论文链接:PixelSNAIL: An Improved Autoregressive Generative Model
论文标题:PixelSNAIL: An Improved Autoregressive Generative Model
代码:GitHub - neocxi/pixelsnail-public
GitHub - neocxi/pixelsnail-public
一、问题提出
高维数据上的自回归生成模型x = (x1,……, xn)将联合分布分解为条件的乘积:

训练一个循环神经网络(RNN)来建模p(xi|x1:i−1)。可选地,模型可以以附加的全局信息h为条件(例如类标签,当应用于图像时),在这种情况下,它在模型p(xi|x1:i−1,h)中。这种方法具有高度的表达性,并允许建模复杂的依赖关系。与GANs相比,自回归模型提供了易于处理的似然计算和易于训练,并已被证明优于潜变量模型。主要的设计考虑因素是用于实现RNN的神经网络体系结构,因为它必须能够很容易地引用序列的前面部分。存在以下几种可能性:
传统的RNN,如GRU或LSTM:通过将信息保持在隐藏状态来传播信息,从一个时间步长到下一个时间步长。这种暂时的线性依赖极大地抑制了它们在数据中建模长期关系的程度
Causal convolutions(因果卷积):对序列应用卷积(掩盖或移位,以便当前预测仅受前一个元素的影响)。它们为序列的早期部分提供了高带宽访问。然而,它们感受域是有限的,并且对于序列中较远的元素仍然会经历明显的衰减。
Self-attention:这些模型将序列转换为无序的键值存储,可以根据内容进行查询。它们具有不受限制的接受域,并允许对序列中遥远的信息进行未退化的访问。然而,它们只提供对少量信息的精确访问,并且需要额外的机制来整合位置信息
因果卷积和自我注意表现出互补的优点和缺点:前者允许在有限的上下文大小上进行高带宽访问,后者允许在无限大的上下文上进行访问。因此,将两者交织在一起提供了两全其美的服务,模型可以获得高带宽访问,而不受其有效使用的信息量的限制。
新的架构PixelSNAIL。
二、PixelSNAIL
1、组件

Residual Block对其输入应用几个2d卷积,每个卷积都有残差连接。为了使它们具有因果关系,卷积被mask,以便当前像素只能访问它左边或上面的2个像素。使用类似于的门控激活函数。在整个模型中,每个块使用4个卷积,每个卷积中使用256个filters。
Attention执行单个键值查找。它将输入投影到较低的维度以产生key和value,然后使用softmax-attention(进行了mask,以便当前像素只能关注先前生成的像素)。使用大小为16的键和大小为128的值。
2、架构

仅在CIFAR-10模型中,在每个残差块的第一次卷积后应用了0.5的dropout,以防止过拟合。对于ImageNet没有使用任何dropout,因为数据集要大得多。
三、实验
1、baseline及其NLL损失:

2、生成采样










![[附源码]Nodejs计算机毕业设计基于JAVA语言的国货美妆店管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/c055d467eaa1446eb5b153e1421965a6.png)
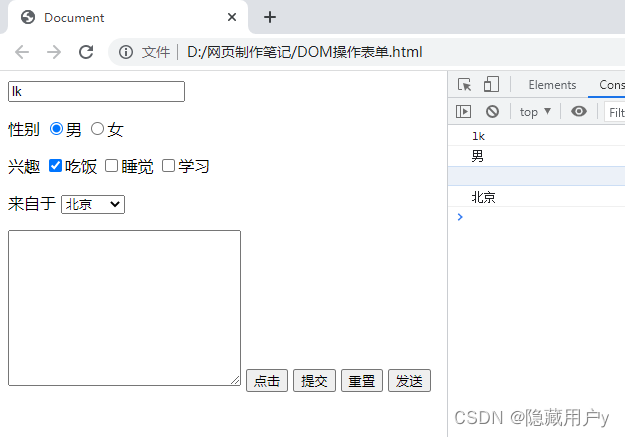

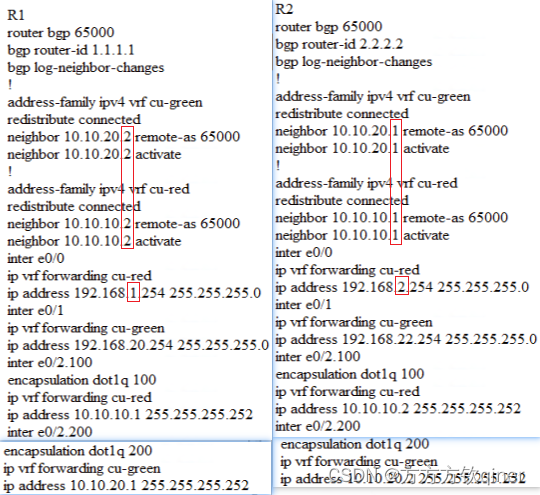
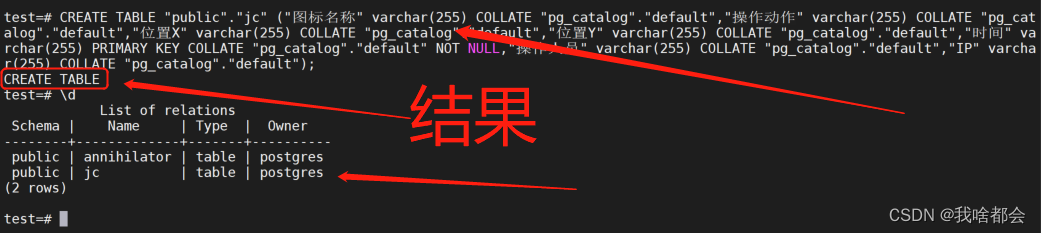
![[附源码]计算机毕业设计的在线作业批改系统Springboot程序](https://img-blog.csdnimg.cn/cb29f2a72d464c4286a6a8afdf35a6d5.png)