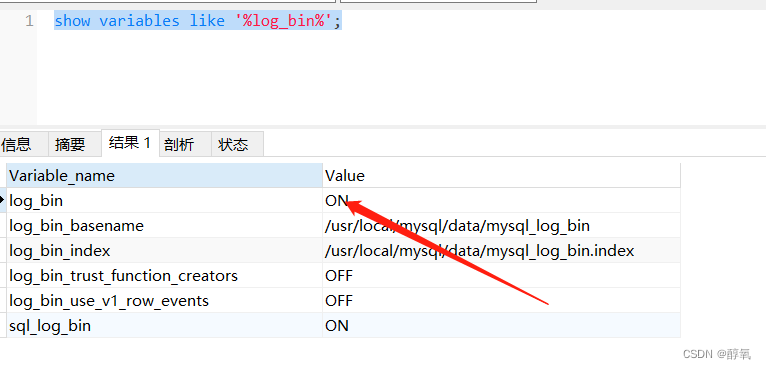
策略梯度
策略梯度(Policy Gradient)方法梯度的计算如下:
E
(
a
t
,
s
t
)
∈
π
θ
[
A
^
t
∇
θ
log
π
θ
(
a
t
∣
s
t
)
]
\mathbb E_{(a_t,s_t) \in \pi_\theta}[\hat A_t \nabla_ \theta \log \pi_\theta(a_t | s_t)]
E(at,st)∈πθ[A^t∇θlogπθ(at∣st)]
A
^
t
\hat A_t
A^t是优势函数(advantage function)
A
t
A_t
At的估计。
A
t
=
Q
(
s
t
,
a
t
)
−
V
(
s
t
)
A_t=Q(s_t, a_t)-V(s_t)
At=Q(st,at)−V(st)优势函数计算的是,在该状态下采取这个行动的奖励与在该状态下的平均奖励的差值。
上面的导数可以通过对下面的目标求导获得:
L
P
G
(
θ
)
=
E
(
a
t
,
s
t
)
∈
π
θ
[
A
^
t
log
π
θ
(
a
t
∣
s
t
)
]
L^{PG}(\theta)=\mathbb E_{(a_t,s_t) \in \pi_\theta}[\hat A_t \log \pi_\theta(a_t | s_t)]
LPG(θ)=E(at,st)∈πθ[A^tlogπθ(at∣st)]
PPO(Proximal Policy Optimization)
PPO有两个形式,其中一种形式PPO_CLIP的优化目标函数是:
L
C
L
I
P
(
θ
)
=
E
(
a
t
,
s
t
)
∈
π
θ
[
min
(
r
t
(
θ
)
A
^
t
,
c
l
i
p
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
^
t
)
]
(1)
L^{CLIP}(\theta)=\mathbb E_{(a_t,s_t) \in \pi_\theta}[\min(r_t(\theta)\hat A_t, clip(r_t(\theta), 1-\epsilon, 1+\epsilon)\hat A_t)] \tag{1}
LCLIP(θ)=E(at,st)∈πθ[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)](1)其中
r
t
(
θ
)
=
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
r_t(\theta)=\frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)}
rt(θ)=πθold(at∣st)πθ(at∣st)。
PPO算法中的advantage用下面的公式估计:
A
^
t
=
δ
t
+
(
γ
λ
)
δ
t
+
1
+
⋯
+
(
γ
λ
)
T
−
t
+
1
δ
T
−
1
\hat A^t = \delta^t + (\gamma \lambda)\delta_{t+1} + \cdots+ (\gamma \lambda)^{T-t+1}\delta_{T-1}
A^t=δt+(γλ)δt+1+⋯+(γλ)T−t+1δT−1其中
δ
t
=
r
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)
δt=rt+γV(st+1)−V(st)。
通常情况下,我们用一个网络学习策略和价值函数,这样策略和价值函数能共享参数,那么就需要结合策略代理和价值函数误差项的损失函数。再加上熵奖励(entropy bonus)来以确保足够的探索,优化目标变为:
L
C
L
I
P
+
V
F
+
S
(
θ
)
=
E
(
a
t
,
s
t
)
∈
π
θ
[
L
t
C
L
I
P
(
θ
)
−
c
1
L
t
V
F
(
θ
)
+
c
2
S
[
π
θ
]
(
s
t
)
]
L^{CLIP+VF+S}(\theta)=\mathbb E_{(a_t,s_t) \in \pi_\theta}[L_t^{CLIP}(\theta) - c_1 L_t^{VF}(\theta) + c_2 S[\pi_\theta](s_t)]
LCLIP+VF+S(θ)=E(at,st)∈πθ[LtCLIP(θ)−c1LtVF(θ)+c2S[πθ](st)]其中
L
t
V
F
(
θ
)
=
(
V
θ
(
s
t
)
−
V
t
t
a
r
g
)
2
L_t^{VF}(\theta)=(V_\theta(s_t)-V_t^{targ})^2
LtVF(θ)=(Vθ(st)−Vttarg)2是价值函数的误差项,S是entropy bonus。
文本生成
在文本生成的情况下,给一个prompt,生成完整的response,是一个episode。动作空间是vocabulary。每生成一个词是一个时间步。
公式(1)需要advantage的估计,为了计算advantage,我们需要定义奖励(reward) r r r和估计状态价值函数 V ( s ) V(s) V(s)。
用于强化学习的reward计算如下:
R
(
x
,
y
)
=
r
(
x
,
y
)
−
β
log
π
(
y
∣
x
)
ρ
(
y
∣
x
)
R(x,y) = r(x,y) - \beta\log\frac{\pi(y|x)}{\rho(y|x)}
R(x,y)=r(x,y)−βlogρ(y∣x)π(y∣x)x是问题,y是回答,
r
(
x
,
y
)
r(x,y)
r(x,y)是reward model的输出,也就是下面代码中的score。注意这里reward model的输出称之为score,送入强化学习部分的才称为reward。
π
(
y
∣
x
)
\pi(y|x)
π(y∣x)是要学习的生成模型,
ρ
(
y
∣
x
)
\rho(y|x)
ρ(y∣x)是参数固定的原始生成模型。
在trl库中reward的计算如下:
def compute_rewards(
self,
scores: torch.FloatTensor,
logprobs: torch.FloatTensor,
ref_logprobs: torch.FloatTensor,
masks: torch.LongTensor,
):
"""
Compute per token rewards from scores and KL-penalty.
Args:
scores (`torch.FloatTensor`):
Scores from the reward model, shape (`batch_size`)
logprobs (`torch.FloatTensor`):
Log probabilities of the model, shape (`batch_size`, `response_length`)
ref_logprobs (`torch.FloatTensor`):
Log probabilities of the reference model, shape (`batch_size`, `response_length`)
"""
rewards, non_score_rewards = [], []
for score, logprob, ref_logprob, mask in zip(scores, logprobs, ref_logprobs, masks):
# compute KL penalty (from difference in logprobs)
kl = self._kl_penalty(logprob, ref_logprob)
non_score_reward = -self.kl_ctl.value * kl
non_score_rewards.append(non_score_reward)
reward = non_score_reward.clone()
last_non_masked_index = mask.nonzero()[-1]
# reward is preference model score + KL penalty
reward[last_non_masked_index] += score
rewards.append(reward)
return torch.stack(rewards), torch.stack(non_score_rewards)
可以看到上面的实现中,只将reward model的score添加到最后一个token的reward上,其他token的reward来自当前模型和 原始生成模型之间KL散度。这么做是为了减轻奖励模型的过度优化问题。
在trl库中用一个网络AutoModelForCausalLMWithValueHead学习策略
π
θ
(
s
)
\pi_\theta(s)
πθ(s)和状态价值函数
V
(
s
)
V(s)
V(s)。AutoModelForCausalLMWithValueHead在普通AutoModelForCausalLM模型上了一个线性层nn.Linear(hidden_size, 1),用于估计状态价值函数
V
(
s
)
V(s)
V(s)。
普通AutoModelForCausalLM模型估计token概率即可作为策略
π
θ
(
s
)
\pi_\theta(s)
πθ(s)。
在trl库中advantage的计算如下:
def compute_advantages(
self: torch.FloatTensor,
values: torch.FloatTensor, # AutoModelForCausalLMWithValueHead输出的状态价值估计V
rewards: torch.FloatTensor, # compute_rewards函数计算得到的rewards
mask: torch.FloatTensor,
):
lastgaelam = 0
advantages_reversed = []
gen_len = rewards.shape[-1]
values = values * mask
rewards = rewards * mask
for t in reversed(range(gen_len)):
nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0
delta = rewards[:, t] + self.config.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.config.gamma * self.config.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1)
returns = advantages + values
advantages = masked_whiten(advantages, mask)
advantages = advantages.detach()
return values, advantages, returns
完整的PPO算法如下:

Reference
Proximal Policy Optimization Algorithms
Fine-Tuning Language Models from Human Preferences
Training language models to follow instructions with human feedback
https://github.com/huggingface/trl