知识目录
- 前言
- 一、加载数据
- 1 - 加载CSV文件
- 2 - 加载Excel文件
- 3 - 加载数据库数据
- 二、分箱
- 1 - 等宽分箱
- 2 - 等频分箱
- 三、时间序列
- 1 - Timestamp和Period的创建
- 2 - 索引和切片
- 3 - 属性和移动
- 4 - 频率转换
- 5 - 数据聚合
- 四、pandas绘制图形
- 1 - 折线图
- 2 - 柱状图
- 3 - 直方图
- 4 - 饼图
- 5 - 散点图
- 6 - 箱型图
- 7 - 面积图
- 结语
前言
一、加载数据
以前我们在练习的时候,基本上使用的是我们模拟出来的数据,但是在真实业务场景中,数据一般是已经存在的,少数需要使用爬虫技术获取。已经存在的数据,一般有
CSV格式,Excel格式和数据库中存储的数据。
下面,我们就针对 pandas 如何加载和存储这些格式的数据进行一个简单介绍。
Tips⭐️:存储数据到文件是 dataframe 对象调用,读取文件是 pandas 调用。
1 - 加载CSV文件
CSV(逗号分隔值)文件可以方便地在不同的操作系统、软件和平台之间传输和读取,因此常被用于数据存储和数据交换。
例如,网站的用户注册数据、市场调研数据等都可以以CSV文件的形式进行存储和传输。
- 存储到CSV文件
df.to_csv(path_or_buf=None,
sep=',',
columns=None,
header=True,
index=True
)
| 参数 | 含义 |
|---|---|
| path_or_buf | 存储路径和文件名 |
| sep | 分隔符,默认为逗号 |
| columns | 要存储的列,如果不指定则存储全部列 |
| header | 是否保留列名 |
| index | 是否保留行索引 |
下面是代码示例:
# 导入模块
import numpy as np
import pandas as pd
# 创建要存储到csv文件的dataframe对象
data = np.random.randint(0,100,(5,3))
df = pd.DataFrame(data,columns=['Python','Java','BigData'])
# 存入到当前目录下的07.csv文件中
df.to_csv(path_or_buf='./07.csv',sep=',',header=True,index=False)
- 读取CSV文件
pd.read_csv(
filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]],
sep=',',
header='infer',
names=None,
index_col=None,
usecols=None,
)
| 参数 | 作用 |
|---|---|
| filepath_or_buffer | 文件路径和文件名,或IO对象 |
| sep | 分隔符,默认是逗号 |
| header | 默认=0,表示使用第一行作为列名 |
| names | 列表类型,在没有指定header的情况下,如果指定了names,那么将names作为列名 |
| index_col | 指定某列作为行索引 |
| usecols | 只读取某些列,默认读取全部 |
下面是代码示例:
# 读取当前路径下的07.csv的Java列
pd.read_csv(filepath_or_buffer='./07.csv',sep=',',header=0,usecols=['Java'])
2 - 加载Excel文件
对于不懂编程的人来说(比如会计、文员等和计算机专业性不太相关的职业),
excel文件是他们用的比较多的数据文件存储格式。
- 存储到Excel文件
df.to_excel(
excel_writer,
sheet_name='Sheet1',
columns=None,
header=True,
index=True,
)
| 参数 | 含义 |
|---|---|
| excel_writer | 文件路径和文件名 |
| sheet_name | 写入excel时当前 sheet 页的名字 |
| columns | 要写入的属性列 |
| header | 将 df 对象哪一行作为列名 |
| index | 是否保留行索引 |
代码示例:
df.to_excel('./07.xlsx',sheet_name='Program Language',index=False)
- 读取Excel文件
pd.read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
参数和读取CSV文件的参数含义是类似的,这里不再解释啦 ~
3 - 加载数据库数据
加载数据库数据,是涉及到许多后端存储数据的业务场景,这里以
MySQL数据举例。
加载MySQL数据库数据首先要安装两个包(pymysql和sqlalchemy)
pip install pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
- 存储到MySQL
df.to_sql(
name,
con,
schema=None,
if_exists='fail',
index=True,
)
| 参数 | 含义 |
|---|---|
| name | 指定要存储的表名 |
| con | 连接对象 |
| schema | 数据库引擎,不指定则使用数据库类型的默认引擎,如MySQL使用 innoDB |
| if_exists | 表已存在时的操作,有{'fail', 'replace', 'append'}三种取值,分别表示报错,替换,追加 |
| index | 是否写入行索引 |
代码示例:
# 导入创建数据库连接的引擎
from sqlalchemy import create_engine
# 获取连接对象
conn = create_engine("mysql+pymysql://root:123456!!!!@localhost:3306/pytest")
# 保存到MySQL数据库
df.to_sql(name='program_language',con=conn,if_exists='append',index=False)
注意:在创建连接对象的字符串中,只需要修改数据库账号和密码(
root:123456!!!!,IP,端口)即可。

- 从MySQL读取
pd.read_sql(
sql,
con,
index_col=None,
coerce_float=True,
parse_dates=None
)
| 参数 | 含义 |
|---|---|
| sql | SQL命令字符串 |
| con | 连接sql数据库的engine,一般可以用SQLalchemy或者pymysql之类的包建立 |
| index_col | 选择某一列作为index |
| coerce_float | 非常有用,将数字形式的字符串直接以float型读入 |
| parse_dates | 将某一列日期型字符串转换为datetime型数据 |
代码示例:
sql = 'SELECT Python FROM program_language;'
pd.read_sql(sql,conn)
二、分箱
分箱操作是指将
连续数据离散化(通俗得讲,就是将数据分到几个区间上,比如有1-100的100个数,分为0-25,25-50,50-75,75-100,这就是分箱操作)。常见的分箱方法有等宽法和等频法。
等宽法:离散化后的每个区间的差值相等。
这样的缺点是可能会不同区间包含的元素数量相差较大。
等频法:离散化后的每个区间内包含的元素数量相等。
这样的缺点是可能会将相同的元素划分到不同的区间里。
1 - 等宽分箱
通过 pandas 的
cut()函数实现等宽分箱。
# 待分箱数据
year = [1992, 1983, 1922, 1932, 1973]
# 指定箱子的分界点
bins = [1900, 1950, 2000]
# 分箱操作
result = pd.cut(year, bins)
# 结果显示的是每个数据在哪个区间内
print(result)

# 对不同箱子中的数进行计数
print(pd.value_counts(result))

# labels参数为False时,返回结果中用不同的整数作为箱子的标签
result2 = pd.cut(year, bins,labels=False)
# 输出结果中的数字对应着不同的箱子
print(result2)
# 对不同箱子中的数进行计数
print(pd.value_counts(result2))

# 给箱子指定标签
group_names = [ '50_before', '50_after']
result3 = pd.cut(year, bins, labels=group_names)
print(pd.value_counts(result3))

2 - 等频分箱
利用 pandas 中的
qcut函数进行等频分箱,分箱后每个箱子的数据量一样。
# 待分箱数据
year2 = [1992, 1983, 1922, 1932, 1973, 1999, 1993, 1995]
# 参数q指定所分箱子的数量
result4 = pd.qcut(year2,q=4)
# 从输出结果可以看到每个箱子中的数据量时相同的
print(result4)

print(pd.value_counts(result4))

三、时间序列
在进行时间序列相关的数据分析时,时间序列处理是自然而然的事情,pandas 提供了许多用于处理时间序列的方法。注意:本文仅简单介绍 pandas 处理时间序列的相关方法,欲知更多请结合其他资料。

在介绍时间序列之前,需要先介绍两个概念:时间戳 pd.Timestamp 和时间段 pd.Period 。
时间戳:Timestamp 是最基本的时间序列数据,用于把数值与时点关联在一起。 pandas对象通过时间戳调用时点数据。
时间段:Period 表示的时间段更直观,还可以用日期时间格式的字符串进行推断。
时间戳和时间段都可以与整数做加减运算,以 freq 指定的参数为单位。
1 - Timestamp和Period的创建
# 创建时间戳
ts1 = pd.Timestamp('2023-8-5')
# 创建时间段
pd1 = pd.Period('2023-8-5',freq='M')
# 创建时间戳范围(periods表示数据量,freq 表示精确到年/月/日)
ts2 = pd.date_range('2022-02-7',periods=4,freq='M')
# 创建时间段范围
pd2 = pd.period_range('2023-8-5',periods=4,freq='M')
display(ts1,ts2,pd1,pd2)

# 时间戳索引
index = pd.date_range('2023-8-5',periods=4,freq='D')
s = pd.Series(np.random.randint(0,10,4),index=index)
s

此外,还有一些和时间戳相关的转换。pd.to_datetime:字符串或时间戳转时间格式,pd.DateOffset:运算时间差。
# 字符串转日期
pd.to_datetime(['2023-8-4','2023/8/4','08/04/2023','2023.8.4'])
# 时间戳转日期
pd.to_datetime([1233123123],unit='ms')
# 计算时间差
ts = pd.Timestamp('2023-8-5')
ts + pd.DateOffset(hours=1,days=-1)
2 - 索引和切片
时间戳的索引和切片,和数组索引和切片类似,都是使用中括号。
# 首先创建时间戳对象
index = pd.date_range('2023-8-5',periods=100,freq='D')
ts = pd.Series(range(len(index)),index)
# 索引
ts['2023-8-12'] # 取一天
ts['2023-8'] # 取8月整个月
ts['2023'] # 取一年
ts[pd.Timestamp('2023-8-20')] # 时间戳索引
# 切片
ts['2023-8-7':'2023-8-20']
ts[pd.Timestamp('2023-8-10'):pd.Timestamp('2023-8-20')] # 时间戳切片
ts[pd.date_range('2023-8-10',periods=4,freq='D')]
3 - 属性和移动
# 属性
ts.index # 索引
ts.index.year # 年份
ts.index.month # 月份
ts.index.dayofweek # 星期
# shift方法
index = pd.date_range('2023-1-20',periods=365,freq='D')
ts = pd.Series(np.random.randint(0,100,len(index)),index)
ts.shift() # 向下移动1位
ts.shift(2) # 向下移动两位
ts.shift(-2) # 向上移动两位
4 - 频率转换
频率转化是改变日期间隔的操作。
# 频率转换
# 由天变为星期,由少变多,去掉了一些数据
ts.asfreq(pd.tseries.offsets.Week())
# 由天变小时,多了一些空数据
ts.asfreq(pd.tseries.offsets.Hour())
# 使用 fill_value 填充
ts.asfreq(pd.tseries.offsets.Hour(),fill_value=0)
5 - 数据聚合
# 首先查看 ts
ts
# 将两天的日期合并,数据相加
ts.resample('2D').sum()
# 将两周的日期合并,数据相加
ts.resample('2W').sum()
d = {
'price':np.random.randint(0,50,8),
'score':range(10,90,10),
'week':pd.date_range('2023-8-5',periods=8,freq='w')
}
df = pd.DataFrame(d)
df
# 对week列按月汇总
df.resample('M',on='week').sum()
# 按照月汇总,price求平均值,score求和
df.resample('M',on='week').agg({'price':np.mean,'score':np.sum})

四、pandas绘制图形
pandas 是数据处理的利器,其实它还可以基于
matplotlib,快速绘制简单的图形,如果是复杂的图形,需要使用 matplotlib 或其他库。pandas通过plot()函数绘制各种图形。
因为 pandas 绘制图形是基于 matplotlib 的,因此要导入 matplotlib 包。
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
pandas绘制图形的写法有两种,是等价的写法,其中 pd 指的是 Series 对象或者 DataFrame 对象。
下面介绍这两种写法
pd.plot.图象类型()
pd.plot(kind = '图象类型')
举个例子
df = pd.DataFrame(np.random.randint(0,100,(4,2)),columns=list('AB'))
df.plot(kind = 'line')
# =====等价于=====
df.plot.line()
# =====都表示绘制折线图,饼图、直方图等都是这样=====
1 - 折线图
下面展示 Series 绘图
data = np.random.randint(0,50,20)
s = pd.Series(data=data)
# 等价于 s.plot(),s.plot(kind='line'),kind默认等于line,所以可以省略
s.plot.line()
因为是随机产生的数据,你们画出来的折线图和我的可能会不一样。

下面是 DataFrame 绘图
data = np.random.randint(0,50,(4,3))
df = pd.DataFrame(data=data,index=list('ABCD'),columns=['Chinese','Math','English'])
df.T.plot(kind='line') # 转置后绘制折线图

2 - 柱状图
Series 绘制柱状图
data = np.random.randint(0,100,5)
s = pd.Series(data=data,index=['Chinese','Math','English','history','computer'])
s.plot(kind='bar')

DataFrame 绘制柱状图
data = np.random.randint(0,50,(4,3))
df = pd.DataFrame(data=data,index=list('ABCD'),columns=['Chinese','Math','English'])
df.plot(kind='bar')

堆叠柱状图
df.plot(kind = 'bar',stacked = True)

# 条形图
df.plot(kind='barh')
# ====== df.plot.barh()

3 - 直方图
data = np.random.randint(0,50,(4,3))
df = pd.DataFrame(data=data,index=list('ABCD'),columns=['Chinese','Math','Englist'])
df.plot(kind='hist',density=True)

4 - 饼图
data = np.random.randint(0,50,(4,3))
df = pd.DataFrame(data=data,index=list('ABCD'),columns=['Chinese','Math','Englist'])
df['Chinese'].plot(kind='pie',autopct='%.1f%%')

如果要对 dataframe 对象绘制饼图,需要加上 subplots=True 参数。
df.plot(kind='pie',autopct='%.2f%%',subplots=True) # 绘制子图

5 - 散点图
df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd'])
df.plot.scatter(x='a', y='b')

6 - 箱型图
df.plot(kind='box')
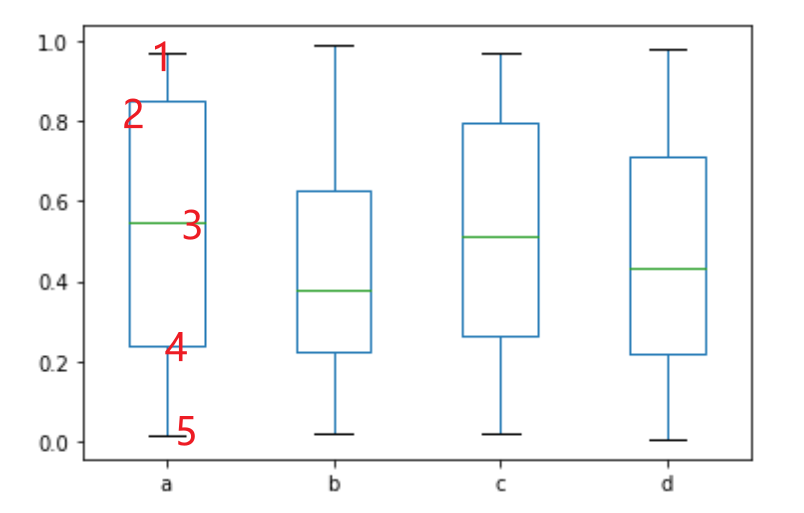
图中数字处的含义:1处代表最大值,2处75%大,3处1/2大,4处25%大,5处是最小值。
7 - 面积图
df.plot.area(stacked=True)
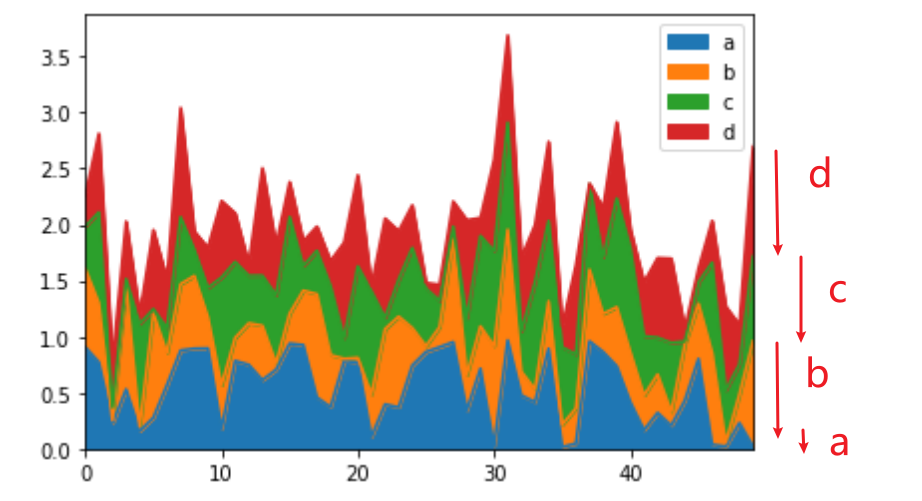
每种颜色对应的区域面积即代表他们的大小。
结语
本文主要讲解了pandas加载数据,分箱操作以及时间序列,绘制各种图形。
⭐️如果有不懂的地方,欢迎大家和我一起探讨 ~
我是向阳花花花花,数据科学路上,与你同行 ⭐️





![[系统安全] 五十二.DataCon竞赛 (1)2020年Coremail钓鱼邮件识别及分类详解](https://img-blog.csdnimg.cn/b71225e4e2d9432a99ab095c7cec4831.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBARWFzdG1vdW50,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)