一、说明
HEalthcare和生命科学行业产生大量数据,这些数据是由合规性和监管要求,记录保存,研究论文等驱动的。但随着数据量的增加,搜索用于研究目的的必要文件和文章以及数据结构成为一个更加复杂和耗时的过程。例如,如今,生物医学搜索引擎包含超过40万篇文章,这些文章代表了大量有用的医疗保健信息。但是手动处理如此大量的数据是一条无法通行的路径,而自然语言处理(NLP)等工具有助于从文本数据中提取信息。
NLP 工具是 AI 的一个分支,包括语音识别、文本分析、翻译和其他与语言相关的目标等应用程序。NLP 提供了通过阅读和理解数据,然后将其转换为可理解的结构化数据,从半结构化/非结构化临床和新兴数据中提取有价值的见解的能力。NLP背后的想法是更好地将人类与计算机的处理能力联系起来,以增强护理并加快治疗的交付并加速研究。
在自由文本中识别医学术语是NLP任务的第一步,因为自动索引生物医学文献并从临床笔记文本中提取患者的问题列表。在生物医学文献中可以找到许多医学术语:疾病名称(结核病,神经胶质瘤,糖尿病),症状(急性头痛,发烧,腹痛),治疗(化疗,药物治疗),诊断测试(活检,光学相干断层扫描,心电图),化学物质,解剖结构等。除了检测文本中的医学术语外,每个术语都应与医学编码标准相关联:疾病和相关健康问题的国际统计分类(ICD-11),统一医学语言系统(UMLS),当前程序术语(CPT)和许多其他术语。特别是,要成功利用生物医学记录中包含的大量知识,拥有自动索引技术至关重要。NLP 领域的一个概念称为实体链接,它有助于解决此任务。
二、用于概念检测的实体链接
在医疗保健领域,准确的实体链接对于正确理解生物医学背景至关重要。在处理生物医学概念时,人们可能会偶然发现许多问题:许多不同的实体可以有非常相似的提及,实体可以通过各种拼写形式在文本中提及,缩写形式的实体可能不会以独特的方式扩展。面对这些挑战,实体链接 (EL) 中的故障将导致对上下文信息的错误解释。在医疗保健领域,此类错误可能会导致医疗相关决策的风险。
EL在医疗保健领域的另一个特点是公开可用的生物医学EL数据集的可用性非常有限。至少,它使构建和训练 EL 模型的过程复杂化;假设推理数据量很大,这样的EL模型可能不够普遍。但是,在最坏的情况下,某些类别的生物医学实体可能没有在公开可用的数据集中注册,这导致为给定类别的实体手动构建此类训练集。
这就是为什么生物医学文本上的EL在许多方面与其他领域的文本不同。因此,解决这些具有挑战性的任务需要复杂的方法。
三、数据和方法
3.1 词汇表和符号
实体 — 命名的单词或短语(疾病、基因、药物等的名称)。通常,实体是从知识库中提取的。
知识库——实体字典;通常包括规范名称、定义、同义词等。
提及(实体) — 文本中实体的名称。此外,上下文(周围)信息可以被视为提及。
实体链接 — 将文本中对实体的提及映射到其在知识库中的标识。
3.2 模型概述
作为EL模型,我们考虑Siamese神经网络,它旨在学习实体提及和相应概念之间的相似性。
我们构建以下模型(参见图 1)。神经网络的两个分支相应地对应于提及输入和实体输入。每个分支将整个文本映射到密集的向量(从一侧提及上述实体和句子的文本,从另一侧引用知识库的实体级信息)。在训练过程中,模型学习增加从正确链接的对提及+实体中提取的向量之间的余弦相似性,并降低错误配对向量之间的余弦相似性。在推理阶段,每个输入提及都映射到向量空间中,并假定最近的实体向量是相应实体的向量。
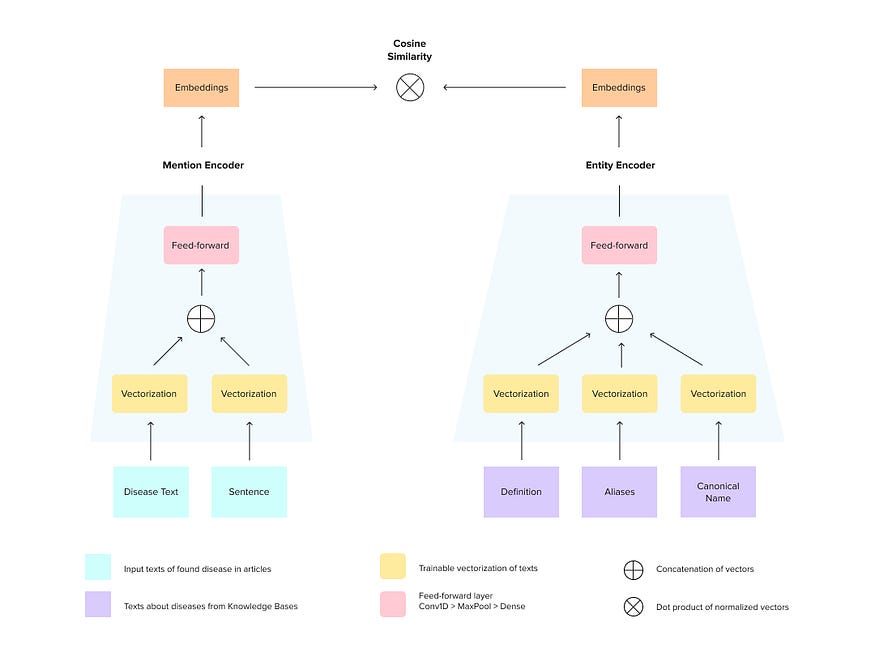
图1.暹罗神经网络
然而,这种方法有几个缺点,特别是对于生物医学数据。
3.3 生物医学EL中的问题
在仅存在少数生物医学EL数据集的情况下,准备准确的训练数据集是一项重要任务。例如,考虑疾病概念链接任务,可以从以下数据集收集训练信息:
–NCBI疾病数据集。NCBI疾病语料库的公开发布包含6.9k种疾病提及,这些疾病被映射到0.8k独特的疾病概念(来自MeSH和OMIM本体)。NCBI疾病数据集的内部精度:<90%。
–MedMentions是生物医学论文的语料库,并提及UMLS实体。它包含 4392 个摘要和 34k 个唯一的 UMLS ID。该数据集不仅仅是一组疾病。MedMentions的内部精度为97.3%。通过保留22种UMLS类型,涵盖疾病和生物过程以及具有定义的实体,可以获得一组4805种UMLS类疾病实体。这些疾病几乎在所有摘要中都有标记,涵盖了15.4k独特疾病的8k提及。
–BC5CDR 语料库由 1.5k 篇 PubMed 文章组成,带有注释的化学物质、疾病和化学-疾病相互作用。通过去除化学物质并仅保留疾病,人们可以获得一组1.5k摘要,其中涵盖了3.1k次提及的疾病。这些提及可以映射到1k个独特的MeSH实体中。
正如人们所看到的,收集的摘要总数可以达到7k,而其中的提及/实体数量分别约为30k/5k。这表明我们的训练数据因提及实体而高度多样化。此外,绝大多数训练样本包含冗余信息(摘要中的单词,与疾病没有任何共同之处)。
但是所考虑的模型将单词的索引映射到嵌入中,并且使用具有一些有用信息的非常大的字典来学习这种映射可能不够充分和有效。可以通过以下方式解决此问题:
-使用预先训练的嵌入(生物医学单词的训练嵌入,例如BioWordVec)-过滤字典并仅保留有用的信息(例如单词,这是提及短语的粒子,知识库中的单词)
使用第二种方法,可以将字典的大小压缩 10-100 倍,这将有利于训练和推理加速。
四、质量增强
将带有提及的上下文信息放入模型的提及分支中可能会提高 EL 的质量。某些提及可能仅与提及短语正确链接,上下文可能在链接过程中发挥关键作用。有了这个,模型可以接受,期待提及,引用提及的句子。
由于可以增加提及和相应上下文的开放可能性,因此可以开发这种方法以提高模型的泛化能力。例如,有一对“提及+摘要中的提及句子”和“来自知识库的实体”,可以:
-创建负(非链接)对,使用句子中的随机单词而不是提及;
-通过句子中的向前和/或向后单词扩展提及;
-删除句子的随机部分而不提及部分。
4.1 培训程序
由于任务是度量学习,因此必须训练模型以找到正确的“提及”-“实体”对之间的相似之处和不正确的对之间的相似之处。这样的模型不能只在正对上训练,因为它不会被训练来区分正确和不正确的链接。另一方面,我们不能为每次提及分配所有负实体,因为我们的数据集将通过幂律扩展提及次数,这对于相对较大的训练 EL 数据集来说可能具有挑战性。
因此,要训练EL模型,必须考虑一些采样过程,例如,三重损失,它适用于三重“提及”-“正确的实体”-“不正确的实体”。此外,可以使用特殊的批次内抽样:通过分配给定批次中批次随机实体中的每个提及,链接到其他提及,可以通过负样本扩展一批正对。
一些提升可以通过处理硬性负样本获得,即错误链接的实体,对于给定的提及,它们比相应的实体更相似。
4.2 质量指标
通过将概念名称的真实和预测ID与指定的余弦相似性截止值进行比较,测量每个句子的EL质量。评估概念名称实体链接质量的方法是真阳性(TP),真阴性(TN),假阴性(FN)。例:
-真正的疾病标签(上ID是真的):广泛的认知障碍D003072,如谵妄D003693或ADD010302,以前与高血药水平的SSRIs无关。
-预测疾病(上 ID 为真,下 ID 为预测):广泛的认知障碍D003072D003072,如谵妄 D003693 或 ADD010302D0220454,以前与 SSRIsD001658 的高血水平无关。
-TP:认知障碍D003072D003072 — 当ID_true等于ID_pred时.
-FP:SSRIsD001658 , ADD010302D0220454 — 当ID_pred不等于ID_true时。
–FN:deliriumD003693 — 当ID_true不等于ID_pred时。
作为准确性指标,我们使用了几个指标来更好地衡量模型准确性:
–精度

–召回

–F1 分数
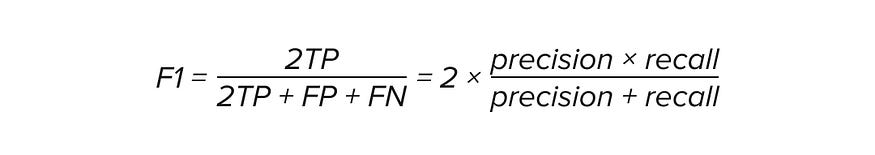
–马修斯相关系数
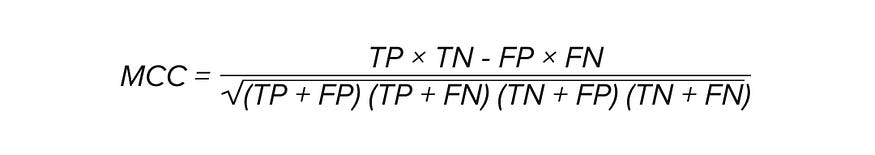
–ROC-AUC
–K 精度
五、结果和结论
在生成的模型中,我们获得了验证数据集的下一个分数(见图 2)。
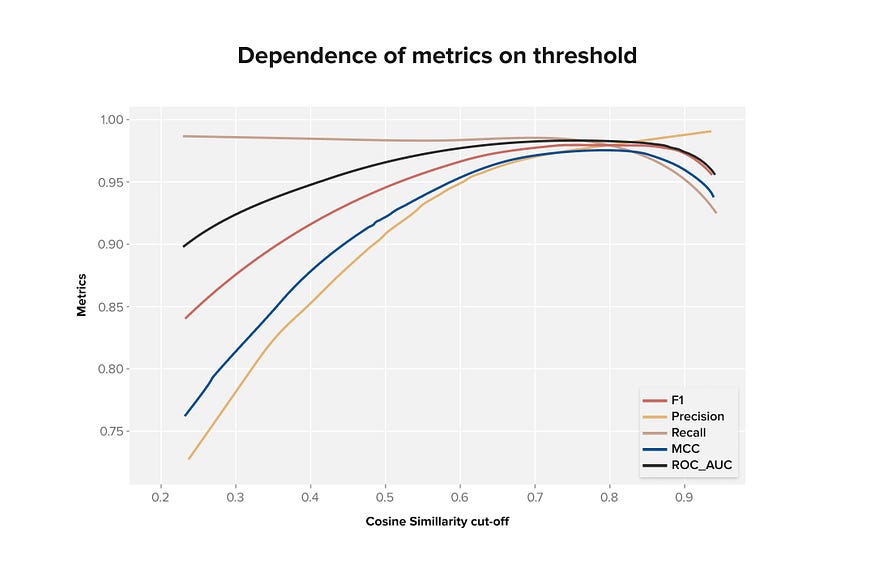
图2.不同相似性阈值的不同质量指标图表
我们发现,对一个概念的正确和不正确描述的分离质量最好,相似度约为0.8。也就是说,如果描述和概念向量之间的余弦相似性大于 0.8,那么这个对很可能是正确的。
对于 K 处的精度计算,验证样本中的每个概念都必须选择 K 最接近的描述,并记住正确描述的数量。如果模型是完美的,那么对于每个概念,最接近的(K = 1)描述都是正确的。我们在原始(非乘法)验证样本上进行了此实验。结果,我们得到了以下 K = 5 时的精度值(见表 1)。
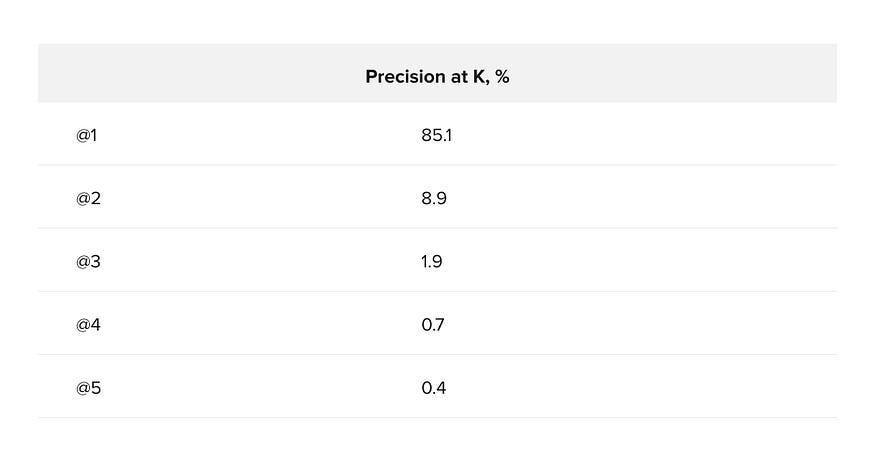
表 1.前 5 个描述的精度为 K
K 的精度表明,对于验证样本中的概念,最接近的描述是正确的,准确率为 85%,正确的描述位于前 5 个最接近的概率为 97%。