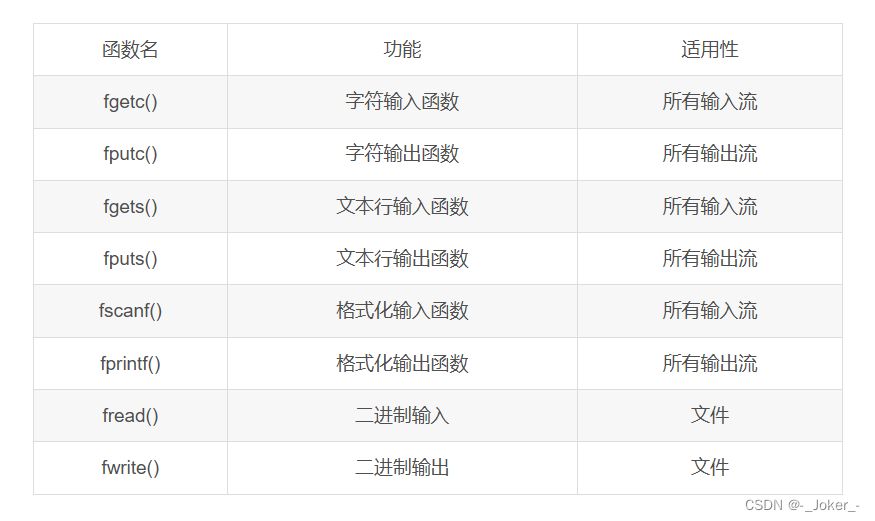
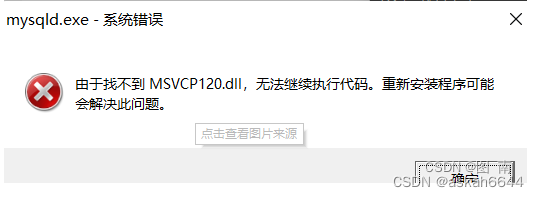
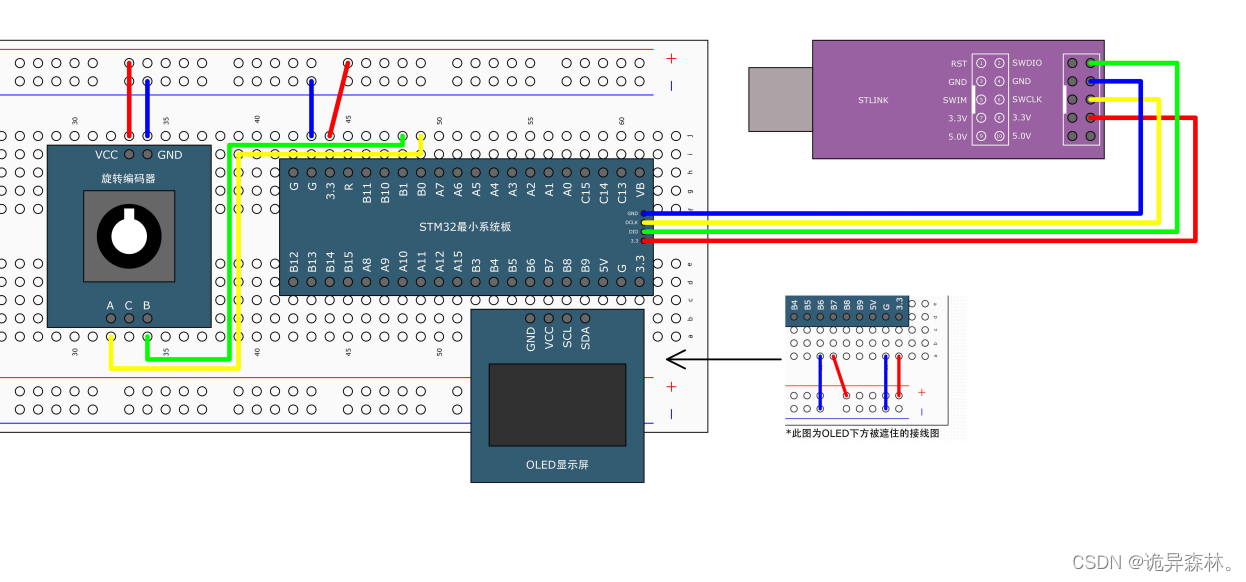
📢前言:本篇是关于如何使用YoloV5+Deepsort训练自己的数据集,从而实现目标检测与目标追踪,并绘制出物体的运动轨迹。本章讲解的为第二部分内容:训练集的采集与划分,Yolov5模型的训练。本文中用到的数据集均为自采,实验动物为斑马鱼。
💻环境&配置:RTX 3060、CUDA Version: 11.1、torch_version:1.9.1+cu111、python:3.8
源码如下:
GitHub - mikel-brostrom/yolo_tracking: A collection of SOTA real-time, multi-object tracking algorithms for object detectors
GitHub - Sharpiless/Yolov5-Deepsort: 最新版本yolov5+deepsort目标检测和追踪,能够显示目标类别,支持5.0版本可训练自己数据集
如果想进一步了解Yolov5+Deepsort中的算法,猛戳这里:【Yolov5+Deepsort】训练自己的数据集(1)| 目标检测&追踪 | 轨迹绘制

目录
Ⅰ准备数据集
0x00 数据集的采集
0x01 数据集的标注
0x02 数据集的划分
Ⅱ Yolov5模型训练
0x00 修改配置文件
0x01 选择预训练模型
0x02 训练结果
0x03 训练结果浅析
0x04 替换权重文件
Ⅰ准备数据集
0x00 数据集的采集
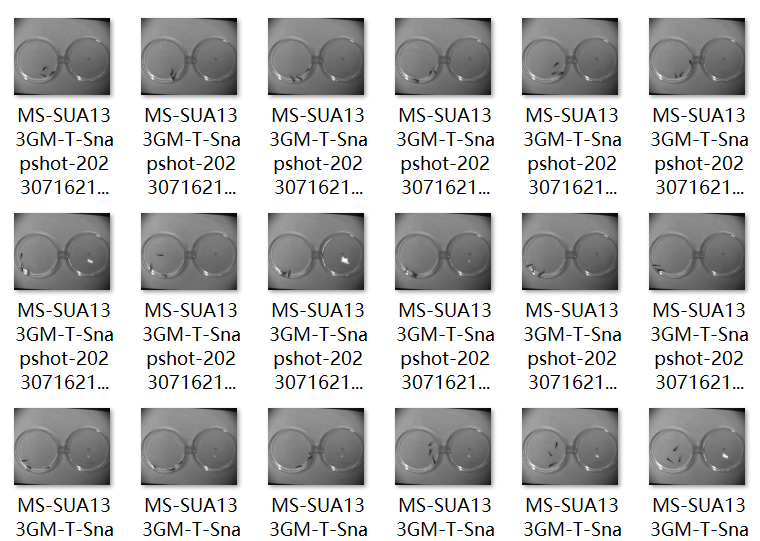
使用USB3.0工业相机对运动的斑马鱼进行照片的抓拍采集,共采集到照片1w+。
数据集示例:

❓为什么使用工业相机呢:
- 可以提供高分辨率和高质量的图像,确保准确的视觉分析和检测。
- 具备高帧率和快速曝光时间,能够在高速运动或快速生产线上捕获清晰的图像,确保高效的生产过程。
- 工业相机经过严格的测试和质量控制,具有高度的稳定性和可靠性,能够长时间稳定工作。
由于工业相机的成本等问题,不使用工业相机也可以采集到质量较高的图片,但是采集的图片一般要满足以下要求:
- 图像质量:图像应该具有足够的清晰度和图像质量,以确保模型能够正确地提取特征并进行准确的预测。低质量或模糊的图像可能会导致模型性能下降。
- 统一尺寸:数据集中的图像应该具有统一的尺寸。在训练过程中,通常需要将图像调整为相同的大小,以便于批量处理。
- 多样性:数据集应该包含多样性的图像样本,涵盖不同的场景、角度、光照条件、背景等。这样可以确保模型在各种情况下都能表现良好。
- 平衡类别:如果数据集是分类任务,每个类别的样本应该尽量保持平衡。不平衡的类别分布可能导致模型对少数类别的表现不佳。
0x01 数据集的标注
在机器学习和计算机视觉领域,有许多常用的图像数据标注软件,用于对图像数据进行标注和注释。
我们使用LabelImg对抓拍的图片进行标记:
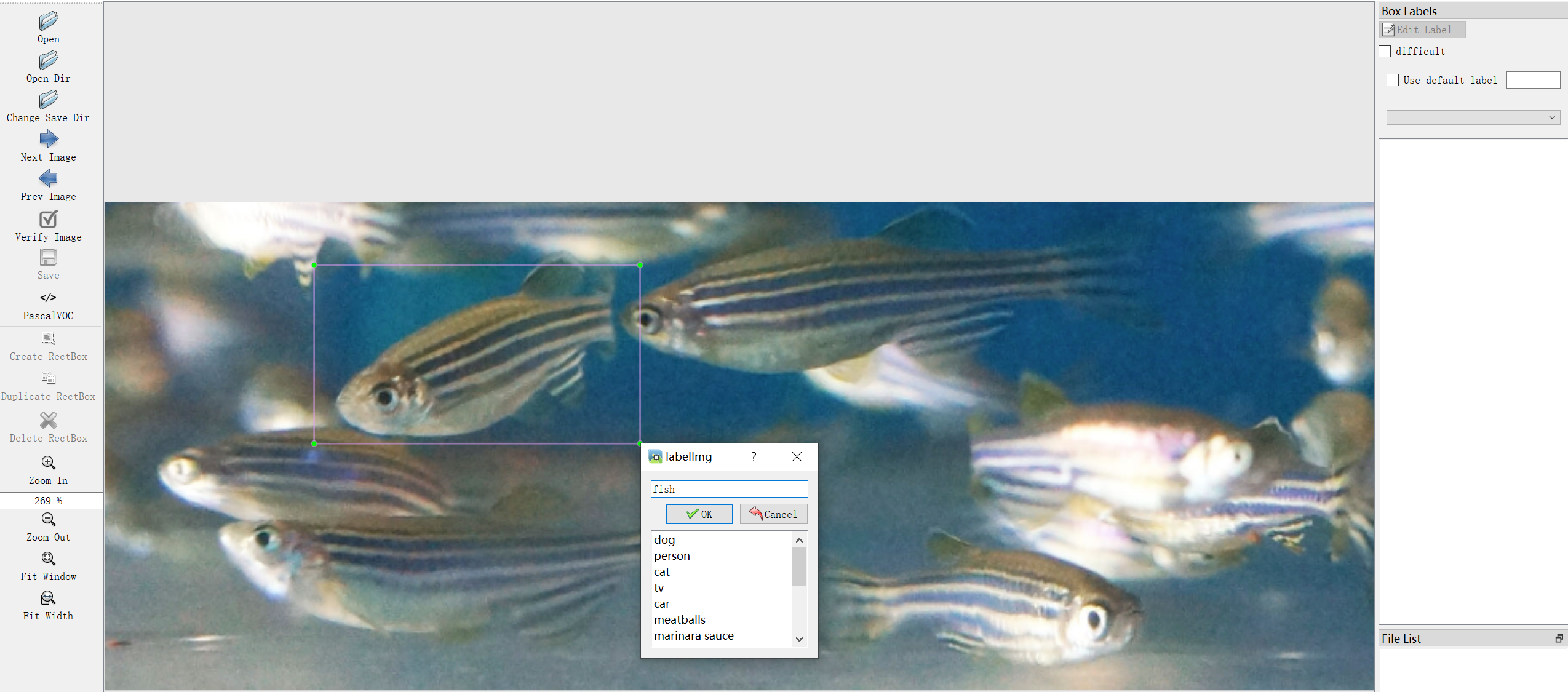
由于我们后续要使用Yolov5作为目标检测的模型,故我们的数据集需采用YOLO的格式进行标记。
得到标记后的txt格式:
🚩为了方便读者的实际操作,在这里给出VOC格式转YOLO格式(txt格式)的代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
print(xml_files)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 需要转换的类别,需要一一对应
classes1 = ['helmet']
# 2、voc格式的xml标签文件路径
xml_files1 = r'path'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'path'
convert_annotation(xml_files1, save_txt_files1, classes1)因为有多种标记工具可以用于标记,若使用LabelMe进行标记,则需要将json格式转为txt格式:
import os
import json
from PIL import Image
json_dir = 'path' # json文件路径
out_dir = 'path' # 输出的 txt 文件路径
def get_json(json_file, filename):
# 读取 json 文件数据
with open(json_file, 'r') as load_f:
content = json.load(load_f)
file_path = 'D:/train/image/'+filename+'.jpg' # 每个json文件对应的图片文件路径
img = Image.open(file_path)
# imgSize = img.size # 大小/尺寸
image_width = img.width # 图片的宽
image_height = img.height # 图片的高
filename_txt = out_dir + filename+'.txt'
# 创建txt文件
fp = open(filename_txt, mode="w", encoding="utf-8")
# 将数据写入文件
#fp.close()
for t in content:
if(t['type']<=7):
# 计算 yolo 数据格式所需要的中心点的 相对 x, y 坐标, w,h 的值
x = (t['x'] + t['width']/ 2) / image_width #归一化
y = (t['y']+ t['height']/ 2 )/ image_height #归一化
w = t['width']/ image_width #归一化
h = t['height'] / image_height #归一化
fp = open(filename_txt, mode="r+", encoding="utf-8")
file_str = str(t['type']-1) + ' ' + str(round(x, 6)) + ' ' + str(round(y, 6)) + ' ' + str(round(w, 6)) + \
' ' + str(round(h, 6))
line_data = fp.readlines()
if len(line_data) != 0:
fp.write('\n' + file_str)
else:
fp.write(file_str)
fp.close()
def main():
files = os.listdir(json_dir) # 得到文件夹下的所有文件名称
s = []
for file in files: # 遍历文件夹
filename = file.split('.')[0]
get_json(json_dir+'/'+file, filename)
if __name__ == '__main__':
main()
0x02 数据集的划分
数据集划分是在机器学习和深度学习任务中至关重要的步骤,用于将数据集分成训练集、验证集和测试集。以下是简单的数据集划分方法:
- 训练集(Training set):用于训练模型的数据集。训练集占据整个数据集的大部分,通常约为总数据集的60-80%。模型通过训练集来学习数据的特征和模式。
- 验证集(Validation set):用于调整模型的超参数和选择最佳模型。验证集是用来评估模型在训练过程中的性能,并帮助确定哪些超参数设置最优。验证集通常约占数据集的10-20%。
- 测试集(Test set):用于评估模型的泛化能力和性能。测试集是在训练和调参完成后,用来验证模型在新数据上的表现。测试集应该与训练集和验证集没有重叠,通常约占数据集的10-20%。
数据集划分应该尽量保持数据的随机性,避免训练集、验证集和测试集之间的数据分布差异过大。
若数据集划分不当,则容易出现过拟合和欠拟合:
1.过拟合(Overfitting):
- 当训练集过小,无法充分代表整个数据分布时,模型可能会在训练集上表现得很好,但在未见过的数据上表现不佳,这称为过拟合。
- 过拟合问题会导致模型过度记忆训练集中的噪声和细节,而无法泛化到新数据上。
- 过拟合通常在验证集和测试集上表现较差,但在训练集上表现优秀。
2.欠拟合(Underfitting):
- 当训练集过大或模型复杂度不够高时,模型可能会无法充分学习数据的规律,而表现不佳,这称为欠拟合。
- 欠拟合问题会导致模型无法学习数据的真实分布和特征,表现较差且泛化能力差。
- 欠拟合通常在训练集、验证集和测试集上表现均较差。
划分好的格式如下:

可以手动进行数据集的划分,也可以使用如下代码进行数据集的划分:
import os
import shutil
import random
random.seed(0)
def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
data=list(zip(each_class_image,each_class_label))
total = len(each_class_image)
random.shuffle(data)
each_class_image,each_class_label=zip(*data)
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
if __name__ == '__main__':
file_path = "D:/Files/dataSet/drone_images"
xml_path = 'D:/Files/dataSet/drone_labels'
new_file_path = "D:/Files/dataSet/droneData"
split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)
Ⅱ Yolov5模型训练
0x00 修改配置文件
在data中找到coco128.yaml并打开
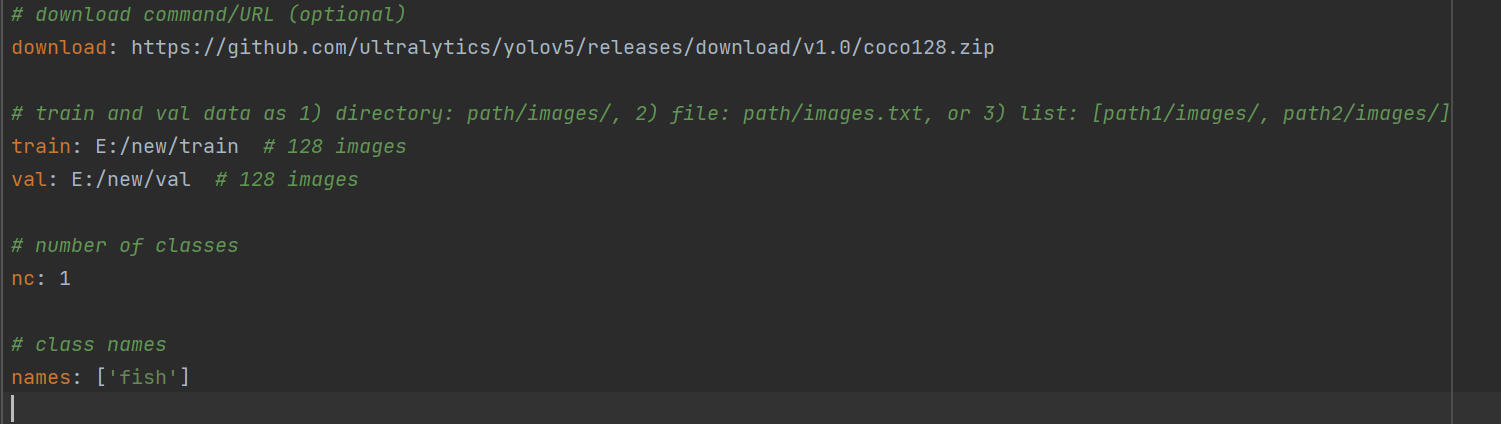 其中,nc是标签名个数,names就是标签的名字。
其中,nc是标签名个数,names就是标签的名字。
train是在path绝对路径条件下的训练集路径,val同上,但是是验证集,这里为了方便,合并训练集和验证集。
0x01 选择预训练模型
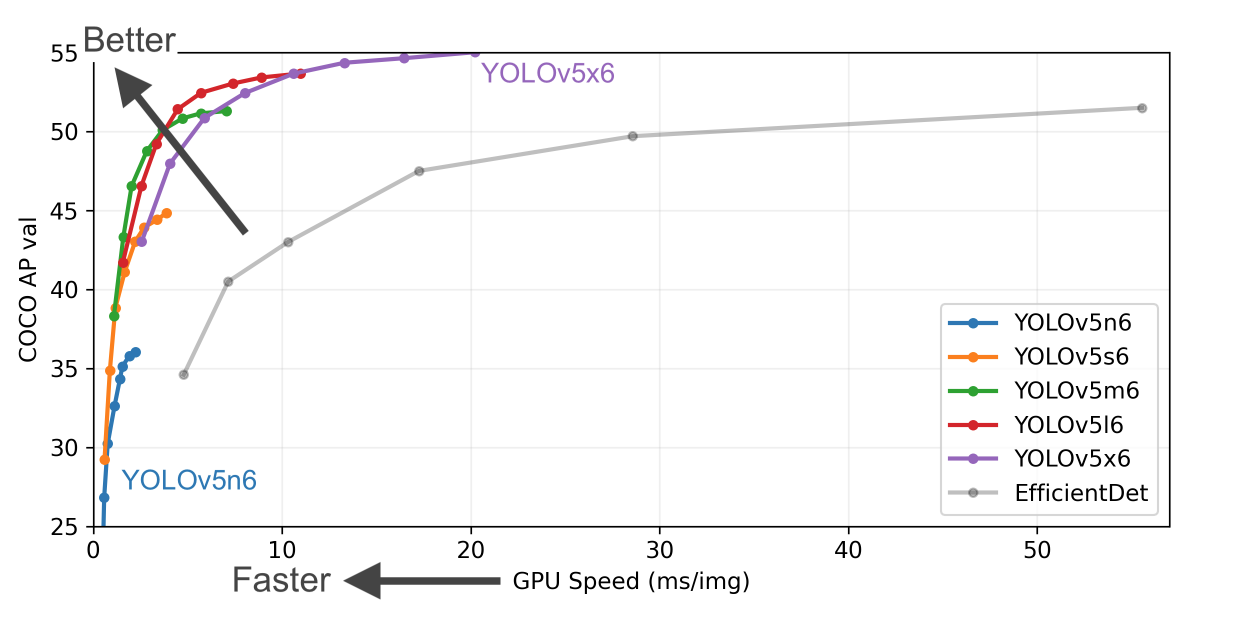
yolov5共有4中配置,本次演示选择yolov5s,这个版本对显存的要求较低,但效果一般。
在yolov5下找到train.py
只需要修改以下参数即可:
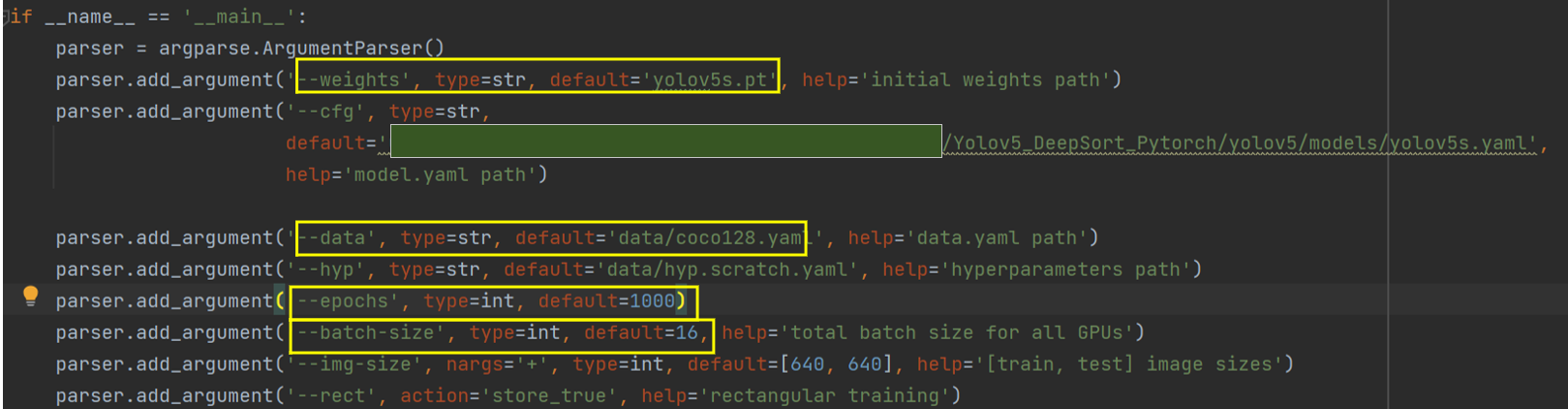
--weights:训练的初始权重的位置,以.pt结尾的文件,可在官网上下载权重。
--cfg:训练模型文件,在本项目中对应yolov5s.yaml。
--data:数据集参数文件,在本项目中对应coco128.yaml
--epochs:训练的轮数,这里设置为1000,可根据需要修改
--batch-size:每次迭代(或称为训练步骤)中模型处理的样本数量,决定了训练的速度,要根据自己电脑的显存选择合理的batch。
0x02 训练结果
可在如下路径下找到最后的结果(在train中的最后一个exp文件夹中,训练次数越多,exp的数量越多):
![]()
可以看到训练结果:

可在如下路径下找到训练后得到的权重:
![]()

best.pt和last.pt是我们训练出来的权重文件,
其中last是最后一次的训练结果,best是效果最好的训练结果。
🚩注:
可能随着不同的训练设定和实验有所变化,因此在不同的实验中,得到的最佳模型参数可能不同。
只是在训练过程中在验证集上表现最好的一个模型快照,但并不能保证它在所有情况下都是最佳的。
0x03 训练结果浅析
1. F1_curve.png —— F1曲线
- F1分数与置信度阈值(x轴)之间的关系。F1分数是分类的一个衡量标准,是精确率和召回率的调和平均数,介于0,1之间。越大越好。
- 若F1曲线很“宽敞”且顶部接近1,说明在训练数据集上表现得很好的置信度阈值区间很大。
R_curve.png —— 单一类召回率(置信度阈值 - 召回率曲线图)
- 当置信度越小的时候,类别检测的越全面(不容易被漏掉,但容易误判)。
P_curve.png —— 单一类准确率(置信度阈值 - 准确率曲线图)
- 当判定概率超过置信度阈值时,各个类别识别的准确率。当置信度越大时,类别检测越准确。
PR_curve.png —— 精确率和召回率的关系图
- 在准确率很高的前提下,尽可能的检测到全部的类别。因此希望我曲线接近(1,1),即希望mAP曲线的面积尽可能接近1。
0x04 替换权重文件
将训练后得到的best.pt替换到track.py中:

至此,yolov5部分已经全部结束。
END
📝因为作者的能力有限,所以文章可能会存在一些错误和不准确之处,恳请大家指出!
| 📃参考文献: [1] Simple Online and Realtime Tracking with a Deep Association Metric [1703.07402] Simple Online and Realtime Tracking with a Deep Association Metric (arxiv.org) |