原文链接:https://arxiv.org/abs/2301.01283
1. 引言
受到DETR启发,本文提出鲁棒的端到端多模态3D目标检测方法CMT(跨模态Transformer)。首先使用坐标编码模块(CEM),通过将3D点集隐式地编码为多模态token,产生位置感知的特征。对图像分支,从视锥空间采样的3D点用来表达每个像素3D位置的概率;对激光雷达分支,将BEV坐标直接编码为点云token。然后引入位置指导的查询,类似PETR,首先初始化3D参考点,并投影到图像和激光雷达空间分别进行坐标编码。
CMT的优点如下:
- 隐式地将3D位置编码到多模态特征中,避免了显式跨视图特征对齐时存在的偏差(bias)。
- 模型仅包含基础操作,无需2D到3D的视图变换,能达到SotA性能。
- 鲁棒性强。在没有激光雷达的情况下,模型的性能能达到与基于视觉的方法相当的水平。
3. 方法
下图为模型框图。图像与激光雷达点云首先通过主干获取多模态token。然后,通过坐标编码将3D坐标编码进多模态token中。位置指导的查询生成器生成的查询在Transformer解码器中与多模态token交互,预测类别与边界框。
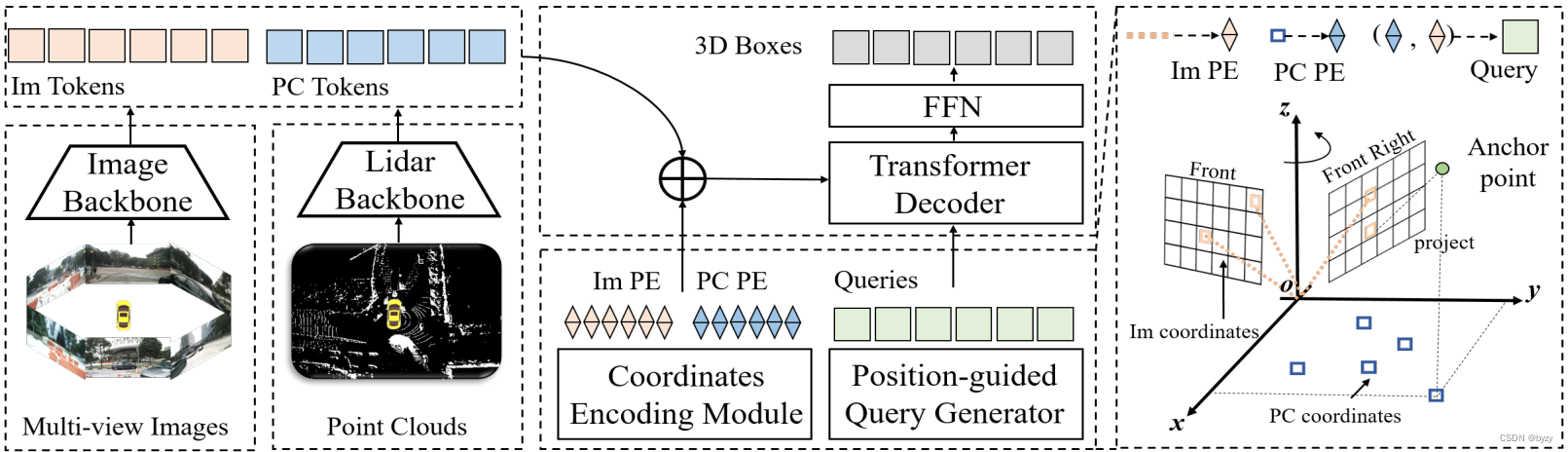
3.1. 坐标编码模块(CEM)
CEM将3D位置信息编码进多模态token中,从而隐式地对齐多模态token。具体来说,CEM生成相机和BEV的位置编码,分别与图像token和激光雷达token相加。设 P ( u , v ) P(u,v) P(u,v)为特征图对应的3D点集,其中 ( u , v ) (u,v) (u,v)为特征图的坐标,则通过MLP ψ \psi ψ,可得到CEM的输出位置嵌入: Γ ( u , v ) = ψ ( P ( u , v ) ) \Gamma(u,v)=\psi(P(u,v)) Γ(u,v)=ψ(P(u,v))
图像坐标编码
受PETR启发,由于一个像素对应3D空间的一条射线,可以在视锥空间中选取一组点进行编码。给定图像特征 F i m F_{im} Fim,每个像素对应相机视锥坐标系下的一组点 { p k ( u , v ) = ( u d k , v d k , d k , 1 ) T } k = 1 d \{p_k(u,v)=(ud_k,vd_k,d_k,1)^T\}_{k=1}^d {pk(u,v)=(udk,vdk,dk,1)T}k=1d其中 d d d是沿深度轴的采样点数量。对应的3D点可按下式计算: p k i m ( u , v ) = T c i l K i − 1 p k ( u , v ) p^{im}_k(u,v)=T_{c_i}^lK_i^{-1}p_k(u,v) pkim(u,v)=TcilKi−1pk(u,v)其中 T c i l ∈ R 4 × 4 T_{c_i}^l\in\mathbb{R}^{4\times4} Tcil∈R4×4是从第 i i i个相机到激光雷达的坐标变换矩阵, K i ∈ R 4 × 4 K_i\in\mathbb{R}^{4\times4} Ki∈R4×4是第 i i i个相机的内参矩阵。则像素 ( u , v ) (u,v) (u,v)的位置编码为 Γ i m ( u , v ) = ψ i m ( { p k i m ( u , v ) } k = 1 d ) \Gamma_{im}(u,v)=\psi_{im}(\{p_k^{im}(u,v)\}_{k=1}^d) Γim(u,v)=ψim({pkim(u,v)}k=1d)
点云坐标编码
使用VoxelNet或PointPillars作为主干网络获取点云token F p c F_{pc} Fpc。设 ( u , v ) (u,v) (u,v)是BEV特征图中的坐标,则采样点集为 p k ( u , v ) = ( u , v , h k , 1 ) T p_k(u,v)=(u,v,h_k,1)^T pk(u,v)=(u,v,hk,1)T,其中 h k h_k hk为第 k k k个点的采样高度,且 h 0 = 0 h_0=0 h0=0。则对应的3D点为 p k p c ( u , v ) = ( u d u , v d v , h k , 1 ) p_k^{pc}(u,v)=(u_du,v_dv,h_k,1) pkpc(u,v)=(udu,vdv,hk,1)其中 ( u d , v d ) (u_d,v_d) (ud,vd)是BEV网格的大小。本文仅采样1个高度,此时等价于BEV空间的2D位置编码。 Γ p c ( u , v ) = ψ p c ( { p k p c ( u , v ) } k = 1 h ) \Gamma_{pc}(u,v)=\psi_{pc}(\{p_k^{pc}(u,v)\}_{k=1}^h) Γpc(u,v)=ψpc({pkpc(u,v)}k=1h)
3.2. 位置指导的查询生成器
从 [ 0 , 1 ] [0,1] [0,1]之间的均匀分布采样,为查询初始化 n n n个锚点 A = { a i ∈ R 3 } i = 1 n A=\{a_i\in\mathbb{R}^3\}_{i=1}^n A={ai∈R3}i=1n。随后将这些归一化坐标转化到3D世界空间: { a x , i = a x , i ( x max − x min ) + x min a y , i = a y , i ( y max − y min ) + y min a z , i = a z , i ( z max − z min ) + z min \left\{ \begin{matrix}a_{x,i}=a_{x,i}(x_{\max}-x_{\min})+x_{\min}\\a_{y,i}=a_{y,i}(y_{\max}-y_{\min})+y_{\min}\\a_{z,i}=a_{z,i}(z_{\max}-z_{\min})+z_{\min}\end{matrix}\right. ⎩ ⎨ ⎧ax,i=ax,i(xmax−xmin)+xminay,i=ay,i(ymax−ymin)+yminaz,i=az,i(zmax−zmin)+zmin其中 p max , p min ( p ∈ { x , y , z } ) p_{\max},p_{\min}(p\in\{x,y,z\}) pmax,pmin(p∈{x,y,z})为感兴趣的坐标范围。然后将 A A A投影到各模态并通过CEM编码。物体查询嵌入为 Γ q = ψ p c ( A p c ) + ψ i m ( A i m ) \Gamma_q=\psi_{pc}(A_{pc})+\psi_{im}(A_{im}) Γq=ψpc(Apc)+ψim(Aim)其中 A p c A_{pc} Apc和 A i m A_{im} Aim分别为 A A A在BEV和图像上的投影。 Γ q \Gamma_q Γq会与查询内容嵌入相加,生成初始的位置指导的查询 Q 0 Q_0 Q0。
3.3. 解码器和损失
解码器与DETR相同,使用 L L L层解码层,逐渐更新查询,并使用两个FFN预测物体类别与边界框。分类使用focal损失,边界框回归使用L1损失。在查询去噪过程中,使用相同方式计算损失。
3.4. 丢弃模态训练以获得鲁棒性
为保证模型在单一相机失效、相机完全失效和激光雷达失效的情况下均保证可靠性,本文提出丢弃模态训练方法,在训练过程中以一定的概率随机使用单一模态数据,保证模型在单一模态和多模态下均得到训练。这样,模型能在单一模态或多模态下测试而无需调整网络权重。实验表明该策略不影响融合模型的性能。
3.5. 讨论
与FUTR3D不同,CMT无需反复从多模态采样和投影,而只需进行多模态位置编码与token相加。
4. 实验
4.1. 数据集和评价指标
对相机图像,仅使用关键帧;对激光雷达,将过去的非关键帧的点云转换到关键帧下。
4.2. 实施细节
在训练前中期使用了GT增广;为加快收敛,引入基于点的去噪策略(类似DN-DETR),通过中心位移判断有噪声锚点。
4.3. 与SotA比较
单一模态方案CMT-L能达到接近激光雷达SotA的水平;多模态CMT能超过目前所有SotA。相比TransFusion,CMT-L引入图像后有更高的性能提升。
4.4. 强鲁棒性
使用普通训练方案训练的模型在激光雷达模态失效时几乎完全失效。而使用丢弃模态训练方案训练的模型在任一模态失效时都能达到另一模态的单一模态水平。单一相机失效时,性能仅有略微下降。
4.5. 消融研究
移除点云位置编码会带来显著的性能下降,而移除图像位置编码仅有略微下降。基于点的查询去噪(PQD)也能带来较大的性能提升并加速收敛。增大输入图像尺寸主要对小物体的检测有较大提升。
4.6. 分析
可视化表明,注意力图中响应较强的区域为前景物体所在区域,且多数锚点更关注最近的前景物体。
5. 结论
局限性
CMT的计算开销较高,因为有大量的多模态token,且Transformer解码器中使用了全局注意力。有两个可能的解决方案:一是减小token数量,如通过网络预测前景token输入CMT;二是替换注意力机制,如使用可变形注意力。

![[分享]STM32G070 串口 乱码 解决方法](https://img-blog.csdnimg.cn/f9be8803e97e4d43b753460e44f9315f.png)