对于分布式系统来说,除了监控层面、以及服务治理层面,还有两个层面流量和数据调度。流量调度其实比较好理解,就是用户请求的流量,如何按照一定的策略算法打到不同的机器上。以及如何实现一个高可用、高性能的流量调度平台。而数据调度,因为目前大多数系统都是无状态的,所以都会将数据存储在第三方存储系统中,而如何实现数据调度,数据高可用、高性能、数据复制等也是一个考虑点。
流量调度主要功能
- 根据系统运行的情况,可以自动进行流量调度,无序人工干预,提升整个系统的稳定性。
- 让系统应对突发流量的时候,可以通过弹性扩缩容保证系统可以稳定运行。
目的都是为了提升系统架构的整体稳定性和高可用性。
流量调度系统
- 服务流控: 服务发现、服务路由、服务降级、服务熔断、服务保护。
- 流量控制: 负载均衡、流量分配、流控控制、异地灾备(多活)
- 流量管理 协议转换、请求校验、数据缓存、数据计算等。
流量调度的关键技术
高性能,网关必须是高性能,使用相关高性能语言。
抗流量,使用集群技术,数据在集群之间进行数据共享。使用Paxos、Raft、Gossip技术等。
业务逻辑,API 网关应该只有简单的业务逻辑。
服务化,可以通过Admin API来不停机的管理配置变更。而不是人肉的进行运维配置.conf文件。
状态数据调度
目前其实是倡导无状态服务,所以会把数据存储到第三方中间件中,比如Redis、MySQL、ZK、OSS等。但是这些存储中间件就有状态,所以就成为一个单点的瓶颈。
分布式事务一致性问题
要解决单点的瓶颈,就需要让数据服务可以像无状态的服务在不同的机器上进行调度,涉及数据的复制问题,而数据复制就一定会引入数据一致性,数据一致性就会引发性能问题。
所以无论是数据副本,还是数据分区,都会有一致性问题。而数据副本是分布式系统解决数据丢失异常的唯一手段。
1.想让数据有高可用性、就需要写多分数据
2.写多份数据会导致数据一致性的问题
3.数据一致性的问题会引发性能问题
而解决数据副本一致性问题,我们通常可以采用。主从、主主、一主多从、两阶段和三阶段提交方案、Paxos方案。
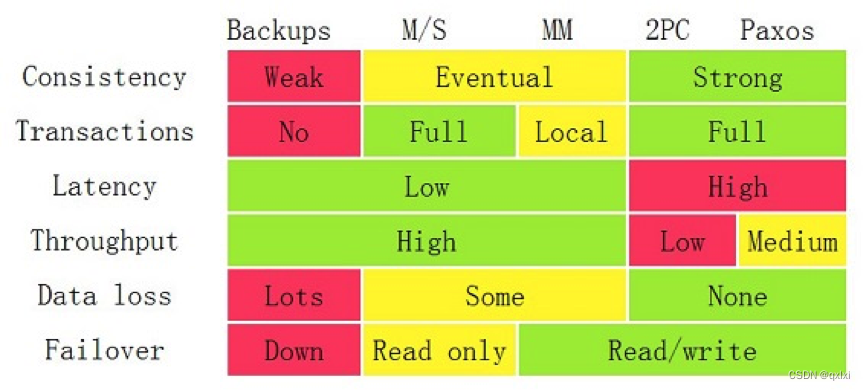
在应用层上解决事务问题,只有“两阶段提交”这样的方式,而在数据层解决事务问题,Paxos 算法则是不二之选。
小结
本篇主要介绍了分布式系统中流量调度和数据调度的相关概念。





![[分享]STM32G070 串口 乱码 解决方法](https://img-blog.csdnimg.cn/f9be8803e97e4d43b753460e44f9315f.png)