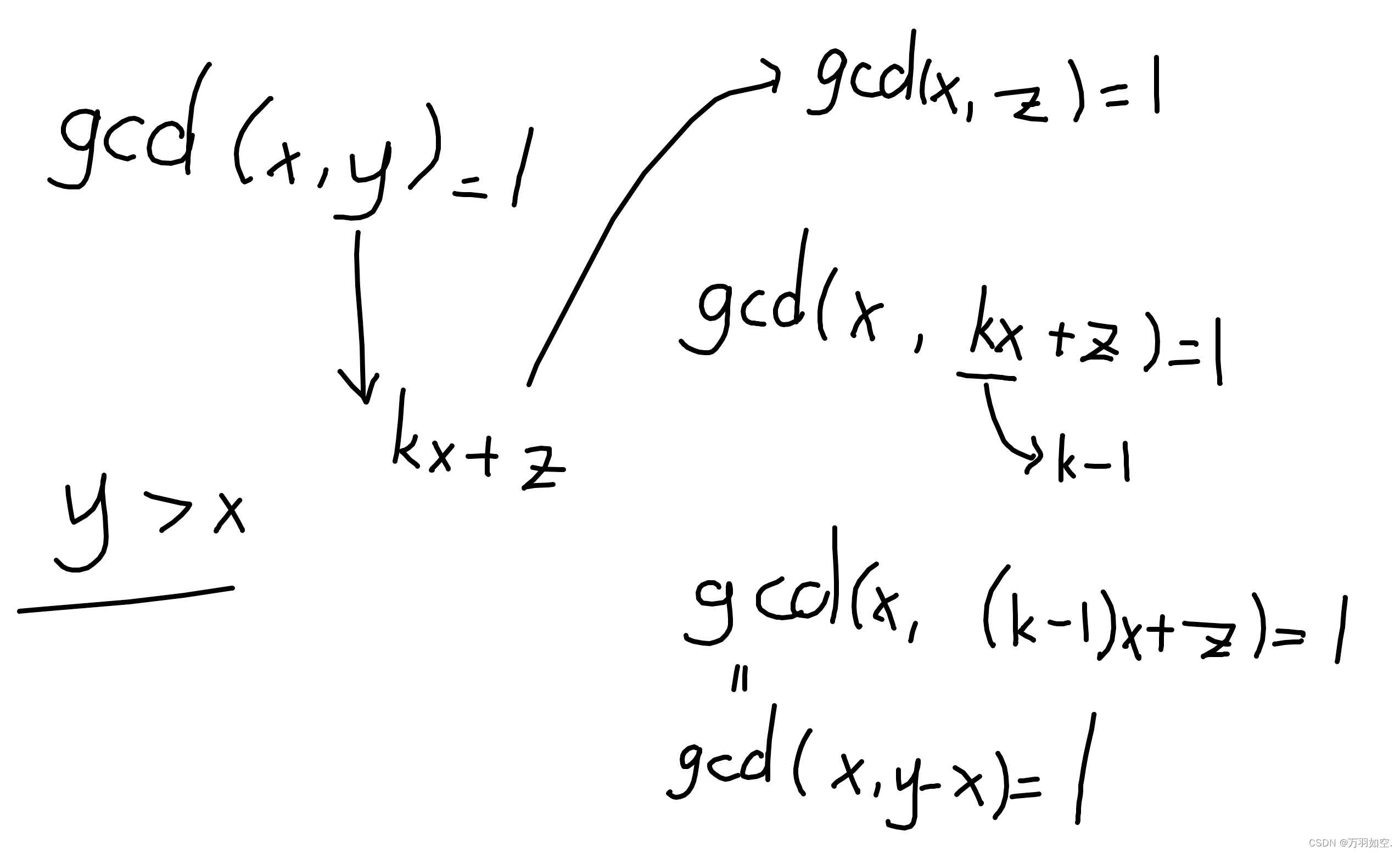文章目录
- 摘要
- 2.2 孪生神经网络
- 3.2 基于孪生ELETRA网络的语义相似度交互模型结构
- 3.3 实验结果分析
- 3.3.4 评价指标
摘要
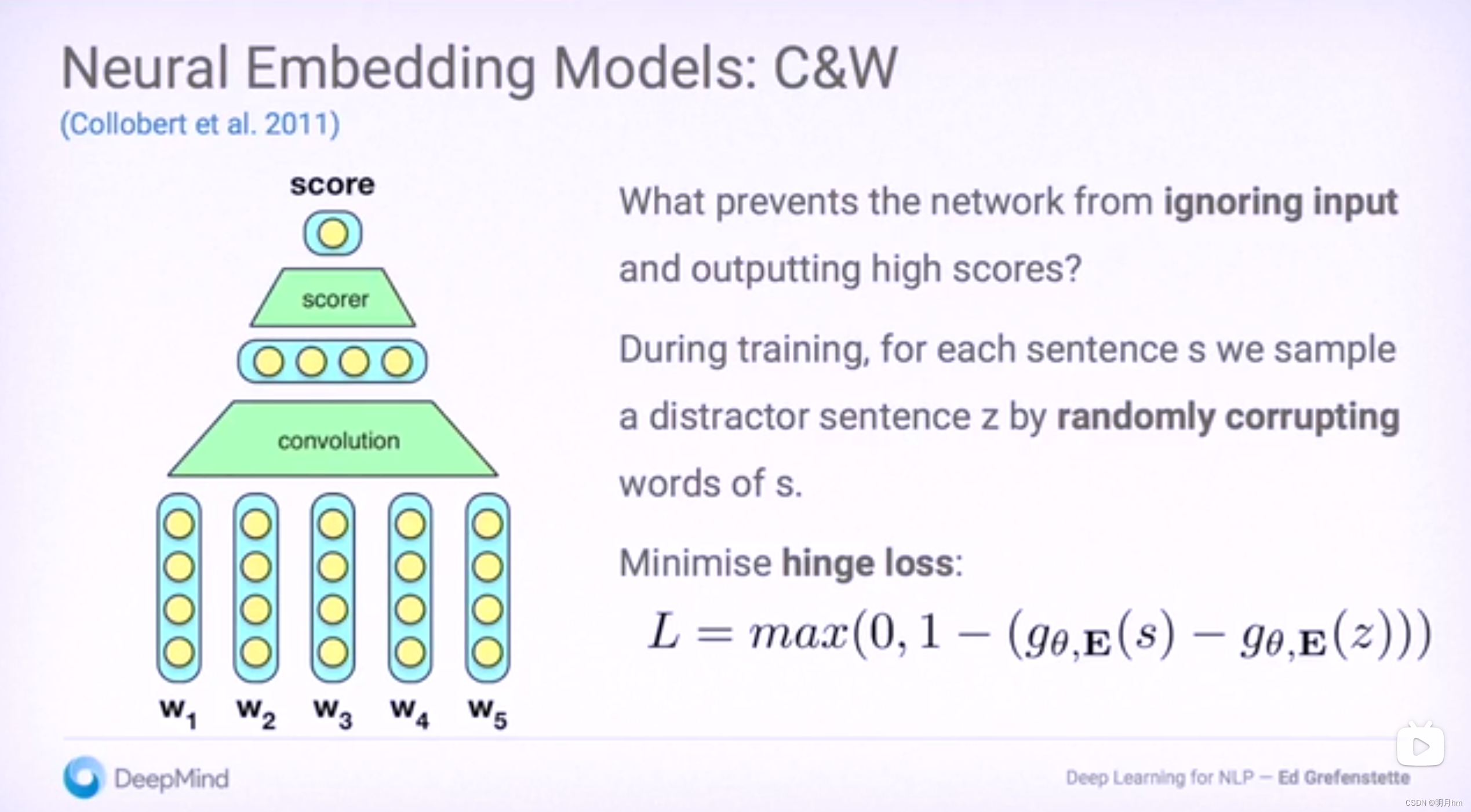
- 啥啊:两个文本之间的交互特征


- LSTM 应用于孪生神经网络的特征提取层,可以获取到长文本的语义信息。

- 孪生神经网络的特征提取层,对文本之间进行编码是相互独立的,句子之间没有交互,使得两侧文本抽取出的特征仅仅是各自最后的语义向量。没有两个句子之间的结构信息、词性信息、句法信息

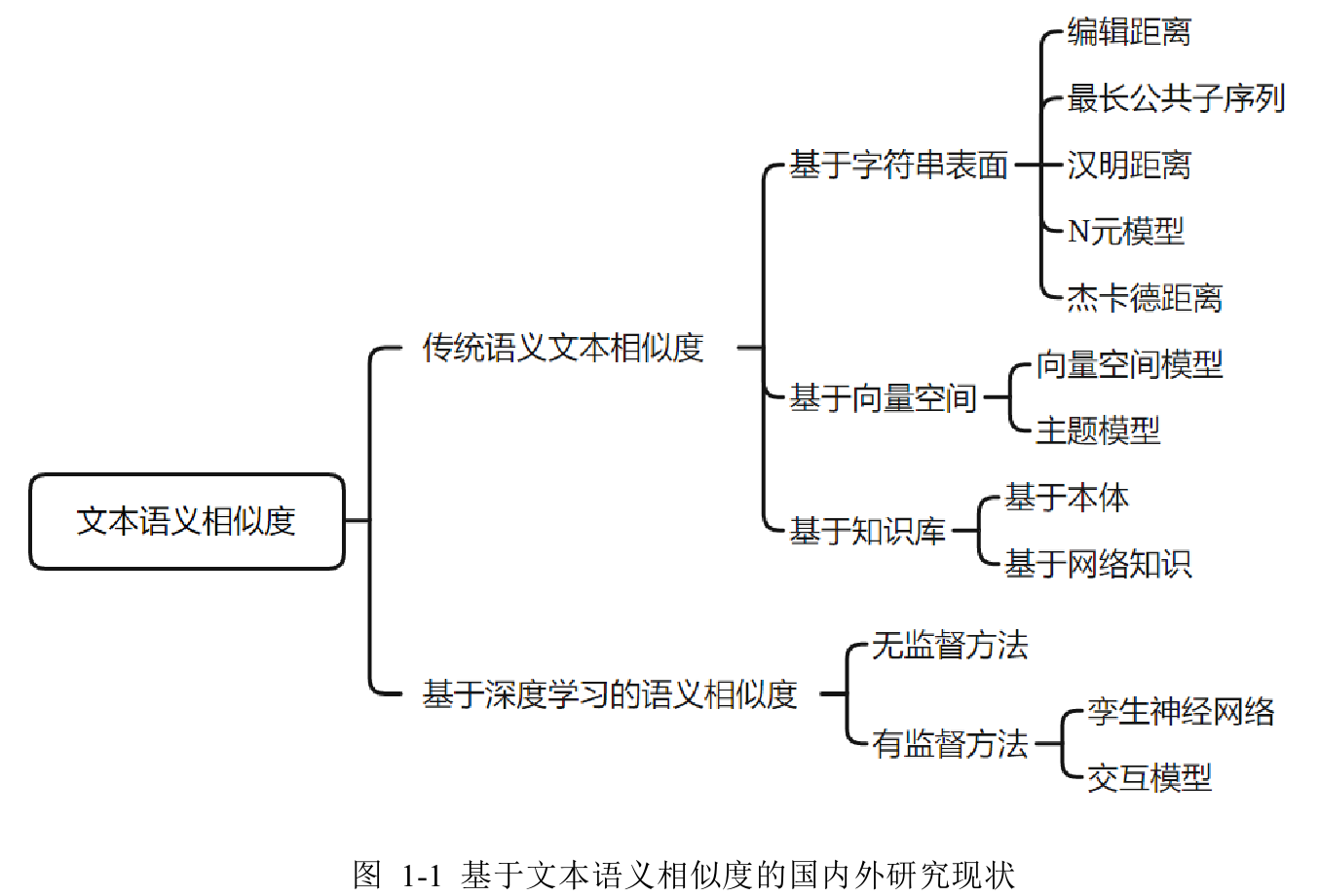
目前国内外在文本语义相似度领域的研究中都取得了不错的成就,却也仍有一定的提升空间。基于传统的语义相似度在原理上简单,执行效率高,但是却存在难以深入文本语义的缺陷。基于深度学习的语义相似度模型可以挖掘到文本的深层含义,模型的性能效果更好,但由于目前研究时间不长,模型的准确率和鲁棒性还有进一步提升的空间。
2.2 孪生神经网络
(之前的内容我没有记录下来)
-
在深度学习还未在**任务中流行之前,大多数采用的是基于统计的语义相似度计算方法,对字符层面的统计分析

-
在搜索引擎中,语义相似度作为信息检索任务的主体。
-
在编码层之后,再利用一些方法机制增加两个网络之间的交互。

-
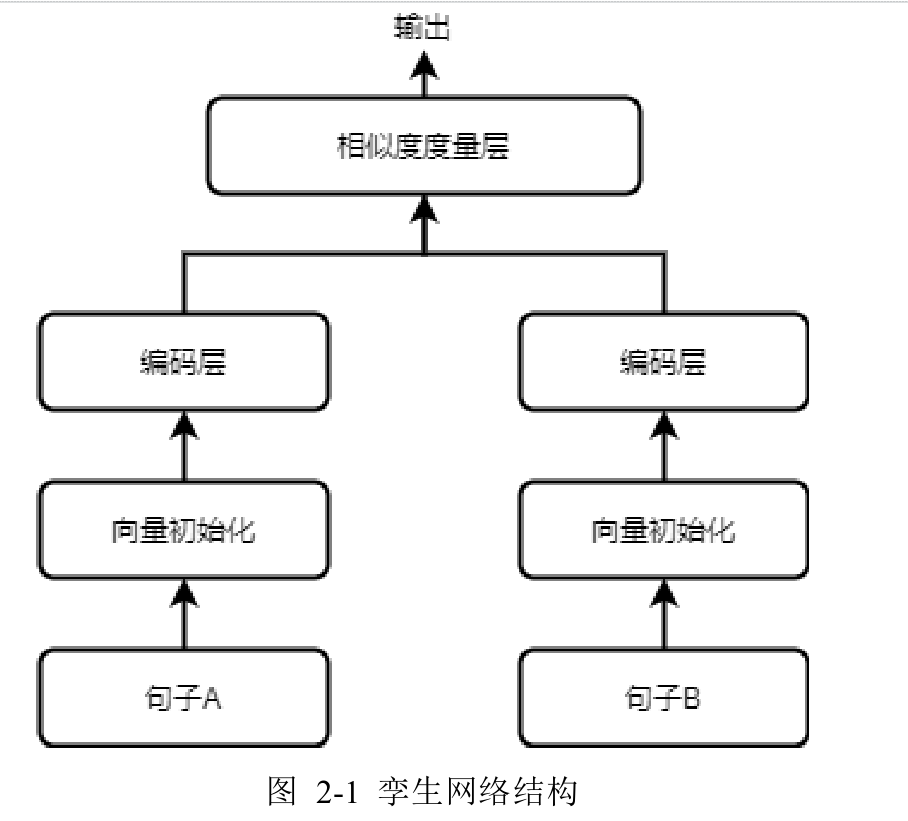
输入层、特征提取层和相似性度量层。孪生神经网络的两个编码层是两个完全相同的共享参数权重的网络模型。(是两个类型相似的样本,比如两个长度相当或者两个同样大小的图片)
-
在利用孪生神经网络框架计算相似度时,需要充分考量其应用场景,从而选择到合适的网络对样本进行特征提取。
-
相似性度量层。传入多层感知机或者其他前馈神经网络中,再利用分类函数对其相似度进行打分。【例如BP神经网络呀】

-
加入特征交互的孪生神经网络
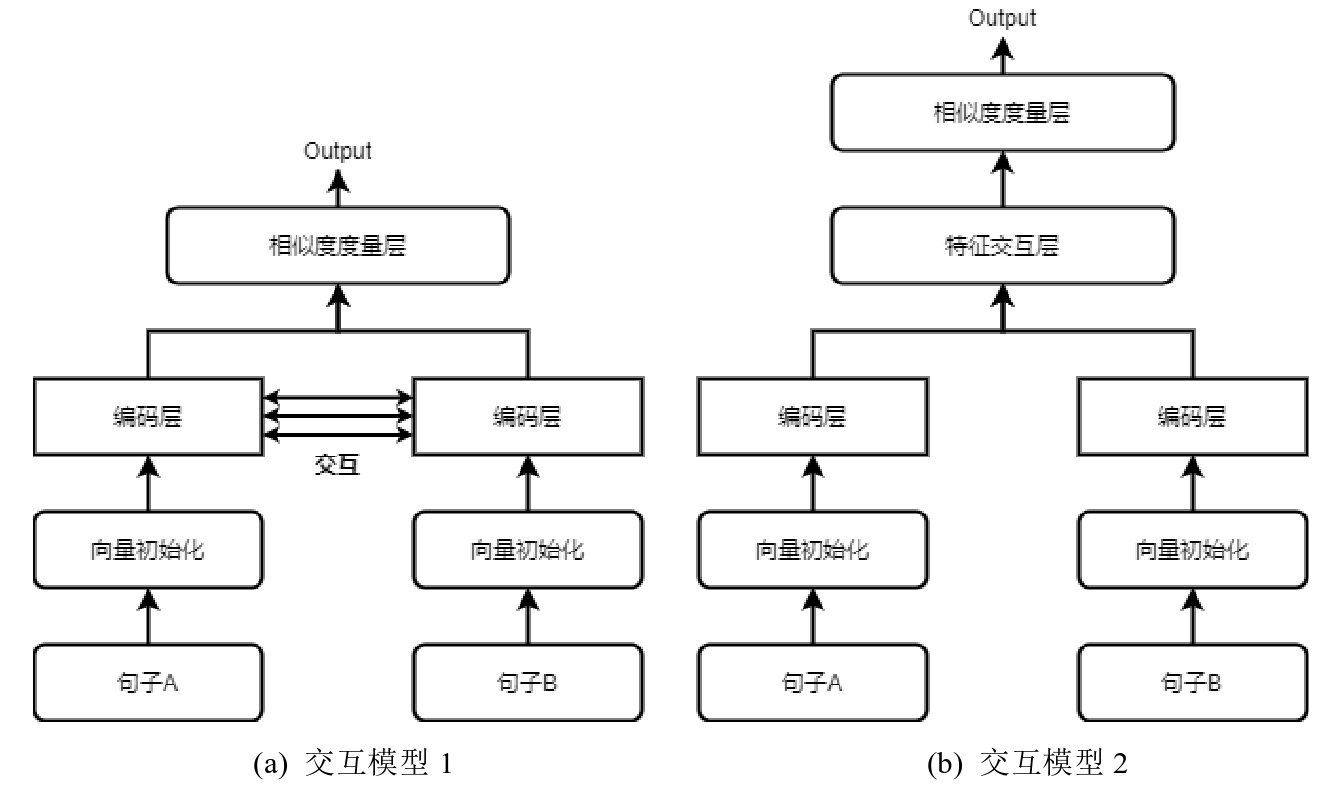
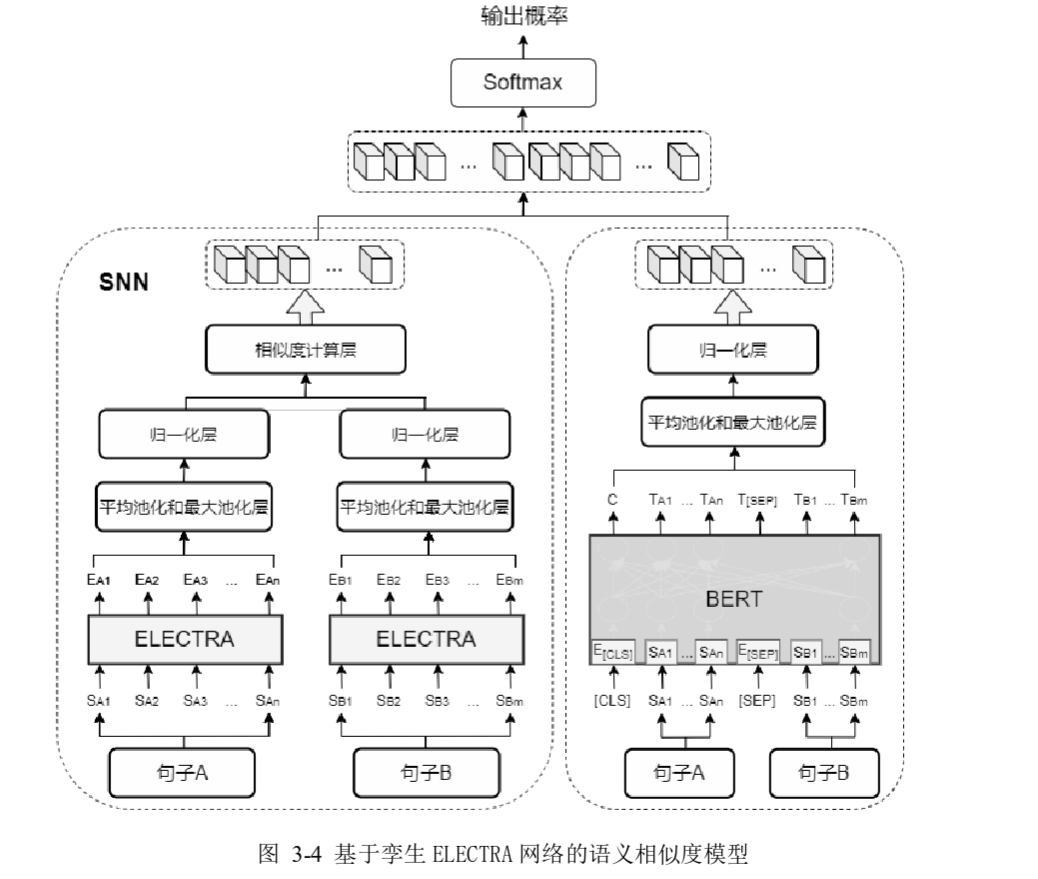
3.2 基于孪生ELETRA网络的语义相似度交互模型结构
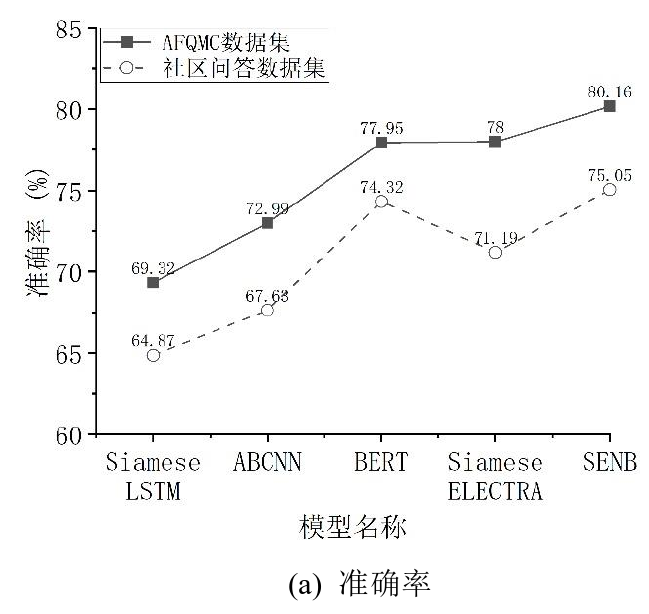
3.3 实验结果分析
3.3.4 评价指标







![[附源码]计算机毕业设计的疫苗接种管理系统Springboot程序](https://img-blog.csdnimg.cn/9d4de1836492416fac39789dbe127fa7.png)