基于协同过滤的推荐算法综述 - 知乎 (zhihu.com)

# -*- coding: gbk -*-
import pandas as pd
_userID = '1'
#电影评分排序
ratings = pd.read_csv('ml-latest-small/ratings.csv')
#打印前20行
#print(ratings.head(10))
#电影所属类别
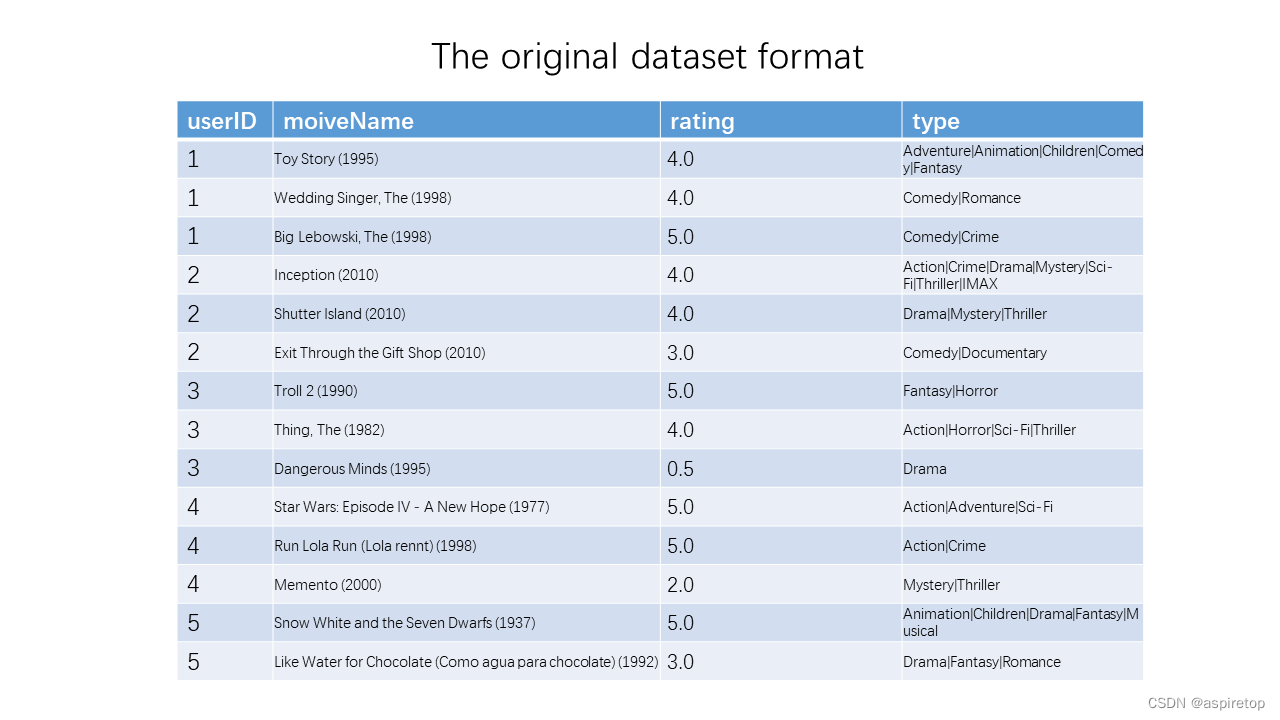
movies = pd.read_csv('ml-latest-small/movies.csv')
#print(movies.head(5))
#合并两个csv的内容
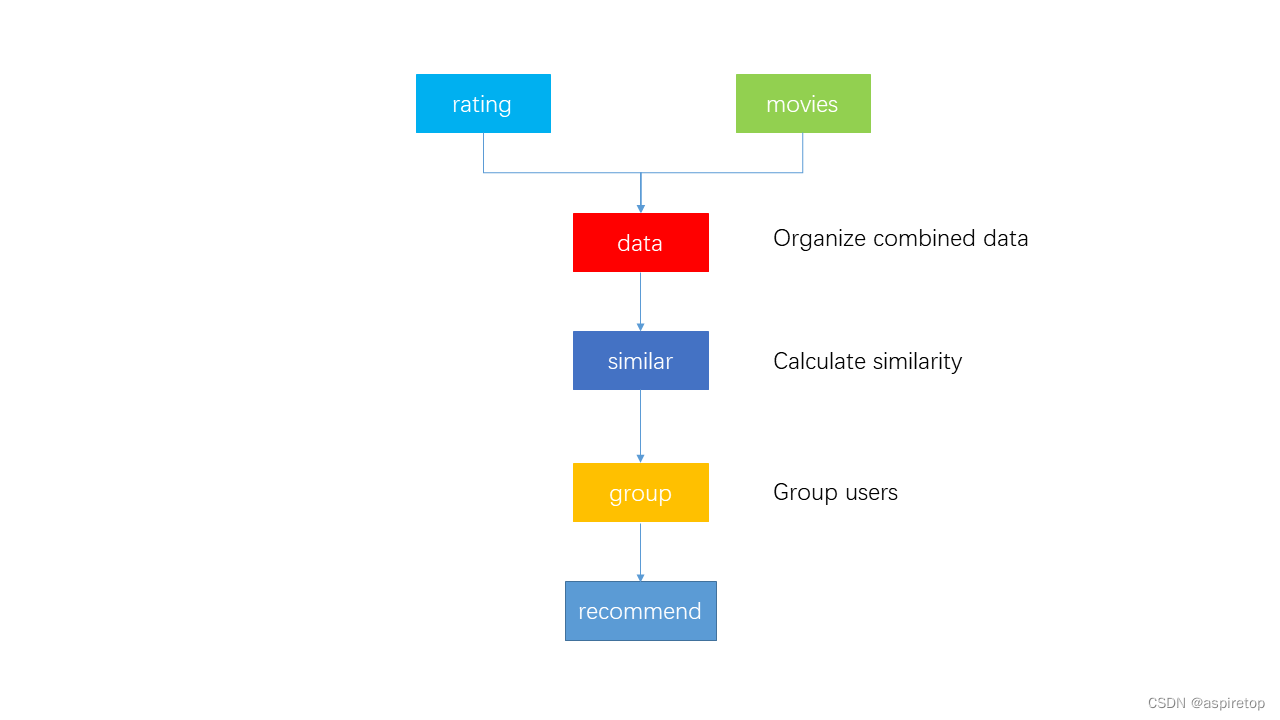
data = pd.merge(movies,ratings,on = 'movieId')
#print(data.head(10))
#data[['userId','title','rating','genres']].sort_values('userId').to_csv('ml-latest-small/data.csv',index=False)
data[['userId','rating','movieId','title','genres']].sort_values('userId').to_csv('ml-latest-small/data.csv',index=False)
# 将合并后的数据集输出保存 以备后续分析
files = pd.read_csv('ml-latest-small/data.csv')
#print(files.head(100))
# 逐行读取刚刚合并并保存的数据集
content = []
with open('ml-latest-small/data.csv','rb') as fp:
content = fp.readlines()
# 将用户、评分、和电影写入字典data
data = {}
for line in content[1:2000]: #取前1000行数据
line = line.decode("utf-8").strip().split(',')
#如果字典中没有某位用户,则使用用户ID来创建这位用户
if not line[0] in data.keys():
data[line[0]] = {line[3]:line[1]}
#否则直接添加以该用户ID为key字典中
else:
data[line[0]][line[3]] = line[1]
#字典结构 key是用户ID,value包含很多对电影,分别为{电影名:评分}
#print(data)
from math import *
def Euclidean(user1,user2):
#取出两位用户评论过的电影和评分
user1_data=data[user1]
user2_data=data[user2]
distance = 0
#找到两位用户都评论过的电影,并计算欧式距离
for key in user1_data.keys():
if key in user2_data.keys():
#注意,distance越大表示两者越相似
distance += pow(float(user1_data[key])-float(user2_data[key]),2)
return 1/(1+sqrt(distance))#这里返回值越小,相似度越大
#计算某个用户与其他用户的相似度
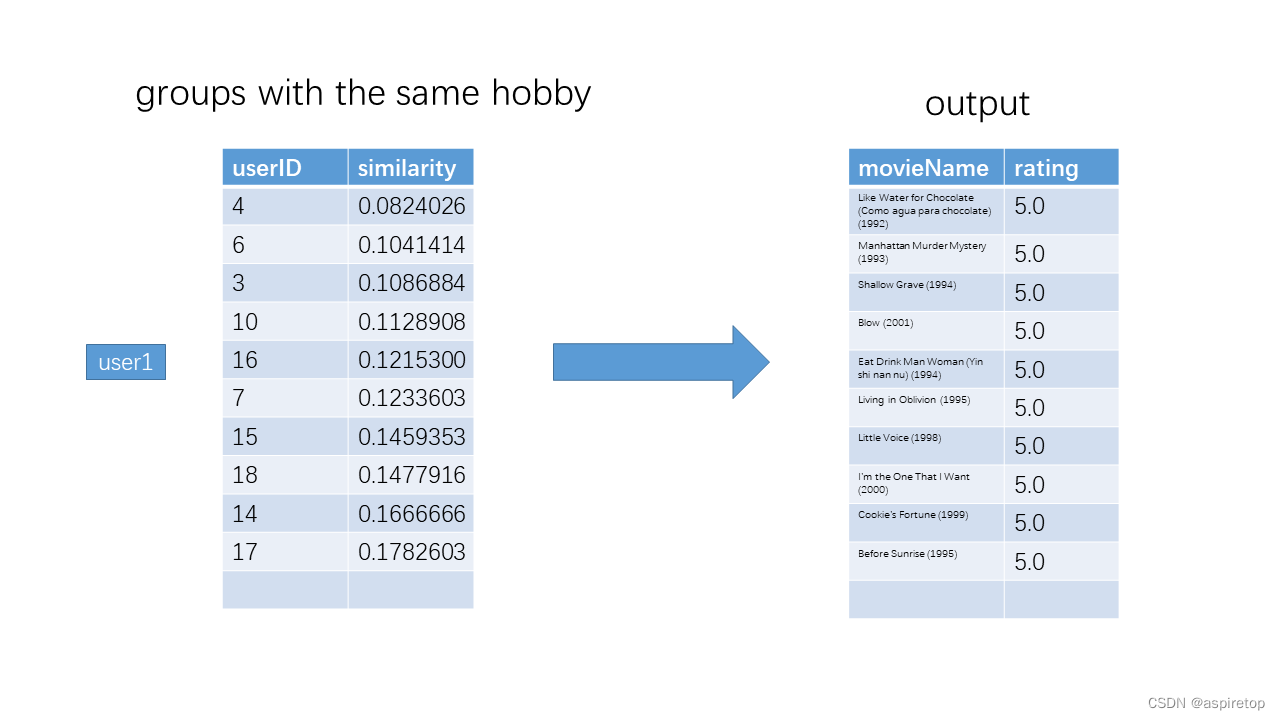
def top10_simliar(userID):
res = []
for userid in data.keys():#所有用户ID
#print(userid)
#排除与自己计算相似度
if not userid == userID:
simliar = Euclidean(userID,userid)
res.append((userid,simliar))
res.sort(key=lambda val:val[1])
#print(res)
return res[:10] #输出前10个最相似的人
#计算第一个用户和其他用户的相似程度,找出与他类似的人群
RES = top10_simliar(_userID)
#print(RES)
# 用户之间相似度结果:0表示两位的影评几乎一样,1表示没有共同的影评
def recommend(user):
#相似度最高的用户ID
top_sim_user = top10_simliar(user)[0][0]
#print(top_sim_user)
#相似度最高的用户的观影记录
items = data[top_sim_user]
#print('最相似用户为{0},其喜欢看的电影是{1}'.format(top_sim_user,items))
recommendations = []
#筛选出待推荐用户未观看的电影并添加到列表中
for item in items.keys():
if item not in data[user].keys():
recommendations.append((item,items[item]))
recommendations.sort(key=lambda val:val[1],reverse=True)#按照评分排序
#返回评分最高的10部电影
return recommendations[:10]
'''
#给用户1推荐电影
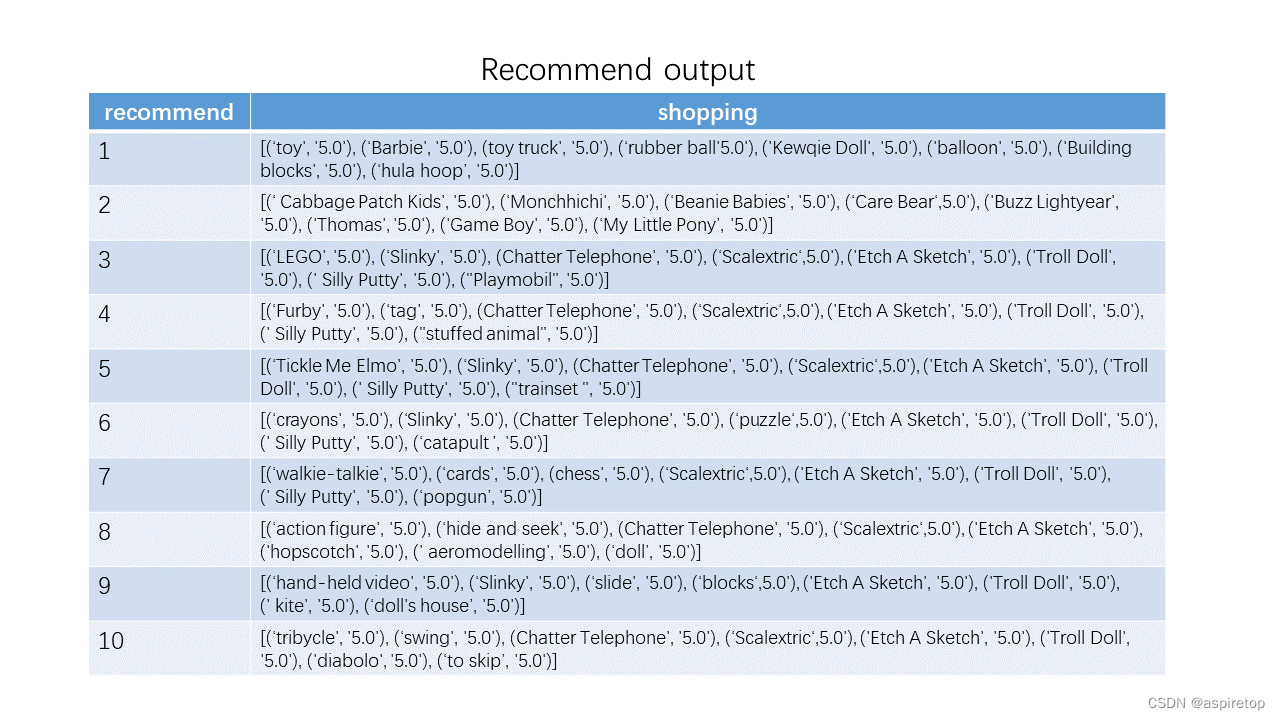
Recommendations = recommend(_userID)
print('推荐给{0}的电影有如下{1}个:'.format(_userID,len(Recommendations)))
print(Recommendations)
'''
for _user in data.keys():
Recommendations = recommend(_user)
#print('推荐给{0}的电影有如下{1}个:'.format(_user,len(Recommendations)))
print('推荐给{0}的电影如下:'.format(_user))
print(Recommendations)
python3.6可以直接运行

![com.alibaba.fastjson.JSONObject循环给同一对象赋值会出现“$ref“:“$[0]“现象问题](https://img-blog.csdnimg.cn/7a03b31634c345b4bfdbc101e6933dcf.png#pic_center)



![[OnWork.Tools]系列 05-系统工具](https://img-blog.csdnimg.cn/img_convert/5def12f1673050b7f1578257f9089a06.gif)