资料
- 解决 K8s 调度不均衡问题
- kubernetes pod内容器状态OOMKilled和退出码137全流程解析
集群中pod触发oom的原因
默认pod能够使用节点的全部可用资源。节点的可分配资源如下

Allocatable = Node Capacity - (kube-reserved) - (system-reserved) - (eviction-threshold)
容量资源( Capacity )是指 kubelet 获取的计算节点当前的资源信息。
- CPU 是从 /proc/cpuinfo 文件中获取的节点 CPU 核数;
- memory 是从 /proc/memoryinfo 中获取的节点内存大小;
- ephemeral-storage 是指节点根分区的大小
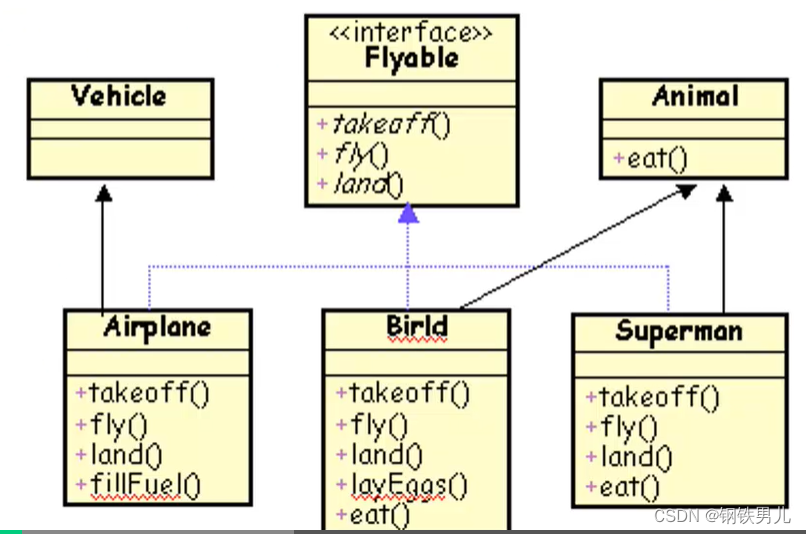
容器的qos介绍略过,需要在container上分别设置
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
pod调度时使用request(下限),设置cgroups限制时使用limits(上限),目的是提升整体资源利用效率
驱逐行为和oom kill的关系
-
Eviction 阈值达到后,节点进入 MemoryPressure 或者 DiskPressure 状态,避免新的pod调度。并且会按照Qos级别对pod进行驱逐具体驱逐优先级是:BestEffort -> Burstable -> Guaranteed。集群的默认阈值如下
memory.available<100Mi nodefs.available<10% nodefs.inodesFree<5% imagefs.available<15% -
由于内存是不可压缩资源,由于内存使用量突增导致内存不足时,pod会因为oom被内核kill掉(此时节点的驱逐状态可能还没来得及触发)。
kubelet 默认每
10秒抓取一次 cAdvisor 的监控数据,所以有可能在 kubelet 驱逐 Pod 回收内存之前发生内存使用量激增的情况,这时就有可能触发内核 OOM killer。当内存资源不足时,kubelet 在驱逐 Pod 时只会考虑 requests 和 Pod 的内存使用量
常见的服务oom分值如下。oom分值越高,被oom kill的优先级越高,-999 和-1000的进程不会被oom kill。
-1000 => sshd -999 => Kubernetes管理进程 -998 => Guaranteed Pod 0 => 其他进程 0 2~999 => Burstable Pod 1000 => BestEffort Pod
oom kill的简单测试
为了查看节点的压力指标,部署metric-server
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
pod的使用量等于其所有业务容器的总和,不包括 pause 容器。执行kubectl top命令得到的结果并不等于pod的总和,也不等于在node上直接运行top命令获得的结果
使用 metrics-server 时,apiserver 通过 /apis/metrics.k8s.io/ 的地址访问 metric
kubectl top node
kubectl top pod pod-name
kubectl top pod pod-name --containers
任务使用内存超出限制,会导致objscore计算kill分数
指定qos之后pod获取资源的行为受到了限制

节点触发驱逐状态

pod长时间超出pod的资源limit就会触发oom killed,可见pod已经重启了10次

在实例上运行dmesg查看日志,看到系统对容器进行了oom kill,在/var/log/message中还能看到那个容器触发了oom kill。此处oom_score_adj打分为-997,尽管优先级很低,由于该进程使用的资源能持续超过cgroup的限制从而被oom kill

如果放开cpu的qos,则会最大程度上使用节点的资源

最终可能会导致节点失联,oom的原因需要具体分析

以上过程存在两个问题
-
kubelet和容器的OOMkilled有什么关系
-
容器的OOMkilled状态最终是如何被apiserver获取?
kubelet和容器的OOMkilled的关系
Kubernetes Pod 驱逐详解
kubelet 默认每 10 秒抓取一次 cAdvisor 的监控数据,可能在 kubelet 驱逐 Pod 回收内存之前发生内存使用量激增的情况,这时就有可能触发内核 OOM killer。
容器的删除从kubelet交接到内核,但是kubelet会决定oom_score_adj的值,从而决定oom_score
容器使用的内存占系统内存的百分比 + oom_score_adj = oom_score
OOM killer 会杀掉 oom_score_adj 值最高的容器,oom_score_adj相同就干掉内存使用最多的容器(oom_score高)
kubect如何获取pod的oom状态
kubernetes pod内容器状态OOMKilled和退出码137全流程解析
- cgroup中的进程运行过程中申请内存并触发缺页异常,如果无法通过在cgroup中回收足够内存就会选择进程kill
- 触发oom时,内核向进程发送SIGKILL信号
- 内核修改进程task_struct,程序对信号进行处理
- containerd-shim监听cgroup内进程的oom事件,进程退出时,内核会向containerd-shim发送SIGCHILD信号,将容器id,进程id,退出码,退出时间等信息通过GRPC消息转发到containerd中
- containerd处理进程和容器退出事件
- kubelet定期对比pod状态的变化,获取容器的退出码/原因,将新的pod状态通过patch方法更新到apiserver

节点问题的监控和修复
pic_center
problem detect
npd(node-problem-detector)是kubernetes的插件,主要目的是检测节点上可能出现的故障,避免pod调度到故障节点上
- 基础设施守护进程故障
- 硬件故障:cpu,内存和磁盘损坏
- 内核故障:内核死锁,文件系统损坏
- 容器运行时故障:未响应的守护进程运行时
npd使用Event和NodeCondition向apiserver汇报
-
NodeCondition:永久性的节点不可用
-
Event:对pod的临时故障影响有限
npd包括子进程(作为goroutine )监控特定类型的节点故障,已经支持的类型如下:
- SystemLogMonitor
- SystemStatsMonitor
- CustomPluginMonitor
- HealthChecker
默认的启动脚本如下
/bin/sh -c exec /node-problem-detector \
--logtostderr \
--config.system-log-monitor=/config/kernel-monitor.json,/config/docker-monitor.json \
--prometheus-address=0.0.0.0 \
--prometheus-port=20257 \
--k8s-exporter-heartbeat-period=5m0s
部署方式如下
helm repo add deliveryhero https://charts.deliveryhero.io/
helm install --generate-name deliveryhero/node-problem-detector
向内核设备测试写入
sudo sh -c "echo 'kernel: BUG: unable to handle kernel NULL pointer dereference at TESTING' >> /dev/kmsg"
查看eks集群节点的event能够发现相关错误信息,及时追踪和排查

remedy system
npd仓库推荐了两个插件用来对故障集群进行补救
Draino
能够根据节点的标签和条件自动排空节点。需要和npd共同使用。当 Node Problem Detector检测到节点故障,draino发现故障后立即cordon节点并排空。之后通过ca替换节点
Descheduler
能够对不均衡的调度
kube-scheduler的调度是静态的,pod一旦完成调度旧不会重新触发调度,由于pod在运行过程中会不断消耗内存,集群中运行过程中可能会出现资源使用不均衡的问题。
descheduler能够对由于新加入节点,节点故障和污点标签重新调度的pod进行再平衡。


![[ vulhub漏洞复现篇 ] GhostScript 沙箱绕过(任意命令执行)漏洞CVE-2019-6116](https://img-blog.csdnimg.cn/67495553f1bf4447b4fcb1e570c16e5f.png)


![[技巧]还在使用RDP远程windows?OpenSSH远程win10操作系统!](https://img-blog.csdnimg.cn/df0bbf8213464b95b348cf4efdf402e3.png)