目录
- 前言
- 阅读指引
- 阅读建议
- 课程内容
- 一、生成BeanDefinition
- 1.1 简单回顾
- 1.2 概念回顾
- 1.3 核心方法讲解
- 二、方法讲解
- 2.1 ClassPathBeanDefinitionScanner#scan
- 2.2 ClassPathBeanDefinitionScanner#doScan
- 2.3 ClassPathScanningCandidateComponentProvider#findCandidateComponents
- 2.4 ClassPathScanningCandidateComponentProvider#scanCandidateComponents
- 2.5 ClassPathScanningCandidateComponentProvider#isCandidateComponent
- 2.6 ClassPathScanningCandidateComponentProvider#isCandidateComponent
- 2.7 ClassPathBeanDefinitionScanner#postProcessBeanDefinition
- 2.8 AnnotationConfigUtils.processCommonDefinitionAnnotations
- 2.9 ClassPathBeanDefinitionScanner#checkCandidate
- 2.10 DefaultListableBeanFactory#registerBeanDefinition
- 三、扫描逻辑流程图
- 四、合并BeanDefinition
- 学习总结
前言
阅读指引
Spring最重要的功能就是帮助程序员创建对象(也就是IOC),而启动Spring就是为创建Bean对象做准备,所以我们先明白Spring到底是怎么去创建Bean的,也就是先弄明白Bean的生命周期。
Bean的生命周期就是指:在Spring中,一个Bean是如何生成的,如何销毁的。
本节课的内容,将会以下面这段代码为入口讲解:
public class MyApplicationTest {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext("org.tuling.spring");
Object newUser = context.getBean("newUser");
System.out.println(newUser);
}
}
主要用到的是如下Spring容器的构造方法:
/**
* 创建一个新的AnnotationConfigApplicationContext,扫描给定包中的组件,为这些组件注册bean定义,并自动刷新上下文。
* 参数:
* baseppackages——要扫描组件类的包
*/
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
阅读建议
- 看源码,切记纠结细枝末节,不然很容易陷进去。正常来说,看主要流程就好了
- 遇到不懂的,多看看类注释或者方法注释。Spring这种优秀源码,注释真的非常到位
- 如果你是idea用户,多用F11的书签功能。
- Ctrl + F11 选中文件 / 文件夹,使用助记符设定 / 取消书签 (必备)
- Shift + F11 弹出书签显示层 (必备)
- Ctrl +1,2,3…9 定位到对应数值的书签位置 (必备)
课程内容
一、生成BeanDefinition
1.1 简单回顾
如果大家看过我前面的文章,应该会知道,BeanDefiniton的生成,是在生产Bean之前的【扫描】阶段。如下图所示:
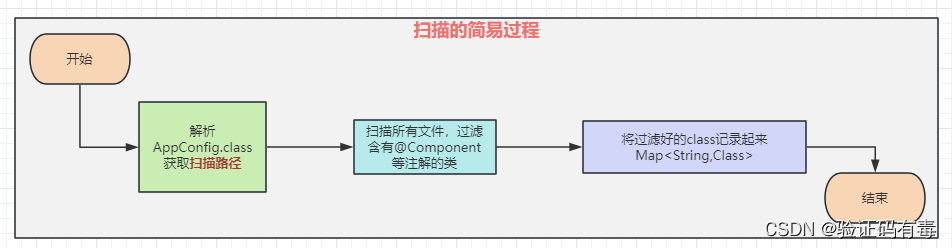
不过咱也说过,这只是简单实现而已,事实上,Spring实现这个扫描过程,涉及到了3个核心类,9个核心方法!
1.2 概念回顾
在这个【扫描】过程中,涉及到了一些Spring底层设计的概念,我在上一个笔记里面有大概介绍过,不记得的同学记得回去翻一翻。
主要涉及的概念有:
- BeanDefinition(设计图纸):BeanDefinition表示Bean定义,BeanDefinition中存在很多属性用来描述一个Bean的特征
- ClassPathBeanDefinitionScanner(图纸注册器):用于注册图纸
- BeanFacotory(Bean工厂):生产Bean。不过实际上,这里用到
DefaultListableBeanFactory这个类的BeanDefinitionRegistry接口的注册能力
文章链接:
《【Spring专题】Spring之底层架构核心概念解析》
1.3 核心方法讲解
我们在前面提到过,整个扫描流程会涉及到【3个核心类,10个核心方法】。下面,我们将会按照调用次序,依次讲解各个方法。
二、方法讲解
整个扫描流程的入口,是下面代码中的scan()方法,而最终调用的是ClassPathBeanDefinitionScanner.scan()
/**
* 创建一个新的AnnotationConfigApplicationContext,扫描给定包中的组件,为这些组件注册bean定义,并自动刷新上下文。
* 参数:
* baseppackages——要扫描组件类的包
*/
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
public void scan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
StartupStep scanPackages = this.getApplicationStartup().start("spring.context.base-packages.scan")
.tag("packages", () -> Arrays.toString(basePackages));
this.scanner.scan(basePackages);
scanPackages.end();
}
2.1 ClassPathBeanDefinitionScanner#scan
全路径:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#scan
方法注释:在指定的基本包中执行扫描
源码如下:
public int scan(String... basePackages) {
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
doScan(basePackages);
// Register annotation config processors, if necessary.
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
但其实真正干活的还不是这里,而是里面的doScan()
2.2 ClassPathBeanDefinitionScanner#doScan
方法调用链:由 2.1中的scan()调用进来
全路径:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan
方法注释:在指定的基包中执行扫描,返回已注册的bean定义。此方法不注册注释配置处理程序,而是将此工作留给调用者。
源码如下:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 寻找候选的BeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 判断是否要设置BeanDefinition属性
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 判断是否要设置通用的注解BeanDefiniton属性
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 判断是否注册BeanDefinition
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
方法解读:这个代码看似很多,其实整体来说比较简单,分为4个步骤
- 先扫描classpath下所有的class,寻找候选的BeanDefinition。至于什么是候选的,后面会讲解
- 遍历找到的候选BeanDefinition,判断是否需要设置BeanDefinition的一些属性。比如默认属性等
- 判断是否要设置通用的注解BeanDefiniton属性
- 判断是否要注册BeanDefinition,毕竟可能出现重复的BeanDefinition
2.3 ClassPathScanningCandidateComponentProvider#findCandidateComponents
方法调用链:由 2.2中的doScan()调用进来
全路径:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#findCandidateComponents
方法注释:扫描类路径上的候选Component。
源码如下:
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
方法解读:这里有一个if-else,但通常都是进入else。if里面的情况我们在业务开发中基本不会用到,这是一个为了加快扫描包的策略,通过使用索引思想。怎么实现呢?就是在resource下新建一个spring.components配置文件(K-V格式)。如下:
org.tuling.spring.bean.User = org.springframework.stereotype.Component
通过直接告诉Spring哪些是候选的Component,免除了扫描所有class文件筛选的过程,从而提升了效率。
2.4 ClassPathScanningCandidateComponentProvider#scanCandidateComponents
方法调用链:由 2.3中的findCandidateComponents()调用进来
全路径:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#scanCandidateComponents
方法注释:扫描类路径上的候选Component。
源码如下:
private Set<org.springframework.beans.factory.config.BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
try {
// 读取类元信息
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 第一层判断是否为候选组件,判断核心为:是否需要过滤
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
// 第二层判断是否为候选组件,判断核心为:是否独立、抽象类等
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
}
catch (FileNotFoundException ex) {
if (traceEnabled) {
logger.trace("Ignored non-readable " + resource + ": " + ex.getMessage());
}
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
方法解读:代码看着很长,实际上很简单。主要分为4个步骤
- 读取类元信息(从磁盘中读取)
- 首先,通过ResourcePatternResolver获得指定包路径下的所有.class文件(Spring源码中将此文件包装成了Resource对象)
- 遍历每个Resource对象
- 利用MetadataReaderFactory解析Resource对象得到MetadataReader(在Spring源码中MetadataReaderFactory具体的实现类为CachingMetadataReaderFactory,MetadataReader的具体实现类为SimpleMetadataReader)
- 判断是否为候选组件,判断核心为:是否需要过滤(第一个
isCandidateComponent)- 利用MetadataReader进行excludeFilters和includeFilters,以及条件注解@Conditional的筛选(条件注解并不能理解:某个类上是否存在@Conditional注解,如果存在则调用注解中所指定的类的match方法进行匹配,匹配成功则通过筛选,匹配失败则pass掉。)
- 筛选通过后,基于metadataReader生成ScannedGenericBeanDefinition
- 判断是否为候选组件,判断核心为:是否独立、抽象类等。(第二个
isCandidateComponent)(注意:他跟上面的isCandidateComponent不是同一个东西,属于方法重载) - 如果筛选通过,那么就表示扫描到了一个Bean,将ScannedGenericBeanDefinition加入结果集
MetadataReader表示类的元数据读取器,主要包含了一个AnnotationMetadata,功能有
- 获取类的名字、
- 获取父类的名字
- 获取所实现的所有接口名
- 获取所有内部类的名字
- 判断是不是抽象类
- 判断是不是接口
- 判断是不是一个注解
- 获取拥有某个注解的方法集合
- 获取类上添加的所有注解信息
- 获取类上添加的所有注解类型集合
2.5 ClassPathScanningCandidateComponentProvider#isCandidateComponent
方法调用链:由 2.4中的scanCandidateComponents()调用进来
全路径:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#isCandidateComponent
方法注释:确定给定的类是否不匹配任何排除筛选器,而匹配至少一个包含筛选器。
源码如下:
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
return false;
}
方法解读:这里只是校验,当前类,是否在过滤器排除选项以内。我估计很多朋友想到的都是@ComponentScan注解里面的includeFilter跟excludeFilter属性。只能说不完全正确。
因为,在我们启动容器创建ClassPathBeanDefinitionScanner也会添加默认的过滤策略。如下所示:
/**
* 注册@Component的默认过滤器。
* 这将隐式注册所有带有@Component元注释的注释,包括@Repository、@Service和@Controller构造型注释。
* 还支持Java EE 6的javax.annotation.ManagedBean和JSR-330的javax.inject.Named注释(如果可用)。
*/
protected void registerDefaultFilters() {
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
2.6 ClassPathScanningCandidateComponentProvider#isCandidateComponent
方法调用链:由 2.4中的scanCandidateComponents()调用进来
全路径:org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#isCandidateComponent
方法注释:确定给定的bean定义是否符合候选条件。默认实现检查类是否不是接口,是否依赖于封闭类。
源码如下:
/**
*确定给定的bean定义是否符合候选条件。
* 默认实现检查类是否不是接口,是否依赖于封闭类。
* 可以在子类中重写。
*/
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
方法解读:这里有2个比较陌生的,那就是,什么是独立类,以及Lookup注解。
- 独立类,及不是普通内部类(静态内部类是独立类)
- Lookup注解,自己去百度使用方法
总结方法,判断是候选Component的条件是:
- 首先是独立类
- 要么是具体的子类,要么就是:有Lookup注解的抽象类
2.7 ClassPathBeanDefinitionScanner#postProcessBeanDefinition
方法调用链:由 2.2中的doScan()调用进来
全路径:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#postProcessBeanDefinition
方法注释:扫描类路径上的候选Component。
源码如下:
/**
* 除了通过扫描组件类检索到的内容之外,还可以对给定的bean定义应用进一步的设置。
*/
protected void postProcessBeanDefinition(AbstractBeanDefinition beanDefinition, String beanName) {
beanDefinition.applyDefaults(this.beanDefinitionDefaults);
if (this.autowireCandidatePatterns != null) {
beanDefinition.setAutowireCandidate(PatternMatchUtils.simpleMatch(this.autowireCandidatePatterns, beanName));
}
}
方法解读:这里主要还初始化了BeanDefinition一些默认属性beanDefinition.applyDefaults(this.beanDefinitionDefaults);
源码如下:
public void applyDefaults(BeanDefinitionDefaults defaults) {
Boolean lazyInit = defaults.getLazyInit();
if (lazyInit != null) {
setLazyInit(lazyInit);
}
setAutowireMode(defaults.getAutowireMode());
setDependencyCheck(defaults.getDependencyCheck());
setInitMethodName(defaults.getInitMethodName());
setEnforceInitMethod(false);
setDestroyMethodName(defaults.getDestroyMethodName());
setEnforceDestroyMethod(false);
}
2.8 AnnotationConfigUtils.processCommonDefinitionAnnotations
方法调用链:由 2.2中的doScan()调用进来
全路径:org.springframework.context.annotation.AnnotationConfigUtils#processCommonDefinitionAnnotations
方法注释:根据注解累类元信息,设置BeanDefinition注解相关属性。
源码如下:
public static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd) {
processCommonDefinitionAnnotations(abd, abd.getMetadata());
}
static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd, AnnotatedTypeMetadata metadata) {
AnnotationAttributes lazy = attributesFor(metadata, Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
}
else if (abd.getMetadata() != metadata) {
lazy = attributesFor(abd.getMetadata(), Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
}
}
if (metadata.isAnnotated(Primary.class.getName())) {
abd.setPrimary(true);
}
AnnotationAttributes dependsOn = attributesFor(metadata, DependsOn.class);
if (dependsOn != null) {
abd.setDependsOn(dependsOn.getStringArray("value"));
}
AnnotationAttributes role = attributesFor(metadata, Role.class);
if (role != null) {
abd.setRole(role.getNumber("value").intValue());
}
AnnotationAttributes description = attributesFor(metadata, Description.class);
if (description != null) {
abd.setDescription(description.getString("value"));
}
}
没啥好解读的,很简单的判断
2.9 ClassPathBeanDefinitionScanner#checkCandidate
方法调用链:由 2.2中的doScan()调用进来
全路径:org.springframework.context.annotation.ClassPathBeanDefinitionScanner#checkCandidate
方法注释:检查给定的候选bean名称,确定是否需要注册相应的bean定义,或者是否与现有定义冲突。
源码如下:
protected boolean checkCandidate(String beanName, BeanDefinition beanDefinition) throws IllegalStateException {
if (!this.registry.containsBeanDefinition(beanName)) {
return true;
}
BeanDefinition existingDef = this.registry.getBeanDefinition(beanName);
BeanDefinition originatingDef = existingDef.getOriginatingBeanDefinition();
if (originatingDef != null) {
existingDef = originatingDef;
}
if (isCompatible(beanDefinition, existingDef)) {
return false;
}
throw new ConflictingBeanDefinitionException("Annotation-specified bean name '" + beanName +
"' for bean class [" + beanDefinition.getBeanClassName() + "] conflicts with existing, " +
"non-compatible bean definition of same name and class [" + existingDef.getBeanClassName() + "]");
}
方法解读:这里正常来说,要么返回true,要么就是重复定义相同名字的Bean然后抛出异常。直接返回false,通常是存在父子容器的情况下。
2.10 DefaultListableBeanFactory#registerBeanDefinition
方法调用链:由 2.2中的doScan()调用进来
全路径:org.springframework.beans.factory.support.DefaultListableBeanFactory#registerBeanDefinition
方法注释:用这个注册中心注册一个新的bean定义。必须支持RootBeanDefinition和ChildBeanDefinition。
源码如下:
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);
}
else if (existingDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (logger.isInfoEnabled()) {
logger.info("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
existingDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(existingDefinition)) {
if (logger.isDebugEnabled()) {
logger.debug("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (existingDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
else if (isConfigurationFrozen()) {
clearByTypeCache();
}
}
方法解读:这个就稍微复杂一点了,我也没细看。而且,这个隐藏的挺深的,虽然是从doScan()里面进调用的,但是本质上是调用AnnotationConfigApplicationContext继承自GenericApplicationContext的registerBeanDefinition方法
三、扫描逻辑流程图
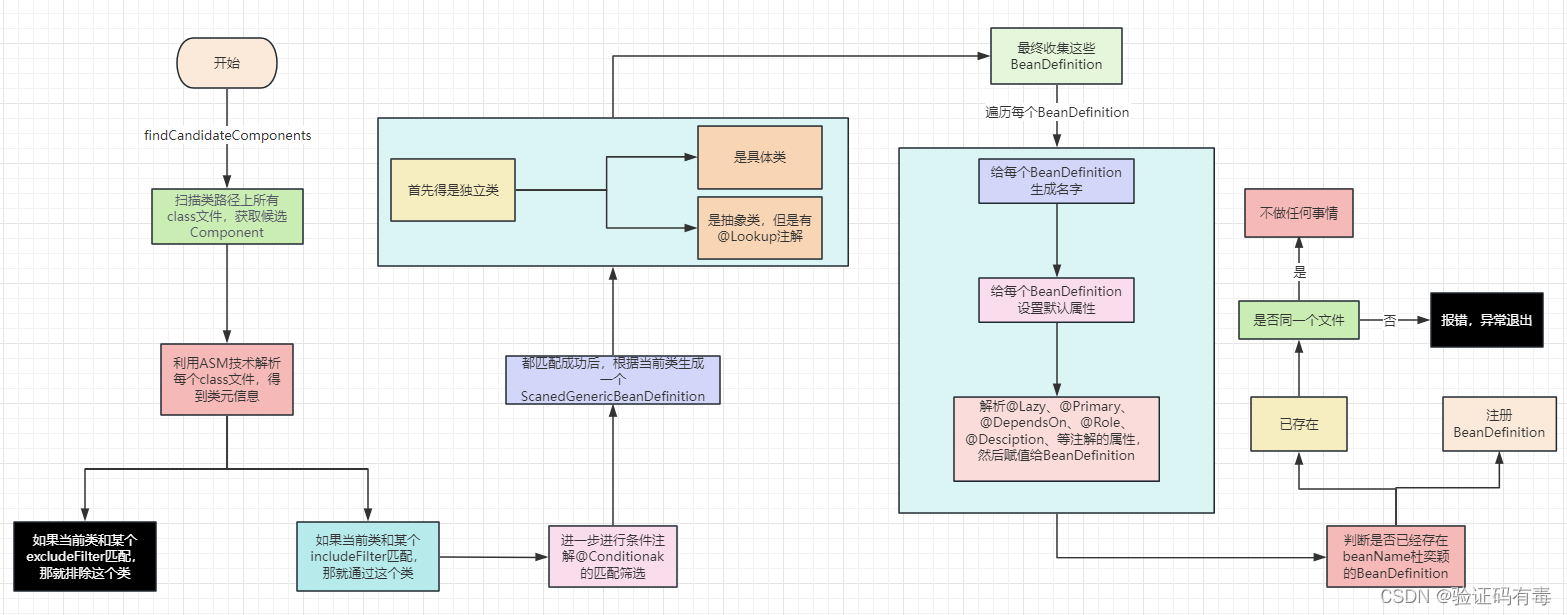
四、合并BeanDefinition
到了后面的IOC过程,生成Bean的时候,我们会看到很多这样的调用:
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
这个就是所谓的,获取合并BeanDefinition。什么是合并BeanDefinition?其实就是父子BeanDefinition。跟Java里面的继承是一样一样的。但是,这个通常发生在xml配置bean里面,如下:
<bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/>
<bean id="child" class="com.zhouyu.service.Child"/>
但是这么定义的情况下,child就是原型Bean了。因为child的父BeanDefinition是parent,所以会继承parent上所定义的scope属性。而在根据child来生成Bean对象之前,需要进行BeanDefinition的合并,得到完整的child的BeanDefinition。
学习总结
- 学习了Spring源码流程中的【扫描】底层原理