你希望生成的 JSON 字符串中键按字母顺序排序,可以将它设置为True。 -
其他参数:
json.dumps()还有其他参数,比如skipkeys、separators等,可以用来进一步定制 JSON 输出的行为。 -
示例:
import json
data = {"name": "Alice", "age": 25, "city": "Wonderland"}
# 输出格式化后的 JSON,每个层级缩进2个空格
formatted_json = json.dumps(data, indent=2)
print(formatted_json)