关于Detectron库预训练模型的权重转换
最近在调试代码的过程中涉及到detectron库的使用,在模型训练前,主干网络的部分需要加载预训练模型,但是原始的预训练模型在detron库中的代码是不能直接使用的,需要通过转换工具对模型的键值对做一下转换才可以使用,具体的使用流程见:MaskFormer/MODEL_ZOO.md at main · facebookresearch/MaskFormer (github.com)
常见的resnet系列的模型就不在这里举例了,以swin-transformer为例,说明如何使用转换工具。
convert-pretrained-swin-model-to-d2.py文件是转换swin_transformer模型的代码,具体的代码内容如下:
#!/usr/bin/env python
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
import pickle as pkl
import sys
import torch
"""
Usage:
# download pretrained swin model:
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
# run the conversion
./convert-pretrained-model-to-d2.py swin_tiny_patch4_window7_224.pth swin_tiny_patch4_window7_224.pkl
# Then, use swin_tiny_patch4_window7_224.pkl with the following changes in config:
MODEL:
WEIGHTS: "/path/to/swin_tiny_patch4_window7_224.pkl"
INPUT:
FORMAT: "RGB"
"""
if __name__ == "__main__":
input = sys.argv[1]
obj = torch.load(input, map_location="cpu")["model"]
res = {"model": obj, "__author__": "third_party", "matching_heuristics": True}
with open(sys.argv[2], "wb") as f:
pkl.dump(res, f)
使用方式如下(以ubuntu系统为例):
pip install timm
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
python tools/convert-pretrained-swin-model-to-d2.py swin_tiny_patch4_window7_224.pth swin_tiny_patch4_window7_224.pkl
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth
python tools/convert-pretrained-swin-model-to-d2.py swin_small_patch4_window7_224.pth swin_small_patch4_window7_224.pkl
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth
python tools/convert-pretrained-swin-model-to-d2.py swin_base_patch4_window12_384_22k.pth swin_base_patch4_window12_384_22k.pkl
wget https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth
python tools/convert-pretrained-swin-model-to-d2.py swin_large_patch4_window12_384_22k.pth swin_large_patch4_window12_384_22k.pkl
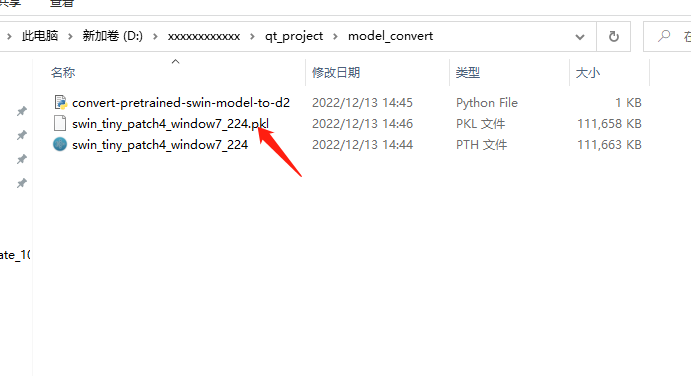
转换之后的结果如下图,即pickle格式的新文件。
附swin transformer系列模型下载地址
microsoft/Swin-Transformer: This is an official implementation for “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”. (github.com)
ImageNet-1K and ImageNet-22K Pretrained Swin-V1 Models
| name | pretrain | resolution | acc@1 | acc@5 | #params | FLOPs | FPS | 22K model | 1K model |
|---|---|---|---|---|---|---|---|---|---|
| Swin-T | ImageNet-1K | 224x224 | 81.2 | 95.5 | 28M | 4.5G | 755 | - | github/baidu/config/log |
| Swin-S | ImageNet-1K | 224x224 | 83.2 | 96.2 | 50M | 8.7G | 437 | - | github/baidu/config/log |
| Swin-B | ImageNet-1K | 224x224 | 83.5 | 96.5 | 88M | 15.4G | 278 | - | github/baidu/config/log |
| Swin-B | ImageNet-1K | 384x384 | 84.5 | 97.0 | 88M | 47.1G | 85 | - | github/baidu/config |
| Swin-T | ImageNet-22K | 224x224 | 80.9 | 96.0 | 28M | 4.5G | 755 | github/baidu/config | github/baidu/config |
| Swin-S | ImageNet-22K | 224x224 | 83.2 | 97.0 | 50M | 8.7G | 437 | github/baidu/config | github/baidu/config |
| Swin-B | ImageNet-22K | 224x224 | 85.2 | 97.5 | 88M | 15.4G | 278 | github/baidu/config | github/baidu/config |
| Swin-B | ImageNet-22K | 384x384 | 86.4 | 98.0 | 88M | 47.1G | 85 | github/baidu | github/baidu/config |
| Swin-L | ImageNet-22K | 224x224 | 86.3 | 97.9 | 197M | 34.5G | 141 | github/baidu/config | github/baidu/config |
| Swin-L | ImageNet-22K | 384x384 | 87.3 | 98.2 | 197M | 103.9G | 42 | github/baidu | github/baidu/config |
ImageNet-1K and ImageNet-22K Pretrained Swin-V2 Models
| name | pretrain | resolution | window | acc@1 | acc@5 | #params | FLOPs | FPS | 22K model | 1K model |
|---|---|---|---|---|---|---|---|---|---|---|
| SwinV2-T | ImageNet-1K | 256x256 | 8x8 | 81.8 | 95.9 | 28M | 5.9G | 572 | - | github/baidu/config |
| SwinV2-S | ImageNet-1K | 256x256 | 8x8 | 83.7 | 96.6 | 50M | 11.5G | 327 | - | github/baidu/config |
| SwinV2-B | ImageNet-1K | 256x256 | 8x8 | 84.2 | 96.9 | 88M | 20.3G | 217 | - | github/baidu/config |
| SwinV2-T | ImageNet-1K | 256x256 | 16x16 | 82.8 | 96.2 | 28M | 6.6G | 437 | - | github/baidu/config |
| SwinV2-S | ImageNet-1K | 256x256 | 16x16 | 84.1 | 96.8 | 50M | 12.6G | 257 | - | github/baidu/config |
| SwinV2-B | ImageNet-1K | 256x256 | 16x16 | 84.6 | 97.0 | 88M | 21.8G | 174 | - | github/baidu/config |
| SwinV2-B* | ImageNet-22K | 256x256 | 16x16 | 86.2 | 97.9 | 88M | 21.8G | 174 | github/baidu/config | github/baidu/config |
| SwinV2-B* | ImageNet-22K | 384x384 | 24x24 | 87.1 | 98.2 | 88M | 54.7G | 57 | github/baidu/config | github/baidu/config |
| SwinV2-L* | ImageNet-22K | 256x256 | 16x16 | 86.9 | 98.0 | 197M | 47.5G | 95 | github/baidu/config | github/baidu/config |
| SwinV2-L* | ImageNet-22K | 384x384 | 24x24 | 87.6 | 98.3 | 197M | 115.4G | 33 | github/baidu/config | github/baidu/config |
Note:
- SwinV2-B* (SwinV2-L*) with input resolution of 256x256 and 384x384 both fine-tuned from the same pre-training model using a smaller input resolution of 192x192.
- SwinV2-B* (384x384) achieves 78.08 acc@1 on ImageNet-1K-V2 while SwinV2-L* (384x384) achieves 78.31.







![[附源码]计算机毕业设计的桌游信息管理系统Springboot程序](https://img-blog.csdnimg.cn/c9f6022b5e1c41a791ebbe683234a871.png)