相关论文
2009.PP-OCR: A Practical Ultra Lightweight OCR System
2109.PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System
2206.PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
工程代码: github_PaddleOCR | 国内gitee_PaddleOCR
概述
中文模型尺寸仅为3.5M,能识别6622个汉字 。识别63个字母数字符号的模型,仅为2.8M
一、PP-OCRv1 模型结构
图中的模型大小是关于中英文识别的。对于字母数字符号识别( alphanumeric symbols recognition),文本识别的模型大小为1.6M~0.9M。其余的模型的大小相同
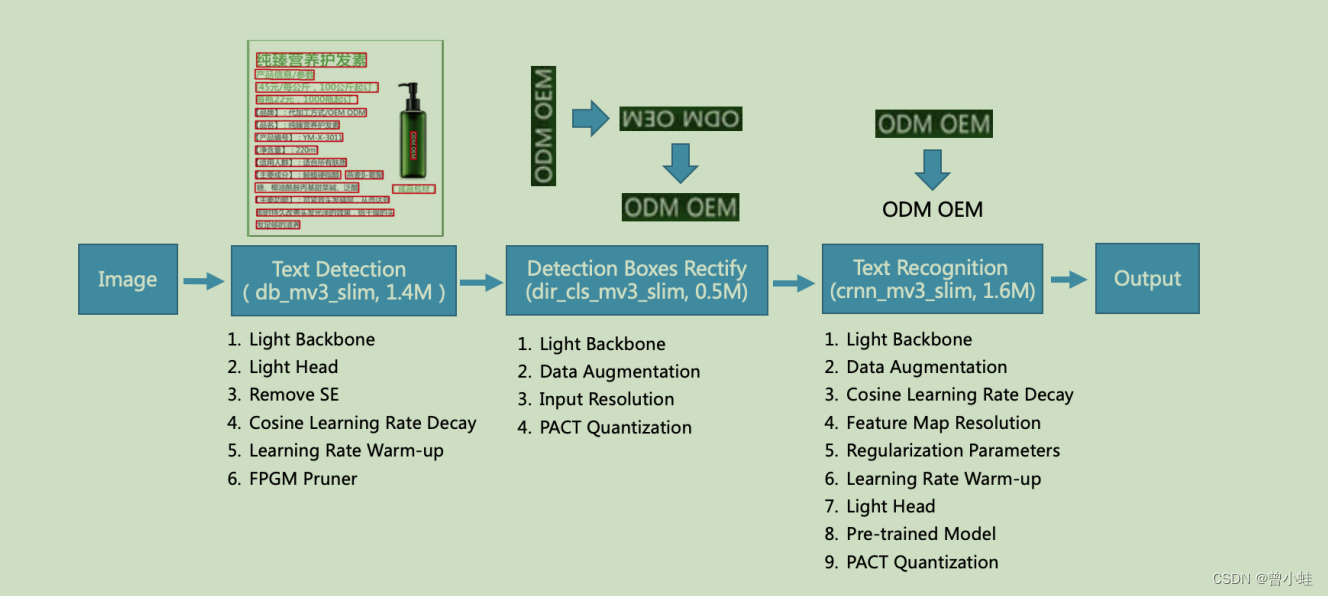
主要流程为: DB文字检测 + 方向分类+CRNN字符识别
其中文本检测算法选用可微二值化算法 DB,使用 97K图片训练
文本识别算法选用CRNN,使用1700万张图片的图片训练
文本方向分类器 MobileNetv3, 在检测和识别模块之间添加,以应对不同方向的文本识别。(60万+图片训练)
下图黑色的文字表示改进结构或者策略
二、改进策略(压缩模型大小、调高精度与泛化)
目标检测模型优化
1. 文字检测的骨干网络(backgone)轻量化
使用MobileNet或者ShuffleNet系列作为 light backbone
2. 文字检测头(head)的轻量化,
采用FPN的类似结构,融合不同尺度的特征层为了方便合并不同分辨率的特征映射,通常使用1×1卷积法将特征映射减少到相同数量的通道数,本文从256减少到了96,
3. 去除了SE( squeeze-and-excitation)模块 (在骨干网络MobileNetv3中)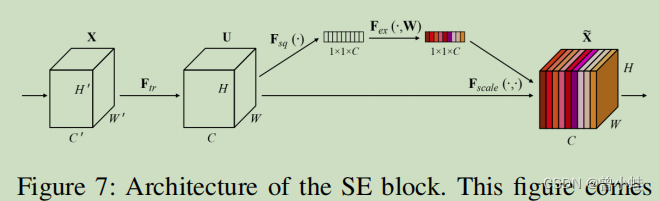
如图7所示,SE块显式地建模通道之间的相互依赖(inter-dependencies)关系,并自适应地重新校准通道方向的特性响应。由于SE块可以明显地提高视觉任务的准确性,因此MobileNetV3的搜索空间中包含了它们,并且许多SE块都在MobileNetV3架构中。然而,当输入分辨率很大时,如640×640,很难估计使用SE块的逐通道特征响应(channel-wise feature responses)。精度的提高很有限,但时间成本很高。当从主干上将SE块移除时,模型尺寸从4.1M减小到2.5M,但精度没有影响。
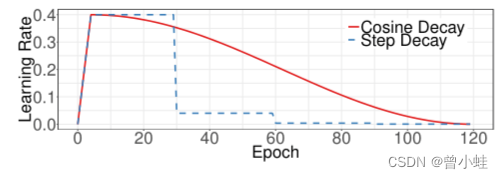
4. 余弦学习率衰减 (Cosine Learning Rate Decay) :
在训练的早期阶段,权值处于随机初始化状态,因此我们可以设置一个相对较大的学习速率,以便更快地收敛(convergence)。在训练的后期阶段,权值接近于最优值,因此应该使用相对较小的学习率。(虽然使用较低的学习速率可以确保你不会错过任何局部最小值,但这也意味着收敛速度很慢。)
5. 学习率预热(Learning Rate Warm-up)
论文建议 :1812.Bag of Tricks for Image Classification with Convolutional Neural Networks (基于卷积神经网络的图像分类的各种技巧)
warm-up采用以较低学习率(例如0)逐渐增大至较高学习率的方式实现网络训练的“热身”阶段(一般2-5epochs),随着训练的进行学习率慢慢变大,到一定程度后就可以设置的预设的学习率进行训练了(因为在训练过程开始时,使用太大的学习率可能会导致数值不稳定(numerical instability),建议使用较小的学习率,这样就可以提高网络的准确率)
扩展阅读:学习率预热和学习率衰减
6. FPGM 剪枝 (Pruner)?
使用FPGM,在原始模型中找到不重要的子网络( sub-network)。
该方法以几何中值(geometric median)为准则,并将卷积层中的每个滤波器作为欧氏空间中( Euclidean space)的一个点。然后计算这些点的几何中值,去掉具有相似值的滤波器,如图所示
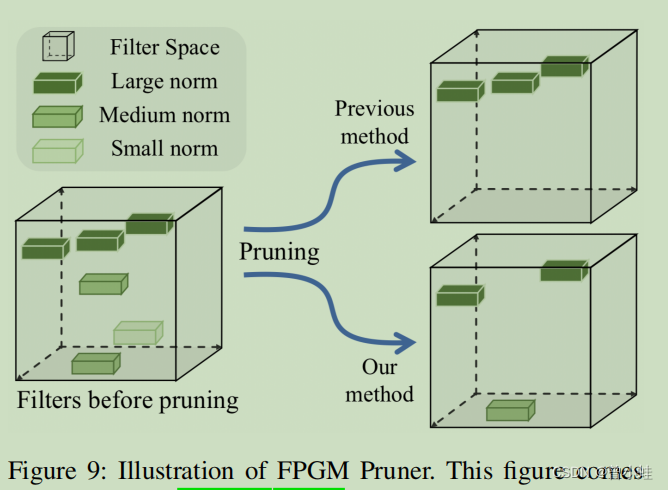
PP-OCR 根据论文 1608.Pruning filters for efficient convnets 计算每层的剪枝灵敏度(pruning sensitivity),然后用来评估每层的冗余度(redundancy)。
方向分类的优化方法
7. 方向分类骨架 MobileNetV3 small x0.35 轻量
8. 数据增强方法
旋转(rotation),透视失真(perspective distortion),运动模糊(motion blur)和高斯噪声。这些过程被简称为BDA(基础数据增强 Base Data Augmentation)。随机增强效果最好。最后,我们在方向分类的训练图像中添加了BDA和随机增强(RandAugment):
9. 增加输入图像的分辨率 Input Resolution
在以往的大多数文本识别方法中,归一化图像的高度和宽度分别设置为32和100。而在PP-OCR中,高度和宽度分别设置为48和192,以提高方向分类器的精度。
10. PACT 量化 (quantization)?
量化可以使神经网络模型具有更低的延迟(latency)、更小的体积(volume)和更低的计算功耗(consumption)
P ACT(准参数化剪切激活, Arameterized Clipping acTivation)是一种新的在线量化方法,可以提前从激活中去除一些异常值 . 为了适应新结构,本文进行了改进。
文字识别优化
11. 识别主干网络 MobileNetV3 small x0.5
改为MobileNetV3 small x1.0 模型也不错,只增加2M的大小
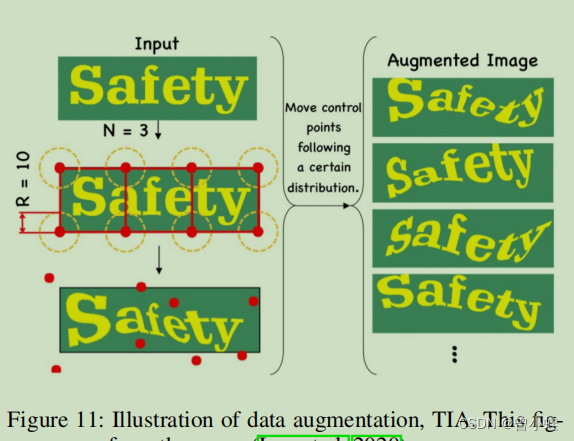
12. 数据增强 TIA
2003. Joint Data Augmentation and Network Optimization for Text Recognition
13. Feature Map Resolution
为了适应多语言识别(multilingual recognition),特别是中文识别 ,CRNN输入的高度和宽度被设置为32和320。,所以,原始的MobileNetV3的步伐 (stride)就不适合用于文本识别了
除了第一个采样特征图之外,我们将向下采样特征图的步幅从(2、2)修改为(2、1)。为了保持更多的垂直信息,我们进一步修改了第二个向下采样特征图的步幅,从(2,1)到(1,1)。因此,第二个向下采样特征图s2的步幅极大地影响了整个特征图的分辨率和文本识别器的精度。在PP-OCR中,s2被设置为(1,1),以获得更好的经验性能。
table from : Searching for mobilenetv3
14. 正则化参数 Regularization Parameters
为了防止过拟合(在训练集上效果好,测试集效果一般),权重衰减(weight decay)是避免过拟合的一种广泛使用的方法之一。在最终的损失函数之后,将l2正则化(L2衰减 (decay))添加到损失函数中。在l2正则化的帮助下,网络的权值倾向于选择一个较小的值,最后整个网络中的参数趋于0,从而相应地提高了模型的泛化性能(generalization)。对于文本识别,l2衰减对识别精度有很大的影响。
15. 轻量化
一个全连接层(full connection)用于将序列特征编码到普通的预测字符中。
序列特征的维度( dimension of the sequence features) 对文本识别器的模型大小有影响,
特别是对于超过词库6千+以上的中文识别。
同时,并不是说维数越高,序列特征的表示能力就越强。在PP-OCR中,序列特征的维数被经验设置为48
16. 预训练模型
如果训练数据较少,则对现有的网络进行微调,并在ImageNet等大数据集上进行训练,以实现快速收敛和更好的精度。在图像分类和目标检测中的迁移学习结果表明,上述策略是有效的
在真实的场景中,用于文本识别的数据往往是有限的。如果用数千万个样本进行训练,即使是合成的,上述模型也可以显著提高精度
17.-19 文字识别与图片检测相似的方法
PACT Quantization 和 cosine-learning decay 衰减 以及 Learning Rate Warm-up 学习率热启动
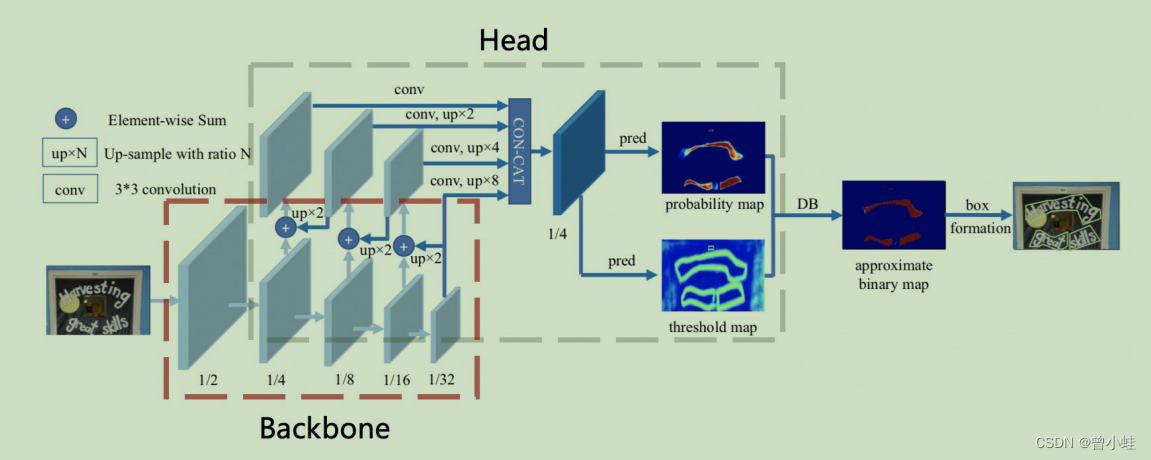
三、原始文本检测算法DB
基于可微二值化的实时场景文字检测 1911.Real-time Scene Text Detection with Differentiable Binarization
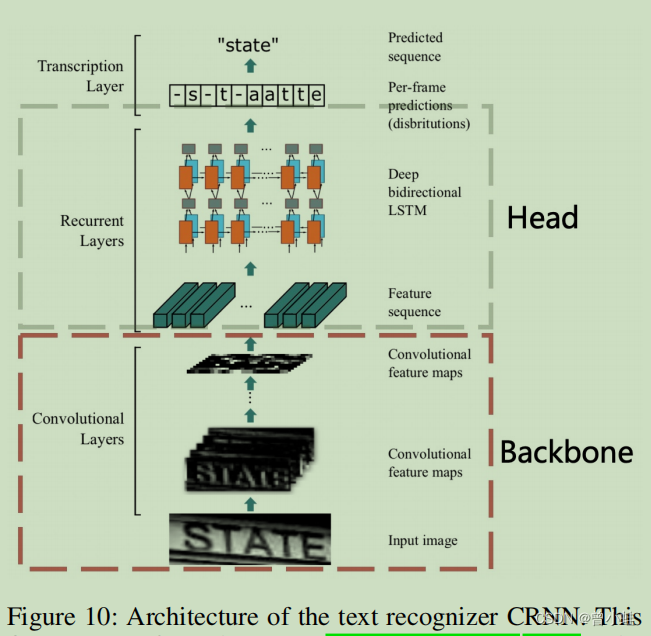
四、文本识别算法 CRNN:
一种基于图像的序列识别的端到端可训练神经网络 及 其在场景文本识别中的应用
1507.An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
结构如下,先卷积,后使用LSTM处理
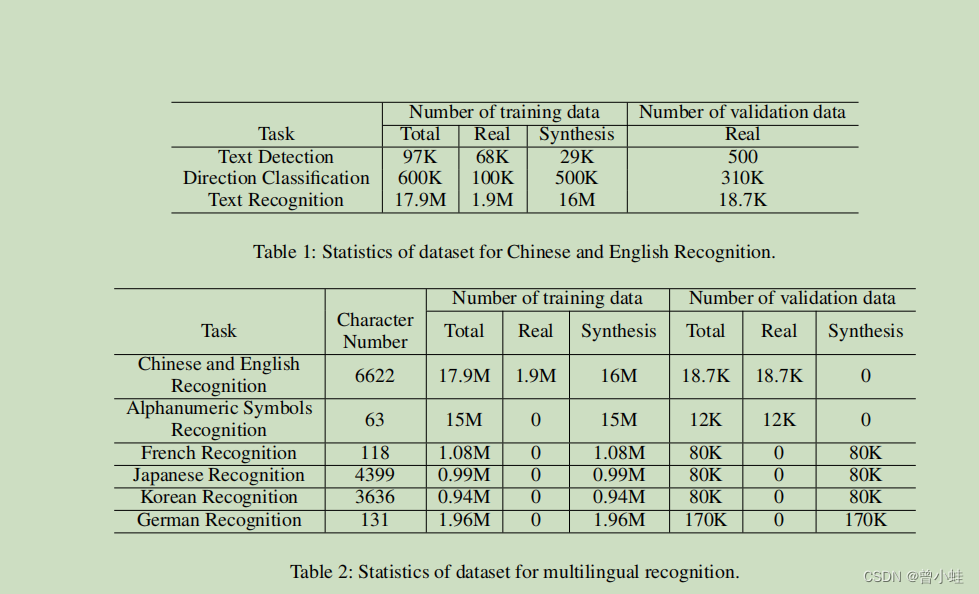
六、实验
6.1 实验数据集
附录:PP-OCRv1-v3的结构变化
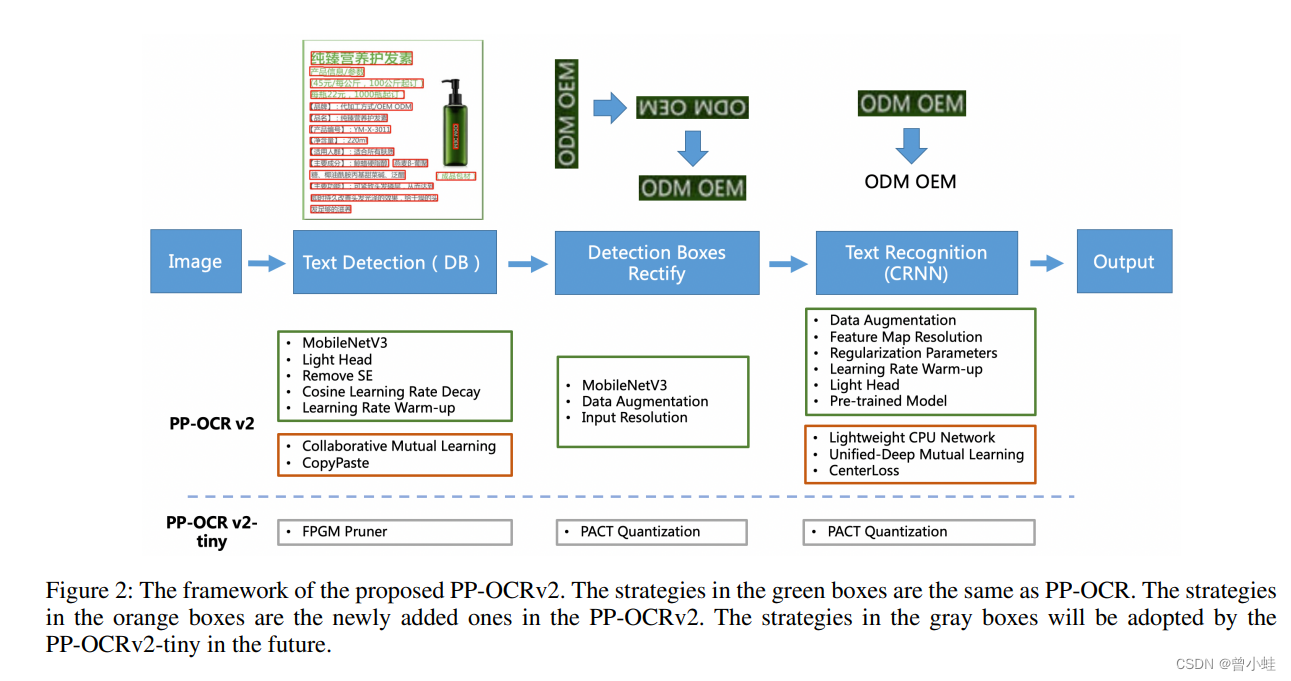
PP-OCRv2 较于v1的改变(红色),绿色表示v1已经具有的结构
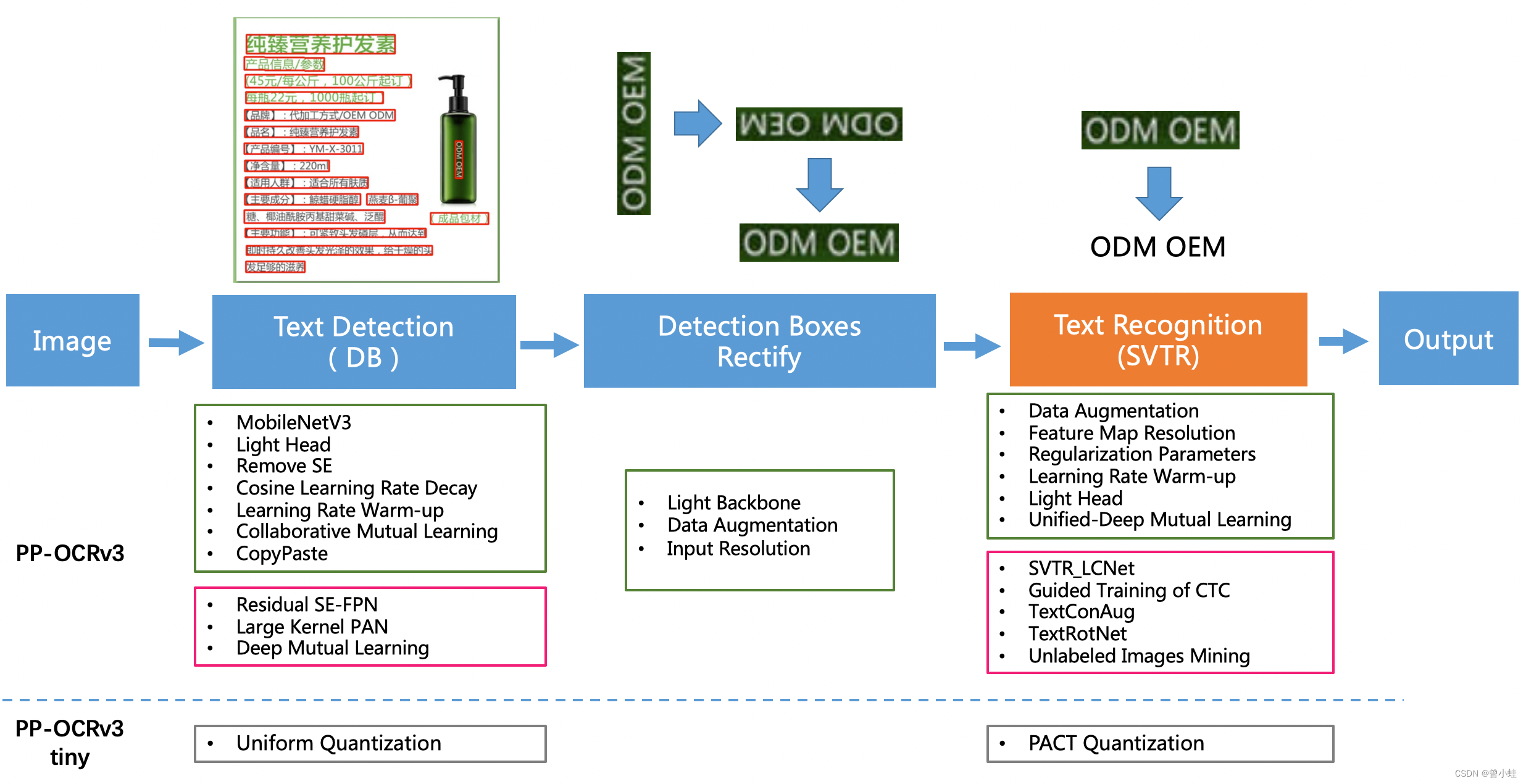
PP-OCRv3 将对于前2代的改变
附录2 代码使用
环境安装参考:
paddlepaddle深度学习框架: https://www.paddlepaddle.org.cn/
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/quickstart.md
代码
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
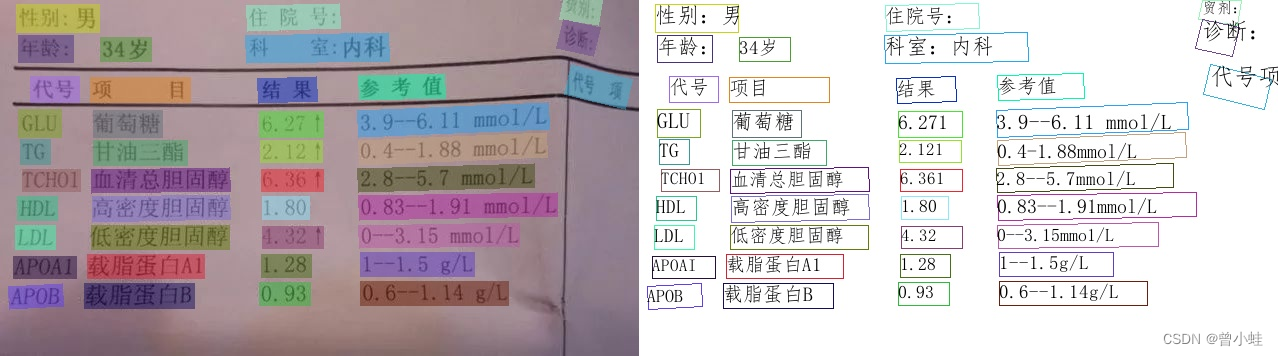
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
# 如果本地没有simfang.ttf,可以在doc/fonts目录下下载
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')