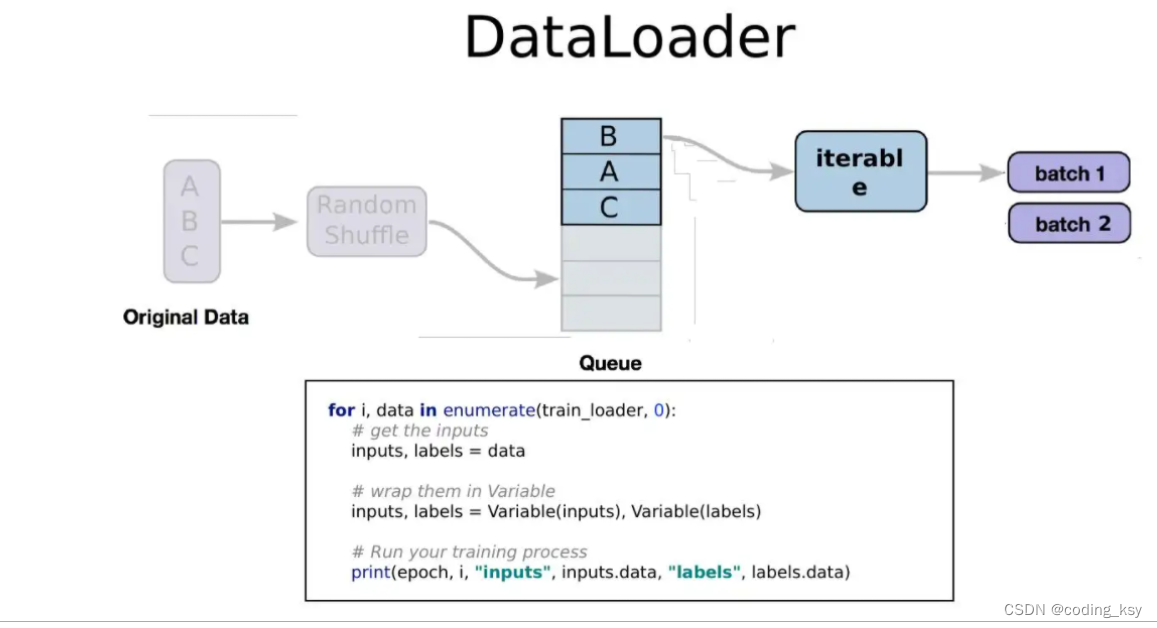
1.数据和标签的目录结构先搞定(得知道到哪读数据) 2.写好读取数据和标签路径的函数(根据自己数据集情况来写) 3.完成单个数据与标签读取函数(给dataloader举一个例子) 原来数据集都是以文件夹为类别ID,现在咱们换一个套路,用txt文件指定数据路径与标签(实际情况基本都这样) 这回咱们的任务就是在txt文件中获取图像路径与标签,然后把他们交给dataloader 核心代码非常简单,按照对应格式传递需要的数据和标签就可以啦 import os
import matplotlib. pyplot as plt
% matplotlib inline
import numpy as np
import torch
from torch import nn
import torch. optim as optim
import torchvision
from torchvision import transforms, models, datasets
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image
第一个小任务,从标注文件中读取数据和标签 至于你准备存成什么格式,都可以的,一会能取出来东西就行 def load_annotations ( ann_file) :
data_infos = [ ]
with open ( ann_file) as f:
samples = [ x. strip( ) . split( ' ' ) for x in f. readlines]
def load_annotations ( ann_file) :
data_infos = { }
with open ( ann_file) as f:
samples = [ x. strip( ) . split( ' ' ) for x in f. readlines( ) ]
for filename, gt_label in samples:
data_infos[ filename] = np. array( gt_label, dtype= np. int64)
return data_infos
不是我非让你存list里,因为dataloader到时候会在这里取数据 按照人家要求来,不要耍个性,让整list咱就给人家整 img_label = load_annotations( './flower_data/train.txt' )
image_name = list ( img_label. keys( ) )
label = list ( img_label. values( ) )
因为一会咱得用这个路径去读数据,所以路径得加上前缀 以后大家任务不同,数据不同,怎么加你看着来就行,反正得能读到图像 data_dir = './flower_data/'
train_dir = data_dir + '/train_filelist'
valid_dir = data_dir + '/val_filelist'
image_path = [ os. path. join( train_dir, img) for img in image_name]
image_path
1.注意要使用from torch.utils.data import Dataset, DataLoader 2.类名定义class FlowerDataset(Dataset),其中FlowerDataset可以改成自己的名字 3.def init (self, root_dir, ann_file, transform=None):咱们要根据自己任务重写 4.def getitem (self, idx):根据自己任务,返回图像数据和标签数据 from torch. utils. data import Dataset, DataLoader
class FlowerDataset ( Dataset) :
def __init__ ( self, root_dir, ann_file, transform= None ) :
self. ann_file = ann_file
self. root_dir = root_dir
self. img_label = self. load_annotations( )
self. img = [ os. path. join( self. root_dir, img) for img in list ( self. img_label. keys( ) ) ]
self. label = [ label for label in list ( self. img_label. values( ) ) ]
self. transform = transform
def __len__ ( self) :
return len ( self. img)
def __getitem__ ( self, idx) :
image = Image. open ( self. img[ idx] )
label = self. label[ idx]
if self. transform:
image = self. transform( image)
label = torch. from_numpy( np. array( label) )
return image, label
def load_annotations ( self) :
data_infos = { }
with open ( self. ann_file) as f:
samples = [ x. strip( ) . split( ' ' ) for x in f. readlines( ) ]
for filename, gt_label in samples:
data_infos[ filename] = np. array( gt_label, dtype= np. int64)
return data_infos
1.预处理的事都在上面的__getitem__中完成,需要对图像和标签咋咋地的,要整啥事,都在上面整 2.返回的数据和标签就是建模时模型的输入和损失函数中标签的输入,一定整明白自己模型要啥 3.预处理这个事是你定的,不同的数据需要的方法也不一样,下面给出的是比较通用的方法 data_transforms = {
'train' :
transforms. Compose( [
transforms. Resize( 64 ) ,
transforms. RandomRotation( 45 ) ,
transforms. CenterCrop( 64 ) ,
transforms. RandomHorizontalFlip( p= 0.5 ) ,
transforms. RandomVerticalFlip( p= 0.5 ) ,
transforms. ColorJitter( brightness= 0.2 , contrast= 0.1 , saturation= 0.1 , hue= 0.1 ) ,
transforms. RandomGrayscale( p= 0.025 ) ,
transforms. ToTensor( ) ,
transforms. Normalize( [ 0.485 , 0.456 , 0.406 ] , [ 0.229 , 0.224 , 0.225 ] )
] ) ,
'valid' :
transforms. Compose( [
transforms. Resize( 64 ) ,
transforms. CenterCrop( 64 ) ,
transforms. ToTensor( ) ,
transforms. Normalize( [ 0.485 , 0.456 , 0.406 ] , [ 0.229 , 0.224 , 0.225 ] )
] ) ,
}
1.构建数据集:分别创建训练和验证用的数据集(如果需要测试集也一样的方法) 2.用Torch给的DataLoader方法来实例化(batch啥的自己定,根据你的显存来选合适的) 3.打印看看数据里面是不是有东西了 train_dataset = FlowerDataset( root_dir= train_dir, ann_file = './flower_data/train.txt' , transform= data_transforms[ 'train' ] )
val_dataset = FlowerDataset( root_dir= valid_dir, ann_file = './flower_data/val.txt' , transform= data_transforms[ 'valid' ] )
train_loader = DataLoader( train_dataset, batch_size= 64 , shuffle= True )
val_loader = DataLoader( val_dataset, batch_size= 64 , shuffle= True )
1.别着急往模型里传,对不对都不知道呢 2.用这个方法:iter(train_loader).next()来试试,得到的数据和标签是啥 3.看不出来就把图画出来,标签打印出来,确保自己整的数据集没啥问题 image, label = iter ( train_loader) . next ( )
sample = image[ 0 ] . squeeze( )
sample = sample. permute( ( 1 , 2 , 0 ) ) . numpy( )
sample *= [ 0.229 , 0.224 , 0.225 ]
sample += [ 0.485 , 0.456 , 0.406 ]
plt. imshow( sample)
plt. show( )
print ( 'Label is: {}' . format ( label[ 0 ] . numpy( ) ) )
image, label = iter ( val_loader) . next ( )
sample = image[ 0 ] . squeeze( )
sample = sample. permute( ( 1 , 2 , 0 ) ) . numpy( )
sample *= [ 0.229 , 0.224 , 0.225 ]
sample += [ 0.485 , 0.456 , 0.406 ]
plt. imshow( sample)
plt. show( )
print ( 'Label is: {}' . format ( label[ 0 ] . numpy( ) ) )
下面这些事之前都唠过了,按照自己习惯的方法整就得了 dataloaders = { 'train' : train_loader, 'valid' : val_loader}
model_name = 'resnet'
feature_extract = True
train_on_gpu = torch. cuda. is_available( )
if not train_on_gpu:
print ( 'CUDA is not available. Training on CPU ...' )
else :
print ( 'CUDA is available! Training on GPU ...' )
device = torch. device( "cuda:0" if torch. cuda. is_available( ) else "cpu" )
model_ft = models. resnet18( )
model_ft
num_ftrs = model_ft. fc. in_features
model_ft. fc = nn. Sequential( nn. Linear( num_ftrs, 102 ) )
input_size = 64
model_ft
optimizer_ft = optim. Adam( model_ft. parameters( ) , lr= 1e-3 )
scheduler = optim. lr_scheduler. StepLR( optimizer_ft, step_size= 7 , gamma= 0.1 )
criterion = nn. CrossEntropyLoss( )
def train_model ( model, dataloaders, criterion, optimizer, num_epochs= 25 , is_inception= False , filename= 'best.pth' ) :
since = time. time( )
best_acc = 0
model. to( device)
val_acc_history = [ ]
train_acc_history = [ ]
train_losses = [ ]
valid_losses = [ ]
LRs = [ optimizer. param_groups[ 0 ] [ 'lr' ] ]
best_model_wts = copy. deepcopy( model. state_dict( ) )
for epoch in range ( num_epochs) :
print ( 'Epoch {}/{}' . format ( epoch, num_epochs - 1 ) )
print ( '-' * 10 )
for phase in [ 'train' , 'valid' ] :
if phase == 'train' :
model. train( )
else :
model. eval ( )
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[ phase] :
inputs = inputs. to( device)
labels = labels. to( device)
optimizer. zero_grad( )
with torch. set_grad_enabled( phase == 'train' ) :
outputs = model( inputs)
loss = criterion( outputs, labels)
_, preds = torch. max ( outputs, 1 )
if phase == 'train' :
loss. backward( )
optimizer. step( )
running_loss += loss. item( ) * inputs. size( 0 )
running_corrects += torch. sum ( preds == labels. data)
epoch_loss = running_loss / len ( dataloaders[ phase] . dataset)
epoch_acc = running_corrects. double( ) / len ( dataloaders[ phase] . dataset)
time_elapsed = time. time( ) - since
print ( 'Time elapsed {:.0f}m {:.0f}s' . format ( time_elapsed // 60 , time_elapsed % 60 ) )
print ( '{} Loss: {:.4f} Acc: {:.4f}' . format ( phase, epoch_loss, epoch_acc) )
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy. deepcopy( model. state_dict( ) )
state = {
'state_dict' : model. state_dict( ) ,
'best_acc' : best_acc,
'optimizer' : optimizer. state_dict( ) ,
}
torch. save( state, filename)
if phase == 'valid' :
val_acc_history. append( epoch_acc)
valid_losses. append( epoch_loss)
scheduler. step( epoch_loss)
if phase == 'train' :
train_acc_history. append( epoch_acc)
train_losses. append( epoch_loss)
print ( 'Optimizer learning rate : {:.7f}' . format ( optimizer. param_groups[ 0 ] [ 'lr' ] ) )
LRs. append( optimizer. param_groups[ 0 ] [ 'lr' ] )
print ( )
time_elapsed = time. time( ) - since
print ( 'Training complete in {:.0f}m {:.0f}s' . format ( time_elapsed // 60 , time_elapsed % 60 ) )
print ( 'Best val Acc: {:4f}' . format ( best_acc) )
model. load_state_dict( best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model( model_ft, dataloaders, criterion, optimizer_ft, num_epochs= 20 , filename= 'best.pth' )