文章目录
- 前言
- 一、双链表的思路
- 二、带头循环双链表的实现分析
- 二、带头循环双链表的实现1
- 1.带头循环双链表实现头文件总览
- 2.带头循环双链表的初始化
- 3.带头循环双链表的插入
- 4.带头循环双链表的打印和销毁
- 5.带头循环双链表的查找和删除
- 三、带头循环双链表的实现2
- 1.带头循环双链表实现2的结构体
- 2.带头循环双链表实现函数改动
- 四、带头循环双链表的隐藏封装
- 1.带头循环双链表隐藏封装的头文件预览
- 2.带头循环双链表函数改动
- 五、带头循环双链表封装为库
- 1.带头循环双链表封装为库的头文件预览
- 2.带头循环双链表函数实现的源文件
- 3.带头循环双链表封装成库
- 六、对内核双链表部分分析来快速实现一个双链表
- 1.对内核双链表部分分析
- 2.快速来实现一个简单的带头循环双链表
- 七、双链表实现2的代码
- 1.双链表实现2的代码的头文件
- 2.双链表实现2的函数实现源文件
- 3.双链表实现2的主函数源文件
- 总结
前言
相信经过前面的学习,大家已经了解的单链表的缺陷和用途,今天我们学习双链表,和以前不同,今天双链表的实现我们增加一点点的难度,但我相信这些难度对大家都没有问题。和之前单链表的实现,我们的数据类型是固定的,主函数中传什么我们的单链表结构体中就需要相应的数据类型, 今天双链表的实现我们将改为主函数(用户)传任何的数据类型我们都可以接收并且实现。
本章涉及函数指针,回调函数,柔性数组的知识点,忘记的小伙伴们可以在本章复习一下哟。
链表在空间上的存储方式:
一、双链表的思路
在实现之前我们先来认识双链表:
什么是双链表: 双链表的结点中有两个指针prev和next,分别指向前驱结点和后继结点。
双链表的优点: 解决了单链表要访问某个结点的前驱结点时,只能从头开始遍历,访问后继结点的复杂度为O(1),访问前驱结点的复杂度为O(n)的问题。
双链表的结构:

不循环的双链表中,头节点或双链表中的第一个节点无前驱节点,最后一个节点无后继节点。头节点是不存储有效数据的!!!
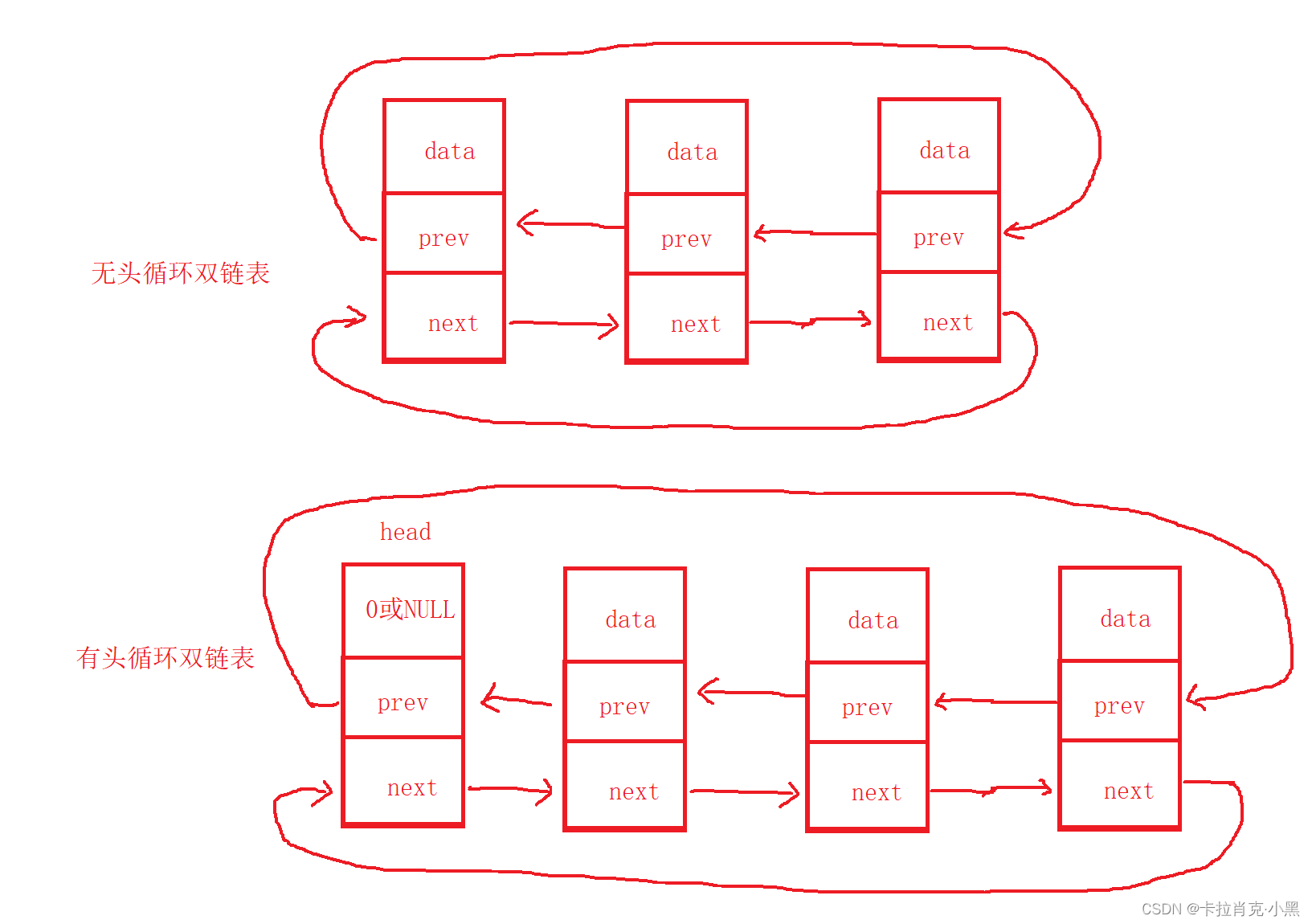
在循环的双链表中,头节点或双链表中的第一个节点前驱节点为最后一个节点,最后一个节点后继节点为头节点或双链表中的第一个节点。头节点是不存储有效数据的!!!
相信经过结构我们已经有了大体的实现思路了,而我们今天要实现的是双链表中最完美的结构,带头循环的双链表,也是日后我们常用的结构。
二、带头循环双链表的实现分析
我们要实现用户(主函数)所传的任何数据类型都可以构成我们的双链表,所以用户构成双链表数据域的类型是未知的,那么我们要构建什么类型的数据呢? 我们选择char类型的指针,又会有一个新问题,用户传入的是整形或者结构体char类型的指针又要如何应对呢?针对上述问题我们设计两个结构体:
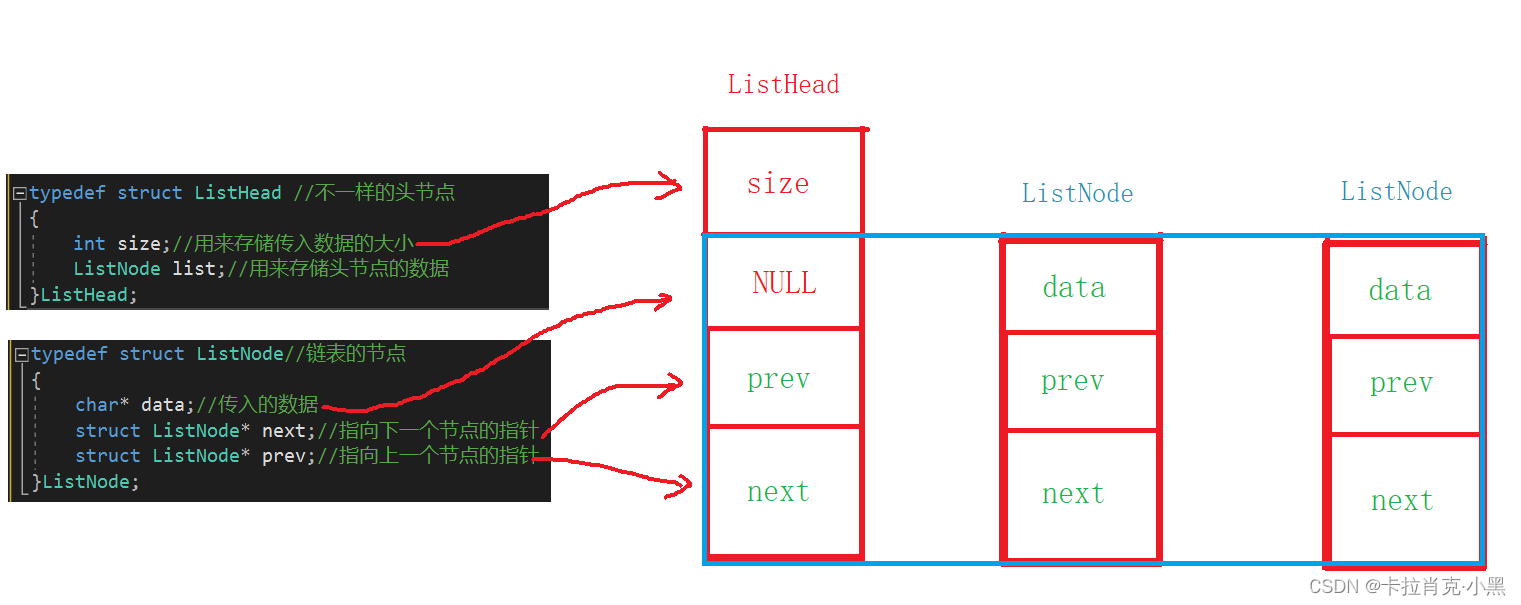
这是我们设计的结构体,由于我们头节点不存储数据,又和其他节点不太一样,那又该如何指向呢?
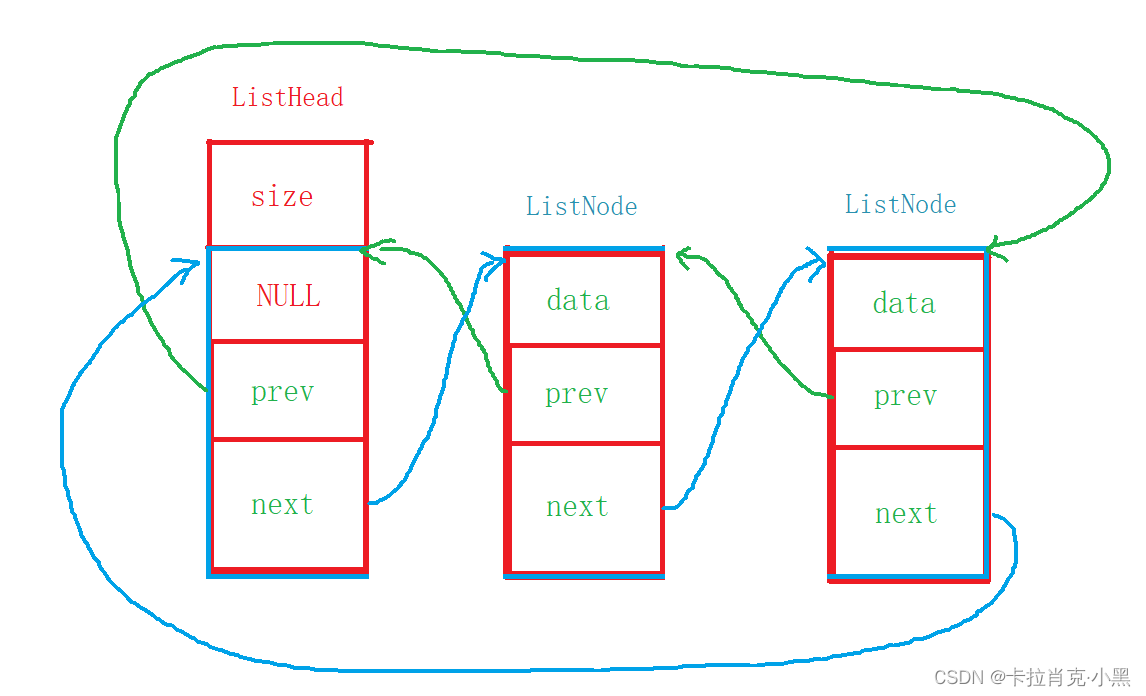
我们指针指向的是位置,我们把尾节点和第一个有效节点的指针都指向头节点的链表节点成员的位置。这样我们的链表就实现循环了。
二、带头循环双链表的实现1
1.带头循环双链表实现头文件总览
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<time.h>
#define HEADINSERTION 1 //头插选项
#define BACKINSERTION 2 //尾插选项
typedef struct ListNode//链表的节点
{
char* data;//传入的数据
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
}ListNode;
typedef struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
ListNode list;//用来存储头节点的数据
}ListHead;
typedef void Printf(const void* );//对用户传递的打印函数进行重命名
typedef int Cmp(const void*, const void*);//对用户传递的打印函数进行重命名
ListHead* ListCreate(int datasize);//用来创建特殊的头节点
void Destory(ListHead* pHead);// 双向链表销毁
void ListPrint(ListHead* pHead, Printf* print);// 双向链表打印
int ListInsert(ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* ListFind(ListHead* pHead, const void* key,Cmp* cmp);//双向链表查找
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp,void* retu);//双向链表删除,并把删除节点返回
我们先看头文件里的函数,至于为什么这样设计。我们在下面一一解答。
2.带头循环双链表的初始化
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
ListHead* pHead = (ListHead*)malloc(sizeof(ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;//用来接收用户要构建链表的数据区的大小
pHead->list.data = NULL;//头节点不存储有效数据,所以置为NULL
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
return pHead;
}
我们初始化时要构建我们特殊的头节点,我们只有知道用户要构建数据区的大小,才可以为后面的插入开辟空间。
3.带头循环双链表的插入
//pos:用来接收用户所传数据,由于用户所传数据未知,所以我们用void指针进行接收
//Optional:插入选择,接收用户是头插还是尾插
//#define HEADINSERTION 1 //头插选项,在我们的头文件中定义的
//#define BACKINSERTION 2 //尾插选项,在我们的头文件中定义的
int ListInsert(ListHead* pHead, const void* pos, int Optional)//双向链表的插入
{
assert(pHead);
ListNode* node = (ListNode*)malloc(sizeof(ListNode));
if (node == NULL)//开辟空间失败就报错结束
{
perror("node malloc");//节点开辟失败
return 1;//返回值为1代表节点开辟失败
}
node->data = (char*)malloc(sizeof(char) * pHead->size);//数据区的开辟,开辟的大小为用户所传的大小
if (node->data == NULL)
{
free(node);//释放开辟好的节点,防止内存泄露
perror("node->data malloc");//数据域开辟失败,进行报错
return 2;//返回值为2代表节点开辟成功,但数据区开辟失败
}
memcpy(node->data, (char*)pos,pHead->size);//把数据拷贝到我们开的节点中
if (HEADINSERTION == Optional)//判断是否为头插
{
node->next = (pHead->list).next;
node->prev = &(pHead->list);//取头节点中的链表节点地址
}
else if (BACKINSERTION == Optional)//判断是否为尾插
{
node->next = &pHead->list;
node->prev = pHead->list.prev;
}
else
{
free(node->data);//释放开辟好的数据区
free(node);//释放开辟好的节点,防止内存泄露
return 3;//返回值为3代表插入位置不符合要求
}
node->prev->next = node;
node->next->prev = node;
return 0;//代表此函数正常结束
}
在工程中我们随便指定位置插入是不合法的行为,因为链表元素内容未知,随便插入容易破坏结构,所以我们这里就实现尾插和头插。我们插入指向头节点都是指向头节点中双链表节点的位置,而不是指向从size开始的位置!!!
我们实现头插和尾插是根据用户选择实现的,这里不必在分为两个函数来进行实现。
在工程中我们要在函数中少使用打印函数,这里我们通过返回值返回,用户可以通过返回值来判断是什么原因出错。保证了我们函数的单一性。
用户所传的数据区是未知的,所以我们要用库函数memcpy或者strcpy函数进行拷贝。
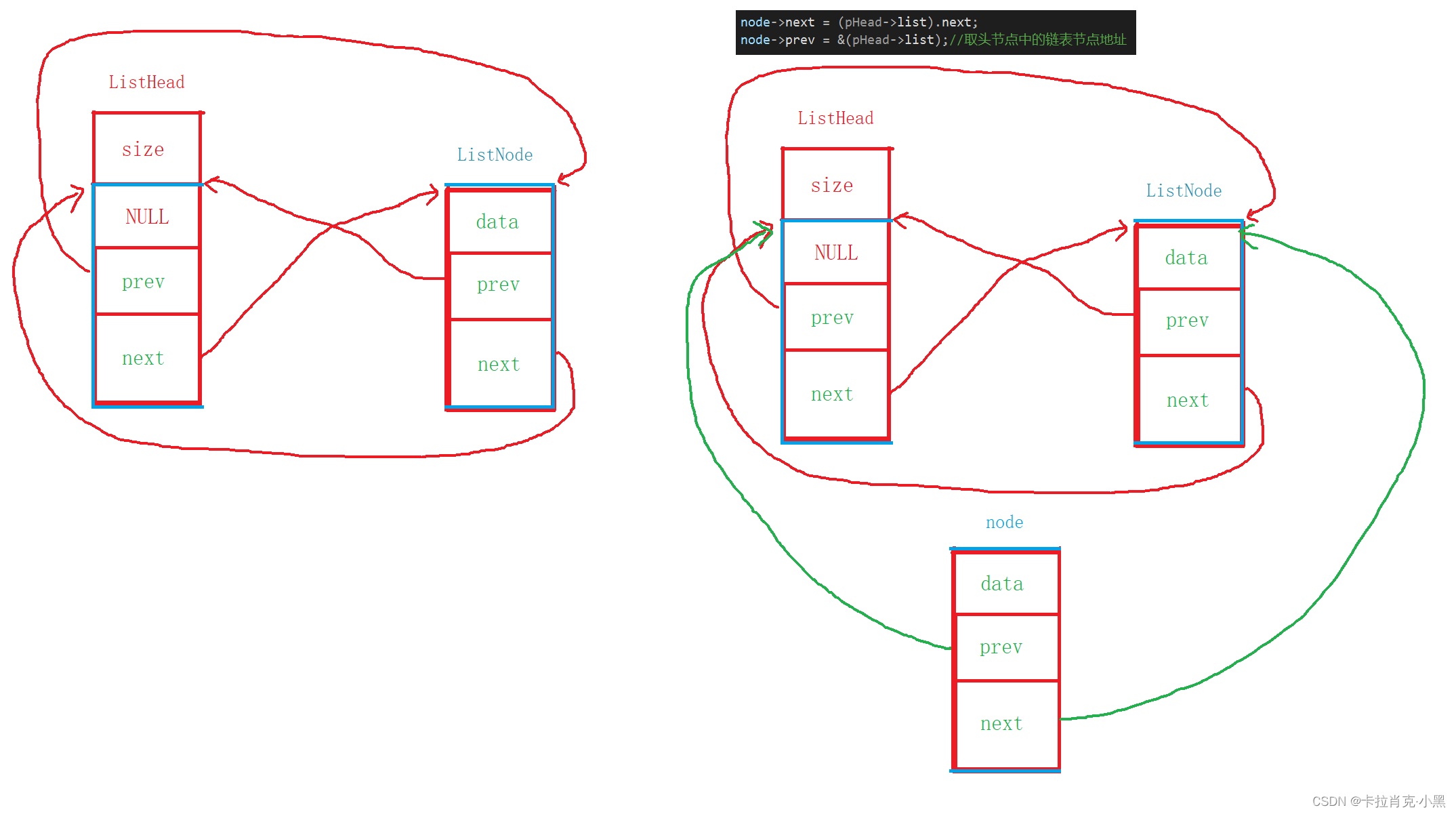
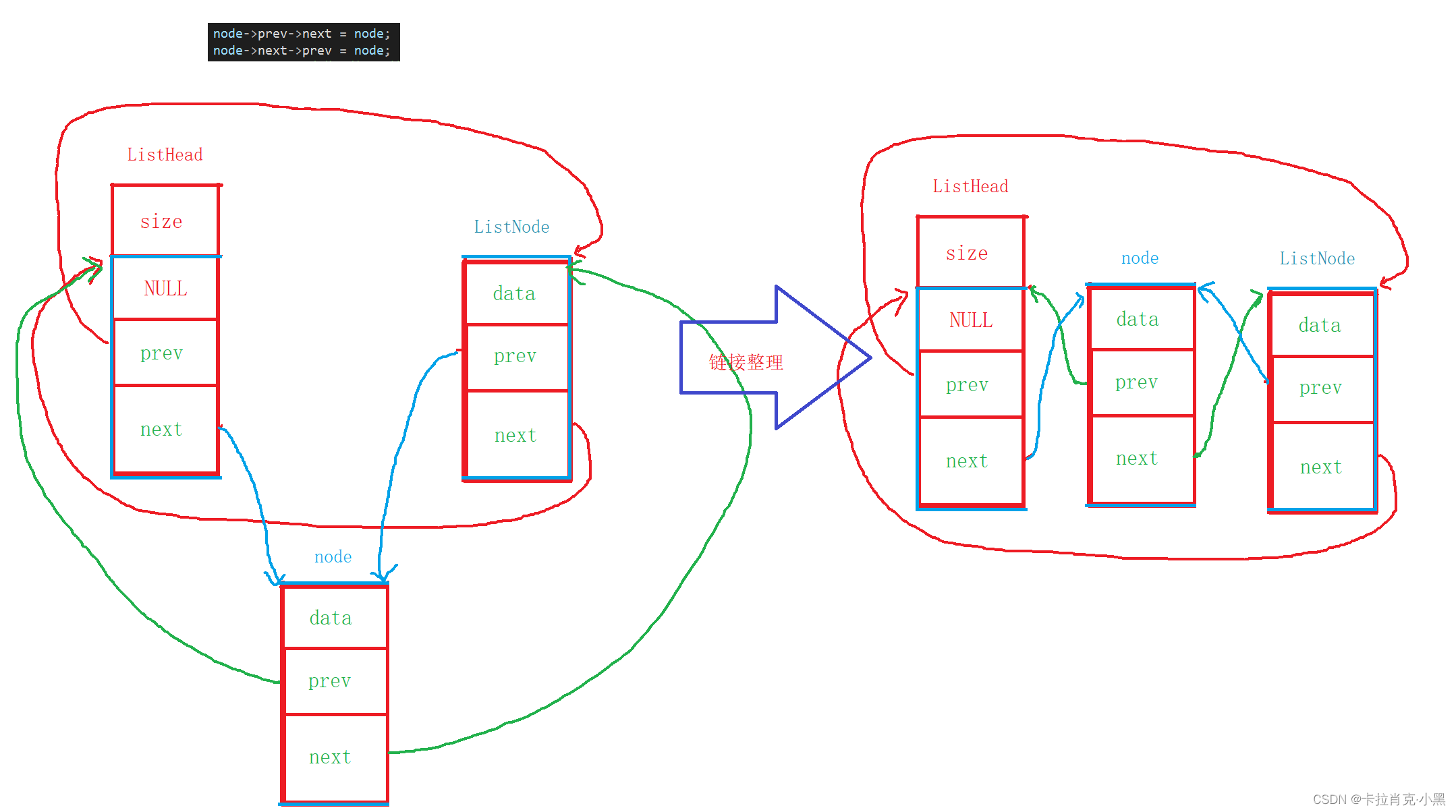
这里头插和尾插实现思路相同,大家可以画一画。我们要注意当我们双链表节点开辟成功时,但数据区为开辟失败时要对开辟的节点进行释放,否则造成内存泄露。
4.带头循环双链表的打印和销毁
void Destory(ListHead* pHead)// 双向链表销毁
{
assert(pHead);
ListNode* pos = (&pHead->list)->next;//从头节点的下一个节点开始
while (pos != &pHead->list)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del->data);//data数据也是动态开辟的
free(del);//释放节点
}
}
void ListPrint(ListHead* pHead, Printf * print)// 双向链表打印,使用回调函数
{
assert(pHead);
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
print(pos->data);//调用用户提供的打印函数
pos = pos->next;
}
}
这里判断是否是头节点都是通过双链表节点和头节点中的双链表节点的地址进行比较。
我们未知用户类型的情况下如何进行打印?
这里通过回调函数进行,由于我们未知用户数据类型,但是用户知道,所以我们可以设置函数类型,让用户自己实现,然后我们通过回调函数调用。
我们头文件的这个重命名函数就在这里起作用了
typedef void Printf(const void* );//对用户传递的打印函数进行重命名
//void Printf(const void* );//用户需要实现的函数
//typedef对该函数进行重命名
下面是测试函数:
#define NAME_SIZE 32
typedef struct Stu
{
int id;
char name[NAME_SIZE];
int math;
int chinese;
}Stu;
void Printf_s(const void* print)//用户写的打印函数
{
Stu* prin = (Stu*)print;//把void类型转换为用户的类型
printf("id:%2d name:%s math:%2d chinese:%2d\n",prin->id, prin->name, prin->math, prin->chinese);
}
void test1()
{
ListHead* pHead = ListCreate(sizeof(Stu));
Stu stu;
int i = 0;
for (i = 0; i < 5; i++)
{
stu.id = i;
snprintf(stu.name, NAME_SIZE, "stu%d:", i);
stu.math = rand()%100;
stu.chinese = rand()%100;
ListInsert(pHead, &stu, 1);//传入1,进行头插
//ListInsert(pHead, &stu, 2);//传入2,进行尾插
}
ListPrint(pHead, Printf_s);// 双向链表打印
Destory(pHead);// 双向链表销毁
}
int main()
{
srand((unsigned)time(NULL));
test1();
return 0;
}
头插:
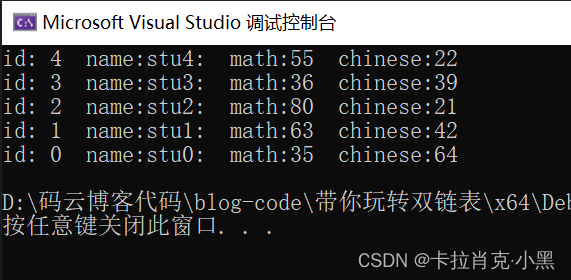
尾插:

我们对成绩是随机取值的,所以两次结果不同,我们这里的给字符串数组赋值用的方法和单链表的方法相同。这里就不多介绍了。
5.带头循环双链表的查找和删除
ListNode* find(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
if (cmp(key, pos->data) == 0)//调用用户提供的比较函数
{
break;
}
pos = pos->next;
}
return pos;//如果找到时,循环终止,返回值为找到的节点,如果找不到,则返回pos为头节点。
}
void* ListFind(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
return (void*)find(pHead, key, cmp)->data;//返会我们的数据区。如果返回的头节点,头节点的值为NULL。不影响我们正常判断
}
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp)//双向链表删除
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del->data);//我们的数据区也是动态开辟的,所以也要内存释放
free(del);
return 0;
}
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp, void* retu)//双向链表删除,并把删除节点返回
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
if (del->data != NULL)
{
memcpy(retu, del->data, pHead->size);//通过函数参数返回
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del->data);
free(del);
return 0;
}
我们要实现查找和删除,都需要先找到节点,所以我们单独创建一个函数,用来返回查找的节点。因为我们未知要比较的类型,所以需要接收用户要比较的类型和用户所提供的比较函数,来实现我们的查找。
我们头节点是不含有效数据的,我们把头节点的数据设置为空,所以查找是如果找不到,我们返回的数据就是头节点的数据(NULL)。
我们删除函数设置了两个,一个是直接删除,一个是删除并把删除的值返回给用户,这两实现思路相同,只是一个多加了一个参数。
typedef int Cmp(const void*, const void*);//对用户传递的比较函数进行重命名
测试函数:
#define NAME_SIZE 32
typedef struct Stu
{
int id;
char name[NAME_SIZE];
int math;
int chinese;
}Stu;
void Printf_s(const void* print)//用户写的打印函数
{
Stu* prin = (Stu*)print;
printf("id:%2d name:%s math:%2d chinese:%2d\n",prin->id, prin->name, prin->math, prin->chinese);
}
int cmp_id(const void* s1, const void*s2)//用户写的比较函数
{
int *key = (int*)s1;
Stu *stu = (Stu*)s2;
return (*key - stu->id);
}
int cmp_name(const void* s1, const void* s2)//用户写的name比较函数
{
char* key = (char*)s1;
Stu* stu = (Stu*)s2;
return strcmp(key, stu->name);
}
void test1()
{
ListHead* pHead = ListCreate(sizeof(Stu));
Stu stu;
int i = 0;
for (i = 0; i < 5; i++)
{
stu.id = i;
snprintf(stu.name, NAME_SIZE, "stu%d:", i);
stu.math = rand()%100;
stu.chinese = rand()%100;
ListInsert(pHead, &stu, 1);//传入1,进行头插
//ListInsert(pHead, &stu, 2);//传入2,进行尾插
}
ListPrint(pHead, Printf_s);// 双向链表打印
printf("\n\n");
//链表元素的查找,通过id查找
int id = 3;
Stu *st = ListFind(pHead, &id, cmp_id);
if (st == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(st);
}
//链表元素的删除,通过id删除
printf("\n\n");
Listdestroy(pHead, &id, cmp_id);
ListPrint(pHead, Printf_s);
//链表元素的删除并且返回,通过姓名删除
printf("\n\n");
char* p = "stu2:";//不要忘了加分号
Stu *s = &stu;
Listtravel(pHead, p, cmp_name, s);
if (s == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(s);
}
printf("\n\n");
ListPrint(pHead, Printf_s);
Destory(pHead);// 双向链表销毁
}
int main()
{
srand((unsigned)time(NULL));
test1();
return 0;
}
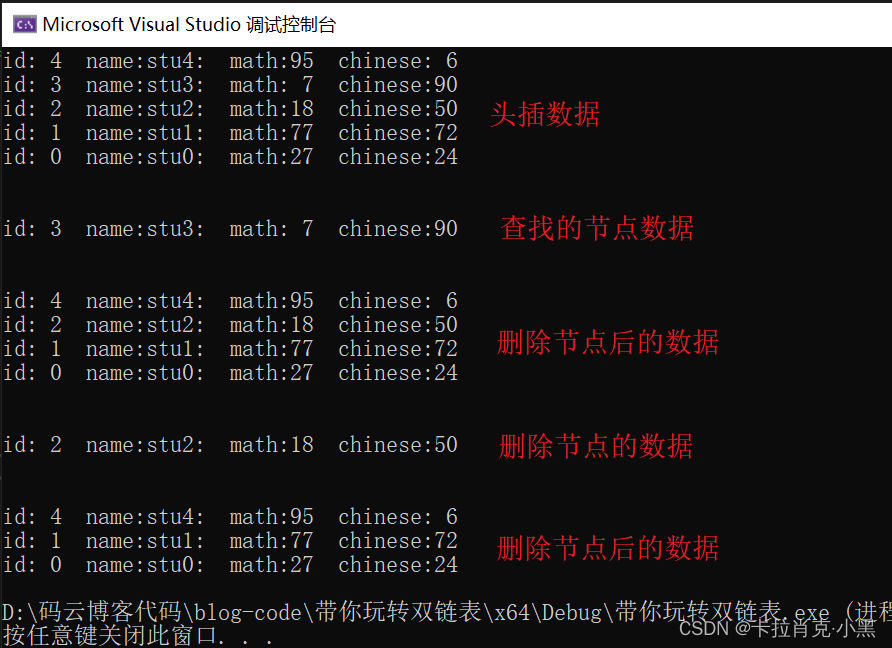
为了验证我们可以首任何类型,这里我们分别用id删除和姓名删除,这里的实现思路和qsort库函数相同。
三、带头循环双链表的实现2
第一种方法我们是通过动态内存开辟的空间。能否不动态开辟我们的数据区的空间呢,答案是肯定的,我们第二种思路就是通过不动态开辟数据区来实现我们的双链表。
我们第二种的思路基于第一种函数实现进行改动,测试函数和为改动的函数保持不变就可以了!!!
1.带头循环双链表实现2的结构体
typedef struct ListNode//链表的节点
{
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
char data[];//传入的数据
//char data[1];//传入的数据
}ListNode;
typedef struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
ListNode list;//用来存储头节点的数据
}ListHead;
这里我们通过柔性数组实现,如果编译器不支持柔性数组,可以把数组中的元素个数赋值为1。
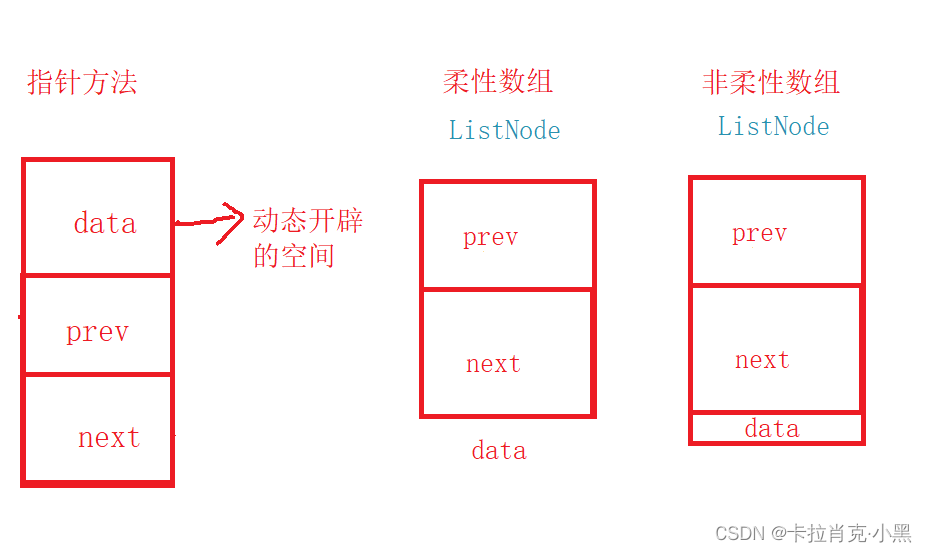
在这里,我们data的目的是为了站一个位置,方便我们寻找数据区的地址。
2.带头循环双链表实现函数改动
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
ListHead* pHead = (ListHead*)malloc(sizeof(ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
return pHead;
}
在这里我们的数据区已经不需要动态开辟空间了,所以这里不需要赋值了。
void Destory(ListHead* pHead)// 双向链表销毁
{
assert(pHead);
ListNode* pos = (&pHead->list)->next;//从头节点的下一个节点开始
while (pos != &pHead->list)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del);
}
}
int ListInsert(ListHead* pHead, const void* pos, int Optional)//双向链表的插入
{
assert(pHead);
ListNode* node = (ListNode*)malloc(sizeof(ListNode)+pHead->size);//申请一个节点结构体的大小加上用户所传数据大小
if (node == NULL)//开辟空间失败就报错结束
{
perror("node malloc");//节点开辟失败
return 1;//返回值为1代表节点开辟失败
}
memcpy(node->data, (char*)pos,pHead->size);//把数据拷贝到我们开的节点中
if (HEADINSERTION == Optional)//判断是否为头插
{
node->next = (pHead->list).next;
node->prev = &(pHead->list);
}
else if (BACKINSERTION == Optional)//判断是否为尾插
{
node->next = &pHead->list;
node->prev = pHead->list.prev;
}
else
{
return 2;//返回值为3代表插入位置不符合要求
}
node->prev->next = node;
node->next->prev = node;
return 0;//代表此函数正常结束
}
这里我们要把释放开辟空间的函数删除,我们只需要为双链表结构体开辟两个指针的空间和用户传入数据的空间大小就可以了。
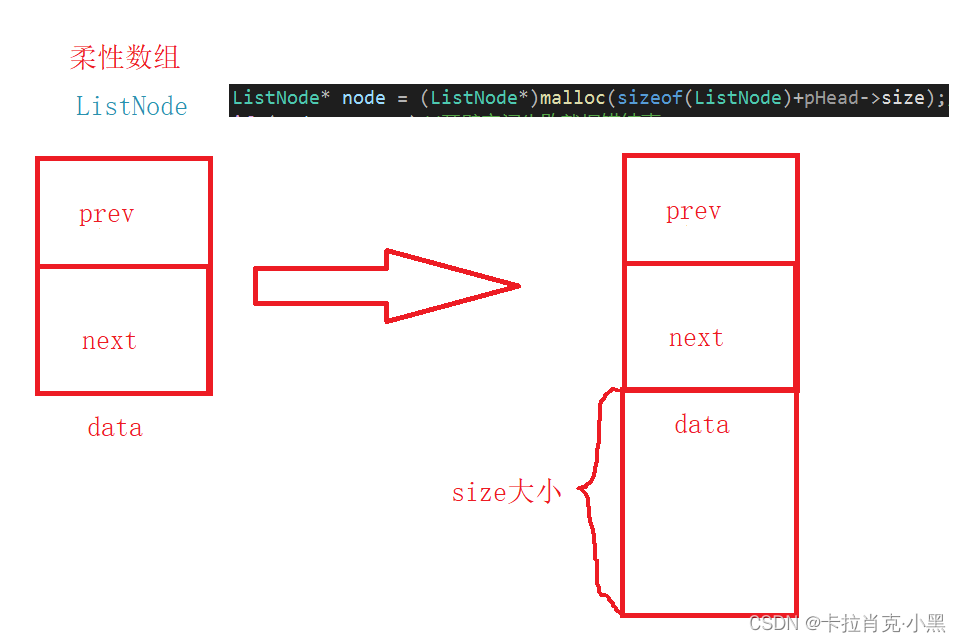
我们拷贝的数据就是放入到data区域里。
void* ListFind(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
ListNode* pos = find(pHead, key, cmp);
if (pos == &pHead->list)//如果是头节点,则证明没找到
{
return NULL;
}
return pos->data;//返会我们的数据区。
}
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp)//双向链表删除
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp, void* retu)//双向链表删除,并把删除节点返回
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
if (del->data != NULL)
{
memcpy(retu, del->data, pHead->size);//通过函数参数返回
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
这里我们删除释放数据区开辟内存和释放内存的函数,且要加上是否是头节点的判断,因为我们头节点没有data区的内存。
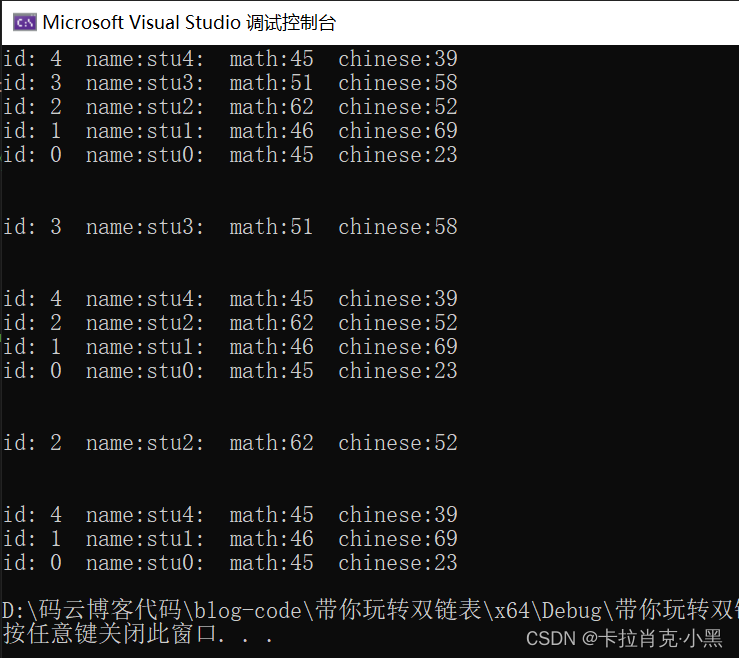
运行测试:
四、带头循环双链表的隐藏封装
我们隐藏封装是在实现二的基础上进行改动!!!
1.带头循环双链表隐藏封装的头文件预览
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<time.h>
#define HEADINSERTION 1 //头插选项
#define BACKINSERTION 2 //尾插选项
typedef void Printf(const void*);//对用户传递的打印函数进行重命名
typedef int Cmp(const void*, const void*);//对用户传递的打印函数进行重命名
typedef struct ListNode//链表的节点
{
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
char data[];//传入的数据
}ListNode;
typedef struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
void (*destory)(struct ListHead* pHead);//双向链表销毁
void (*listprint)(struct ListHead* pHead, Printf* print);//双向链表打印
int (*listinsert)(struct ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* (*listfind)(struct ListHead* pHead, const void* key, Cmp* cmp);//双向链表查找
int (*listdestroy)(struct ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int (*listtravel)(struct ListHead* pHead, const void* key, Cmp* cmp, void* retu);//双向链表删除,并把删除节点返回
ListNode list;//用来存储头节点的数据,柔性数组,这个必须放在最下方
}ListHead;
ListHead* ListCreate(int datasize);//用来创建特殊的头节点
在这里我们把我们要实现的函数全部设置为函数指针,这样函数用户可以通过结构体直接调用,而不知道我们函数具体如何实现的
2.带头循环双链表函数改动
我们是在二的基础上进行改动,所以我们这里只展示改动的代码。
//提前声明
void Destory(struct ListHead* pHead);// 双向链表销毁
void ListPrint(struct ListHead* pHead, Printf* print);// 双向链表打印
int ListInsert(struct ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* ListFind(struct ListHead* pHead, const void* key,Cmp* cmp);//双向链表查找
int Listdestroy(struct ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int Listtravel(struct ListHead* pHead, const void* key, Cmp* cmp,void* retu);//双向链表删除,并把删除节点返回
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
ListHead* pHead = (ListHead*)malloc(sizeof(ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
pHead->destory = Destory;//把我们封装函数指针指向相应的函数
pHead->listprint = ListPrint;
pHead->listinsert = ListInsert;
pHead->listfind = ListFind;
pHead->listdestroy = Listdestroy;
pHead->listtravel = Listtravel;
return pHead;
}
我们对函数指针进行赋值时,要先对我们要指向的函数进行声明,这样不会进行报错。
测试函数的修改:
#define NAME_SIZE 32
typedef struct Stu
{
int id;
char name[NAME_SIZE];
int math;
int chinese;
}Stu;
void Printf_s(const void* print)//用户写的打印函数
{
Stu* prin = (Stu*)print;
printf("id:%2d name:%s math:%2d chinese:%2d\n",prin->id, prin->name, prin->math, prin->chinese);
}
int cmp_id(const void* s1, const void*s2)//用户写的id比较函数
{
int *key = (int*)s1;
Stu *stu = (Stu*)s2;
return (*key - stu->id);
}
int cmp_name(const void* s1, const void* s2)//用户写的name比较函数
{
char* key = (char*)s1;
Stu* stu = (Stu*)s2;
return strcmp(key,stu->name);
}
void test1()
{
ListHead* pHead = ListCreate(sizeof(Stu));
Stu stu;
int i = 0;
for (i = 0; i < 5; i++)
{
stu.id = i;
snprintf(stu.name, NAME_SIZE, "stu%d:", i);
stu.math = rand()%100;
stu.chinese = rand()%100;
pHead->listinsert(pHead, &stu, 2);
}
pHead->listprint(pHead, Printf_s);// 双向链表打印
//链表元素的查找,通过id查找
printf("\n\n");
int id = 3;
Stu *st = pHead->listfind(pHead, &id, cmp_id);
if (st == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(st);
}
//链表元素的删除,通过id删除
printf("\n\n");
pHead->listdestroy(pHead, &id, cmp_id);
pHead->listprint(pHead, Printf_s);
//链表元素的删除,通过姓名删除
printf("\n\n");
char* p = "stu2:";//不要忘了加分号
Stu *s = &stu;
pHead->listtravel(pHead, p, cmp_name, s);
if (s == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(s);
}
printf("\n\n");
pHead->listprint(pHead, Printf_s);
pHead->destory(pHead);// 双向链表销毁
}
int main()
{
srand((unsigned)time(NULL));
test1();
return 0;
}
我们需要把我们通过函数实现的部分换位结构体的调用。
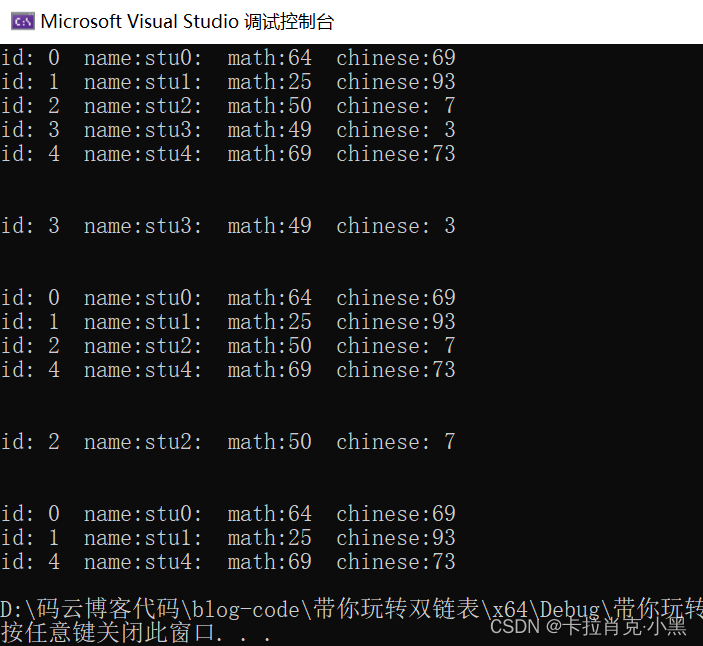
五、带头循环双链表封装为库
我们封装为库也是在实现二的基础上进行改动的!!!
1.带头循环双链表封装为库的头文件预览
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<time.h>
#define HEADINSERTION 1 //头插选项
#define BACKINSERTION 2 //尾插选项
//可以做出成一个动态库或静态库,不需要知道我们的结构体类型就可以操作构建一个结构体
typedef void ListHead;// 把void类型改为ListHead,我们函数进行传参都是用的void
typedef void Printf(const void* );//对用户传递的打印函数进行重命名
typedef int Cmp(const void*, const void*);//对用户传递的打印函数进行重命名
ListHead* ListCreate(int datasize);//用来创建特殊的头节点
void Destory(ListHead* pHead);// 双向链表销毁
void ListPrint(ListHead* pHead, Printf* print);// 双向链表打印
int ListInsert(ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* ListFind(ListHead* pHead, const void* key,Cmp* cmp);//双向链表查找
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp,void* retu);//双向链表删除,并把删除节点返回
这里我们实现了我们结构体的隐藏,用户不知道我们的结构体类型,只知道我们函数可以实现什么的功能,且传入的参数都是void指针类型。这里避免用户知道我们的结构体类型进而进行改动。我们把结构体类型放入到我们实现函数的源文件中。
2.带头循环双链表函数实现的源文件
typedef struct ListNode//链表的节点
{
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
char data[];//传入的数据
}ListNode;
struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
ListNode list;//用来存储头节点的数据
};
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
struct ListHead* pHead = (struct ListHead*)malloc(sizeof(struct ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
return pHead;
}
void Destory(ListHead* p)// 双向链表销毁
{
assert(p);
struct ListHead *pHead = p;
ListNode* pos = (&pHead->list)->next;//从头节点的下一个节点开始
while (pos != &pHead->list)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del);
}
}
void ListPrint(ListHead* p, Printf * print)// 双向链表打印,使用回调函数
{
assert(p);
struct ListHead* pHead = p;
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
print(pos->data);//调用用户提供的打印函数
pos = pos->next;
}
}
int ListInsert(ListHead* p, const void* pos, int Optional)//双向链表的插入
{
assert(p);
struct ListHead* pHead = p;
ListNode* node = (ListNode*)malloc(sizeof(ListNode)+pHead->size);//申请一个节点结构体的大小加上用户所传数据大小
if (node == NULL)//开辟空间失败就报错结束
{
perror("node malloc");//节点开辟失败
return 1;//返回值为1代表节点开辟失败
}
memcpy(node->data, (char*)pos,pHead->size);//把数据拷贝到我们开的节点中
if (HEADINSERTION == Optional)//判断是否为头插
{
node->next = (pHead->list).next;
node->prev = &(pHead->list);
}
else if (BACKINSERTION == Optional)//判断是否为尾插
{
node->next = &pHead->list;
node->prev = pHead->list.prev;
}
else
{
return 2;//返回值为3代表插入位置不符合要求
}
node->prev->next = node;
node->next->prev = node;
return 0;//代表此函数正常结束
}
ListNode* find(ListHead* p, const void* key, Cmp* cmp)//双向链表查找
{
assert(p);
struct ListHead* pHead = p;
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
if (cmp(key, pos->data) == 0)//调用用户提供的比较函数
{
break;
}
pos = pos->next;
}
return pos;//如果找到时,循环终止,返回值为找到的节点,如果找不到,则返回pos为头节点。
}
void* ListFind(ListHead* p, const void* key, Cmp* cmp)//双向链表查找
{
assert(p);
struct ListHead* pHead = p;
ListNode* pos = find(pHead, key, cmp);
if (pos == &pHead->list)//如果是头节点,则证明没找到
{
return NULL;
}
return pos->data;//返会我们的数据区。
}
int Listdestroy(ListHead* p, const void* key, Cmp* cmp)//双向链表删除
{
assert(p);
struct ListHead* pHead = p;
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
int Listtravel(ListHead* p, const void* key, Cmp* cmp, void* retu)//双向链表删除,并把删除节点返回
{
assert(p);
struct ListHead* pHead = p;
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
if (del->data != NULL)
{
memcpy(retu, del->data, pHead->size);//通过函数参数返回
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
我们改动的地方就是在我们实现的函数中把void类型指针转换位我们自己结构体的类型。
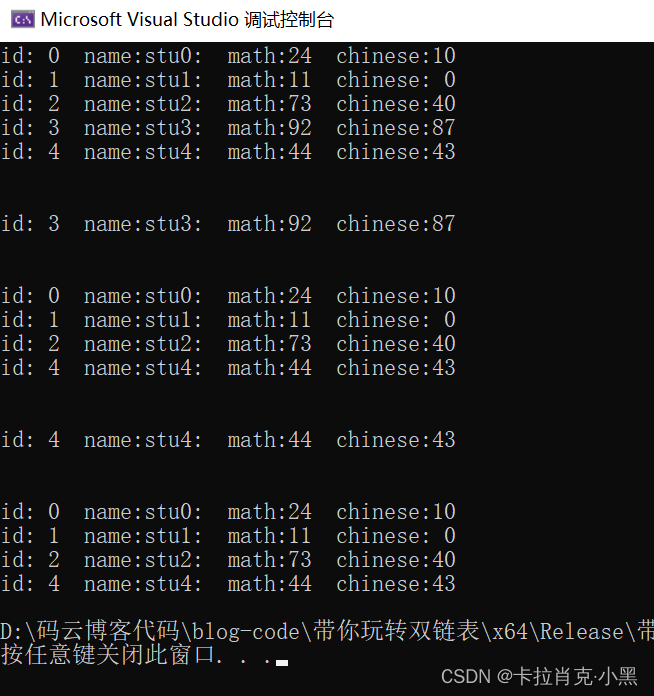
我们测试函数用的和我们实现2一样。
3.带头循环双链表封装成库
1、找到项目,选择属性,在配置属性里,将配置类型改为静态库 (.lib)。
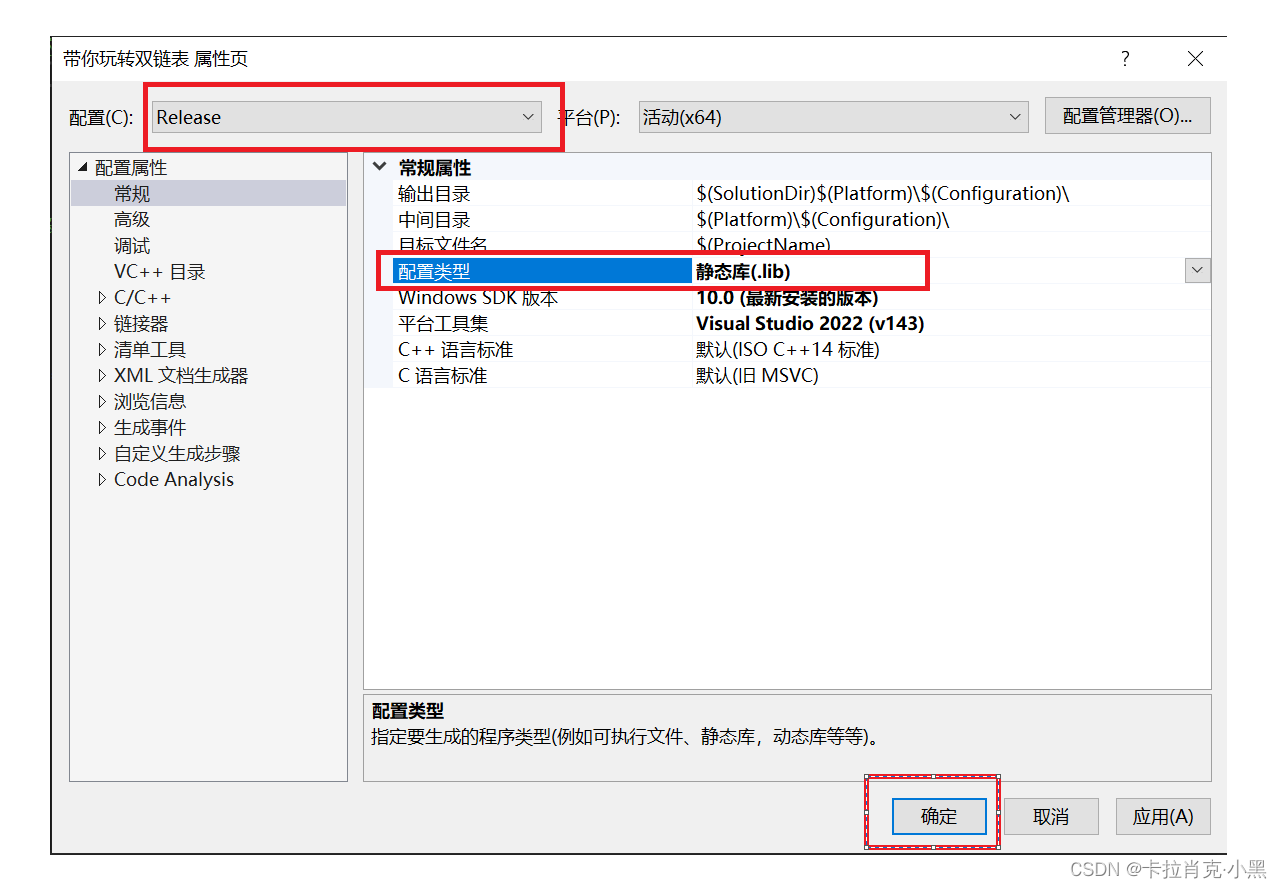
2、生成
3、在我们这个项目文件中找到我们的.lib文件,即为生成的静态库。
六、对内核双链表部分分析来快速实现一个双链表
1.对内核双链表部分分析

在链表中最重要的时节点指针,我们看内核中的链表结构,里面没有数据区,我们要创建双链表需要我们把他的结构体包含在我们的结构体中。可以出现在我们结构体中的任何位置。
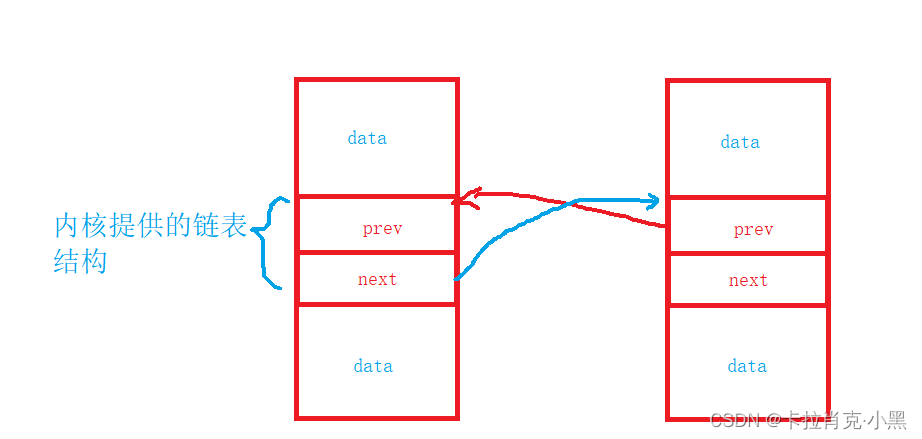

在这里实现的头插和尾插都是定义的一个函数,然后调用这个函数实现我们插入删除
2.快速来实现一个简单的带头循环双链表
typedef struct ListNode//链表的节点
{
int data;
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
}ListNode;
ListNode* ListCreate()//用来创建头节点
{
ListNode* pHead = (ListNode*)malloc(sizeof(ListNode));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->data = 0;
pHead->next = pHead;//后继节点指向自己
pHead->prev = pHead;//前驱节点指向自己
return pHead;
}
void Destory(ListNode* pHead)// 双向链表销毁
{
assert(pHead);
ListNode* pos = pHead->next;//从头节点的下一个节点开始
while (pos != pHead)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del);//释放节点
}
}
void ListPrint(ListNode* pHead)// 双向链表打印
{
assert(pHead);
ListNode* pos = pHead->next;//从头节点的下一个节点开始
while (pos != pHead)
{
printf("%d->", pos->data);
pos = pos->next;
}
printf("\n");
}
void ListInsert(ListNode* pos, int key)//双向链表的插入
{
assert(pos);
ListNode* init = (ListNode*)malloc(sizeof(ListNode));
if (init == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
init->data = key;
init->next = pos->next;
init->prev = pos;
pos->next->prev = init;
pos->next = init;
}
void Listdestroy(ListNode* pHead,ListNode* pos)//双向链表删除
{
assert(pos);
if (pos == pHead)
{
return;
}
ListNode* del = pos;
pos->prev->next = pos->next;
pos->next->prev = pos->prev;
free(del);
}
void SListPushBack(ListNode* pHead, int x)//单链表尾插
{
assert(pHead);
ListInsert(pHead->prev, x);
}
void SListPushFront(ListNode* pHead, int x)//单链表的头插
{
assert(pHead);
ListInsert(pHead, x);
}
void SListPopBack(ListNode* pHead)// 单链表的尾删
{
assert(pHead);
Listdestroy(pHead,pHead->prev);
}
void SListPopFront(ListNode* pHead)// 单链表头删
{
assert(pHead);
Listdestroy(pHead,pHead->next);
}
ListNode* ListFind(ListNode* pHead, int key)//双向链表查找
{
assert(pos);
ListNode* pos = pHead->next;
while (pos != pHead)
{
if (pos->data == key)
{
return pos;
}
pos = pos->next;
}
return NULL;
}
根据上面的代码我们可以看出我们只需要实现双链表的插入和删除就把双链表的大部分功能实现了。
相信通过这么多的案例和练习,大家对双链表的实现和用途都有了解了,自己动手实现一下吧。
七、双链表实现2的代码
由于我们的后面封装和构成库都是通过2来进行改变的,我们把实现2的代码来具体看看一下把
1.双链表实现2的代码的头文件
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<time.h>
#define HEADINSERTION 1 //头插选项
#define BACKINSERTION 2 //尾插选项
typedef struct ListNode//链表的节点
{
struct ListNode* next;//指向下一个节点的指针
struct ListNode* prev;//指向上一个节点的指针
char data[];//传入的数据
//char data[1];//传入的数据
}ListNode;
typedef struct ListHead //不一样的头节点
{
int size;//用来存储传入数据的大小
ListNode list;//用来存储头节点的数据
}ListHead;
typedef void Printf(const void* );//对用户传递的打印函数进行重命名
typedef int Cmp(const void*, const void*);//对用户传递的打印函数进行重命名
ListHead* ListCreate(int datasize);//用来创建特殊的头节点
void Destory(ListHead* pHead);// 双向链表销毁
void ListPrint(ListHead* pHead, Printf* print);// 双向链表打印
int ListInsert(ListHead* pHead, const void* pos, int Optional);//双向链表的插入
void* ListFind(ListHead* pHead, const void* key,Cmp* cmp);//双向链表查找
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp);//双向链表删除
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp,void* retu);//双向链表删除,并把删除节点返回
2.双链表实现2的函数实现源文件
#include"main2.h"
ListHead* ListCreate(int datasize)//用来创建特殊的头节点
{
ListHead* pHead = (ListHead*)malloc(sizeof(ListHead));
if (pHead == NULL)//开辟空间失败就报错结束
{
perror("pHead malloc");
exit(-1);
}
pHead->size = datasize;
pHead->list.next = &pHead->list;//后继节点指向自己
pHead->list.prev = &pHead->list;//前驱节点指向自己
return pHead;
}
void Destory(ListHead* pHead)// 双向链表销毁
{
assert(pHead);
ListNode* pos = (&pHead->list)->next;//从头节点的下一个节点开始
while (pos != &pHead->list)
{
ListNode* del = pos;//要释放的节点
pos = pos->next;//保存下一个节点
free(del);
}
}
void ListPrint(ListHead* pHead, Printf * print)// 双向链表打印,使用回调函数
{
assert(pHead);
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
print(pos->data);//调用用户提供的打印函数
pos = pos->next;
}
}
int ListInsert(ListHead* pHead, const void* pos, int Optional)//双向链表的插入
{
assert(pHead);
ListNode* node = (ListNode*)malloc(sizeof(ListNode)+pHead->size);//申请一个节点结构体的大小加上用户所传数据大小
if (node == NULL)//开辟空间失败就报错结束
{
perror("node malloc");//节点开辟失败
return 1;//返回值为1代表节点开辟失败
}
memcpy(node->data, (char*)pos,pHead->size);//把数据拷贝到我们开的节点中
if (HEADINSERTION == Optional)//判断是否为头插
{
node->next = (pHead->list).next;
node->prev = &(pHead->list);
}
else if (BACKINSERTION == Optional)//判断是否为尾插
{
node->next = &pHead->list;
node->prev = pHead->list.prev;
}
else
{
return 2;//返回值为3代表插入位置不符合要求
}
node->prev->next = node;
node->next->prev = node;
return 0;//代表此函数正常结束
}
ListNode* find(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
ListNode* pos = pHead->list.next;
while (pos != &pHead->list)//判断是否走到头节点
{
if (cmp(key, pos->data) == 0)//调用用户提供的比较函数
{
break;
}
pos = pos->next;
}
return pos;//如果找到时,循环终止,返回值为找到的节点,如果找不到,则返回pos为头节点。
}
void* ListFind(ListHead* pHead, const void* key, Cmp* cmp)//双向链表查找
{
assert(pHead);
ListNode* pos = find(pHead, key, cmp);
if (pos == &pHead->list)//如果是头节点,则证明没找到
{
return NULL;
}
return pos->data;//返会我们的数据区。
}
int Listdestroy(ListHead* pHead, const void* key, Cmp* cmp)//双向链表删除
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
int Listtravel(ListHead* pHead, const void* key, Cmp* cmp, void* retu)//双向链表删除,并把删除节点返回
{
assert(pHead);
ListNode* del = find(pHead, key, cmp);
if (del == &pHead->list)
{
return 1;//代表未找到我们要删除的节点
}
if (del->data != NULL)
{
memcpy(retu, del->data, pHead->size);//通过函数参数返回
}
//删除节点
del->prev->next = del->next;
del->next->prev = del->prev;
free(del);
return 0;
}
3.双链表实现2的主函数源文件
#include"main2.h"
#define NAME_SIZE 32
typedef struct Stu
{
int id;
char name[NAME_SIZE];
int math;
int chinese;
}Stu;
void Printf_s(const void* print)//用户写的打印函数
{
Stu* prin = (Stu*)print;
printf("id:%2d name:%s math:%2d chinese:%2d\n",prin->id, prin->name, prin->math, prin->chinese);
}
int cmp_id(const void* s1, const void*s2)//用户写的比较函数
{
int *key = (int*)s1;
Stu *stu = (Stu*)s2;
return (*key - stu->id);
}
int cmp_name(const void* s1, const void* s2)//用户写的name比较函数
{
char* key = (char*)s1;
Stu* stu = (Stu*)s2;
return strcmp(key, stu->name);
}
void test1()
{
ListHead* pHead = ListCreate(sizeof(Stu));
Stu stu;
int i = 0;
for (i = 0; i < 5; i++)
{
stu.id = i;
snprintf(stu.name, NAME_SIZE, "stu%d:", i);
stu.math = rand()%100;
stu.chinese = rand()%100;
ListInsert(pHead, &stu, 1);//传入1,进行头插
//ListInsert(pHead, &stu, 2);//传入2,进行尾插
}
ListPrint(pHead, Printf_s);// 双向链表打印
//链表元素的查找,通过id查找
printf("\n\n");
int id = 3;
Stu *st = ListFind(pHead, &id, cmp_id);
if (st == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(st);
}
//链表元素的删除,通过id删除
printf("\n\n");
Listdestroy(pHead, &id, cmp_id);
ListPrint(pHead, Printf_s);
//链表元素的删除并且返回,通过姓名删除
printf("\n\n");
char* p = "stu2:";//不要忘了加分号
Stu *s = &stu;
Listtravel(pHead, p, cmp_name, s);
if (s == NULL)
{
printf("can not find\n");
}
else
{
Printf_s(s);
}
printf("\n\n");
ListPrint(pHead, Printf_s);
Destory(pHead);// 双向链表销毁
}
int main()
{
srand((unsigned)time(NULL));
test1();
return 0;
}
总结
相信大家对我们双链表已经有了很深的了解,这个带头循环链表将是我们使用最多的结构,所以这个需要我们深刻理解掌握。欢迎大家留言。感谢支持呀。